
Kubernetes 核心概念簡介
管理角色
Kubernetes中有兩種管理角色,Master和Node.
Master
Master是Kubernetes集群的控制節點,所有對於Kubernetes的命令操作都需要在控制節點執行。Master一般運行如下進程:
kube-apiserver: Kubernetes API Server, 提供了HTTP Rest接口的關鍵服務進程,是所有資源增,刪,改,查的入口,也是集群控制的入口進程,kubectl是直接與 API Server交互的,默認監聽 6443端口。
kube-controller-manager: 每個資源一般都對應有一個控制器,而controller manager就是負責管理這些控制器的,它是自動化的循環控制器,是Kubernetes的核心控制守護進程。默認監聽10252端口。
kube-scheduler : 負責將pod資源調度到合適的node 上。其本身提供了復雜豐富的調度算法,可以根據node 節點的性能,負載,數據位置等各種情況進行合理的調度。默認監聽10251 端口。
etcd: 一個高可用的鍵值存儲系統,Kubernetes使用它來存儲各個資源的狀態,從而實現了Restful的API。默認監聽2379和2380端口(2379提供服務,2380用於集群節點通信)
Node
除了Master節點,集群中的其它節點被稱作Node節點,Node節點是業務應用實際的運行的平臺,通過Master 調度不同的任務到Node節點上,以docker 的方式運行。當某個Node節點宕機時,其上的工作負載會被Master自動轉移到其它Node節點上。
Node節點上運行著如下進程:
kubelet: Kubelet是在每個Node節點上運行agent,是Node節點上面最重要的模塊,它負責維護和管理該Node上面的所有容器,但是Kubelet不會管理不是由Kubernetes創建的容器。本質上,它負責使Pod得運行狀態與期望的狀態一致。Kubelet會定時向Master匯報自己當前的自身信息,如操作系統,Docker版本,CPU,內存,pod運行狀態等信息。
kube-proxy:該模塊實現了Kubernetes中的服務發現和反向代理功能。反向代理支持TCP和UDP連接轉發,默認基於Round Robin算法將客戶端流量轉發到與service對應的一組後端pod。服務發現方面,kube-proxy使用etcd的watch機制,監控集群中service和endpoint對象數據的動態變化,並且維護一個service到endpoint的映射關系,從而保證了後端pod的IP變化不會對訪問者造成影響。
runtime: 這裏一般使用docker 容器,Kubernetes也支持其他的容器。
Node節點的狀態管理
1、通過在Master查看Node狀態:
[root@node-1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
node-1 Ready master 22h v1.10.2
node-2 Ready <none> 22h v1.10.2
node-3 Ready <none> 1h v1.10.2
2、查看Node的詳細信息,如下命令會輸出節點當前狀態的詳細信息,包括可用資源總量:
kubectl describe node node-2
Pod
Pod是Kubernetes中非常重要的基本單位。Pod是應用運行的載體,整個Kubernetes系統都是圍繞著Pod展開的,比如如何部署運行Pod、如何保證Pod的數量、如何訪問Pod等。Pod是一個或多個容器的集合。
在每一個Pod中都有一個特殊的Pause容器和一個或多個業務容器,Pause來源於pause-amd64鏡像,Pause容器在Pod中具有非常重要的作用:
- Pause容器作為Pod容器的根容器,其本地於業務容器無關,它的狀態代表了整個pod的狀態。
- Pod裏的多個業務容器共享Pause容器的IP,每個Pod被分配一個獨立的IP地址,Pod中的每個容器共享網絡命名空間,包括IP地址和網絡端口。Pod內的容器可以使用localhost相互通信。k8s支持底層網絡集群內任意兩個Pod之間進行通信。
- Pod中的所有容器都可以訪問共享volumes,允許這些容器共享數據。volumes 還用於Pod中的數據持久化,以防其中一個容器需要重新啟動而丟失數據。
Pod 的定義
Kubernetes中所有的資源對象都可以采用YAML或者JSON格式的文件來定義,比如,我們可以定義如下的Pod對象:
apiVersion: v1
kind: Pod
metadata:
name: myweb
labels:
name: myweb
spec:
containers:
- name: myweb
image: kubeguide/tomcat-app:v1
ports:
- containerPort: 8080
env:
- name: MYSQL_SERVER_HOST
value: ‘mysql‘
- name: MYSQL_SERVER_PORT
value: ‘3306‘
2、Pod Volume可以使用分布式文件系統,將Pod Volume定義在Pod上,然後被各個容器掛載到自身的容器。目前Kubernetes支持多種文件存儲。
3、我們還可以對pod使用的資源進行配額,一般是對CPU和內存的限制:
apiVersion: v1
kind: Pod
metadata:
name: mysql
labels:
name: mysql
spec:
containers:
- name: db
image: mysql
resources:
requests: # 最小資源申請量
memory: "64Mi" # 64M內存
cpu: "250m" # 0.25個CPU
limits: # 最大配額
memory: "128Mi" # 128M 內存
cpu: "500m" # 0.5個CPU
4、 Pod 常用操作:
kubectl create -f pod_file.yaml # 創建pod
kubectl describe pods POD_NAME # 查看pod詳細信息
kubectl get pods # pods 列表
kubectl delete pod POD_NAME # 刪除pod
kubectl replace pod_file.yaml # 更新pod
Label
Label 是用戶自定義的鍵值對,主要是用於標記資源對象,如Node,Pod,Service,RC等。一個資源可以定義任意數量的Label,同一個Label也可以被添加到任意數量的資源對象上去,Label 通常在資源對象定義時確定,也可以在對象創建後動態的添加或刪除。
可以給資源對象綁定多個不同Label,來實現多維度的資源分組管理功能,一些常見的Label示例:
- 版本標簽:"release":"stable","release":"beta"
- 環境標簽:“environment”:"dev" , "environment":"qa" , "environment":"production"
提示:Deployment,ReplicaSet,DaemonSet和Job等管理對象可以在Selector中使用基於集合的篩選條件定義。
Label Selector (標簽選擇器) ,主要用於對擁有某些Label的資源對象進行查詢和篩選,類似SQL的查詢機制。
Label Selector可以通過基於等式和集合的查詢方式進行匹配查詢,通過多個表達式的組合,從而實現復雜的條件選擇,如:
name=mysql,env!=production
name notin (tomcat),env!=productionReplication Controller
Replication Controller(RC)是Kubernetes中的另一個核心概念,Kubernetes中通過RC來保證應用能夠持續運行,它會確保任何時間Kubernetes中都有指定數量的Pod處於運行狀態。在此基礎上,RC還提供了一些更高級的特性,比如滾動升級、升級回滾等。
RC在Kubernetes中定義了一個期望的場景,即聲明某種pod副本數量在任意時刻符合某個預期的值,其定義的內容如下:
- Pod 期待的副本數(replicas)
- 用於篩選目標Pod的Label Selector.
- 當Pod 的副本數量小於預期的數量時,用於創建新的Pod
RC運行過程: 當我們定義了一個RC的YAML文件(或者調用kubectl命令)提交到Kubernets集群後,Master 上的Controller Manager組件就得到通知,定期巡檢系統中當前存活的目標Pod,並確保目標Pod實例的數量剛好鄧毅此RC的期望值。如果有過多的Pod副本在運行,系統就會停掉一些Pod,反之則會自動創建一些Pod。
自動伸縮
通過修改RC數量,實現Pod的動態縮放:
kubectl scale rc myweb --replicas=10 # 將pod 擴展到10個
kubectl scale rc myweb --replicas=1 # 將pod 縮到 1個
滾動升級
使用RC可以進行動態平滑升級,保證業務始終在線。其具體實現方式:
kubectl rolling-update my-rcName-v1 -f my-rcName-v2-rc.yaml --update-period=10s升級開始後,首先依據提供的定義文件創建V2版本的RC,然後每隔10s(--update-period=10s)逐步的增加V2版本的Pod副本數,逐步減少V1版本Pod的副本數。升級完成之後,刪除V1版本的RC,保留V2版本的RC,及實現滾動升級。
升級過程中,發生了錯誤中途退出時,可以選擇繼續升級。Kubernetes能夠智能的判斷升級中斷之前的狀態,然後緊接著繼續執行升級。當然,也可以進行回退,命令如下:
kubectl rolling-update my-rcName-v1 -f my-rcName-v2-rc.yaml --update-period=10s --rollbackReplicaSet
replica set,可以被認為 是“升級版”的Replication Controller。replica set也是用於保證與label selector匹配的pod數量維持在期望狀態。區別在於,replica set引入了對基於子集的selector查詢條件,而Replication Controller僅支持基於值相等的selecto條件查詢。replica set很少被單獨使用,目前它多被Deployment用於進行pod的創建、更新與刪除的編排機制。
RC(Replica Set)特性和作用
- 通過定義一個RC實現Pod的創建過程及副本數量的自動控制。
- RC 裏包括完整的Pod定義模板。
- RC通過Label Selector 機制是對Pod副本的自動控制。
- 通過改變RC的副本數量,可以實現Pod副本的擴容和縮容。
- 通過改變RC裏Pod模板中的鏡像版本,可以實現Pod滾動升級。
Deployment
Deployment主要職責同樣是為了保證pod的數量和健康,90%的功能與Replication Controller完全一樣,可以看做新一代的Replication Controller。Deployment內部使用了Replica Set來實現。
Deployment 相對於RC一個最大的升級是我們可以隨時知道當前Pod "部署"的進度,和詳細的運行狀態。
具有以下使用場景:
創建Pod: 可以創建一個Deployment對象來生成對應的Replica Set,完成Pod副本的創建。
查看事件狀態: 通過檢查Deployment的狀態來查看部署動作是否完成,如副本數量是否達到了預期的值。
升級:更新Deployment以創建新的Pod,同時還可以清理不再需要的舊版本ReplicaSet。
回滾: 如果當前的Pod不穩定或者有bug,可以回滾到一個早期的穩定版本。
暫停和恢復:可以隨時暫停Deployment對象,修改對應的參數配置,之後再恢復Deployment繼續發布。
Deployment 定義
Deployment的定義和Replica Set的定義幾乎一樣,僅僅是API版本和kind類型不同:
# Deployment的聲明
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
# Replica Set的聲明
apiVersion: v1
kind: ReplicaSet
metadata:
name: mysql
...
創建一個deployment
1、這裏以上面的nginx為例,創建nginx:
[root@node-1 ~]# kubectl create -f nginx.yaml
deployment.apps "nginx-deployment" created
2、查看Deployment信息:
# 剛執行時,顯示的AVAILABLE數量時0
[root@node-1 ~]# kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 3 3 3 0 22s
# 1分鐘後顯示已經有3個可用nginx-deployment
[root@node-1 ~]# kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 3 3 3 3 1m
# 查看pods
[root@node-1 ~]# kubectl get pods | grep nginx
nginx-deployment-666865b5dd-cfmfp 1/1 Running 0 11m
nginx-deployment-666865b5dd-nhxtv 1/1 Running 0 11m
nginx-deployment-666865b5dd-qj7sf 1/1 Running 0 11m
# 查看 rs
[root@node-1 ~]# kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-666865b5dd 3 3 3 25m
# 查看deployments的詳細部署信息
[root@node-1 ~]# kubectl describe deployments
...
對於上述kubectl get deployments的輸出,其含義:
- DESIRED : Pod副本數量的期望值,即Deployment裏定義的Replica。
- CURRENT: 當前實際的Replica數量,當這個值不斷增加,達到DESIRED時表明部署完成。
- UP-TO-DATE:最新版本的Pod副本數量,用於指示在滾動升級過程中有多少Pod副本已經成功升級。
- AVAILABLE: 當前集群中可用的Pod副本數量(當前存活的Pod數量)
使用kubectl describe deployments命令可以獲取指定Deployment的詳細狀態
滾動升級
例如,我們要對當前的nginx-deployment進行升級或者回滾,可以使用如下兩種方式。
* 直接 set 鏡像
1、若要對docker鏡像進行更新,直接 set 鏡像:
[root@node-1 ~]# kubectl set image deployment/nginx-deployment nginx=nginx:1.12.2
2、查看狀態,可以發現在保證pod 可用的狀態下,會平滑的替換舊的deployment對象,並且會記錄此過程:
[root@node-1 ~]# kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 3 4 1 3 3h
[root@node-1 ~]# kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 3 4 2 3 3h
[root@node-1 ~]# kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 3 3 3 3 4h
[root@node-1 ~]# kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-666865b5dd 0 0 0 4h
nginx-deployment-69647c4bc6 3 3 3 3m
[root@node-1 ~]# kubectl describe deployments # 會顯示詳細events事件* 直接edit Deployment
1、執行 edit命令修改Deployment配置,類似KVM的virsh edit 命令,修改後立即生效(如果沒有修改,將不會發生任何變化):
[root@node-1 ~]# kubectl edit deployments/nginx-deployment
2、查看deployment狀態:
[root@node-1 ~]# kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 3 4 1 3 5h
[root@node-1 ~]# kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 3 4 3 3 5h
[root@node-1 ~]# kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 3 3 3 3 5h3、一般常見的修改是修改鏡像版本和參數。
回滾
1、執行回滾命令,到上一個版本:
[root@node-1 ~]# kubectl rollout undo deployment/nginx-deployment
2、使用如下命令,可以查看保存的deployment歷史:
[root@node-1 ~]# kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-666865b5dd 0 0 0 5h
nginx-deployment-68dfb7c95b 3 3 3 27m
nginx-deployment-69647c4bc6 0 0 0 1h
命令參考
- kubectl describe deployments #查詢詳細信息,獲取升級進度
- kubectl get deployments # 獲取升級進度的簡略信息
- kubectl get rs # 獲取RS記錄,每執行一次deployment就會生成一個RS記錄。
- kubectl set image deployment/nginx-deployment nginx=nginx:1.12.2 # 升級
- kubectl edit deployments/nginx-deployment # 修改deployment 參數
- kubectl rollout pause deployment/nginx-deployment #暫停升級
- kubectl rollout resume deployment/nginx-deployment #繼續升級
- kubectl rollout undo deployment/nginx-deployment #回滾到上一版本
- kubectl scale deployment nginx-deployment --replicas 10 #彈性伸縮Pod數量
Service
Service是Kubernetes中的核心對象之一。Kubernetes中的Pod,RC,等資源對象最終都是為Service服務。
Service定義了一個服務訪問的入口地址,前端應用Pod通過這個地址訪問後端的Pod集群實例,Service通過Label Selector來實現與後端Pod集群的通訊。其中,RC的作用是保障集群中始終有可用的Pod集群,從而確保了服務質量。
Service原理
Service的服務原理圖:
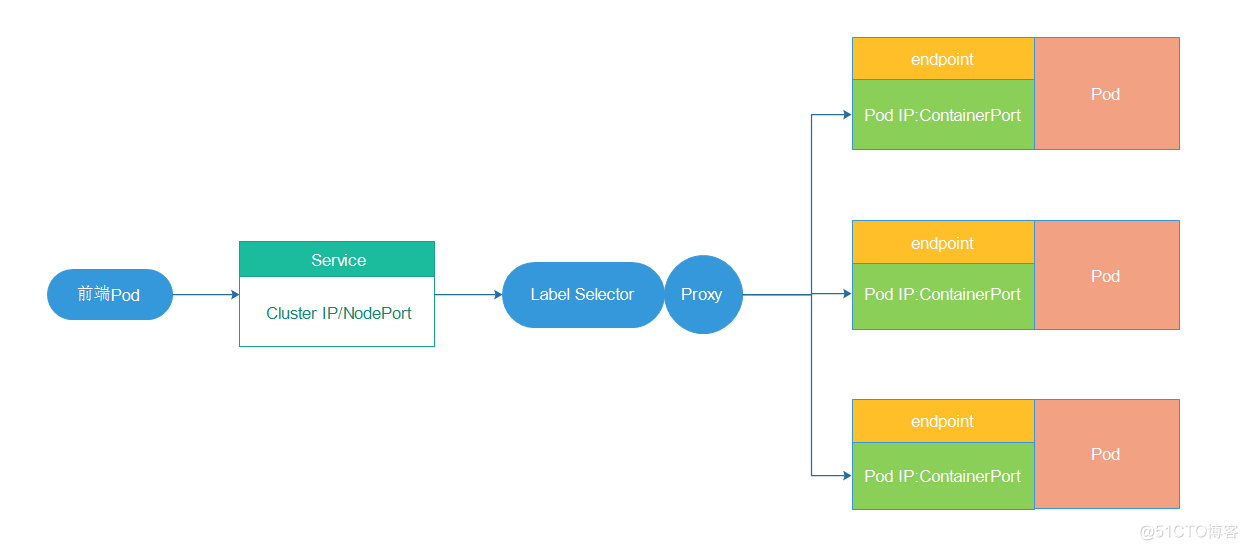
在上圖中,我們需要理解以下幾點:
- Service其實就是一個對外的服務接口,當我們創建一個service時,k8s會自動創建一個全局唯一的Cluster IP,這個IP是一個虛擬的IP,如果嘗試使用PING是無法ping通的,但是,它是連通前端Pod和後端服務Pod的橋梁,雖然不能ping通,但是可以通過IP+端口的方式訪問後端Pod。後端的Pod組成了一個集群,通過RC的控制來提供永不間斷的服務。
- 在Service的整個生命周期內,Cluster IP不會發生改變,Service Name與Cluster IP形成固定的映射關系(這裏一般使用的是DNS,早期使用的是環境變量的方式),這樣就不存在服務發現的問題。
-
Service的Cluster IP和Endpoint屬於Kubernetes集群內部的地址,無法在集群外部使用,一般會使用Flannel、Weave、Romana等第三方網絡服務來實現Pod之間的通訊。這裏涉及網絡的部分我們會在後續的博文中單獨討論。
- Kubernetes在每個Node節點上都運行著一個kube-proxy的進程,它扮演了負載均衡器的角色,它負責將對service的請求轉發到後端的某個Pod實例上,並在內部實現了負載均衡和會話保持的機制。
外部訪問Service
由於Cluster IP是一個內部地址,外部的node 節點無法直接訪問到,當我們的外部用戶需要訪問這些服務時,需要在定義Service時添加NodePort的擴展。下面的文件定義了一個nginx服務添加外部NodePort的示例。
編輯service文件:
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
type: NodePort
ports:
- port: 80
nodePort: 30008 # 對外的用戶訪問端口,默認範圍是30000-32767
selector:
app: nginx
當我們創建這個service後,所有的節點上都會有30008的端口映射,訪問任意節點都會轉發到對應的Pod集群中。
命令參考
- kubectl get services # 獲取service列表,可以指定具體的service
- kubectl describe services # 顯示service的詳細信息,可以指定具體的service
- kubectl get endpoints # 獲取Endpoint 信息
- kubectl delete services mysql # 刪除指定的service
Volume
在Kubernetes中,Volume是能被Pod中多個容器訪問的共享目錄。由於Pod中的容器隨時可能會被銷毀或重建,對於一些需要數據共享或要持久化保存的數據,我們需要使用單獨的存儲空間,掛載到對應的Pod上。當容器終止時,Volume中的數據不會丟失。
Volume的定義格式:
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: k8s.gcr.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /cache
name: cache-volume
volumes:
- name: cache-volume
emptyDir: {} # 指定Volume類型Kubernetes支持多種類型的Volume,下面會對一些常見的Volume做出說明。
本地存儲
- emptyDir: 無需指定宿主機的對應目錄路徑,由Pod自動創建,Pod移除時數據會永久刪除,作為容器間的共享目錄。上面的示例就是此格式的Volume。
- hostPath: Pod掛載宿主機上的文件和目錄,可用於永久保存日誌,容器內部訪問宿主機數據,定義方式如下:
apiVersion: v1 kind: Pod metadata: name: test-pd spec: containers: - image: k8s.gcr.io/test-webserver name: test-container volumeMounts: - mountPath: /test-pd name: test-volume volumes: - name: test-volume hostPath: # directory location on host path: /data # this field is optional type: Directory
網絡存儲
- gce Persistemt Disk: 谷歌公有雲提供的永久磁盤,這裏要求使用谷歌的公有雲,節點是GCE虛擬機才行。
- AWS Elastic Block Store: 與GCE類似,此類型的Volume使用亞馬遜公有雲提供的EBS數據存儲。
- NFS: NFS網絡文件系統的數據存儲,這個需要部署NFS服務器,定義如下:
volumes:
- name: nfs
nfs:
server: NFS-SERVER-IP # NFS 服務器地址
path: "/"- iscsi: 使用iSCSI存儲設備上的目錄掛載到Pod中。
- glusterfs: 使用GlusterFS掛載到Pod中。
- rbd: 使用Ceph對象存儲掛載到Pod。
除此之外,Kubernetes還支持其他的存儲方式,具體詳情可以查看官方文檔。
Persistent Volume
理解並管理五花八門的存儲是一件讓人頭疼的事情,Kubernetes為了解決這些問題,對所有的網絡存儲進行了抽象,讓我們在管理這些存儲時不必考慮後端的實現細節,對於不同的網絡存儲統一使用一套相同的管理手段。
PersistentVolume為用戶和管理員提供了一個API,它抽象了如何提供存儲以及如何使用它的細節。 為此,引入兩個新的API資源:PersistentVolume和PersistentVolumeClaim。
PersistentVolume(PV): 是管理員設置的單獨的網絡存儲集群,它不屬於任何節點,但是可以被每個節點訪問。 PV是Volumes之類的卷插件,具有獨立於的生命周期。 此API對象用於捕獲存儲實現的細節,如NFS,iSCSI,GlusterFS,CephFS或特定於雲提供程序的存儲系統。
PersistentVolumeClaim(PVC):是用戶對存儲的請求的定義。 它與pod相似。pods消耗節點資源,PVC消耗PV資源, Pods可以請求特定級別的資源(CPU和內存)。Claim可以配置特定的存儲資源大小和訪問模式(例如,多種不同的讀寫權限),並根據用戶定義的需求去使用合適的Persistent Volume。
定義Persistent Volume
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv1
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
nfs:
path: /somepath
server: 10.2.2.2
accessModes有三種權限:
- ReadWriteOnce:讀寫權限,只能被單個Node掛載
- ReadOnlyMany: 只讀權限,允許被多個Node掛載
- ReadWriteMany: 讀寫權限、允許被多個Node掛載。
定義Persistent Volume Claim
如果某個Pod想申請某種類型的PV,可以做如下定義:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: myclaim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
stroage: 8Gi
定義之後再Pod的Volume中引用上述PVC:
volumes:
- name: mypd
persistentVolumeClaim:
claimName: myclaimPV的狀態
PV是有狀態的對象,有如下幾種狀態:
- Available: 空閑狀態
- Bound: 已經綁定到某個PVC上
- Released: 對應的PVC已經刪除,但是資源還沒有被釋放
- Failed: PV自動回收失敗
Namespace
Namespace(命名空間)是Kubernetes中非常重要的概念,Namespace在很多情況下實現多租戶的資源隔離,將集群中的不同資源對象分配到不同的Namespace中,形成邏輯上分組的不同項目,便於不同分組在使用集群資源的同時還能被分別管理。
Kubernetes在啟動之後,默認會創建一個default的Namespace:
[root@node-1 ~]# kubectl get namespaces
NAME STATUS AGE
default Active 3d
當我們創建對象時,不指定namespace就會使用默認的default:
[root@node-1 ~]# kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
default mysql-fw2pj 1/1 Running 2 1d
default myweb-4jk8j 1/1 Running 2 1d
default myweb-68zfl 1/1 Running 2 1d
default myweb-bv8pt 1/1 Running 2 1d
default nginx-deployment-68dfb7c95b-6zcj4 1/1 Running 2 1d
default nginx-deployment-68dfb7c95b-g89nd 1/1 Running 3 1d
default nginx-deployment-68dfb7c95b-zvtkf 1/1 Running 2 1d
kube-system etcd-node-1 1/1 Running 7 3d
...
Namespace的定義
使用yaml文件定義一個名為deployment的Namespace:
apiVersion: v1
kind: Namespace
metadata:
name: deployment
當創建對象時,就可以指定這個資源對象屬於哪個Namespace:
apiVersion: v1
kind: Pod
metadata:
name: myweb
namespace: development
當我們指定非默認的namespace之後,使用如下命令就只能查看默認區域的namespaces:
# kubectl get pods查看所有namespace區域的對象要使用--all-namespaces參數:
# kubectl get pods --all-namespaces
#也可以指定namespaces:
# kubectl get pods --namespace=kube-system
Horizontal Pod Autoscaler
HPA與之前介紹的RC,deployment一樣,也是屬於Kubernetes的一種資源對象。HPA通過追蹤分析RC控制的所有目標Pod的負載變化情況,來確定是否需要針對性的調整目標Pod的副本數。HPA有以下兩種方式來度量Pod的負載情況:
- CPU Utilization Percentage: CPU利用率百分比
- 自定義的度量指標
CPU的利用率百分比通常是度量的Pod CPU 1min內的平均值,使用Heapster擴展組件來得到這個值,這裏定義一個簡單的例子:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: myweb
namespace: default
spec:
maxReplicas: 10
minReplicas: 2
scaleTargetRef:
kind: Deployment
name: myweb
targetCPUUtilizationPercentage: 90當Pod 副本的CPU利用率超過90%時會觸發自動擴容行為,且Pod數量最多不能超過10,最少不能低於2.
除此之外,也可以使用命令操作:
kubectl autoscale deployment myweb --cpu-percent=90 --min=1 --max=10StatefulSet
在Kubernetes系統中,Pod管理的對象如 RC,Deployment,DaemonSet 和Job 都是面向無狀態的服務。對於無狀態的服務我們可以任意銷毀並在任意節點重建,但是在實際的應用中,很多服務是有狀態的,特別是對於復雜的中間件集群,如Mysql集群,MongoDB集群,Zookeeper集群,etcd集群等,這些服務都有固定的網絡標識,並有持久化的數據存儲,這就需要使用StatefulSet對象。
StatefulSet具有以下特性:
- StatefulSet裏的每個Pod都有穩定且唯一的網絡標識, 可以用來發現網絡中的其他成員。
- StatefulSet 控制的Pod副本的啟停順序是受控的,比如操作第n個Pod時,前n-1個Pod必須是正常運行的狀態。
- Pod 采用穩定的持久化存儲卷,刪除Pod時默認不會刪除與StatefulSet相關的儲存卷。
參考資料:
https://kubernetes.io/docs/concepts/
https://www.cnblogs.com/zhenyuyaodidiao/p/6500720.html
《Kubernets權威指南》
Kubernetes 核心概念簡介