
阿裏HBase的數據管道設施實踐與演進
直播視頻請點擊
PPT下載請點擊
精彩視頻整理:
數據導入場景
生意參謀
生意參謀是一種為商家服務,幫助商家進行決策和運營的數據產品。如在淘寶或天貓上開一家店,生意參謀會提供店裏每天進入的流量、轉化率、客戶的畫像和同行業進行對比這些數據屬於什麽位置。商家可以根據流量分析、活動分析和行業分析去進行決策。可以根據平時日誌、點擊量和訪問量,數據庫把數據通過實時的流處理寫入HBase。有一部分寫到離線系統裏,定期做一些清洗和計算再寫入HBase,然後供業務去查詢 HBase。
螞蟻風控
在螞蟻上任何一筆交易支付都會調用風控,風控主要是去看這次交易是否屬於同一個設備,是否是經常交易的地點,以及交易的店鋪信息。它必須在100ms—200ms把風險做完,風控是根據長期的歷史信息、近期歷史的信息和實時的信息三個方向做綜合考量。用戶的輸入會實時的寫入HBase,同時這個實時的信息增量也會導入到離線系統裏面,離線系統會定期的對數據進行計算,計算的數據結果會作為歷史或近期歷史再寫回HBase,一個支付可能會調百十次的風控,而且需要在百毫秒內進行返回。
數據導入需要解決的問題
2013年剛剛開始做數據導入的時候面臨的更多的是功能需求性的問題,現在需要考慮的是導入的周期性調度、異構數據源多、導入效率高和多集群下的數據一致性的問題。前兩個問題更適合由平臺化去解決,HBase的數據導入更關註的是導入效率和多集群下的數據的一致性。
什麽是Bulkload?Bulkload有什麽功能?
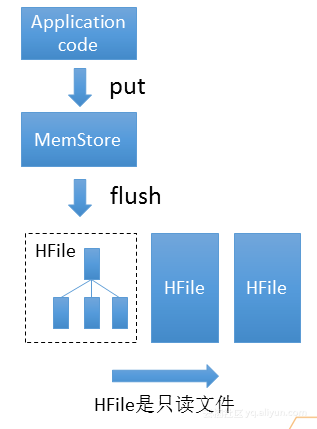
Bulkload使用的是一種新的結構LSM Tree進行寫入更新,其結構如上圖所示。使用Application code 進行數據寫入,數據會被寫入到MemStore,MemStore在HBase裏是一個跳表,可以把它看成一個有序的列表,並不斷往裏面插入數據。當數據達到一定量時就會啟動flush對數據進行編碼和壓縮,並寫成HFile。HFile是由索引塊和數據塊組成的文件結構,其特點是只讀性,生成HFile之後就不可改了。當用戶進行讀取數據的時候,就會從三個HFile和一個MemStore進行查找進行讀取。這個結構的優化就是就把隨機的寫變成了有序的寫。Bulkload就可以把上千上萬條數據在毫秒內加入到HBase裏。所以Bulkload的優勢如下:
高吞吐
不需要WAL
避免small compaction
支持離線構建
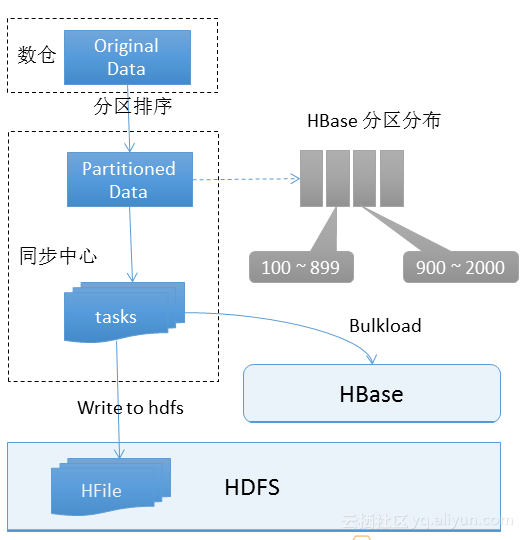
Bulkload的導入結構如上圖所示,數據來源於數倉,首先根據HBase的分區規則對數據進行分區和排序。然後會生成Partition Data,需要寫一個HBase插進去。同步中心就會調動一個作業,作業內部會有很多的tasks,每個task獨立的執行把文件讀出,寫到HDFS上,形成一個HFile文件。當把所有文件寫完,同步中心就會調Bulkload指令到HBase,把所有的HFile一次性的load進去。
以前采用的是多集群導入的方法,但是多集群導入有很多缺點如下:
很難保證多個任務同時完成,導致一定時間窗口內數據不一致
調度後的運行環境不一致
網絡延遲不一致
失敗重試
集群部署對業務不透明的缺點:需要配置多個任務
集群遷移需要重新配置任務
為了保證數據的一致性,采用了邏輯集群導入法。
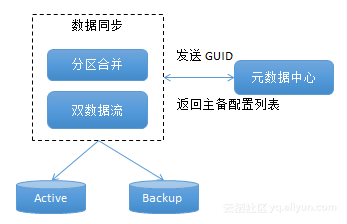
邏輯集群的流程如上圖所示,首先進行分區合並,然後進行雙數據流處理,把流分別寫到Active和Backup裏,當Active和Backup的HFile文件寫完後執行Bulkload。因為Bulkload是毫秒級別的,所以能實現一致性。
多任務和邏輯集群的差別比較如下:
多任務模式:需要重復配置,是不透明的,很難保證一致性,分區排序
需要執行兩次,編碼壓縮兩次。邏輯集群模式:配置一次,遷移無感知,在一致性上達到毫秒級,分區排序是執行一次,但分區數量變多,編碼壓縮一次。
隨著業務做得越來越大,這種導入就會遇到新的線上問題,如擴展性、資源利用率、研發效率、監控等。
什麽是HImporter系統?
HImporter是用於輔助數據同步的中間層,他會把所有HFile的構建,加載邏輯下沈到HImporter層。
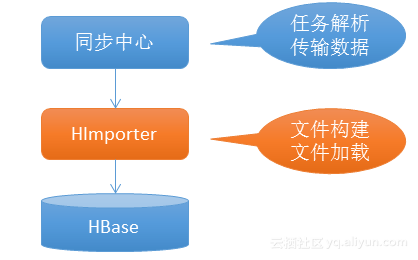
HImporter所處的位置如上圖所示。
HImporter的優勢
分布式水平擴展,同一個作業的不同任務可以調度到HImporter的不同worker節點
提高資源利用率,將壓縮等CPU密集操作下降到HImporter
快速叠代,HImporter的運維和叠代與同步中心獨立
獨立監控,HImporter可按照自己的需求實現監控
HImporter 功能叠代
功能叠代主要包括表屬性感知、保證本地化率、支持輕量計算和安全隔離。其中表屬性感知就是感知特性,並保證特征不會變,主要包括、混合存儲、新壓縮編碼、表級別副本數;保證本地化率是將Hfile寫入到分區所在服務器,保證本地化率和存儲特性,對一些rt敏感的業務效果明顯;支持輕量計算就是支持MD5,字符串拼接等函數;安全隔離是避免對外暴露HDFS地址、支持Task級別重試。
數據導出場景
菜鳥聯盟
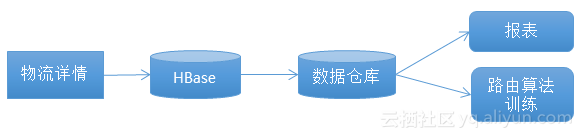
菜鳥聯盟的場景如上圖所示。一個物流詳情會傳到HBase,HBase會傳到數據倉庫,數據倉會產生報表,然後去訓練路由算法。
淘寶客服
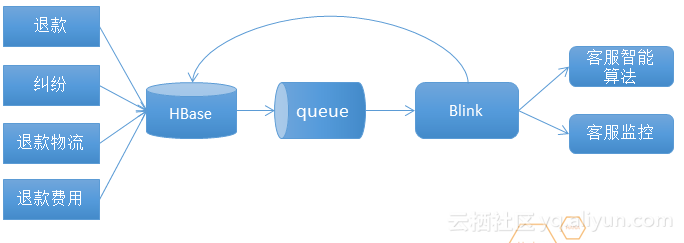
淘寶客服的一個退款應用場景如上圖。這是一個逆向鏈接,把退款、糾紛、退款物流、退款費用等實時的寫入到HBase裏,HBase會實時的寫入queue裏,blink流系統會消費queue產生一些數據會返回到HBase,blink輸出會支撐智能服務、客戶監控等。
增量數據導出需要解決的問題
增量數據導出需要解決的問題主要是離線數據的T+1處理特點、吞吐量 、實時性、主備流量切換等。
早期的方案是會周期性的從HDFS裏把所有的日誌羅列出來,然後對日誌進行排序會產生一個有序的時間流。取work裏同步時間最短的作為最終的同步時間。這種方案具有對NN節點造成很大壓力、無法應對主備切換、日誌熱點處理能力低等問題。
HExporter系統
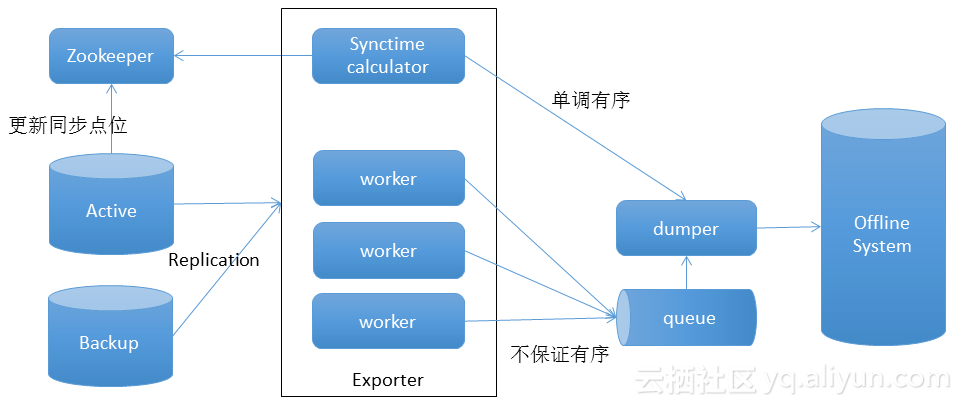
HExporter1.0如上圖所示,HExporter1.0優勢主要有主備流量切換不影響數據導出,能夠識別數據來源,過濾非原始數據;獨立的同步時間流,能夠保障數據按有序時間分區Dump到數據倉庫;復用HBase replication框架,能夠降低開發工作量,復用HBase的監控,運維體系。
HExporter1.0 優化主要包括以下五點:
減少拓撲網絡中的數據發送,備庫避免向Exporter發送重復數據;
遠程輔助消化器,空閑的機器幫助消化熱點;
避免發送小包,HExporter在接收到小包後,等待一段時間再處理;
同步通道配置隔離,實時消費鏈路和離線消費鏈路可以采用不同的配置;
數據發送前壓縮。
HExporter1.0的問題是業務寫入流量產生高峰,離線出現同步延遲;HBase升級速度慢。然後我們就有了以下解決思路,離線同步的資源可以和在線資源隔離,利用離線大池子可以削峰填谷;Exporter的worker是無狀態的,如果把所有邏輯都放在Exporter,那麽升級、擴容會簡單快速。然後就產生了HExporter2.0。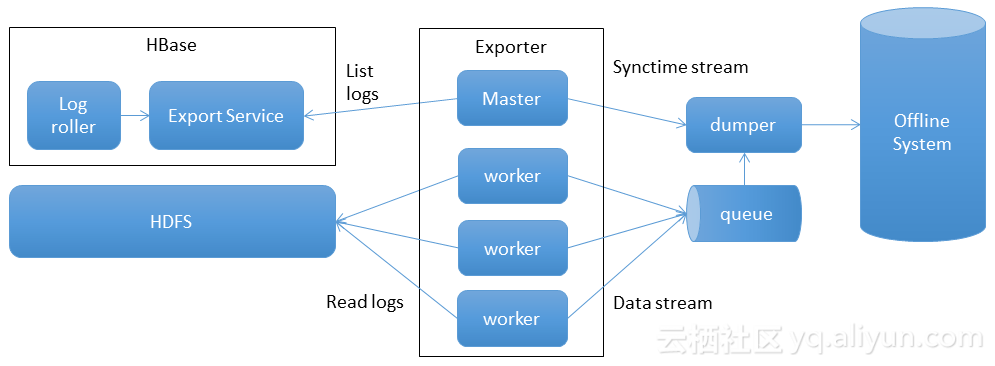
HExporter2.0如上圖所示
總結
ALiHBase數據通道的導入和導出都是添加了中間層,中間層的核心價值易擴展、可靠性高、叠代快和穩定。因為采用分布式水平擴展更易擴展;采用自主識別主備切換,封裝對HBase訪問更可靠;采用架構解耦,快速叠代使叠代速度更快;因為無狀態,節點對等所以更加穩定。
原文鏈接
阿裏HBase的數據管道設施實踐與演進