
Elastic-Job-Lite 源碼分析 —— 作業分片策略
摘要: 原創出處 http://www.iocoder.cn/Elastic-Job/job-sharding-strategy/ 「芋道源碼」歡迎轉載,保留摘要,謝謝!
本文基於 Elastic-Job V2.1.5 版本分享
- 1. 概述
- 2. 自帶作業分片策略
- 2.1 AverageAllocationJobShardingStrategy
- 2.2 OdevitySortByNameJobShardingStrategy
- 2.3 RotateServerByNameJobShardingStrategy
- 3. 自定義作業分片策略
- 666. 彩蛋
??????關註微信公眾號:【芋道源碼】有福利:
- RocketMQ / MyCAT / Sharding-JDBC 所有源碼分析文章列表
- RocketMQ / MyCAT / Sharding-JDBC 中文註釋源碼 GitHub 地址
- 您對於源碼的疑問每條留言都將得到認真回復。甚至不知道如何讀源碼也可以請教噢。
- 新的源碼解析文章實時收到通知。每周更新一篇左右。
- 認真的源碼交流微信群。
1. 概述
本文主要分享 Elastic-Job-Lite 作業分片策略。
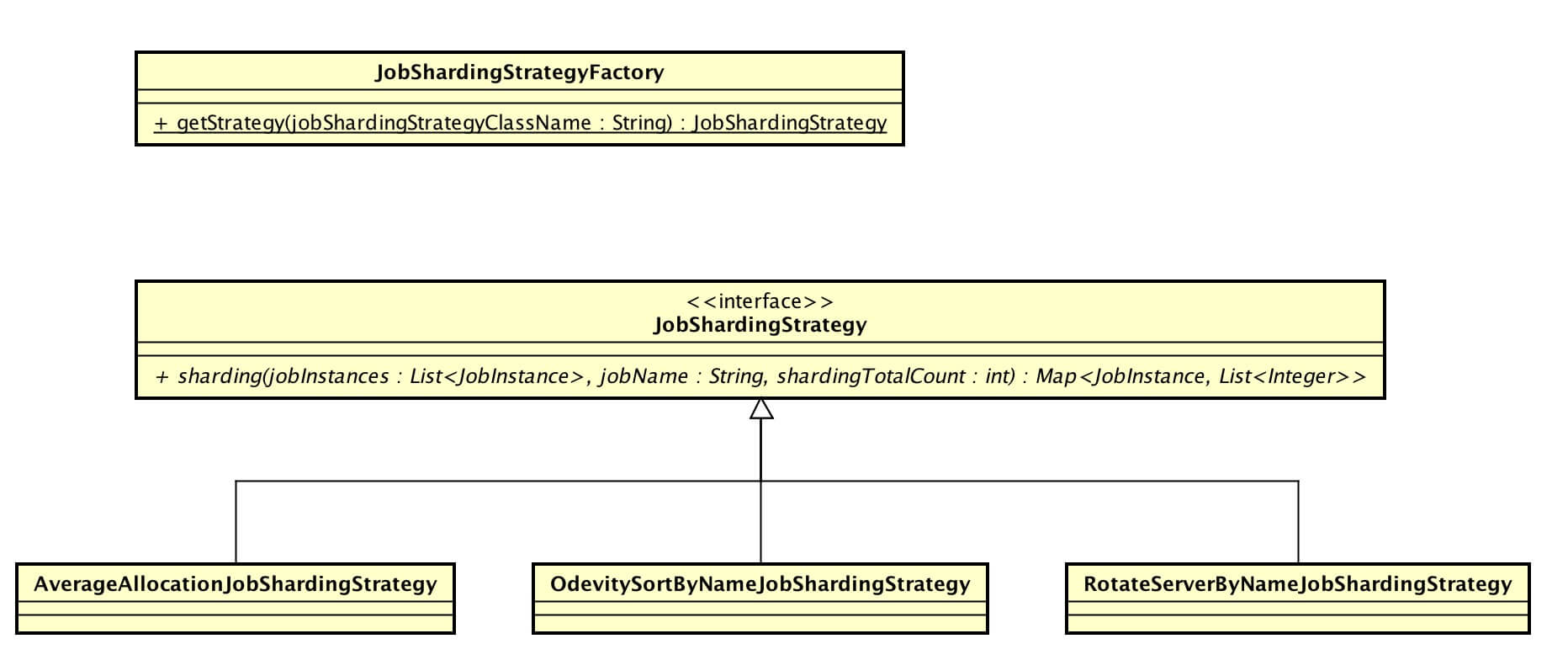
涉及到主要類的類圖如下( 打開大圖 ):
你行好事會因為得到贊賞而愉悅
同理,開源項目貢獻者會因為 Star 而更加有動力
為 Elastic-Job 點贊!傳送門
2. 自帶作業分片策略
JobShardingStrategy,作業分片策略接口。分片策略通過實現接口的 #sharding(...) 方法提供作業分片的計算。
| public interface JobShardingStrategy { Map<JobInstance, List<Integer>> sharding(List<JobInstance> jobInstances, String jobName, int shardingTotalCount); } |
Elastic-Job-Lite 提供三種自帶的作業分片策略:
- AverageAllocationJobShardingStrategy:基於平均分配算法的分片策略。
- OdevitySortByNameJobShardingStrategy:根據作業名的哈希值奇偶數決定IP升降序算法的分片策略。
- RotateServerByNameJobShardingStrategy:根據作業名的哈希值對作業節點列表進行輪轉的分片策略。
2.1 AverageAllocationJobShardingStrategy
AverageAllocationJobShardingStrategy,基於平均分配算法的分片策略。Elastic-Job-Lite 默認的作業分片策略。
如果分片不能整除,則不能整除的多余分片將依次追加到序號小的作業節點。如:
如果有3臺作業節點,分成9片,則每臺作業節點分到的分片是:1=[0,1,2], 2=[3,4,5], 3=[6,7,8]
如果有3臺作業節點,分成8片,則每臺作業節點分到的分片是:1=[0,1,6], 2=[2,3,7], 3=[4,5]
如果有3臺作業節點,分成10片,則每臺作業節點分到的分片是:1=[0,1,2,9], 2=[3,4,5], 3=[6,7,8]
代碼實現如下:
| public final class AverageAllocationJobShardingStrategy implements JobShardingStrategy { public Map<JobInstance, List<Integer>> sharding(final List<JobInstance> jobInstances, final String jobName, final int shardingTotalCount) { // 不存在 作業運行實例 if (jobInstances.isEmpty()) { return Collections.emptyMap(); } // 分配能被整除的部分 Map<JobInstance, List<Integer>> result = shardingAliquot(jobInstances, shardingTotalCount); // 分配不能被整除的部分 addAliquant(jobInstances, shardingTotalCount, result); return result; } } |
-
調用
#shardingAliquot(...)方法分配能被整除的部分。能整除的咱就不舉例子。如果有 3 臺作業節點,分成 8 片,被整除的部分是前 6 片 [0, 1, 2, 3, 4, 5],調用該方法結果:1=[0,1], 2=[2,3], 3=[4,5]。private Map<JobInstance, List<Integer>> shardingAliquot(final List<JobInstance> shardingUnits, final int shardingTotalCount) { Map<JobInstance, List<Integer>> result = new LinkedHashMap<>(shardingTotalCount, 1); int itemCountPerSharding = shardingTotalCount / shardingUnits.size(); // 每個作業運行實例分配的平均分片數 int count = 0; for (JobInstance each : shardingUnits) { List<Integer> shardingItems = new ArrayList<>(itemCountPerSharding + 1); // 順序向下分配 for (int i = count * itemCountPerSharding; i < (count + 1) * itemCountPerSharding; i++) { shardingItems.add(i); } result.put(each, shardingItems); count++; } return result; } -
調用
#addAliquant(...)方法分配能不被整除的部分。繼續上面的例子。不能被整除的部分是後 2 片 [6, 7],調用該方法結果:1=[0,1] + [6], 2=[2,3] + [7], 3=[4,5]。private void addAliquant(final List<JobInstance> shardingUnits, final int shardingTotalCount, final Map<JobInstance, List<Integer>> shardingResults) { int aliquant = shardingTotalCount % shardingUnits.size(); // 余數 int count = 0; for (Map.Entry<JobInstance, List<Integer>> entry : shardingResults.entrySet()) { if (count < aliquant) { entry.getValue().add(shardingTotalCount / shardingUnits.size() * shardingUnits.size() + count); } count++; } }
如何實現主備
通過作業配置設置總分片數為 1 ( JobCoreConfiguration.shardingTotalCount = 1 ),只有一個作業分片能夠分配到作業分片項,從而達到一主N備。
2.2 OdevitySortByNameJobShardingStrategy
OdevitySortByNameJobShardingStrategy,根據作業名的哈希值奇偶數決定IP升降序算法的分片策略。
作業名的哈希值為奇數則IP 降序.
作業名的哈希值為偶數則IP 升序.
用於不同的作業平均分配負載至不同的作業節點.
如:
- 如果有3臺作業節點, 分成2片, 作業名稱的哈希值為奇數, 則每臺作業節點分到的分片是: 1=[ ], 2=[1], 3=[0].
- 如果有3臺作業節點, 分成2片, 作業名稱的哈希值為偶數, 則每臺作業節點分到的分片是: 1=[0], 2=[1], 3=[ ].
實現代碼如下:
| public Map<JobInstance, List<Integer>> sharding(final List<JobInstance> jobInstances, final String jobName, final int shardingTotalCount) { long jobNameHash = jobName.hashCode(); if (0 == jobNameHash % 2) { Collections.reverse(jobInstances); } return averageAllocationJobShardingStrategy.sharding(jobInstances, jobName, shardingTotalCount); } |
-
從實現代碼上,仿佛和 IP 升降序沒什麽關系?答案在傳遞進來的參數
jobInstances。jobInstances已經是按照 IP 進行降序的數組。所以當判斷到作業名的哈希值為偶數時,進行數組反轉(Collections#reverse(...))實現按照 IP 升序。下面看下為什麽說jobInstances已經按照 IP 進行降序:// ZookeeperRegistryCenter.java public List<String> getChildrenKeys(final String key) { try { List<String> result = client.getChildren().forPath(key); Collections.sort(result, new Comparator<String>() { public int compare(final String o1, final String o2) { return o2.compareTo(o1); } }); return result; } catch (final Exception ex) { RegExceptionHandler.handleException(ex); return Collections.emptyList(); } } -
調用
AverageAllocationJobShardingStrategy#sharding(...)方法完成最終作業分片計算。
2.3 RotateServerByNameJobShardingStrategy
RotateServerByNameJobShardingStrategy,根據作業名的哈希值對作業節點列表進行輪轉的分片策略。這裏的輪轉怎麽定義呢?如果有 3 臺作業節點,順序為 [0, 1, 2],如果作業名的哈希值根據作業分片總數取模為 1, 作業節點順序變為 [1, 2, 0]。
分片的目的,是將作業的負載合理的分配到不同的作業節點上,要避免分片策略總是讓固定的作業節點負載特別大,其它工作節點負載特別小。這個也是為什麽官方對比 RotateServerByNameJobShardingStrategy、AverageAllocationJobShardingStrategy 如下:
AverageAllocationJobShardingStrategy的缺點是,一旦分片數小於作業作業節點數,作業將永遠分配至IP地址靠前的作業節點,導致IP地址靠後的作業節點空閑。如:
OdevitySortByNameJobShardingStrategy則可以根據作業名稱重新分配作業節點負載。
如果有3臺作業節點,分成2片,作業名稱的哈希值為奇數,則每臺作業節點分到的分片是:1=[0], 2=[1], 3=[]
如果有3臺作業節點,分成2片,作業名稱的哈希值為偶數,則每臺作業節點分到的分片是:3=[0], 2=[1], 1=[]
實現代碼如下:
| public final class RotateServerByNameJobShardingStrategy implements JobShardingStrategy { private AverageAllocationJobShardingStrategy averageAllocationJobShardingStrategy = new AverageAllocationJobShardingStrategy(); public Map<JobInstance, List<Integer>> sharding(final List<JobInstance> jobInstances, final String jobName, final int shardingTotalCount) { return averageAllocationJobShardingStrategy.sharding(rotateServerList(jobInstances, jobName), jobName, shardingTotalCount); } private List<JobInstance> rotateServerList(final List<JobInstance> shardingUnits, final String jobName) { int shardingUnitsSize = shardingUnits.size(); int offset = Math.abs(jobName.hashCode()) % shardingUnitsSize; // 輪轉開始位置 if (0 == offset) { return shardingUnits; } List<JobInstance> result = new ArrayList<>(shardingUnitsSize); for (int i = 0; i < shardingUnitsSize; i++) { int index = (i + offset) % shardingUnitsSize; result.add(shardingUnits.get(index)); } return result; } } |
- 調用
#rotateServerList(...)實現作業節點數組輪轉。 - 調用
AverageAllocationJobShardingStrategy#sharding(...)方法完成最終作業分片計算。
3. 自定義作業分片策略
可能在你的業務場景下,需要實現自定義的作業分片策略。通過定義類實現 JobShardingStrategy 接口即可:
| public final class OOXXShardingStrategy implements JobShardingStrategy { public Map<JobInstance, List<Integer>> sharding(final List<JobInstance> jobInstances, final String jobName, final int shardingTotalCount) { // 實現邏輯 } } |
實現後,配置實現類的全路徑到 Lite作業配置( LiteJobConfiguration )的 jobShardingStrategyClass 屬性。
作業進行分片計算時,作業分片策略工廠( JobShardingStrategyFactory ) 會創建作業分片策略實例:
|
public final class JobShardingStrategyFactory {
public static JobShardingStrategy getStrategy(final String jobShardingStrategyClassName) {
if (Strings.isNullOrEmpty(jobShardingStrategyClassName)) {
return new AverageAllocationJobShardingStrategy();
}
try {
Class<?> jobShardingStrategyClass = Class.forName(jobShardingStrategyClassName);
if (!JobShardingStrategy.class.isAssignableFrom(jobShardingStrategyClass)) {
throw new JobConfigurationException("Class ‘%s‘ is not job strategy class", jobShardingStrategyClassName);
}
return (JobShardingStrategy) jobShardingStrategyClass.newInstance();
} catch (final ClassNotFoundException | InstantiationException | IllegalAccessException ex) {
throw new JobConfigurationException("Sharding strategy class ‘%s‘ config error, message details are ‘%s‘", jobShardingStrategyClassName, ex.getMessage());
}
}
}
|
Elastic-Job-Lite 源碼分析 —— 作業分片策略