
機器學習的數學基礎
矩陣
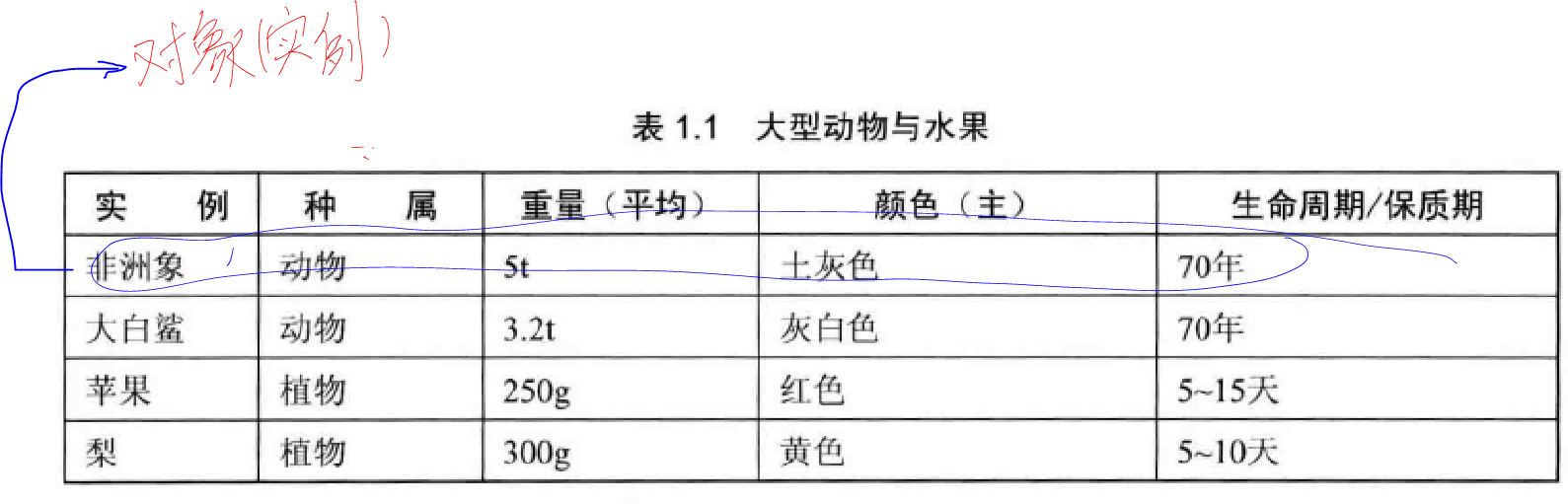
一般而言,一個對象應該被視為完整的個體,表現實中有意義的事物,不能輕易拆分。
對象是被特征化的客觀事物,而表(或矩陣)是容納這些對象的容器。換句話說,對象是表中的元素,表是對象的集合(表中的每個對象都有相同的特征和維度,對象對於每個特征都有一定的取值)。
分類或聚類可以看作根據對象特征的相似性與差異性,對矩陣空間的一種劃分。
預測或回歸可以看作根據對象在某種序列(時間)上的相關性,表現為特征取值變化的一種趨勢。
import numpy as npa = np.arange(9).reshape((3, -1))
aarray([[0, 1, 2], [3, 4, 5], [6, 7, 8]])
b = a.copy()id(a) == id(b)Falserepr(a) == repr(b)TrueLinalg
A = np.mat([[1, 2, 4, 5, 7], [9,12 ,11, 8, 2], [6, 4, 3, 2, 1], [9, 1, 3, 4, 5], [0, 2, 3, 4 ,1]])行列式
np.linalg.det(A)-812.00000000000068逆
np.linalg.inv(A)matrix([[ -7.14285714e-02, -1.23152709e-02, 5.29556650e-02, 9.60591133e-02, -8.62068966e-03], [ 2.14285714e-01, -3.76847291e-01, 1.22044335e+00, -4.60591133e-01, 3.36206897e-01], [ -2.14285714e-01, 8.25123153e-01, -2.04802956e+00, 5.64039409e-01, -9.22413793e-01], [ 5.11521867e-17, -4.13793103e-01, 8.79310345e-01, -1.72413793e-01, 8.10344828e-01], [ 2.14285714e-01, -6.65024631e-02, 1.85960591e-01, -8.12807882e-02, -1.46551724e-01]])
轉置
A.Tmatrix([[ 1, 9, 6, 9, 0],
[ 2, 12, 4, 1, 2],
[ 4, 11, 3, 3, 3],
[ 5, 8, 2, 4, 4],
[ 7, 2, 1, 5, 1]])A * A.Tmatrix([[ 95, 131, 43, 78, 43], [131, 414, 153, 168, 91], [ 43, 153, 66, 80, 26], [ 78, 168, 80, 132, 32], [ 43, 91, 26, 32, 30]])
秩
np.linalg.matrix_rank(A)5解方程
\[Ax = b\]
b = [1, 0, 1, 0, 1]
S = np.linalg.solve(A, b)
Sarray([-0.0270936 , 1.77093596, -3.18472906, 1.68965517, 0.25369458])現代數學三大基石:
- 概率論說明了事物可能會是什麽樣;
- 數值分析揭示了它們為什麽這樣,以及如何變成這樣;
- 線性代數告訴我們事物從來不只有一個樣子,使我們能夠從多個角度來觀察事物。
相似性度量
比較常見是範數(如歐式距離(\(L_2\))、曼哈頓距離(\(L_1\))、切比雪夫距離(\(L_{\infty}\)))和夾角余弦。下面我主要說明一下其他的幾個比較有意思的度量:
漢明距離(Hamming)
定義:兩個等長字符串 s1 與 s2 之間的漢明距離定義為將其中一個變成另外一個所需要的最小替換次數。
應用:信息編碼(為了增強容錯性,應該使得編碼間的最小漢明距離盡可能大)。
A = np.mat([[1, 1, 0, 1, 0, 1, 0, 0, 1], [0, 1, 1, 0, 0, 0, 1, 1, 1]])
smstr = np.nonzero(A[0] - A[1])A[0] - A[1]matrix([[ 1, 0, -1, 1, 0, 1, -1, -1, 0]])smstr(array([0, 0, 0, 0, 0, 0], dtype=int64),
array([0, 2, 3, 5, 6, 7], dtype=int64))d = smstr[0].shape[0]
d6傑卡德相似系數(Jaccard Similarity Coefficient)
相似度:
\[
J(A, B) = \frac{|\;A \bigcap B\;|}{|\;A \bigcup B\;|}
\]
傑卡德距離(Jaccard Distance)
區分度:
\[
J_{\delta}(A, B) = 1 - J(A, B) = 1 - \frac{|\;A \bigcap B\;|}{|\;A \bigcup B\;|}
\]
應用:
樣本 \(A\) 和樣本 \(B\) 所有維度的取值為 \(0\) 或 \(1\),表示包含某個元素與否。
import scipy.spatial.distance as distAmatrix([[1, 1, 0, 1, 0, 1, 0, 0, 1],
[0, 1, 1, 0, 0, 0, 1, 1, 1]])dist.pdist(A, ‘jaccard‘)array([ 0.75])蝴蝶效應(洛倫茲動力學方程):確定性與隨機性相統一
- 系統未來的所有運動都被限制在一個明確的範圍之內——確定性;
- 運動軌跡變化纏繞的規則是隨機性的,任何時候你都無法準確判定下一次運動的軌跡將落在「蝴蝶」的哪側翅膀上的哪個點上——隨機性。
總而言之,系統運動大的範圍是確定的、可測的,但是運動的細節是隨機的、不可測的。
從統計學角度來看,蝴蝶效應說明了:
- 樣本總體(特征向量或對象)的取值範圍一般是確定的,所有樣本對象(包括已經存在的和未出現的)的取值都位於此空間內;
- 無論收集再多的樣本對象,也不能使這種隨機性降低或消失。
隨機性是事物的一種根本的、內在的、無法根除的性質,也是一切事物(概率)的本質屬性。
衡量事物運動的隨機性,必須從整體而不是局部來認知事物,因為從每個局部,事物可能看起來都是不同的(或相同的)。
概率論便是度量隨機性的一個工具。一般地,上述所說的矩陣,被稱為設計矩陣,基本概念重寫:
- 樣本(樣本點):原指隨機試驗的一個結果,可以理解為設計矩陣中的一個對象,如蘋果、小豬等。
- 樣本空間:原指隨機試驗所有可能結果的集合,可以理解為矩陣的所有對象,引申為對象特征的取值範圍:\(10\) 個蘋果,\(2\) 只小豬。
- 隨機事件:原指樣本空間的一個子集,可以理解為某個分類,它實際指向一種概率分布:蘋果為紅色,小豬為白色
- 隨機變量:可以理解為指向某個事件的一個變量:\(X\{x_i = \text{黃色}\}\)
- 隨機變量的概率分布:給定隨機變量的取值範圍,導致某種隨機事件出現的可能性。可以理解為符合隨機變量取值範圍的某個對象屬於某個類別或服從某種趨勢的可能性。
空間變換
由特征列的取值所構成的矩陣空間應具有完整性,即能夠反映事物的空間形式或變換規律。
向量:具有大小和方向。
向量與矩陣的乘積就是一個向量從一個線性空間(坐標系),通過線性變換,選取一個新的基底,變換到這個新的基底所構成的另一個線性空間的過程。
矩陣與矩陣的乘法 \(C = A \cdot B\):
- \(A\):向量組
- \(B\):線性變換下的矩陣
假設我們考察一組對象 \(\scr{A} = \{\alpha_1, \cdots, \alpha_m\}\),它們在兩個不同維度的空間 \(V^n\) 和 \(V^p\) 的基底分別是 \(\{\vec{e_1}, \cdots, \vec{e_n}\}\) 和 \(\{\vec{d_1}, \cdots, \vec{d_p}\}\),\(T\) 即為 \(V^n\) 到 \(V^p\) 的線性變換,且有(\(k = \{1, \cdots, m\}\)):
\[
\begin{align}
&T
\begin{pmatrix}
\begin{bmatrix}
\vec{e_1} \\ \vdots \\ \vec{e_n}
\end{bmatrix}
\end{pmatrix} =
A
\begin{bmatrix}
\vec{d_1} \\ \vdots \\ \vec{d_p}
\end{bmatrix} \&\alpha_k =
\begin{bmatrix}
x_1^{k} & \cdots & x_n^k
\end{bmatrix}
\begin{bmatrix}
\vec{e_1} \\ \vdots \\ \vec{e_n}
\end{bmatrix}\&T(\alpha_k)=
\begin{bmatrix}
y_1^{k} & \cdots & y_p^k
\end{bmatrix}
\begin{bmatrix}
\vec{d_1} \\ \vdots \\ \vec{d_p}
\end{bmatrix}
\end{align}
\]
令
\[
\begin{cases}
&X^k =
\begin{bmatrix}
x_1^{k} & \cdots & x_n^k
\end{bmatrix}\&Y^k =
\begin{bmatrix}
y_1^{k} & \cdots & y_p^k
\end{bmatrix}
\end{cases}
\]
則記:
\[
\begin{cases}
&X =
\begin{bmatrix}
X^{1} \\ \vdots \\ X^m
\end{bmatrix} \&Y = \begin{bmatrix}
Y^{1} \\ \vdots \\ Y^m
\end{bmatrix}
\end{cases}
\]
由式(1)可知:
\[
\begin{align}
XA = Y
\end{align}
\]
因而 \(X\) 與 \(Y\) 表示一組對象在不同的線性空間的坐標表示。\(A\) 表示線性變換在某個基偶(如,\((\{\vec{e_1}, \cdots, \vec{e_n}\}, \{\vec{d_1}, \cdots, \vec{d_p}\})\))下的矩陣表示。
機器學習的數學基礎