
機器學習數學基礎-線性代數
轉載出處:
從這篇文章開始,我會寫好一個系列的文章,就叫掌握機器學習數學基礎之XX(重點知識)吧,主要講述在機器學習中主要的一些數學基礎。
線性代數
為什麼要寫這個系列?
- 網上文章過於全面,一上來就推薦什麼MIT線性代數,推薦各種微積分,推薦什麼《微積分入門》啊,《概率論入門》啊等等,甚至很多還是英文版的,還要學很多英文術語才能看懂,我覺得沒有必要全看,因為就像MIT的線性代數,很多是我們在機器學習中用不到或者用的及其少但又很難理解的。什麼馬爾可夫矩陣,快速傅立葉變換,若爾當形,哇,有點頭暈....
- 網上文章寫的過於簡略,機器學習雖說不用把多門數學完全學通,但和數學還是有很大關係的,很多文章一篇想概括所有在機器學習中重要的數學基礎。不贊同!寫的太簡略了,還不如寫個目錄,或者跳過太多重要數學基礎,還不如不寫。
- 梳理並複習,我會盡量擷取我認為重要的,並會指出在機器學習哪裡有應用的數學基礎,並儘量寫的通俗,亦寫的有深度。有助於我複習,並達到更新專欄的作用!
注意:我將寫下我認為於機器學習高度相關的數學基礎,很多知識是其他地方學習的,主要來自《deep learning》,我也只是知識的搬運工以及加上自己的看法。
下面開始分節敘述,線性代數部分主要包括如下:
- 標量、向量、矩陣和張量
- 矩陣向量的運算
- 單位矩陣和逆矩陣
- 行列式
- 方差,標準差,協方差矩陣
- 範數
- 特殊型別的矩陣和向量
- 特徵分解以及其意義
- 奇異值分解及其意義
- Moore-Penrose 偽逆
- 跡運算
標量、向量、矩陣和張量
- 標量:一個標量就是一個單獨的數,一般用小寫的變數名稱表示。當然,當我們介紹標量時,要明確它們是哪種型別的數值。這個在寫論文時要注意,比如:在定義自然數標量時,我們可能會說”令n ∈ N表示元素的數目”。
- 向量:在物理學和工程學中,幾何向量更常被稱為向量,這個學過高中數學和物理的就知道,但線上性代數中,經過進一步的抽象,大小和方向的概念亦不一定適用,但我們可以簡單的理解為一列數,通過這列數中的索引,我們可以確定每個單獨的數。通常會賦予向量粗體的小寫名稱。當我們需要明確表示向量中的元素時,我們會將元素排列成一個方括號包圍的縱柱(如下圖):
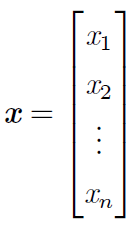
- 矩陣:矩陣是二維陣列,其中的每一個元素被兩個索引而非一個所確定。我們通常會賦予矩陣粗體的大寫變數名稱,比如A。 如果一個實數矩陣高度為m,寬度為n,那麼我們說
,當我們到明確表達矩陣的時候,我們將它們寫在用方括號包圍起來的陣列中,如下圖:
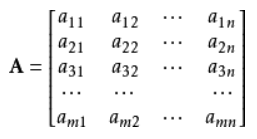
- 張量:線性代數或幾何代數中定義的張量是基於向量和矩陣的推廣,通俗一點理解的話,我們可以將標量視為零階張量,向量(向量)視為一階張量,那麼矩陣就是二階張量。例如,可以將任意一張彩色圖片表示成一個三階張量(就像C語言中的三維陣列),三個維度分別是圖片的高度、寬度和色彩資料。 使用字型 A 來表示張量 “A’’。張量 A 中座標為 (i, j, k) 的元素記作
。
上面的知識重要性不言而喻,這些都不知道就別說學過機器學習了...幾乎一切運算都是基於向量矩陣來進行的,而在tensorflow中,用張量來表示一切資料,並用來運算。
矩陣向量的運算
矩陣乘法:是矩陣運算中最重要的操作之一。兩個矩陣 A 和 B 的 矩陣乘積(matrix product)是第三個矩陣 C。為了使乘法定義良好,矩陣 A 的列數必須和矩陣 B 的行數相等。如果矩陣 A 的形狀是 m × n,矩陣 B 的形狀是 n × p,那麼矩陣C 的形狀是 m × p。我們可以通過將兩個或多個矩陣並列放置以書寫矩陣乘法,例如C = AB.
具體地,該乘法操作定義為 :
舉個例子,如下所示:
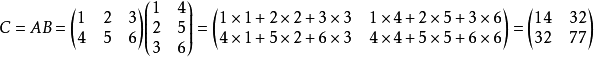
需要注意的是,兩個矩陣的標準乘積不是指兩個矩陣中對應元素的乘積。 不過,那樣的矩陣操作確實是存在的,被稱為元素對應乘積或者Hadamard乘積,記為A B
特別地,兩個相同維數的向量和
的 點積(dot product)可看作是矩陣乘積
。我們可以把矩陣乘積 C =AB 中計算
的步驟看作是 A 的第 i 行和 B 的第 j 列之間的點積。注意,我們有時候也加兩個向量的乘積為內積
矩陣乘積服從分配律:A(B + C) = AB + AC
矩陣乘積也服從結合律:A(BC) = (AB)C
但不同於標量乘積,矩陣乘積並不滿足交換律(AB = BA 的情況並非總是滿足)。
然而,兩個向量的 點積(dot product)滿足交換律 :
矩陣轉置:
- 矩陣轉置的結果為
結果為對稱矩陣,由
,得證
矩陣的乘法和其他運算有必要深究,比如矩陣乘法的意義。在機器學習中,很多運算就是矩陣和向量的運算,而Hadamard乘積在反向傳播推導中也有應用。
單位矩陣和逆矩陣
線性代數提供了被稱為矩陣逆的強大工具。 對於大多數矩陣A,我們都能通過矩陣逆解析地求解。
為了描述矩陣逆,我們首先需要定義單位矩陣的概念。 任意向量和單位矩陣相乘,都不會改變。 我們將保持 維向量不變的單位矩陣記作
。 形式上
。
單位矩陣的結構很簡單:所有沿主對角線的元素都是1,而所有其他位置的元素都是0。 如
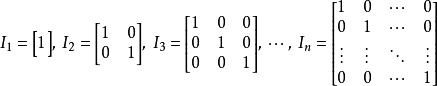
矩陣A的矩陣逆記作 ,其定義的矩陣滿足如下條件
現在我們可以通過以下步驟求解:
由 得
由 得
最終:
求一個矩陣的逆矩陣比較簡單,但是更加重要還有更加有用的是判斷一個矩陣是否存在逆矩陣,這是一個重點難點,由於判別方式也非常的多種,這裡就簡述一些簡單方法:
- 一切不是方陣(行數不等於列數)的矩陣都沒有逆矩陣
- 可逆矩陣就是非奇異矩陣,非奇異矩陣也是可逆矩陣(奇異矩陣涉及到秩的運算,不是很必要學啊,但推薦去了解吧,如果不想學,那知道這句就好)
- 行列式等於0的方陣是奇異矩陣,也就是說行列式不等於0等價於是可逆矩陣
矩陣的求逆運算在機器學習中也有非常廣泛的應用,比如邏輯迴歸,比如SVM等等,也是非常重要的,各類的論文中也會涉及到很多這樣的運算,所以真的必不可少!
行列式
行列式,記作 det(A):是一個將方陣 A 對映到實數的函式。行列式等於矩陣特徵值的乘積。行列式的絕對值可以用來衡量矩陣參與矩陣乘法後空間擴大或者縮小了多少。如果行列式是 0,那麼空間至少沿著某一維完全收縮了,使其失去了所有的體積。如果行列式是 1,那麼這個轉換保持空間體積不變。
行列式也是一個很大的概念,深究起來非常方,如果不想了解很多,那隻需要知道概念就好吧。
方差,標準差,協方差
方差:是衡量隨機變數或一組資料時離散程度的度量,方差計算公式:
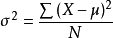
其中 為總體方差,
為變數,
為總體均值,
為總體例數。下面的標準差公式中亦相同。
標準差:也被稱為標準偏差,或者實驗標準差,公式為
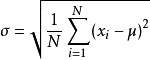
標準差是方差的算術平方根。標準差能反映一個數據集的離散程度。平均數相同的兩組資料,標準差未必相同。
為什麼需要協方差?
我們知道,標準差和方差一般是用來描述一維資料的,但現實生活我們常常遇到含有多維資料的資料集,最簡單的 大家上學時免不了要統計多個學科的考試成績。面對這樣的資料集,我們當然可以按照每一維獨立的計算其方差,但是通常我們還想了解更多,比如,一個男孩子的 猥瑣程度跟他受女孩子歡迎程度是否存在一些聯絡。協方差就是這樣一種用來度量兩個隨機變數關係的統計量。
協方差矩陣
理解協方差矩陣的關鍵就在於牢記它計算的是不同維度之間的協方差,而不是不同樣本之間,拿到一個樣本矩陣,我們最先要明確的就是一行是一個樣本還是一個維度,心中明確這個整個計算過程就會順流而下,這麼一來就不會迷茫了
舉個例子(例子來自這篇文章):
問題:
有一組資料(如下),分別為二維向量,這四個資料對應的協方差矩陣是多少?
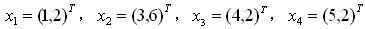
解答:
由於資料是二維的,所以協方差矩陣是一個2*2的矩陣,矩陣的每個元素為:
元素(i,j) = (第 i 維所有元素 - 第 i 維的均值) * (第 j 維所有元素 - 第 j 維的均值) 。
其中「*」代表向量內積符號,即兩個向量求內積,對應元素相乘之後再累加。
我們首先列出第一維:
D1: (1,3,4,5) 均值:3.25
D2: (2,6,2,2) 均值:3
下面計算協方差矩陣第(1,2)個元素:
元素(1,2)=(1-3.25,3-3.25,4-3.25,5-3.25)*(2-3,6-3,2-3,2-3)=-1
類似的,我們可以把2*2個元素都計算出來:
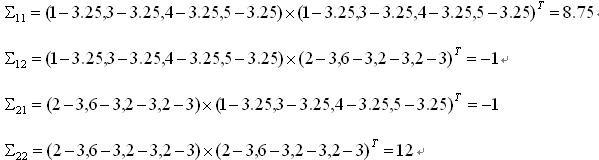
這個題目的最終結果就是:
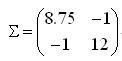
我們來分析一下上面的例子。首先看一下元素(1,1)的計算過程:
把所有資料的第一個維度拿出來,求出均值,之後的求解過程完全是我們熟悉的「方差」的求法。也就是說,這完完全全就是在求所有資料第一維元素(共4個)的方差(8.75)嘛。類似地,元素(2,2)求的是第二維(共4個)元素的方差(12)。
再來看元素(1,2),這分明就是我們高數裡面學的求 x 和 y 的協方差,不再單獨計算某一維度的分散程度,而是把兩個維度的分散值結合起來,這裡才真正體現了「協方差矩陣」中「協方差」的意味。從計算過程和計算結果都能看出,元素(2,1)與元素(1,2)是一樣的。也就是說,所有協方差矩陣都是一個對稱陣。
總結一下協方差矩陣的特點:
- 對角線元素(i,i)為資料第 i 維的方差。
- 非對角線元素(i,j)為第 i 維和第 j 維的協方差。
- 協方差矩陣是對稱陣。
現在只需要瞭解這些就夠了。
這些知識也是非常基礎的,在各個演算法中都有涉及,像偏方差權衡,RL中的方差問題和解決,還有協方差矩陣在二元高斯分佈(在下面一片概率論中會講述)中決定了它的形狀,詳細演示。
範數
什麼是範數,聽得那麼術語..其實就是衡量一個向量大小的單位。在機器學習中,我們也經常使用被稱為範數(norm) 的函式衡量矩陣大小
範數如下:
(為什麼是這樣的,不要管了,要扯就扯偏了,記得是衡量向量或者矩陣大小的就行了)
常見的:
範數
:為x向量各個元素絕對值之和;
範數
:為x向量各個元素平方和的開方,這個也就是兩點直線距離嘛,回憶初高中的知識!
注意:當 p = 2 時, 範數被稱為 歐幾里得範數(Euclidean norm)。它表示從原點
出發到向量 x 確定的點的歐幾里得距離。 範數在機器學習中出現地十分頻繁
經常簡化表示為 ∥x∥,略去了下標 2。平方 範數也經常用來衡量向量的大小,可以
簡單地通過點積 計算。
這些知識在各大演算法(如SVM)中亦有涉及,而且在距離量度中的歐式距離,華盛頓距離都有密切關係。
特殊型別的矩陣和向量
有些特殊型別的矩陣和向量是特別有用的,也相當於一些術語,比如一些文章直接說是XX矩陣或者XX向量,這個時候我們應該要明白這些矩陣或者向量是什麼樣子的,還有什麼樣的性質!
對角矩陣(diagonal matrix):只在主對角線上含有非零元素,其他位置都是零。形式上,矩陣 是對角矩陣,當且僅當對於所有的
特殊的:單位矩陣是對角元素全部是 1的對角矩陣。
單位向量:指模等於1(具有 單位範數)的向量。由於是非零向量,單位向量具有確定的方向。單位向量有無數個。
也就是說:對於單位向量,有 = 1.
對稱矩陣:是轉置和自己相等的矩陣:
當某些不依賴引數順序的雙引數函式生成元素時,對稱矩陣經常會出現, 例如,如果A是一個距離度量矩陣, 表示點
到點
的距離,那麼
,因為距離函式是對稱的。
正交矩陣:是指行向量和列向量是分別標準正交的方陣:
這意味著
所以正交矩陣受到關注是因為求逆計算代價小。 我們需要注意正交矩陣的定義。 違反直覺的是,正交矩陣的行向量不僅是正交的,還是標準正交的。 對於行向量或列向量互相正交但不是標準正交的矩陣,沒有對應的專有術語。
特徵分解以及其意義
許多數學物件可以通過將它們分解成多個組成部分,或者找到它們的一些屬性而更好地理解,這些屬性是通用的,而不是由我們選擇表示它們的方式引起的。
例如:整數可以分解為質數。 我們可以用十進位制或二進位制等不同方式表示整數12,但質因數分解永遠是對的12=2×3×3。 從這個表示中我們可以獲得一些有用的資訊,比如12不能被5整除,或者12的倍數可以被3整除。
正如我們可以通過分解質因數來發現整數的一些內在性質,我們也可以通過分解矩陣來發現矩陣表示成陣列元素時不明顯的函式性質。
- 特徵分解是使用最廣的矩陣分解之一,即我們將矩陣分解成一組特徵向量和特徵值。
- 一個變換(或者說矩陣)的特徵向量就是這樣一種向量,它經過這種特定的變換後保持方向不變,只是進行長度上的伸縮而已。
特徵向量的原始定義:
可以很容易看出, 是方陣
對向量
進行變換後的結果,顯然
和
的方向相同。
是特徵向量的話,
表示的就是特徵值。
求解:令 A 是一個 N×N 的方陣,且有 N 個線性無關的特徵向量
這樣, A 可以被分解
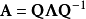
其中 Q 是N×N方陣,且其第 i列為 A 的特徵向量 。 Λ 是對角矩陣,其對角線上的元素為對應的特徵值,也即
這裡需要注意只有可對角化矩陣才可以作特徵分解。比如
![]()
不能被對角化,也就不能特徵分解。
特徵值及特徵向量的幾何意義和物理意義:
在空間中,對一個變換而言,特徵向量指明的方向才是很重要的,特徵值不那麼重要。雖然我們求這兩個量時先求出特徵值,但特徵向量才是更本質的東西!特徵向量是指經過指定變換(與特定矩陣相乘)後不發生方向改變的那些向量,特徵值是指在經過這些變換後特徵向量的伸縮的倍數,也就是說矩陣對某一個向量或某些向量只發生伸縮變換,不對這些向量產生旋轉的效果,那麼這些向量就稱為這個矩陣的特徵向量,伸縮的比例就是特徵值。
物理的含義就是影象的運動:特徵向量在一個矩陣的作用下作伸縮運動,伸縮的幅度由特徵值確定。特徵值大於1,所有屬於此特徵值的特徵向量身形暴長;特徵值大於0小於1,特徵向量身形猛縮;特徵值小於0,特徵向量縮過了界,反方向到0點那邊去了。
注意:常有教科書說特徵向量是在矩陣變換下不改變方向的向量,實際上當特徵值小於零時,矩陣就會把特徵向量完全反方向改變,當然特徵向量還是特徵向量。我也贊同特徵向量不改變方向的說法:特徵向量永遠不改變方向,改變的只是特徵值(方向反轉特徵值為負值了)。特徵向量也是線性不變數。
特徵分解的重要應用--PCA(主成分分析):
舉個栗子:機器學習中的分類問題,給出178個葡萄酒樣本,每個樣本含有13個引數,比如酒精度、酸度、鎂含量等,這些樣本屬於3個不同種類的葡萄酒。任務是提取3種葡萄酒的特徵,以便下一次給出一個新的葡萄酒樣本的時候,能根據已有資料判斷出新樣本是哪一種葡萄酒。
原資料有13維,但這之中含有冗餘,減少資料量最直接的方法就是降維。做法:把資料集賦給一個178行13列的矩陣R,減掉均值並歸一化,它的協方差矩陣C是13行13列的矩陣,對C進行特徵分解,對角化,其中U是特徵向量組成的矩陣,D是特徵值組成的對角矩陣,並按由大到小排列。然後,另R’ =RU,就實現了資料集在特徵向量這組正交基上的投影。嗯,重點來了,R’中的資料列是按照對應特徵值的大小排列的,後面的列對應小特徵值,去掉以後對整個資料集的影響比較小。比如,現在我們直接去掉後面的7列,只保留前6列,就完成了降維。
這個降維方法就叫PCA(Principal Component Analysis)。降維以後分類錯誤率與不降維的方法相差無幾,但需要處理的資料量減小了一半(不降維需要處理13維,降維後只需要處理6維)。在深度學習之前,影象處理是很常用到PCA的,PCA是一個非常不錯的降維方法!
奇異值分解及其意義
奇異值分解就是將矩陣 A 分解成三個矩陣的乘積:
假設 A 是一個 m × n 的矩陣,那麼 U 是一個 m × m 的矩陣,D 是一個 m × n的矩陣,V 是一個 n × n 矩陣。這些矩陣中的每一個經定義後都擁有特殊的結構。矩陣 U 和 V 都被定義為正交矩陣,而矩陣 D 被定義為對角矩陣。注意:矩陣 D 不一定是方陣。
求解比較複雜,詳細推薦檢視這篇奇異值分解
奇異值分解的意義:
奇異值分解的含義是,把一個矩陣A看成線性變換(當然也可以看成是資料矩陣或者樣本矩陣),那麼這個線性變換的作用效果是這樣的,我們可以在原空間找到一組標準正交基V,同時可以在對應空間找到一組標準正交基U,我們知道,看一個矩陣的作用效果只要看它在一組基上的作用效果即可,在內積空間上,我們更希望看到它在一組標準正交基上的作用效果。而矩陣A在標準正交基V上的作用效果恰好可以表示為在U的對應方向上只進行純粹的伸縮!這就大大簡化了我們對矩陣作用的認識,因為我們知道,我們面前不管是多麼複雜的矩陣,它在某組 標準正交基上的作用就是在另外一組標準正交基上進行伸縮而已。
更加詳細的講述請看:奇異值的意義
特徵分解也是這樣的,也可以簡化我們對矩陣的認識。對於可對角化的矩陣,該線性變換的作用就是將某些方向(特徵向量方向)在該方向上做伸縮。
有了上述認識,當我們要看該矩陣對任一向量x的作用效果的時候,在特徵分解的視角下,我們可以把x往特徵向量方向上分解,然後每個方向上做伸縮,最後再把結果加起來即可;在奇異值分解的視角下,我們可以把x往V方向上分解,然後將各個分量分別對應到U方向上做伸縮,最後把各個分量上的結果加起來即可。
奇異值分解和上面所講的特徵分解有很大的關係,而我的理解是:
- 不是所有的矩陣都能對角化(對稱矩陣總是可以),而所有矩陣總是可以做奇異值分解的。那麼多型別的矩陣,我們居然總是可以從一個統一且簡單的視角去看它,我們就會感嘆奇異值分解是多麼奇妙了!
- 協方差矩陣(或
)的奇異值分解結果和特徵值分解結果一致。所以在PCA中,SVD是一種實現方式
上面的知識可能需要其他的一些前置知識,但我認為也不必要非學,用的不多,可以遇到再學吧,我們知道其主要公式,意義和應用就好,重要性也一目瞭然,對於矩陣的變換運算,比如降維(PCA)或推薦系統中都有其重要的作用。
Moore-Penrose 偽逆
對於非方矩陣而言,其逆矩陣沒有定義。假設在下面問題中,我們想通過矩陣A的左逆B來求解線性方程:
等式兩邊同時左乘左逆B後,得到:
是否存在唯一的對映將A對映到B取決於問題的形式。
如果矩陣A的行數大於列數,那麼上述方程可能沒有解;如果矩陣A的行數小於列數,那麼上述方程可能有多個解。
Moore-Penrose偽逆使我們能夠解決這種情況,矩陣A的偽逆定義為:
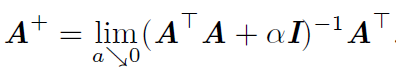
但是計算偽逆的實際演算法沒有基於這個式子,而是使用下面的公式:
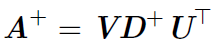
其中,矩陣U,D 和V 是矩陣A奇異值分解後得到的矩陣。對角矩陣D 的偽逆D+ 是其非零元素取倒之後再轉置得到的。
注意,這裡的偽逆也是應用奇異值分解來求得的,這就很好體現知識是聯絡的啦,偽逆的應用在機器學習中也是大量存在的,比如最簡單的線性迴歸中求廣義逆矩陣,也就是偽逆。
跡運算
跡運算返回的是矩陣對角元素的和:
跡運算因為很多原因而有用。 若不使用求和符號,有些矩陣運算很難描述,而通過矩陣乘法和跡運算子號可以清楚地表示。 例如,跡運算提供了另一種描述矩陣Frobenius 範數的方式:
(不必知道是什麼,只要知道有這樣的運算就好,如果有興趣,當然可以去了解)
用跡運算表示表示式,我們可以使用很多有用的等式巧妙地處理表達式。 例如,跡運算在轉置運算下是不變的:
多個矩陣相乘得到的方陣的跡,和將這些矩陣中的最後一個挪到最前面之後相乘的跡是相同的。 當然,我們需要考慮挪動之後矩陣乘積依然定義良好:Tr(ABC) = Tr(CAB) = Tr(BCA).
跡運算也是常用的數學知識,比如這些知識在正規方程組計算中就有著重要的作用。