
OCR技術淺探(轉)
網址:https://spaces.ac.cn/archives/3785
OCR技術淺探
作為OCR系統的第一步,特征提取是希望找出圖像中候選的文字區域特征,以便我們在第二步進行文字定位和第三步進行識別. 在這部分內容中,我們集中精力模仿肉眼對圖像與漢字的處理過程,在圖像的處理和漢字的定位方面走了一條創新的道路. 這部分工作是整個OCR系統最核心的部分,也是我們工作中最核心的部分.
傳統的文本分割思路大多數是“邊緣檢測 + 腐蝕膨脹 + 聯通區域檢測”,如論文[1]. 然而,在復雜背景的圖像下進行邊緣檢測會導致背景部分的邊緣過多(即噪音增加),同時文字部分的邊緣信息則容易被忽略,從而導致效果變差. 如果在此時進行腐蝕或膨脹,那麽將會使得背景區域跟文字區域粘合,效果進一步惡化.(事實上,我們在這條路上已經走得足夠遠了,我們甚至自己寫過邊緣檢測函數來做這個事情,經過很多測試,最終我們決定放棄這種思路。)
因此,在本文中,我們放棄了邊緣檢測和腐蝕膨脹,通過聚類、分割、去噪、池化等步驟,得到了比較良好的文字部分的特征,整個流程大致如圖2,這些特征甚至可以直接輸入到文字識別模型中進行識別,而不用做額外的處理.由於我們每一部分結果都有相應的理論基礎作為支撐,因此能夠模型的可靠性得到保證.
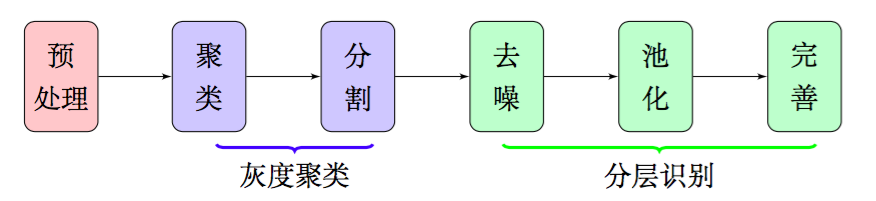
圖2:特征提取大概流程
在這部分的實驗中,我們以圖3來演示我們的效果. 這個圖像的特點是尺寸中等,背景較炫,色彩較為豐富,並且文字跟圖片混合排版,排版格式不固定,是比較典型的電商類宣傳圖片. 可以看到,處理這張圖片的要點就是如何識別圖片區域和文字區域,識別並剔除右端的電飯鍋,只保留文字區域.

圖3:小米電飯鍋介紹圖
圖像的預處理 ?
首先,我們將原始圖片以灰度圖像的形式讀入,得到一個m×nm×n的灰度矩陣MM,其中m,nm,n是圖像的長、寬. 這樣讀入比直接讀入RGB彩色圖像維度更低,同時沒有明顯損失文字信息. 轉換為灰度圖事實上就是將原來的RGB圖像的三個通道以下面的公式整合為一個通道:
圖3的灰度圖如下圖.

灰度圖像
圖像本身的尺寸不大,如果直接處理,則會導致文字筆畫過小,容易被當成噪音處理掉,因此為了保證文字的筆畫有一定的厚度,可以先將圖片進行放大. 在我們的實驗中,一般將圖像放大為原來的兩倍就有比較好的效果了.
不過,圖像放大之後,文字與背景之間的區分度降低了. 這是因為圖片放大時會使用插值算法來填補空缺部分的像素. 這時候需要相應地增大區分度. 經過測試,在大多數圖片中,使用次數為2的“冪次變換”效果較好. 冪次變換為
x?xr(2)(2)x?xr
其中xx代表矩陣MM中的元素,rr為次數,在這裏我們選取為2. 然後需要將結果映射到[0,255][0,255]區間:
其中Mmax,MminMmax,Mmin是矩陣MM的最大值和最小值. 經過這樣處理後,圖像如下圖.

冪次變換
灰度聚類 ?
接著我們就對圖像的色彩進行聚類. 聚類的有兩個事實依據:
1. 灰度分辨率 肉眼的灰度分辨率大概為40,因此對於像素值254和255,在我們肉眼看來都只是白色;
2. 設計原則 根據我們一般的審美原則,在考慮海報設計、服裝搭配等搭配的時候,一般要求在服裝、海報等顏色搭配不超過三種顏色.
更通俗地說,雖然灰度圖片色階範圍是[0,255][0,255],但我們能感覺到的整體的色調一般不多,因此,可以將相近的色階歸為一類,從而減少顏色分布,有效地降低噪音.
事實上,聚類是根據圖像的特點自適應地進行多值化的過程,避免了傳統的簡單二值化所帶來的信息損失. 由於我們需要自動地確定聚類數目,因此傳統的KMeans等聚類方法被我們拋棄了,而且經過我們測試,諸如MeanShift等可行的聚類方法又存在速度較慢等缺陷. 因此,我們自行設計了聚類方法,使用的是“核概率密度估計”的思路,通過求顏色密度極值的方式來聚類.
核密度估計
經過預處理的圖像,我們可以對每個色階的出現次數進行統計,得到如圖5的頻率分布直方圖:
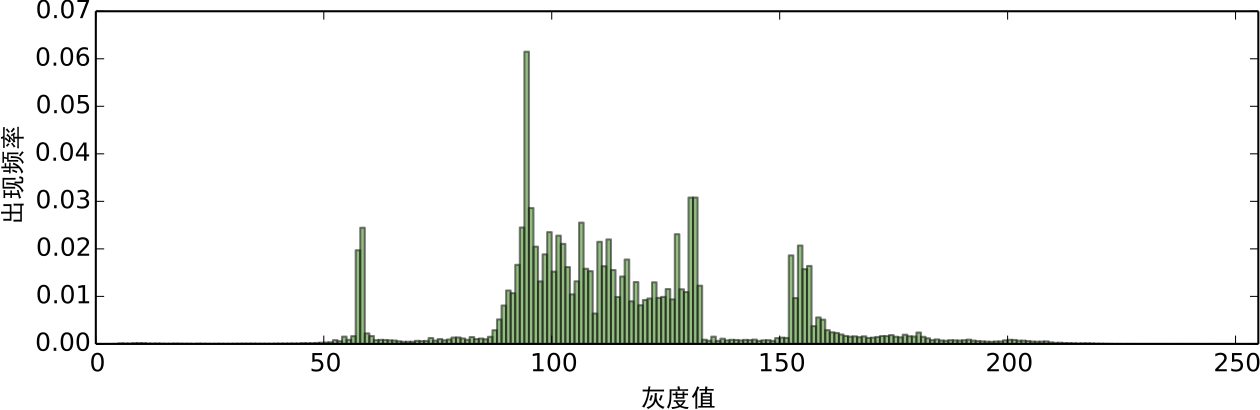
圖5:對預處理後的圖像進行灰色階統計
可以看到,色階的分布形成了幾個比較突出的峰,換言之,存在一定的聚類趨勢. 然而,直方圖的統計結果是不連續的,一個平滑的結果更便於我們分析研究,結果也更有說服力. 將統計結果平滑化的方法,就是核密度估計(kernel density estimation).
核密度估計方法是一種非參數估計方法,由Rosenblatt和Parzen提出,在統計學理論和應用領域均受到高度的重視[2]. 當然,也可以簡單地將它看成一種函數平滑方式. 我們根據大量的數據來估計某個值出現的概率(密度)時,事實上做的是如下估算:
p^(x)=1nh∑i=1nK(x?xih)(4)(4)p^(x)=1nh∑i=1nK(x?xih)
其中K(x)K(x)稱為核函數. 當hh取為1,且K(x)K(x)取
時,就是我們上述的直方圖估計. K(x)K(x)這一項的含義很簡單,它就是告訴我們在範圍hh內的xixi都算入到xx中去,至於怎麽算,由K(x?xih)K(x?xih)給出. 可見,hh的選擇對結果的影響很大,hh我們稱之為帶寬(bandwidth),它主要影響結果的平滑性.
如果K(x)K(x)是離散的,得到的結果還是離散的,但如果K(x)K(x)是光滑的,得到的結果也是比較光滑的. 一個常用的光滑函數核是高斯核:
所得到的估計也叫高斯核密度估計. 在這裏,我們使用scott規則自適應地選取hh,但需要手動指定一個平滑因子,在本文中,我們選取為0.2.對於示例圖片,我們得到如圖6的紅色曲線的結果.
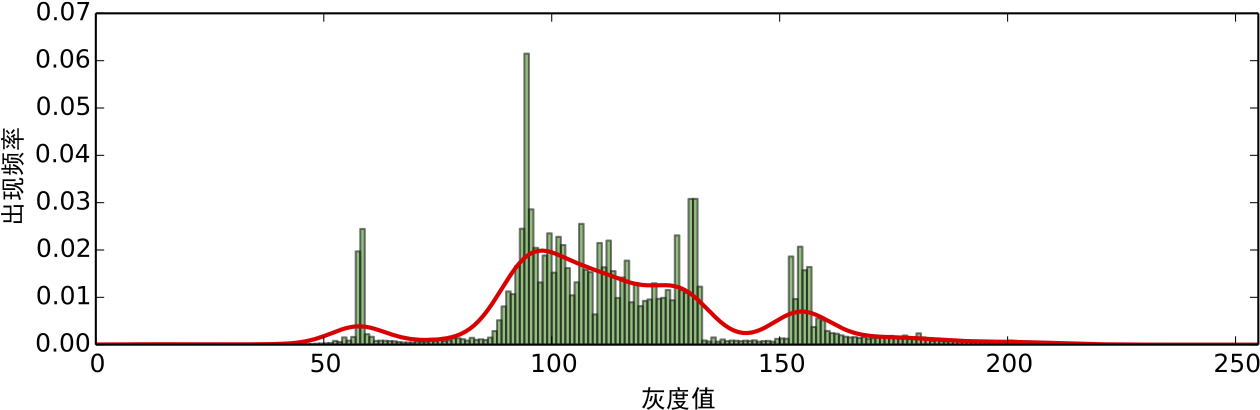
圖6:頻率分布的高斯核密度估計
極大極小值分割
從圖6中我們進一步可以看出,圖像確實存在著聚類趨勢. 這表現為它有幾個明顯的極大值和極小值點,這裏的極大值點位於x=10,57,97,123,154x=10,57,97,123,154,極小值點位於25,71,121,14225,71,121,142.
因此,一個很自然的聚類方法是:有多少個極大值點,就聚為多少類,並且以極小值點作為類別之間的邊界. 也就是說,對於圖3,可以將圖像分層5層,逐層處理. 分層之後,每一層的形狀如下圖,其中白色是1,黑色是0.

圖層1

圖層2

圖層3

圖層4

圖層5
通過聚類將圖像分為5個圖層
可見,由於“對比度”和“漸變性”假設,通過聚類確實可以將文字圖層通過核密度估計的聚類方法分離開來. 而且,通過聚類分層的思路,無需對文字顏色作任何假定,即便是文字顏色跟背景顏色一致時,也可以獲得有效檢測.
OCR技術淺探(轉)