
InnoDB的Buffer Pool簡介
阿新 • • 發佈:2018-05-10
個數 說過 下一個 而且 角度 比例 控制 刷新 變化
這篇非常重要!這篇非常重要!這篇非常重要!重要的事情說三遍,這篇是後續事務和鎖的基礎,一定要看懂這篇,反正我寫的已經夠白話了,你要再看不懂呢,那你告訴我,我改還不行麽~下邊是建議正文:
1. 最好使用電腦觀看。
2. 如果你非要使用手機觀看,那請把字體調整到最小,這樣觀看效果會好一些。
3. 碎片化閱讀並不會得到真正的知識提升,要想有提升還得找張書桌認認真真看一會書,或者我們公眾號的文章。
4. 如果覺得不錯,各位幫著轉發轉發,如果覺得有問題或者寫的哪不清晰,務必私聊我~
5. 本公眾號的文章都是需要被系統性學習的,在閱讀本篇文章前最好已經閱讀過下邊幾篇文章,要不然可能會有閱讀不暢的體驗:
表空間的編號
我們在嘮叨的時候就已經說過,存儲引擎是使用來存儲的,又可以被分為系統表空間和獨立表空間。為了方便管理,每個都會有一個字節的編號,值得註意的一點是,系統表空間的編號始終為,也會根據一定規則給其他獨立表空間也編上號~
所以,當我們查看或修改某個的數據的時候,實際上需要同時知道表空間的編號和該頁的編號,也就是的組合才能定位到某一個具體的。如果你有認真看前邊嘮叨的那篇文章,肯定記得每個的編號也是占用個字節,而在一個內頁的編號是不能重復的,個字節是個二進制位,也就是說:一個表空間最多擁有232個頁,默認情況下一個頁的大小為16KB,也就是說一個表空間最多存儲64TB的數據~ 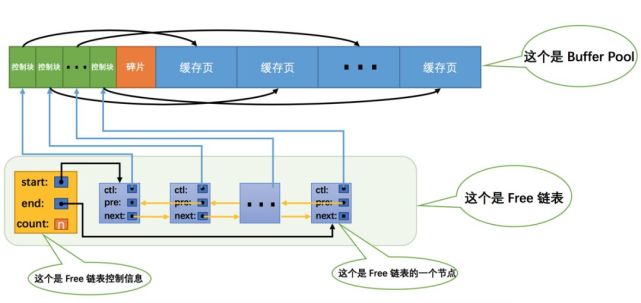
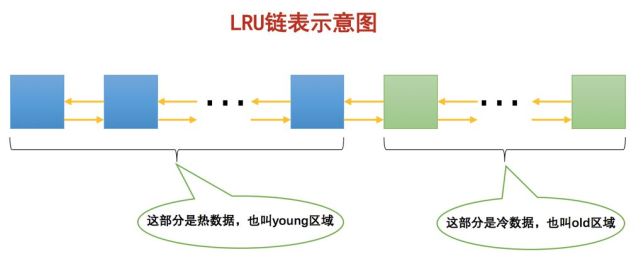 大家要特別註意一個事兒:我們是按照某個比例將 LRU鏈表 分成兩半的,不是某些節點固定是young區域的,某些節點固定式old區域的,隨著程序的運行,某個節點所屬的區域也可能發生變化。所以把一個完整的分成了和兩個部分之後,修改鏈表的方式也就可以變一變了:
如果某個頁第一次從磁盤加載到中,則放到區域的頭部。
如果該頁已經在中,則將其放到區域的頭部,也就是的頭部。
這樣搞有啥好處呢?在沒有空閑的緩存頁時,我們可以從old區域中淘汰一些頁,而不影響young區域中的緩存頁。這樣全表掃描的頁雖然也會進入中,但是由於首次緩存時只會放到區域,區域不受影響,也就是只會對造成部分換血,而不是全部換血,這在一定程度上降低了全表掃描對的緩存命中率的影響。
那這個劃分成兩截的比例怎麽確定呢?對於存儲引擎來說,我們可以通過查看系統變量的值來確定區域在中所占的比例,比方說這樣:
從結果可以看出來,默認情況下,區域在中所占的比例是,也就是說區域大約占的。這個比例我們是可以設置的,我們可以在啟動時修改參數來控制區域在中所占的比例,比方說這樣修改配置文件:
這樣我們在啟動服務器後,區域占的比例就是。當然,如果在服務器運行期間,我們也可以修改這個系統變量的值,不過需要註意的是,這個系統變量屬於,一經修改,會對所有客戶端生效,所以我們只能這樣修改:
更進一步優化LRU鏈表
這就說完了麽?沒有,早著呢~ 首次從磁盤上加載到的頁會放到區域,第二次訪問該頁的時候便會被放到區域,那如果在很短的時間內進行了兩次全表掃描操作豈不是會把區域的節點都移動到區域了,那相當於又把給破壞掉了,咋辦?
我們可以設置一個間隔時間,當第二次訪問區域的某個緩存頁時(該緩存頁沒有被淘汰掉),如果距離上一次訪問的時間小於這個時間,那就不把這個緩存頁放到區域,這個過程稱之為;而如果距離上一次訪問的時間不小於這個時間,那就把這個緩存頁放到區域,這個過程稱之為。這樣就可以降低在短時間內有大量全表掃描對的緩存命中率的影響。中這個間隔時間是由系統變量控制的,你看:
在我的電腦上的值是,它的單位是毫秒,也就意味著如果在1秒內發生了多次全表掃描,這些在區域的頁也不會被加入到區域的~ 當然,像一樣,我們也可以在服務器啟動或運行時設置的值,這裏就不贅述了,你自己試試吧~
還有一個問題,對於區域的緩存頁來說,我們每次訪問一個緩存頁就要把它移動到的頭部,這樣開銷是不是太大啦,畢竟在區域的緩存頁都是熱點數據,也就是可能被經常訪問的,這樣頻繁的對進行節點移動操作是不是不太好啊?是的,為了解決這個問題其實我們還可以提出一些優化策略,比如只有被訪問的緩存頁其於區域的(這個值可調節)之後,才會被移動到頭部,這樣就可以降低調整的頻率,從而提升性能。
還有木有什麽別的針對的優化措施呢?當然有啊,你要是好好學,寫篇論文,寫本書都不是問題,可是我們畢竟是一個介紹MySQL基礎知識的文章,再說多了篇幅就受不了了,適可而止,想了解更多的優化知識,自己去看源碼或者更多關於鏈表的知識嘍~ 另外,不同的大公司,可能會針對自己的業務對鏈表進行自己的定制,優化是無窮盡的,但是千萬別忘了我們的初心:盡量提高Buffer Pool的緩存命中率。
其他的一些鏈表
為了更好的管理中的緩存頁,除了我們上邊提到的一些措施,設計的大叔們還引進了其他的一些,比如用於管理解壓頁,用於管理存儲沒有被解壓的壓縮頁,用來管理被壓縮的頁等等,反正是為了更好的管理這個引入了各種鏈表,構造和我們介紹的鏈表都差不多,具體的使用方式就不啰嗦了,大家有興趣深究的再去找些更深的書或者直接看源代碼吧~
InnoDB中對各種列表的處理
上邊對各種鏈表的介紹,只是從我們初學者的學習原理的角度去看的,設計的大叔在真正實現這些鏈表上又下了一番苦功夫,都是為了節省內存和挺高性能而做的努力。比方說
實際的鏈表節點並不是獨立於的而存在的,而是被放在了緩存頁控制塊中。
雖然為了不同的目的我們提出了很多的鏈表,但是每個緩存頁控制塊其實只有一個節點和一個通用的鏈表節點。為了節省內存,針對緩存頁所處於的不同狀態,對緩存頁控制塊的通用鏈表節點進行了復用,比方說在該緩存頁空閑時,該節點代表的節點;比方說該緩存頁被修改時,該節點代表的節點,吧啦吧啦~
當然,如果你看不懂我上邊在說啥(本來也沒打算讓你看懂),那就不用看了,這只是設計的大叔在針對具體的場景做的優化方案,待你真正動手去設計一個存儲引擎時,你才會考慮如何更好地實現我們上邊的這些原理,現在可以先跳過,設計的大叔們為了更好地實現,使用了好幾萬行代碼,要說清楚這些,怎麽也得好幾篇文章了,我沒那個時間,等以後牛逼有空了,我再來仔細說清楚針對這些鏈表實現的具體細節~
多個Buffer Pool實例
我們上邊說過,本質是向操作系統申請的一塊連續的內存空間,在多線程環境下,為了保護緩存頁可能會對緩存頁進行加鎖處理啥的(具體怎麽鎖我們後邊的文章會嘮叨),在特別大而且多線程並發訪問特別高的情況下,單一的可能會影響請求的處理速度。所以在特別大的時候,我們可以把它們拆分成若幹個小的,每個都稱為一個,它們都是獨立的,獨立的去申請內存空間,獨立的管理各種鏈表,獨立的吧啦吧啦,所以在多線程並發訪問時並不會相互影響,從而提高並發處理能力。我們可以在服務器啟動的時候通過設置的值來修改的個數,比方說這樣:
這樣就表明我們要創建2個。那每個實際占多少內存空間呢?其實使用這個公式算出來的:
也就是總共的大小除以個數,結果就是每個占用的大小。
不過也不是說實例創建的越多越好,分別管理各個也是需要性能開銷的,設計的大叔們規定:Buffer Pool的大小小於1G的時候設置多個實例是無效的,InnoDB會默認把innodb_buffer_pool_instances 的值修改為1。而我們鼓勵在大小大於1G的時候設置多個Buffer Pool實例。
InnoDB中查看的狀態信息
作為MySQL的管理人員,我們有時候需要查看一下中的情況,設計的大叔們給我們提供了這樣的查詢請求,就像這樣(為了突出重點,我們只把輸出中關於的部分提取了出來):
雖然這裏頭的參數我們並不能全部看懂,但是有一些還是很眼熟的:
代表該可以容納多少緩存,註意,單位是!
代表當前還有多少空閑緩存頁,也就是中還有多少個節點。
代表鏈表中的頁的數量,包含和兩個區域的節點數量。
代表鏈表區域的節點數量。
代表臟頁數量,也就是中節點的數量。
代表從區域移動到區域的節點數量,代表區域沒有移動到區域就被淘汰的節點數量。後邊跟著移動的速率。
代表讀取,創建,寫入了多少頁。後別跟著讀取、創建、寫入的速率。
代表中節點的數量。
代表非大小的頁的數量,這些非大小的頁都是被管理的,我們也沒多嘮叨它,看不懂就忽略它吧~
其他的參數我們目前不需要理解,之後遇到的話會仔細說的~
總結
我們可以通過的組合可以定位到某一個具體的。磁盤太慢,用內存作為緩存很有必要。本質上是向操作系統申請的一段連續的內存空間,可以通過來調整它的大小由控制塊和緩存頁組成,每個控制塊和緩存頁都是一一對應的,在填充足夠多的控制塊和緩存頁的組合後,剩余的空間可能產生不夠填充一組控制塊和緩存頁,這部分空間不能被使用,也被稱為。
使用了許多來管理。
中每一個節點都代表一個空閑的緩存頁,在將磁盤中的頁加載到時,會從中尋找空閑的緩存頁。
為了快速定位某個頁是否被加載到,使用作為,緩存頁作為,建立哈希表。
在中被修改的頁稱為,臟頁並不是立即刷新,而是被加入到中,待之後的某個時刻同步到磁盤上。
分為和兩個區域,可以通過來調節區域所占的比例。首次從磁盤上加載到的頁會被放到區域的頭部,如果在間隔時間後該頁該頁沒有被淘汰掉並且仍在區域時,會把它放到鏈表的頭部,也就是區域的頭部。在沒有可用的空閑緩存頁時,會首先淘汰掉區域的一些頁。
我們可以通過指定來控制的個數,每個中都有各自獨立的鏈表,互不幹擾。
可以用下邊的命令查看的狀態信息:
題外話
寫文章挺累的,有時候你覺得閱讀挺流暢的,那其實是背後無數次修改的結果。如果你覺得不錯請幫忙轉發一下,萬分感謝~
轉載於https://view.inews.qq.com/a/20180424G0YLHQ00?uid=&from=singlemessage
原作者:我們都是小青蛙 2018-04-24
原內容有很多文字錯誤,在原內容上進行了更新和修正……
大家要特別註意一個事兒:我們是按照某個比例將 LRU鏈表 分成兩半的,不是某些節點固定是young區域的,某些節點固定式old區域的,隨著程序的運行,某個節點所屬的區域也可能發生變化。所以把一個完整的分成了和兩個部分之後,修改鏈表的方式也就可以變一變了:
如果某個頁第一次從磁盤加載到中,則放到區域的頭部。
如果該頁已經在中,則將其放到區域的頭部,也就是的頭部。
這樣搞有啥好處呢?在沒有空閑的緩存頁時,我們可以從old區域中淘汰一些頁,而不影響young區域中的緩存頁。這樣全表掃描的頁雖然也會進入中,但是由於首次緩存時只會放到區域,區域不受影響,也就是只會對造成部分換血,而不是全部換血,這在一定程度上降低了全表掃描對的緩存命中率的影響。
那這個劃分成兩截的比例怎麽確定呢?對於存儲引擎來說,我們可以通過查看系統變量的值來確定區域在中所占的比例,比方說這樣:
從結果可以看出來,默認情況下,區域在中所占的比例是,也就是說區域大約占的。這個比例我們是可以設置的,我們可以在啟動時修改參數來控制區域在中所占的比例,比方說這樣修改配置文件:
這樣我們在啟動服務器後,區域占的比例就是。當然,如果在服務器運行期間,我們也可以修改這個系統變量的值,不過需要註意的是,這個系統變量屬於,一經修改,會對所有客戶端生效,所以我們只能這樣修改:
更進一步優化LRU鏈表
這就說完了麽?沒有,早著呢~ 首次從磁盤上加載到的頁會放到區域,第二次訪問該頁的時候便會被放到區域,那如果在很短的時間內進行了兩次全表掃描操作豈不是會把區域的節點都移動到區域了,那相當於又把給破壞掉了,咋辦?
我們可以設置一個間隔時間,當第二次訪問區域的某個緩存頁時(該緩存頁沒有被淘汰掉),如果距離上一次訪問的時間小於這個時間,那就不把這個緩存頁放到區域,這個過程稱之為;而如果距離上一次訪問的時間不小於這個時間,那就把這個緩存頁放到區域,這個過程稱之為。這樣就可以降低在短時間內有大量全表掃描對的緩存命中率的影響。中這個間隔時間是由系統變量控制的,你看:
在我的電腦上的值是,它的單位是毫秒,也就意味著如果在1秒內發生了多次全表掃描,這些在區域的頁也不會被加入到區域的~ 當然,像一樣,我們也可以在服務器啟動或運行時設置的值,這裏就不贅述了,你自己試試吧~
還有一個問題,對於區域的緩存頁來說,我們每次訪問一個緩存頁就要把它移動到的頭部,這樣開銷是不是太大啦,畢竟在區域的緩存頁都是熱點數據,也就是可能被經常訪問的,這樣頻繁的對進行節點移動操作是不是不太好啊?是的,為了解決這個問題其實我們還可以提出一些優化策略,比如只有被訪問的緩存頁其於區域的(這個值可調節)之後,才會被移動到頭部,這樣就可以降低調整的頻率,從而提升性能。
還有木有什麽別的針對的優化措施呢?當然有啊,你要是好好學,寫篇論文,寫本書都不是問題,可是我們畢竟是一個介紹MySQL基礎知識的文章,再說多了篇幅就受不了了,適可而止,想了解更多的優化知識,自己去看源碼或者更多關於鏈表的知識嘍~ 另外,不同的大公司,可能會針對自己的業務對鏈表進行自己的定制,優化是無窮盡的,但是千萬別忘了我們的初心:盡量提高Buffer Pool的緩存命中率。
其他的一些鏈表
為了更好的管理中的緩存頁,除了我們上邊提到的一些措施,設計的大叔們還引進了其他的一些,比如用於管理解壓頁,用於管理存儲沒有被解壓的壓縮頁,用來管理被壓縮的頁等等,反正是為了更好的管理這個引入了各種鏈表,構造和我們介紹的鏈表都差不多,具體的使用方式就不啰嗦了,大家有興趣深究的再去找些更深的書或者直接看源代碼吧~
InnoDB中對各種列表的處理
上邊對各種鏈表的介紹,只是從我們初學者的學習原理的角度去看的,設計的大叔在真正實現這些鏈表上又下了一番苦功夫,都是為了節省內存和挺高性能而做的努力。比方說
實際的鏈表節點並不是獨立於的而存在的,而是被放在了緩存頁控制塊中。
雖然為了不同的目的我們提出了很多的鏈表,但是每個緩存頁控制塊其實只有一個節點和一個通用的鏈表節點。為了節省內存,針對緩存頁所處於的不同狀態,對緩存頁控制塊的通用鏈表節點進行了復用,比方說在該緩存頁空閑時,該節點代表的節點;比方說該緩存頁被修改時,該節點代表的節點,吧啦吧啦~
當然,如果你看不懂我上邊在說啥(本來也沒打算讓你看懂),那就不用看了,這只是設計的大叔在針對具體的場景做的優化方案,待你真正動手去設計一個存儲引擎時,你才會考慮如何更好地實現我們上邊的這些原理,現在可以先跳過,設計的大叔們為了更好地實現,使用了好幾萬行代碼,要說清楚這些,怎麽也得好幾篇文章了,我沒那個時間,等以後牛逼有空了,我再來仔細說清楚針對這些鏈表實現的具體細節~
多個Buffer Pool實例
我們上邊說過,本質是向操作系統申請的一塊連續的內存空間,在多線程環境下,為了保護緩存頁可能會對緩存頁進行加鎖處理啥的(具體怎麽鎖我們後邊的文章會嘮叨),在特別大而且多線程並發訪問特別高的情況下,單一的可能會影響請求的處理速度。所以在特別大的時候,我們可以把它們拆分成若幹個小的,每個都稱為一個,它們都是獨立的,獨立的去申請內存空間,獨立的管理各種鏈表,獨立的吧啦吧啦,所以在多線程並發訪問時並不會相互影響,從而提高並發處理能力。我們可以在服務器啟動的時候通過設置的值來修改的個數,比方說這樣:
這樣就表明我們要創建2個。那每個實際占多少內存空間呢?其實使用這個公式算出來的:
也就是總共的大小除以個數,結果就是每個占用的大小。
不過也不是說實例創建的越多越好,分別管理各個也是需要性能開銷的,設計的大叔們規定:Buffer Pool的大小小於1G的時候設置多個實例是無效的,InnoDB會默認把innodb_buffer_pool_instances 的值修改為1。而我們鼓勵在大小大於1G的時候設置多個Buffer Pool實例。
InnoDB中查看的狀態信息
作為MySQL的管理人員,我們有時候需要查看一下中的情況,設計的大叔們給我們提供了這樣的查詢請求,就像這樣(為了突出重點,我們只把輸出中關於的部分提取了出來):
雖然這裏頭的參數我們並不能全部看懂,但是有一些還是很眼熟的:
代表該可以容納多少緩存,註意,單位是!
代表當前還有多少空閑緩存頁,也就是中還有多少個節點。
代表鏈表中的頁的數量,包含和兩個區域的節點數量。
代表鏈表區域的節點數量。
代表臟頁數量,也就是中節點的數量。
代表從區域移動到區域的節點數量,代表區域沒有移動到區域就被淘汰的節點數量。後邊跟著移動的速率。
代表讀取,創建,寫入了多少頁。後別跟著讀取、創建、寫入的速率。
代表中節點的數量。
代表非大小的頁的數量,這些非大小的頁都是被管理的,我們也沒多嘮叨它,看不懂就忽略它吧~
其他的參數我們目前不需要理解,之後遇到的話會仔細說的~
總結
我們可以通過的組合可以定位到某一個具體的。磁盤太慢,用內存作為緩存很有必要。本質上是向操作系統申請的一段連續的內存空間,可以通過來調整它的大小由控制塊和緩存頁組成,每個控制塊和緩存頁都是一一對應的,在填充足夠多的控制塊和緩存頁的組合後,剩余的空間可能產生不夠填充一組控制塊和緩存頁,這部分空間不能被使用,也被稱為。
使用了許多來管理。
中每一個節點都代表一個空閑的緩存頁,在將磁盤中的頁加載到時,會從中尋找空閑的緩存頁。
為了快速定位某個頁是否被加載到,使用作為,緩存頁作為,建立哈希表。
在中被修改的頁稱為,臟頁並不是立即刷新,而是被加入到中,待之後的某個時刻同步到磁盤上。
分為和兩個區域,可以通過來調節區域所占的比例。首次從磁盤上加載到的頁會被放到區域的頭部,如果在間隔時間後該頁該頁沒有被淘汰掉並且仍在區域時,會把它放到鏈表的頭部,也就是區域的頭部。在沒有可用的空閑緩存頁時,會首先淘汰掉區域的一些頁。
我們可以通過指定來控制的個數,每個中都有各自獨立的鏈表,互不幹擾。
可以用下邊的命令查看的狀態信息:
題外話
寫文章挺累的,有時候你覺得閱讀挺流暢的,那其實是背後無數次修改的結果。如果你覺得不錯請幫忙轉發一下,萬分感謝~
轉載於https://view.inews.qq.com/a/20180424G0YLHQ00?uid=&from=singlemessage
原作者:我們都是小青蛙 2018-04-24
原內容有很多文字錯誤,在原內容上進行了更新和修正……
InnoDB的Buffer Pool簡介