
Kubernetes核心概念總結
1、基礎架構
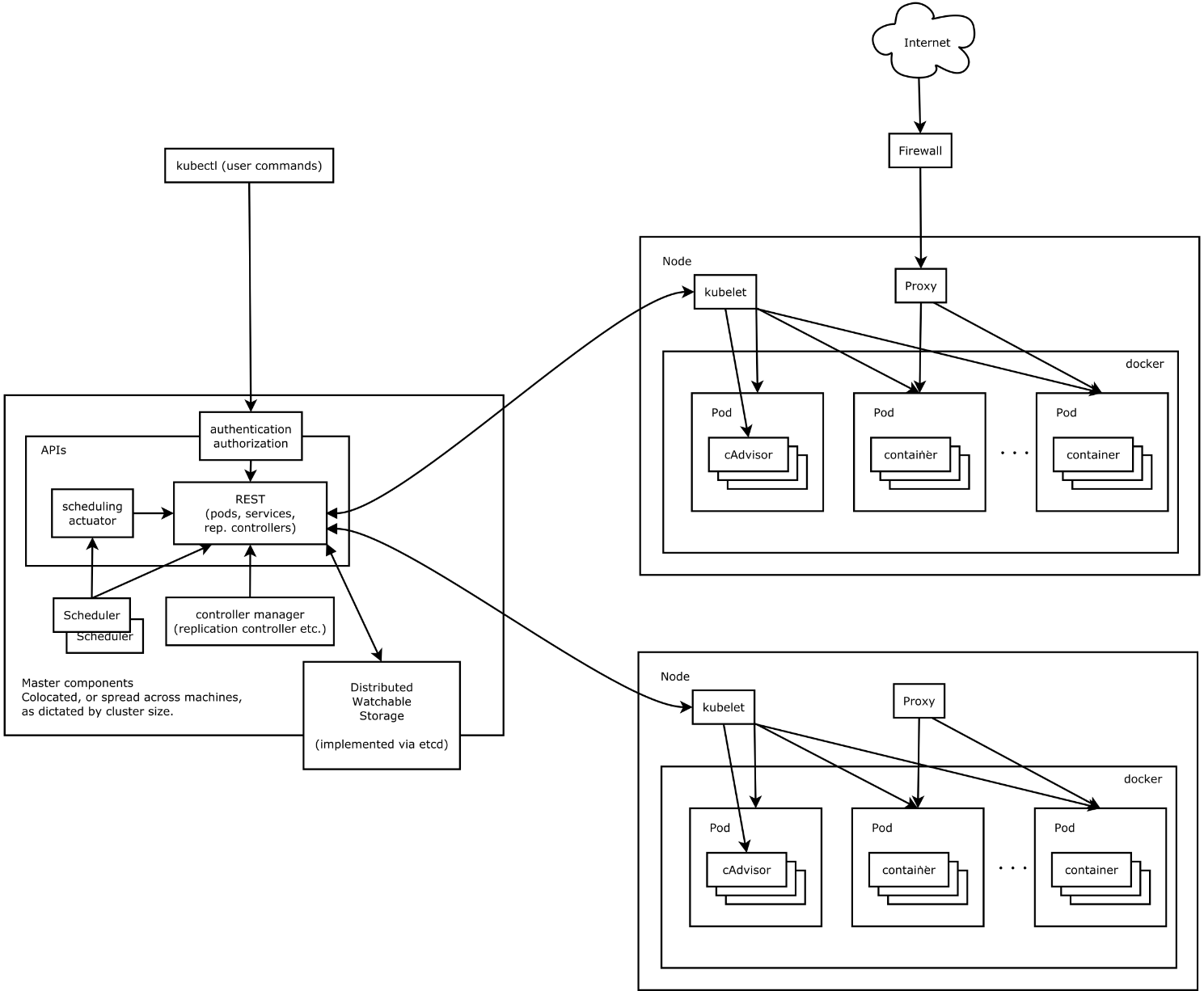
1.1 Master
Master節點上面主要由四個模組組成:APIServer、scheduler、controller manager、etcd。
APIServer。APIServer負責對外提供RESTful的Kubernetes API服務,它是系統管理指令的統一入口,任何對資源進行增刪改查的操作都要交給APIServer處理後再提交給etcd。如架構圖中所示,kubectl(Kubernetes提供的客戶端工具,該工具內部就是對Kubernetes API的呼叫)是直接和APIServer互動的。
schedule。scheduler的職責很明確,就是負責排程pod到合適的Node上。如果把scheduler看成一個黑匣子,那麼它的輸入是pod和由多個Node組成的列表,輸出是Pod和一個Node的繫結,即將這個pod部署到這個Node上。Kubernetes目前提供了排程演算法,但是同樣也保留了介面,使用者可以根據自己的需求定義自己的排程演算法。
controller manager。如果說APIServer做的是“前臺”的工作的話,那controller manager就是負責“後臺”的。每個資源一般都對應有一個控制器,而controller manager就是負責管理這些控制器的。比如我們通過APIServer建立一個pod,當這個pod建立成功後,APIServer的任務就算完成了。而後面保證Pod的狀態始終和我們預期的一樣的重任就由controller manager去保證了。
etcd。etcd是一個高可用的鍵值儲存系統,Kubernetes使用它來儲存各個資源的狀態,從而實現了Restful的API。
1.2 Node
每個Node節點主要由三個模組組成:kubelet、kube-proxy、runtime。
runtime。runtime指的是容器執行環境,目前Kubernetes支援docker和rkt兩種容器。
kube-proxy。該模組實現了Kubernetes中的服務發現和反向代理功能。反向代理方面:kube-proxy支援TCP和UDP連線轉發,預設基於Round Robin演算法將客戶端流量轉發到與service對應的一組後端pod。服務發現方面,kube-proxy使用etcd的watch機制,監控叢集中service和endpoint物件資料的動態變化,並且維護一個service到endpoint的對映關係,從而保證了後端pod的IP變化不會對訪問者造成影響。另外kube-proxy還支援session affinity。
kubelet。Kubelet是Master在每個Node節點上面的agent,是Node節點上面最重要的模組,它負責維護和管理該Node上面的所有容器,但是如果容器不是通過Kubernetes建立的,它並不會管理。本質上,它負責使Pod得執行狀態與期望的狀態一致。
至此,Kubernetes的Master和Node就簡單介紹完了。下面我們來看Kubernetes中的各種資源/物件。
2、Pod
Pod 是Kubernetes的基本操作單元,也是應用執行的載體。整個Kubernetes系統都是圍繞著Pod展開的,比如如何部署執行Pod、如何保證Pod的數量、如何訪問Pod等。另外,Pod是一個或多個機關容器的集合,這可以說是一大創新點,提供了一種容器的組合的模型。
2.1 基本操作
|
建立 |
kubectl create -f xxx.yaml |
|
查詢 |
kubectl get pod yourPodName kubectl describe pod yourPodName |
|
刪除 |
kubectl delete pod yourPodName |
|
更新 |
kubectl replace /path/to/yourNewYaml.yaml |
2.2 Pod與容器
在Docker中,容器是最小的處理單元,增刪改查的物件是容器,容器是一種虛擬化技術,容器之間是隔離的,隔離是基於Linux Namespace實現的。而在Kubernetes中,Pod包含一個或者多個相關的容器,Pod可以認為是容器的一種延伸擴充套件,一個Pod也是一個隔離體,而Pod內部包含的一組容器又是共享的(包括PID、Network、IPC、UTS)。除此之外,Pod中的容器可以訪問共同的資料捲來實現檔案系統的共享。
2.3 映象
在kubernetes中,映象的下載策略為:
Always:每次都下載最新的映象
Never:只使用本地映象,從不下載
IfNotPresent:只有當本地沒有的時候才下載映象
Pod被分配到Node之後會根據映象下載策略進行映象下載,可以根據自身叢集的特點來決定採用何種下載策略。無論何種策略,都要確保Node上有正確的映象可用。
2.4 其他設定
通過yaml檔案,可以在Pod中設定:
啟動命令,如:spec-->containers-->command;
環境變數,如:spec-->containers-->env-->name/value;
埠橋接,如:spec-->containers-->ports-->containerPort/protocol/hostIP/hostPort(使用hostPort時需要注意埠衝突的問題,不過Kubernetes在排程Pod的時候會檢查宿主機埠是否衝突,比如當兩個Pod均要求繫結宿主機的80埠,Kubernetes將會將這兩個Pod分別排程到不同的機器上);
Host網路,一些特殊場景下,容器必須要以host方式進行網路設定(如接收物理機網路才能夠接收到的組播流),在Pod中也支援host網路的設定,如:spec-->hostNetwork=true;
資料持久化,如:spec-->containers-->volumeMounts-->mountPath;
重啟策略,當Pod中的容器終止退出後,重啟容器的策略。這裡的所謂Pod的重啟,實際上的做法是容器的重建,之前容器中的資料將會丟失,如果需要持久化資料,那麼需要使用資料捲進行持久化設定。Pod支援三種重啟策略:Always(預設策略,當容器終止退出後,總是重啟容器)、OnFailure(當容器終止且異常退出時,重啟)、Never(從不重啟);
2.5 Pod生命週期
Pod被分配到一個Node上之後,就不會離開這個Node,直到被刪除。當某個Pod失敗,首先會被Kubernetes清理掉,之後ReplicationController將會在其它機器上(或本機)重建Pod,重建之後Pod的ID發生了變化,那將會是一個新的Pod。所以,Kubernetes中Pod的遷移,實際指的是在新Node上重建Pod。以下給出Pod的生命週期圖。
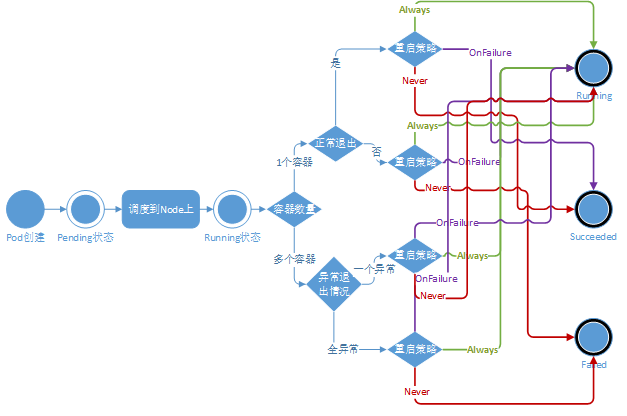
生命週期回撥函式:PostStart(容器建立成功後調研該回調函式)、PreStop(在容器被終止前呼叫該回調函式)。以下示例中,定義了一個Pod,包含一個JAVA的web應用容器,其中設定了PostStart和PreStop回撥函式。即在容器建立成功後,複製/sample.war到/app資料夾中。而在容器終止之前,傳送HTTP請求到http://monitor.com:8080/waring,即向監控系統傳送警告。具體示例如下:

………..
containers:
- image: sample:v2
name: war
lifecycle:
posrStart:
exec:
command:
- “cp”
- “/sample.war”
- “/app”
prestop:
httpGet:
host: monitor.com
psth: /waring
port: 8080
scheme: HTTP
3、Replication Controller
Replication Controller(RC)是Kubernetes中的另一個核心概念,應用託管在Kubernetes之後,Kubernetes需要保證應用能夠持續執行,這是RC的工作內容,它會確保任何時間Kubernetes中都有指定數量的Pod在執行。在此基礎上,RC還提供了一些更高階的特性,比如滾動升級、升級回滾等。
3.1 RC與Pod的關聯——Label
RC與Pod的關聯是通過Label來實現的。Label機制是Kubernetes中的一個重要設計,通過Label進行物件的弱關聯,可以靈活地進行分類和選擇。對於Pod,需要設定其自身的Label來進行標識,Label是一系列的Key/value對,在Pod-->metadata-->labeks中進行設定。
Label的定義是任一的,但是Label必須具有可標識性,比如設定Pod的應用名稱和版本號等。另外Lable是不具有唯一性的,為了更準確的標識一個Pod,應該為Pod設定多個維度的label。如下:
"release" : "stable", "release" : "canary"
"environment" : "dev", "environment" : "qa", "environment" : "production"
"tier" : "frontend", "tier" : "backend", "tier" : "cache"
"partition" : "customerA", "partition" : "customerB"
"track" : "daily", "track" : "weekly"
舉例,當你在RC的yaml檔案中定義了該RC的selector中的label為app:my-web,那麼這個RC就會去關注Pod-->metadata-->labeks中label為app:my-web的Pod。修改了對應Pod的Label,就會使Pod脫離RC的控制。同樣,在RC執行正常的時候,若試圖繼續建立同樣Label的Pod,是建立不出來的。因為RC認為副本數已經正常了,再多起的話會被RC刪掉的。
3.2 彈性伸縮
彈性伸縮是指適應負載變化,以彈性可伸縮的方式提供資源。反映到Kubernetes中,指的是可根據負載的高低動態調整Pod的副本數量。調整Pod的副本數是通過修改RC中Pod的副本是來實現的,示例命令如下:
擴容Pod的副本數目到10
$ kubectl scale relicationcontroller yourRcName --replicas=10
縮容Pod的副本數目到1
$ kubectl scale relicationcontroller yourRcName --replicas=1
3.3 滾動升級
滾動升級是一種平滑過渡的升級方式,通過逐步替換的策略,保證整體系統的穩定,在初始升級的時候就可以及時發現、調整問題,以保證問題影響度不會擴大。Kubernetes中滾動升級的命令如下:
$ kubectl rolling-update my-rcName-v1 -f my-rcName-v2-rc.yaml --update-period=10s
升級開始後,首先依據提供的定義檔案建立V2版本的RC,然後每隔10s(--update-period=10s)逐步的增加V2版本的Pod副本數,逐步減少V1版本Pod的副本數。升級完成之後,刪除V1版本的RC,保留V2版本的RC,及實現滾動升級。
升級過程中,發生了錯誤中途退出時,可以選擇繼續升級。Kubernetes能夠智慧的判斷升級中斷之前的狀態,然後緊接著繼續執行升級。當然,也可以進行回退,命令如下:
$ kubectl rolling-update my-rcName-v1 -f my-rcName-v2-rc.yaml --update-period=10s --rollback
回退的方式實際就是升級的逆操作,逐步增加V1.0版本Pod的副本數,逐步減少V2版本Pod的副本數。
3.4 新一代副本控制器replica set
這裡所說的replica set,可以被認為 是“升級版”的Replication Controller。也就是說。replica set也是用於保證與label selector匹配的pod數量維持在期望狀態。區別在於,replica set引入了對基於子集的selector查詢條件,而Replication Controller僅支援基於值相等的selecto條件查詢。這是目前從使用者角度餚,兩者唯一的顯著差異。 社群引入這一API的初衷是用於取代vl中的Replication Controller,也就是說.當v1版本被廢棄時,Replication Controller就完成了它的歷史使命,而由replica set來接管其工作。雖然replica set可以被單獨使用,但是目前它多被Deployment用於進行pod的建立、更新與刪除。Deployment在滾動更新等方面提供了很多非常有用的功能,關於DeplOymCn的更多資訊,讀者們可以在後續小節中獲得。
4、Job
從程式的執行形態上來區分,我們可以將Pod分為兩類:長時執行服務(jboss、mysql等)和一次性任務(資料計算、測試)。RC建立的Pod都是長時執行的服務,而Job建立的Pod都是一次性任務。
在Job的定義中,restartPolicy(重啟策略)只能是Never和OnFailure。Job可以控制一次性任務的Pod的完成次數(Job-->spec-->completions)和併發執行數(Job-->spec-->parallelism),當Pod成功執行指定次數後,即認為Job執行完畢。
5、Service
為了適應快速的業務需求,微服務架構已經逐漸成為主流,微服務架構的應用需要有非常好的服務編排支援。Kubernetes中的核心要素Service便提供了一套簡化的服務代理和發現機制,天然適應微服務架構。
5.1 原理
在Kubernetes中,在受到RC調控的時候,Pod副本是變化的,對於的虛擬IP也是變化的,比如發生遷移或者伸縮的時候。這對於Pod的訪問者來說是不可接受的。Kubernetes中的Service是一種抽象概念,它定義了一個Pod邏輯集合以及訪問它們的策略,Service同Pod的關聯同樣是居於Label來完成的。Service的目標是提供一種橋樑, 它會為訪問者提供一個固定訪問地址,用於在訪問時重定向到相應的後端,這使得非 Kubernetes原生應用程式,在無須為Kubemces編寫特定程式碼的前提下,輕鬆訪問後端。
Service同RC一樣,都是通過Label來關聯Pod的。當你在Service的yaml檔案中定義了該Service的selector中的label為app:my-web,那麼這個Service會將Pod-->metadata-->labeks中label為app:my-web的Pod作為分發請求的後端。當Pod發生變化時(增加、減少、重建等),Service會及時更新。這樣一來,Service就可以作為Pod的訪問入口,起到代理伺服器的作用,而對於訪問者來說,通過Service進行訪問,無需直接感知Pod。
需要注意的是,Kubernetes分配給Service的固定IP是一個虛擬IP,並不是一個真實的IP,在外部是無法定址的。真實的系統實現上,Kubernetes是通過Kube-proxy元件來實現的虛擬IP路由及轉發。所以在之前叢集部署的環節上,我們在每個Node上均部署了Proxy這個元件,從而實現了Kubernetes層級的虛擬轉發網路。
5.2 Service代理外部服務
Service不僅可以代理Pod,還可以代理任意其他後端,比如執行在Kubernetes外部Mysql、Oracle等。這是通過定義兩個同名的service和endPoints來實現的。示例如下:
redis-service.yaml
apiVersion: v1
kind: Service
metadata:
name: redis-service
spec:
ports:
- port: 6379
targetPort: 6379
protocol: TCP
redis-endpoints.yaml
apiVersion: v1
kind: Endpoints
metadata:
name: redis-service
subsets:
- addresses:
- ip: 10.0.251.145
ports:
- port: 6379
protocol: TCP
基於檔案建立完Service和Endpoints之後,在Kubernetes的Service中即可查詢到自定義的Endpoints。
[[email protected] demon]# kubectl describe service redis-service Name: redis-service Namespace: default Labels: <none> Selector: <none> Type: ClusterIP IP: 10.254.52.88 Port: <unset> 6379/TCP Endpoints: 10.0.251.145:6379 Session Affinity: None No events. [[email protected] demon]# etcdctl get /skydns/sky/default/redis-service {"host":"10.254.52.88","priority":10,"weight":10,"ttl":30,"targetstrip":0}
5.3 Service內部負載均衡
當Service的Endpoints包含多個IP的時候,及服務代理存在多個後端,將進行請求的負載均衡。預設的負載均衡策略是輪訓或者隨機(有kube-proxy的模式決定)。同時,Service上通過設定Service-->spec-->sessionAffinity=ClientIP,來實現基於源IP地址的會話保持。
5.4 釋出Service
Service的虛擬IP是由Kubernetes虛擬出來的內部網路,外部是無法定址到的。但是有些服務又需要被外部訪問到,例如web前段。這時候就需要加一層網路轉發,即外網到內網的轉發。Kubernetes提供了NodePort、LoadBalancer、Ingress三種方式。
NodePort,在之前的Guestbook示例中,已經延時了NodePort的用法。NodePort的原理是,Kubernetes會在每一個Node上暴露出一個埠:nodePort,外部網路可以通過(任一Node)[NodeIP]:[NodePort]訪問到後端的Service。
LoadBalancer,在NodePort基礎上,Kubernetes可以請求底層雲平臺建立一個負載均衡器,將每個Node作為後端,進行服務分發。該模式需要底層雲平臺(例如GCE)支援。
Ingress,是一種HTTP方式的路由轉發機制,由Ingress Controller和HTTP代理伺服器組合而成。Ingress Controller實時監控Kubernetes API,實時更新HTTP代理伺服器的轉發規則。HTTP代理伺服器有GCE Load-Balancer、HaProxy、Nginx等開源方案。
5.5 servicede 自發性機制
Kubernetes中有一個很重要的服務自發現特性。一旦一個service被建立,該service的service IP和service port等資訊都可以被注入到pod中供它們使用。Kubernetes主要支援兩種service發現 機制:環境變數和DNS。
環境變數方式
Kubernetes建立Pod時會自動新增所有可用的service環境變數到該Pod中,如有需要.這些環境變數就被注入Pod內的容器裡。需要注意的是,環境變數的注入只發送在Pod建立時,且不會被自動更新。這個特點暗含了service和訪問該service的Pod的建立時間的先後順序,即任何想要訪問service的pod都需要在service已經存在後建立,否則與service相關的環境變數就無法注入該Pod的容器中,這樣先建立的容器就無法發現後建立的service。
DNS方式
Kubernetes叢集現在支援增加一個可選的元件——DNS伺服器。這個DNS伺服器使用Kubernetes的watchAPI,不間斷的監測新的service的建立併為每個service新建一個DNS記錄。如果DNS在整個叢集範圍內都可用,那麼所有的Pod都能夠自動解析service的域名。Kube-DNS搭建及更詳細的介紹請見:基於Kubernetes叢集部署skyDNS服務
5.6 多個service如何避免地址和埠衝突
此處設計思想是,Kubernetes通過為每個service分配一個唯一的ClusterIP,所以當使用ClusterIP:port的組合訪問一個service的時候,不管port是什麼,這個組合是一定不會發生重複的。另一方面,kube-proxy為每個service真正開啟的是一個絕對不會重複的隨機埠,使用者在service描述檔案中指定的訪問埠會被對映到這個隨機埠上。這就是為什麼使用者可以在建立service時隨意指定訪問埠。
5.7 service目前存在的不足
Kubernetes使用iptables和kube-proxy解析service的人口地址,在中小規模的叢集中執行良好,但是當service的數量超過一定規模時,仍然有一些小問題。首當其衝的便是service環境變數氾濫,以及service與使用service的pod兩者建立時間先後的制約關係。目前來看,很多使用者在使用Kubernetes時往往會開發一套自己的Router元件來替代service,以便更好地掌控和定製這部分功能。
6、Deployment
Kubernetes提供了一種更加簡單的更新RC和Pod的機制,叫做Deployment。通過在Deployment中描述你所期望的叢集狀態,Deployment Controller會將現在的叢集狀態在一個可控的速度下逐步更新成你所期望的叢集狀態。Deployment主要職責同樣是為了保證pod的數量和健康,90%的功能與Replication Controller完全一樣,可以看做新一代的Replication Controller。但是,它又具備了Replication Controller之外的新特性:
Replication Controller全部功能:Deployment繼承了上面描述的Replication Controller全部功能。
事件和狀態檢視:可以檢視Deployment的升級詳細進度和狀態。
回滾:當升級pod映象或者相關引數的時候發現問題,可以使用回滾操作回滾到上一個穩定的版本或者指定的版本。
版本記錄: 每一次對Deployment的操作,都能儲存下來,給予後續可能的回滾使用。
暫停和啟動:對於每一次升級,都能夠隨時暫停和啟動。
多種升級方案:Recreate----刪除所有已存在的pod,重新建立新的; RollingUpdate----滾動升級,逐步替換的策略,同時滾動升級時,支援更多的附加引數,例如設定最大不可用pod數量,最小升級間隔時間等等。
6.1 滾動升級
相比於RC,Deployment直接使用kubectl edit deployment/deploymentName 或者kubectl set方法就可以直接升級(原理是Pod的template發生變化,例如更新label、更新映象版本等操作會觸發Deployment的滾動升級)。操作示例——首先 我們同樣定義一個nginx-deploy-v1.yaml的檔案,副本數量為2:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
建立deployment:
$ kubectl create -f nginx-deploy-v1.yaml --record deployment "nginx-deployment" created $ kubectl get deployments NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE nginx-deployment 3 0 0 0 1s $ kubectl get deployments NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE nginx-deployment 3 3 3 3 18s
正常之後,將nginx的版本進行升級,從1.7升級到1.9。第一種方法,直接set映象:
$ kubectl set image deployment/nginx-deployment2 nginx=nginx:1.9 deployment "nginx-deployment2" image updated
第二種方法,直接edit:
$ kubectl edit deployment/nginx-deployment deployment "nginx-deployment2" edited
檢視Deployment的變更資訊(以下資訊得以儲存,是建立時候加的“--record”這個選項起的作用):
$ kubectl rollout history deployment/nginx-deployment
deployments "nginx-deployment":
REVISION CHANGE-CAUSE
1 kubectl create -f docs/user-guide/nginx-deployment.yaml --record
2 kubectl set image deployment/nginx-deployment nginx=nginx:1.9.1
3 kubectl set image deployment/nginx-deployment nginx=nginx:1.91
$ kubectl rollout history deployment/nginx-deployment --revision=2
deployments "nginx-deployment" revision 2
Labels: app=nginx
pod-template-hash=1159050644
Annotations: kubernetes.io/change-cause=kubectl set image deployment/nginx-deployment nginx=nginx:1.9.1
Containers:
nginx:
Image: nginx:1.9.1
Port: 80/TCP
QoS Tier:
cpu: BestEffort
memory: BestEffort
Environment Variables: <none>
No volumes.
最後介紹下Deployment的一些基礎命令。
$ kubectl describe deployments #查詢詳細資訊,獲取升級進度 $ kubectl rollout pause deployment/nginx-deployment2 #暫停升級 $ kubectl rollout resume deployment/nginx-deployment2 #繼續升級 $ kubectl rollout undo deployment/nginx-deployment2 #升級回滾 $ kubectl scale deployment nginx-deployment --replicas 10 #彈性伸縮Pod數量
關於多重升級,舉例,當你建立了一個nginx1.7的Deployment,要求副本數量為5之後,Deployment Controller會逐步的將5個1.7的Pod啟動起來;當啟動到3個的時候,你又發出更新Deployment中Nginx到1.9的命令;這時Deployment Controller會立即將已啟動的3個1.7Pod殺掉,然後逐步啟動1.9的Pod。Deployment Controller不會等到1.7的Pod都啟動完成之後,再依次殺掉1.7,啟動1.9。
7、Volume
在Docker的設計實現中,容器中的資料是臨時的,即當容器被銷燬時,其中的資料將會丟失。如果需要持久化資料,需要使用Docker資料卷掛載宿主機上的檔案或者目錄到容器中。在Kubernetes中,當Pod重建的時候,資料是會丟失的,Kubernetes也是通過資料卷掛載來提供Pod資料的持久化的。Kubernetes資料卷是對Docker資料卷的擴充套件,Kubernetes資料卷是Pod級別的,可以用來實現Pod中容器的檔案共享。目前,Kubernetes支援的資料卷型別如下:
1) EmptyDir
2) HostPath
3) GCE Persistent Disk
4) AWS Elastic Block Store
5) NFS
6) iSCSI
7) Flocker
8) GlusterFS
9) RBD
10) Git Repo
11) Secret
12) Persistent Volume Claim
13) Downward API
7.1本地資料卷
EmptyDir、HostPath這兩種型別的資料卷,只能最用於本地檔案系統。本地資料卷中的資料只會存在於一臺機器上,所以當Pod發生遷移的時候,資料便會丟失。該型別Volume的用途是:Pod中容器間的檔案共享、共享宿主機的檔案系統。
7.1.1 EmptyDir
如果Pod配置了EmpyDir資料卷,在Pod的生命週期內都會存在,當Pod被分配到 Node上的時候,會在Node上建立EmptyDir資料卷,並掛載到Pod的容器中。只要Pod 存在,EmpyDir資料卷都會存在(容器刪除不會導致EmpyDir資料卷丟失資料),但是如果Pod的生命週期終結(Pod被刪除),EmpyDir資料卷也會被刪除,並且永久丟失。
EmpyDir資料卷非常適合實現Pod中容器的檔案共享。Pod的設計提供了一個很好的容器組合的模型,容器之間各司其職,通過共享檔案目錄來完成互動,比如可以通過一個專職日誌收集容器,在每個Pod中和業務容器中進行組合,來完成日誌的收集和彙總。
7.1.2 HostPath
HostPath資料卷允許將容器宿主機上的檔案系統掛載到Pod中。如果Pod需要使用宿主機上的某些檔案,可以使用HostPath。
7.2網路資料卷
Kubernetes提供了很多型別的資料卷以整合第三方的儲存系統,包括一些非常流行的分散式檔案系統,也有在IaaS平臺上提供的儲存支援,這些儲存系統都是分散式的,通過網路共享檔案系統,因此我們稱這一類資料卷為網路資料卷。
網路資料卷能夠滿足資料的持久化需求,Pod通過配置使用網路資料卷,每次Pod建立的時候都會將儲存系統的遠端檔案目錄掛載到容器中,資料卷中的資料將被水久儲存,即使Pod被刪除,只是除去掛載資料卷,資料卷中的資料仍然儲存在儲存系統中,且當新的Pod被建立的時候,仍是掛載同樣的資料卷。網路資料捲包含以下幾種:NFS、iSCISI、GlusterFS、RBD(Ceph Block Device)、Flocker、AWS Elastic Block Store、GCE Persistent Disk
7.3 Persistent Volume和Persistent Volume Claim
理解每個儲存系統是一件複雜的事情,特別是對於普通使用者來說,有時候並不需要關心各種儲存實現,只希望能夠安全可靠地儲存資料。Kubernetes中提供了Persistent Volume和Persistent Volume Claim機制,這是儲存消費模式。Persistent Volume是由系統管理員配置建立的一個數據卷(目前支援HostPath、GCE Persistent Disk、AWS Elastic Block Store、NFS、iSCSI、GlusterFS、RBD),它代表了某一類儲存外掛實現;而對於普通使用者來說,通過Persistent Volume Claim可請求並獲得合適的Persistent Volume,而無須感知後端的儲存實現。Persistent Volume和Persistent Volume Claim的關係其實類似於Pod和Node,Pod消費Node資源,Persistent Volume Claim則消費Persistent Volume資源。Persistent Volume和Persistent Volume Claim相互關聯,有著完整的生命週期管理:
1) 準備:系統管理員規劃或建立一批Persistent Volume;
2) 繫結:使用者通過建立Persistent Volume Claim來宣告儲存請求,Kubernetes發現有儲存請求的時候,就去查詢符合條件的Persistent Volume(最小滿足策略)。找到合適的就繫結上,找不到就一直處於等待狀態;
3) 使用:建立Pod的時候使用Persistent Volume Claim;
4) 釋放:當用戶刪除繫結在Persistent Volume上的Persistent Volume Claim時,Persistent Volume進入釋放狀態,此時Persistent Volume中還殘留著上一個Persistent Volume Claim的資料,狀態還不可用;
5) 回收:是否的Persistent Volume需要回收才能再次使用。回收策略可以是人工的也可以是Kubernetes自動進行清理(僅支援NFS和HostPath)
7.4資訊資料卷
Kubernetes中有一些資料卷,主要用來給容器傳遞配置資訊,我們稱之為資訊資料卷,比如Secret(處理敏感配置資訊,密碼、Token等)、Downward API(通過環境變數的方式告訴容器Pod的資訊)、Git Repo(將Git倉庫下載到Pod中),都是將Pod的資訊以檔案形式儲存,然後以資料卷方式掛載到容器中,容器通過讀取檔案獲取相應的資訊。
8、Pet Sets/StatefulSet
K8s在1.3版本里釋出了Alpha版的PetSet功能。在雲原生應用的體系裡,有下面兩組近義詞;第一組是無狀態(stateless)、牲畜(cattle)、無名(nameless)、可丟棄(disposable);第二組是有狀態(stateful)、寵物(pet)、有名(having name)、不可丟棄(non-disposable)。RC和RS主要是控制提供無狀態服務的,其所控制的Pod的名字是隨機設定的,一個Pod出故障了就被丟棄掉,在另一個地方重啟一個新的Pod,名字變了、名字和啟動在哪兒都不重要,重要的只是Pod總數;而PetSet是用來控制有狀態服務,PetSet中的每個Pod的名字都是事先確定的,不能更改。PetSet中Pod的名字的作用,是用來關聯與該Pod對應的狀態。
對於RC和RS中的Pod,一般不掛載儲存或者掛載共享儲存,儲存的是所有Pod共享的狀態,Pod像牲畜一樣沒有分別;對於PetSet中的Pod,每個Pod掛載自己獨立的儲存,如果一個Pod出現故障,從其他節點啟動一個同樣名字的Pod,要掛在上原來Pod的儲存繼續以它的狀態提供服務。
適合於PetSet的業務包括資料庫服務MySQL和PostgreSQL,叢集化管理服務Zookeeper、etcd等有狀態服務。PetSet的另一種典型應用場景是作為一種比普通容器更穩定可靠的模擬虛擬機器的機制。傳統的虛擬機器正是一種有狀態的寵物,運維人員需要不斷地維護它,容器剛開始流行時,我們用容器來模擬虛擬機器使用,所有狀態都儲存在容器裡,而這已被證明是非常不安全、不可靠的。使用PetSet,Pod仍然可以通過漂移到不同節點提供高可用,而儲存也可以通過外掛的儲存來提供高可靠性,PetSet做的只是將確定的Pod與確定的儲存關聯起來保證狀態的連續性。
9、ConfigMap
很多生產環境中的應用程式配置較為複雜,可能需要多個config檔案、命令列引數和環境變數的組合。並且,這些配置資訊應該從應用程式映象中解耦出來,以保證映象的可移植性以及配置資訊不被洩露。社群引入ConfigMap這個API資源來滿足這一需求。
ConfigMap包含了一系列的鍵值對,用於儲存被Pod或者系統元件(如controller)訪問的資訊。這與secret的設計理念有異曲同工之妙,它們的主要區別在於ConfigMap通常不用於儲存敏感資訊,而只儲存簡單的文字資訊。
10、Horizontal Pod Autoscaler
自動擴充套件作為一個長久的議題,一直為人們津津樂道。系統能夠根據負載的變化對計算資源的分配進行自動的擴增或者收縮,無疑是一個非常吸引人的特徵,它能夠最大可能地減少費用或者其他代價(如電力損耗)。自動擴充套件主要分為兩種,其一為水平擴充套件,針對於例項數目的增減;其二為垂直擴充套件,即單個例項可以使用的資源的增減。Horizontal Pod Autoscaler(HPA)屬於前者。
10.1 Horizontal Pod Autoscaler如何工作
Horizontal Pod Autoscaler的操作物件是Replication Controller、ReplicaSet或Deployment對應的Pod,根據觀察到的CPU實際使用量與使用者的期望值進行比對,做出是否需要增減例項數量的決策。controller目前使用heapSter來檢測CPU使用量,檢測週期預設是30秒。
10.2 Horizontal Pod Autoscaler的決策策略
在HPA Controller檢測到CPU的實際使用量之後,會求出當前的CPU使用率(實際使用量與pod 請求量的比率)。然後,HPA Controller會通過調整副本數量使得CPU使用率儘量向期望值靠近.另外,考慮到自動擴充套件的決策可能需要一段時間才會生效,甚至在短時間內會引入一些噪聲. 例如當pod所需要的CPU負荷過大,從而執行一個新的pod進行分流,在建立的過程中,系統的CPU使用量可能會有一個攀升的過程。所以,在每一次作出決策後的一段時間內,將不再進行擴充套件決策。對於ScaleUp而言,這個時間段為3分鐘,Scaledown為5分鐘。再者HPA Controller允許一定範圍內的CPU使用量的不穩定,也就是說,只有當aVg(CurrentPodConsumption/Target低於0.9或者高於1.1時才進行例項調整,這也是出於維護系統穩定性的考慮。
相關推薦
kubernetes核心概念總結和手動叢集部署實踐 之一
基礎架構 Master Master節點上面主要由四個模組組成,APIServer,schedule,controller manager, etcd. APIServer: APIServer負責對外提供RESTful的kubernetes AP
Kubernetes核心概念總結
1、基礎架構 1.1 Master Master節點上面主要由四個模組組成:APIServer、scheduler、controller manager、etcd。 APIServer。APIServer負責對外提供RESTful的Kuberne
Kubernetes核心概念之Replication Controller詳解
kubernetes docker 虛擬化 replication controll Replication Controller簡稱RC,它能夠保證Pod持續運行,並且在任何時候都有指定數量的Pod副本,在此基礎上提供一些高級特性,比如滾動升級和彈性伸縮? ? 它在k8s中的架構如圖:? ?
十分鐘帶你理解Kubernetes核心概念
rtu 虛擬 請求分發 問題: int ref spa virtual ogl 本文將會簡單介紹Kubernetes的核心概念。因為這些定義可以在Kubernetes的文檔中找到,所以文章也會避免用大段的枯燥的文字介紹。相反,我們會使用一些圖表(其中一些是動畫)和示例來解釋
Kubernetes 核心概念簡介
kubernetes 原理 概念Kubernets 中的Node, Pod,Replication Controller, Service 等都可以看作一種資源對象,這些資源幾乎都可以通過使用Kubernetes提供的kubectl 工具執行增刪改查,並將其保存在etcd中持久化儲存。通過跟蹤對比etcd
Kubernetes核心概念之Service詳解
clusterip ips aml 開放 lan font led IT 架構 Service是k8s中非常重要的組成單元,作用是作為代理把在POD中容器內的服務發布出去,提供一套簡單的發現機制和服務代理,也就是運維常說的‘前端’概念,那麽它如何實現代理功能以及自動
Kubernetes核心概念之Volume存儲數據卷詳解
gin creat 自己的 當前 ges 訪問路徑 服務器 tor type 在Docker中就有數據卷的概念,當容器刪除時,數據也一起會被刪除,想要持久化使用數據,需要把主機上的目錄掛載到Docker中去,在K8S中,數據卷是通過Pod實現持久化的,如果Pod刪除
kubernetes核心概念
proxy posit volume 均衡 業務 簡單 單位 osi 變化 ClusterCluster 是計算、存儲和網絡資源的集合,Kubernetes 利用這些資源運行各種基於容器的應用。MasterMaster 是 Cluster 的大腦,它的主要職責是調度,即決定
kubernetes核心概念-pod + service
k8s的部署架構 kubernetes中有兩類資源,分別是master和nodes,master和nodes上跑的服務如下圖, kube-apiserver | kubelet kube-controller-manager
Kubernetes 核心概念
什麼是Kubernetes? Kubernetes(k8s)是自動化容器操作的開源平臺,這些操作包括部署,排程和節點叢集間擴充套件。如果你曾經用過Docker容器技術部署容器,那麼可以將Docker看成Kubernetes內部使用的低級別元件。Kubernetes不僅僅支援Docker,還支援Rocket,
Java NIO核心概念總結篇
最近學習Java NIO的相關知識,為了以後方便複習記錄下主要知識點。 參考來源:某視訊中的講解以及一些博文,見文章結尾。 一、Java NIO基本介紹 Java NIO(New IO,也有人叫:Non Blocking IO)是從Java1.4版本開始引入的一個新的
Kubernetes核心概念介紹
Kubernetes是一個可輕便的,可拓展的開源平臺,為管理容器與服務提供便利的配置以及自動化.現已有著很龐大以及快速增長的生態系統. Kubernetes還有一個重要的思想就是一切皆容器. k8s是kubernetes的簡稱,8代指是ubernete. 關鍵
01 . 容器編排簡介及Kubernetes核心概念
#### Kubernetes簡介 > Kubernetes是谷歌嚴格保密十幾年的祕密武器—Borg的一個開源版本,是Docker分散式系統解決方案.2014年由Google公司啟動. > > > > Kubernetes提供了面向應用的容器叢集部署和管理系統。Kubernetes的目標旨在消除編排物理/
Maven學習總結(四)——Maven核心概念
pbm true 遠程倉庫 vc6 orm 復制代碼 lean 其它 filesize 一、Maven坐標 1.1、什麽是坐標? 在平面幾何中坐標(x,y)可以標識平面中唯一的一點。 1.2、Maven坐標主要組成 groupId:組織標識(包
Kubernetes核心原理簡單總結(一)
1、kubernetes APIserver 1)提供了叢集管理的API介面 2)是叢集內各個功能模組之間資料互動和通訊的中心樞紐 3)擁有完備的叢集安全機制 API通過 apiserver程序提供服務,該程序在master節點上。該程序包括兩個埠:本地埠,預設是8080埠
通過例項快速掌握k8s(Kubernetes)核心概念
容器技術是微服務技術的核心技術之一,並隨著微服務的流行而迅速成為主流。Docker是容器技術的先驅和奠基者,它出現之後迅速佔領市場,幾乎成了容器的代名詞。但它在開始的時候並沒有很好地解決容器的叢集問題。Kubernetes抓住了這個機遇,以容器編排者(Container Orchestration)的身份出現
ios多線程操作(四)—— GCD核心概念
indent img 操作 fort 16px 2.0 b2c 有一種 read GCD全稱Grand Central Dispatch。可譯為“大派發中樞調度器”,以純C語言寫成,提供了很多很強大的函數。GCD是蘋果公司為多核的並行運算提出的解決方式,它能夠自己主
elasticsearch中的幾個概念總結
查詢 article ase con 總結 diff 返回 cse nan 1、Geo spatial search : 地理空間搜索,可以在搜索查詢中指定的某一距離內查找所要的內容。也可以返回以當前為圓心,逐漸添加圓的半徑。直到找到所匹配到的內容。
Java oo 概念總結
count 就會 strac 通道 left 方法名 引用類型 under 序列化 1、 Java語言的特點是什麽? 簡單 面向對象 跨平臺 多線程 健壯性安全性 垃圾回收機制 2、如何編譯和執行java文件?產生幫助文檔用什麽命令? 編譯: ja
vuex所有核心概念完整解析State Getters Mutations Actions
function 鉤子 action 元素事件 getter 參數 pst isp 文件中 vuex是解決vue組件和組件間相互通信而存在的,vuex理解起來稍微復雜,但一旦看懂則即為好用: 安裝: npm install --save vuex 引入 import