
OCR技術淺探:特徵提取(1)
研究背景
關於光學字元識別(Optical Character Recognition, 下面都簡稱OCR),是指將影象上的文字轉化為計算機可編輯的文字內容,眾多的研究人員對相關的技術研究已久,也有不少成熟的OCR技術和產品產生,比如漢王OCR、ABBYY FineReader、Tesseract OCR等. 值得一提的是,ABBYY FineReader不僅正確率高(包括對中文的識別),而且還能保留大部分的排版效果,是一個非常強大的OCR商業軟體.
然而,在諸多的OCR成品中,除了Tesseract OCR外,其他的都是閉源的、甚至是商業的軟體,我們既無法將它們嵌入到我們自己的程式中,也無法對其進行改進. 開源的唯一選擇是Google的Tesseract OCR,但它的識別效果不算很好,而且中文識別正確率偏低,有待進一步改進.
綜上所述,不管是為了學術研究還是實際應用,都有必要對OCR技術進行探究和改進. 我們隊伍將完整的OCR系統分為“特徵提取”、“文字定位”、“光學識別”、“語言模型”四個方面,逐步進行解決,最終完成了一個可用的、完整的、用於印刷文字的OCR系統. 該系統可以初步用於電商、微信等平臺的圖片文字識別,以判斷上面資訊的真偽.
研究假設
在本文中,我們假設影象的文字部分有以下的特徵:
1. 假設我們要識別的影象字型都是比較規範的印刷字型,如宋體、黑體、楷體、行書等;
2. 文字與背景應該有比較明顯的對比度;
3. 在設計模型的時候,我們假設了圖片文字是橫向排版的;
4. 文字的筆畫應該有一定的寬度,不可以太細;
5. 同一個文字的色彩應該最多是漸變的;
6. 一般文字是通過比較密集的筆畫成字的,並且很多時候都具有一定的連通性.
可以看到,這些特徵都是常見的電商宣傳海報等的常見特點,因此這些假設都是比較合理的.
分析流程

圖1:我們的實驗流程圖
特徵提取
作為OCR系統的第一步,特徵提取是希望找出影象中候選的文字區域特徵,以便我們在第二步 進行文字定位和第三步進行識別。在這部分內容中,我們集中精力模仿肉眼對影象與漢字的處理過程,在影象的處理和漢字的定位方面走了一條創新的道路。這部分工作是整個OCR系統最核心的部分,也是我們工作中最核心的部分。
傳統的文字分割思路大多數是“邊緣檢測 + 腐蝕膨脹 + 聯通區域檢測”,如論文[1]。 然而,在複雜背景的影象下進行邊緣檢測會導致背景部分的邊緣過多(即噪音增加),同時文字部分的邊緣 資訊則容易被忽略,從而導致效果變差。 如果在此時進行腐蝕或膨脹,那麼將會使得背景區域跟文字區域粘合,效果進一步惡化。(事實上,我們在這條路上已經走得足夠遠了,我們甚至自己寫過邊緣檢測函式來做這個事情,經過很多測試,最終我們決定放棄這種思路。)
因此,在本文中,我們放棄了邊緣檢測和腐蝕膨脹,通過聚類、分割、去噪、池化等步驟,得到了比較良好的文字部分的特徵,整個流程大致如圖2,這些特徵甚至可以直接輸入到文字識 別模型中進行識別,而不用做額外的處理。由於我們每一部分結果都有相應的理論基礎作為支撐,因此能夠模型的可靠性得到保證。
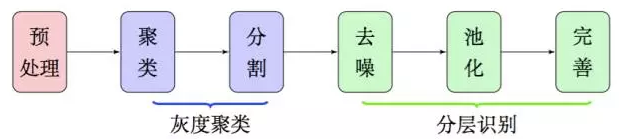
圖2:特徵提取大概流程
在這部分的實驗中,我們以圖3來演示我們的效果。這個影象的特點是尺寸中等,背景較炫,色彩較為豐富,並且文字跟圖片混合排版,排版格式不固定,是比較典型的電商類宣傳圖片。可以看到,處理這張圖片的要點就是如何識別圖片區域和文字區域,識別並剔除右端的電飯鍋,只保留文字區域。

圖3:小米電飯鍋介紹圖
影象的預處理
首先,我們將原始圖片以灰度影象的形式讀入,得到一個的灰度矩陣,其中m, n 是影象的長、寬。這樣讀入比直接讀入RGB彩色影象維度更低,同時沒有明顯損失文字資訊。轉換為灰度圖事實上就是將原來的RGB影象的三個通道以下面的公式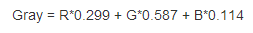 (1)
(1)
整合為一個通道:

圖3的灰度圖如下圖
影象本身的尺寸不大,如果直接處理,則會導致文字筆畫過小,容易被當成噪音處理掉,因此為了保證文字的筆畫有一定的厚度,可以先將圖片進行放大。 在我們的實驗中,一般將影象放大為原來的兩倍就有比較好的效果了。
不過,影象放大之後,文字與背景之間的區分度降低了。這是因為圖片放大時會使用插值演算法來填補空缺部分的畫素。這時候需要相應地增大區分度。經過測試,在大多數圖片中,使用次數為2的“冪次變換”效果較好。冪次變換為
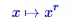 (2)
(2)
其中x代表矩陣M中的元素,r為次數,在這裡我們選取為2。 然後需要將結果對映到[0,255]區間:
 (3)
(3)
其中 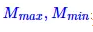 是矩陣的最大值和最小值。
是矩陣的最大值和最小值。
灰色聚類
接著我們就對影象的色彩進行聚類。聚類的有兩個事實依據:
-
灰度解析度 肉眼的灰度解析度大概為40,因此對於畫素值254和255,在我們肉眼看來都 只是白色;
-
設計原則 根據我們一般的審美原則,在考慮海報設計、服裝搭配等搭配的時候,一般要 求在服裝、海報等顏色搭配不超過三種顏色。
更通俗地說,雖然灰度圖片色階範圍是[0, 255],但我們能感覺到的整體的色調一般不多,因此,可以將相近的色階歸為一類,從而減少顏色分佈,有效地降低噪音。
事實上,聚類是根據影象的特點自適應地進行多值化的過程,避免了傳統的簡單二值化所帶來 的資訊損失。由於我們需要自動地確定聚類數目,因此傳統的KMeans等聚類方法被我們拋棄 了,而且經過我們測試,諸如MeanShift等可行的聚類方法又存在速度較慢等缺陷。因此,我們 自行設計了聚類方法,使用的是“核概率密度估計”的思路,通過求顏色密度極值的方式來聚類。
核密度估計 經過預處理的影象,我們可以對每個色階的出現次數進行統計,得到如圖5的頻率分佈直方圖:
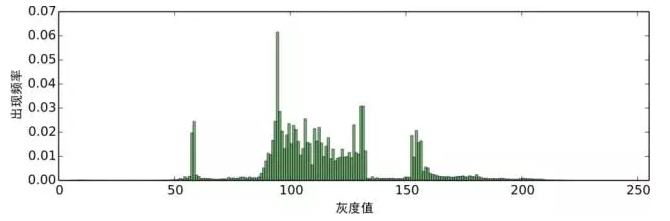
圖5:對預處理後的影象進行灰色階統計
可以看到,色階的分佈形成了幾個比較突出的峰,換言之,存在一定的聚類趨勢。 然而,直方 圖的統計結果是不連續的,一個平滑的結果更便於我們分析研究,結果也更有說服力。 將統計 結果平滑化的方法,就是核密度估計(kernel density estimation)。
核密度估計方法是一種非引數估計方法,由Rosenblatt和Parzen提出,在統計學理論和應用領 域均受到高度的重視[2]。 當然,也可以簡單地將它看成一種函式平滑方式。 我們根據大量的資料 來估計某個值出現的概率(密度)時,事實上做的是如下估算:
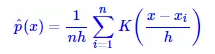 (4)
(4)
其中K(x)稱為核函式。 當 取為1,且K(x)取
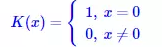 (5)
(5)
時,就是我們上述的直方圖估計。 K(x)這一項的含義很簡單,它就是告訴我們在範圍h內的都算入到x中去,至於怎麼算,由
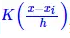 給出。可見,h的選擇對結果的影響很大,h我們稱之為頻寬(bandwidth),它主要影響結果的平滑性。
如果K(x)是離散的,得到的結果還是離散的,但如果K(x)是光滑的,得到的結果也是比較光滑的。一個常用的光滑函式核是高斯核:
給出。可見,h的選擇對結果的影響很大,h我們稱之為頻寬(bandwidth),它主要影響結果的平滑性。
如果K(x)是離散的,得到的結果還是離散的,但如果K(x)是光滑的,得到的結果也是比較光滑的。一個常用的光滑函式核是高斯核:
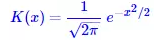 (6)
(6)
所得到的估計也叫高斯核密度估計。 在這裡,我們使用scott規則自適應地選取 ,但需要手動指定一個平滑因子,在本文中,我們選取為0。2。對於示例圖片,我們得到如圖6的紅色曲線的結果。
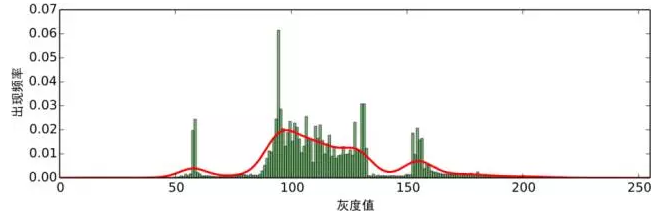
圖6:頻率分佈的高斯核密度估計
極大極小值分割
從圖6中我們進一步可以看出,影象確實存在著聚類趨勢。 這表現為它有幾個明顯的極大值和極 小值點,這裡的極大值點位於x = 10, 57, 97, 123, 154,極小值點位於25, 71, 121, 142。
因此,一個很自然的聚類方法是:有多少個極大值點,就聚為多少類,並且以極小值點作為類 別之間的邊界。 也就是說,對於圖3,可以將影象分層5層,逐層處理。 分層之後,每一層的形狀 如下圖,其中白色是1,黑色是0。

通過聚類將影象分為5個圖層
可見,由於“對比度”和“漸變性”假設,通過聚類確實可以將文字圖層通過核密度估計的聚類方 法分離開來。 而且,通過聚類分層的思路,無需對文字顏色作任何假定,即便是文字顏色跟背 景顏色一致時,也可以獲得有效檢測。
逐層識別
當影象有效地進行分層後,我們就可以根據前面的假設,進一步設計相應的模型,通過逐層處 理的方式找出影象中的文字區域。
連通性
可以看到,每一層的影象是由若干連通區域組成的,文字本身是由筆畫較 為密集組成的,因此往往文字也能夠組成一個連通區域。這裡的連通定義為 8鄰接,即某個畫素周圍的8個畫素都定義為鄰接畫素,鄰接的畫素則被定 義為同一個連通區域。
定義了連通區域後,每個圖層被分割為若干個連通區域,也就是說,我們 逐步地將原始影象進行分解,如圖9。
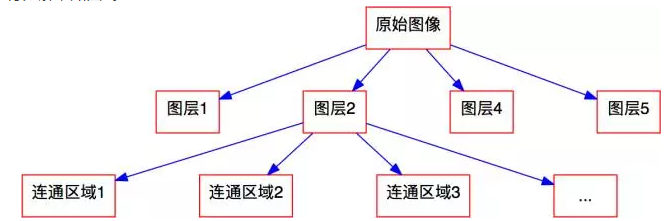
圖9 影象分解結構圖
抗腐蝕能力 將影象分解至連通區域這一粒度後,我們就不再細分了,下一步開始識別哪些區域是可能的文字區域。 這裡我們要求文字具有一定的抗腐蝕能力。 因此我們先來定義腐蝕。
腐蝕是一種影象上的形態學變換,一般針對於二值影象,對於二值影象中的非零畫素(即取值為 1的畫素),如果它鄰接的畫素都為1,則保持不變,否則變為0,這裡我們同樣採用的是8鄰接的 定義。 可以看到,如果連通區域的邊界線越長,那麼腐蝕運算對它的“傷害”就越大,反之,如果 連通區域的邊界線越短,那麼腐蝕運算對它的“傷害”就越小。
根據以上腐蝕的定義,我們可以給出一個對文字區域的要求:
抗腐蝕要求 文字所在的連通區域應當具有一定的抗腐蝕能力。
這裡的“一定”是指在一個連續的範圍內,不能太大,也不能太小。 比如,一個面積較大的方形區 域,它的抗腐蝕能力是很強的,因為它邊界線很短,但這些區域明顯不是文字區域,上一篇文 章中分解後圖層5的電飯鍋便是屬於這一型別;此外,抗腐蝕能力太弱也不可以,比如細長的 線條,腐蝕之後可能就消失了,這些也不作為候選的文字區域,上一篇文章中分解後圖層4的 文字邊界線就屬於這一型別。
這裡可以定義一個抗腐蝕能力的指標:
連通區域的抗腐蝕能力 = 該區域被腐蝕後的總面積/該區域被腐蝕前的總面積 (7)
經過測試,文字區域的抗腐蝕能力大概在[0.1, 0.9]這個區間中。
經過抗腐蝕能力篩選分解的5個圖層,得到如下圖的特徵層。


只保留抗腐蝕能力在[0。1, 0。9]這個區間中的連通區域
池化操作 到現在為止,我們得到了5個特徵層,雖然肉眼可以看到,文字主要集中在第5個特徵層。但是,對於一般的圖片,文字可能分佈在多個特徵層,因此需要對特徵層進行整合。我們這裡進行特徵整合的方法,類似於卷積神經網路中的“池化”,因此我們也借用了這個名稱。 首先,我們將5個特徵層進行疊加,得到一幅整體的影象特徵(稱為疊加特徵)。這樣的影象特徵可以當作最後的特徵輸出,但並不是最好的方法。我們認為,某個區域內的主要文字特徵應該已經集中分佈在某個特徵層中,而不是分散在所有的特徵層。因此,得到疊加特徵後,使用類 似“最大值池化”的方式整合特徵,步驟如下:
1。直接疊加特徵,然後對疊加特徵劃分連通區域;
2。檢測每個連通區域的主要貢獻是哪個特徵層,該連通區域就只保留這個特徵層的來源。
經過這樣的池化操作後,得到的最終特徵結果如圖11。

圖11 池化後的特徵
後期處理
對於我們演示的這幅影象,經過上述操作後,得到的特徵圖11已經不用再做什麼處理了。 然而, 對於一般的圖片,還有可能出現一些沒處理好的區域,這時候需要在前述結果的基礎上進一步 排除。 排除過程主要有兩個步驟,一個是低/高密度區排除,另外則是孤立區排除。
密度排除 一種明顯不是文字區域的連通區域是低密度區,一個典型的例子就是由表格線組成的連通區域,這樣的區域範圍較大,但點很少,也就是密度很低,這種低密度區可以排除。 首先我們來定義連通區域密度和低密度區:
連通區域密度 從一個連通區域出發,可以找到該連通區域的水平外切矩形,該區域的密度定義為
連通區域密度 =連通區域的面積/外切矩形的面積×原影象總面積/外切矩形的面積 (8)
低密度區 如果一個連通區域的密度小於16,那麼這個連通區域定義為低密度區。
直覺上的定義應該是連通區域的面積 / 外切矩形的面積,但這裡多了一個因子原影象總面積 / 外切矩形的面積,目的是把面積大小這個影響因素加進去,因為文字一般有明顯的邊界,容易被分割開來,所以一般來說面積越大的區域越不可能是文字區域。這裡的引數16是經驗值。 低密度區排除是排除表格等線條較多的非文字區域的有效方法。類似地,範圍較大的高密度區也是一類需要排除的區域。 有了低密度區之後,就很容易定義高密度區了:
高密度區定義* 如果一個連通區域以水平外切矩形反轉後的區域是一個低密度區,那個這個 連通區域定義為高密度區。
這個定義是很自然的,但是卻有一定的不合理性。比如“一”字,是一個水平的矩形,於是翻轉後 的密度為0,於是這個“一”字就被排除了,這是不合理的。 解決這個問題的一個方案是:
高密度區定義 當且僅當下面條件滿足時才被定義為高密度區:
(矩形的面積 −連通區域的面積)/外切矩形的面積× 外切矩形的面積/原影象總面積< 16 (9)
這是在原來定義的基礎上加上了1,防止了翻轉後密度為0的情況。
還有另外一種失效的情況,就是假如輸入圖片是單字圖片,那麼只有一個連通區域,且原影象總面積 外切矩形的面積接近於1,因此它就被判為低密度區,這樣就排除了單字。這種情形確實比較難兼顧。一個可行的解決辦法是通過人工指定是單字模式、單行模型還是整體圖片模式,Google的Tesseract OCR也提供了這樣的選項。
孤立區
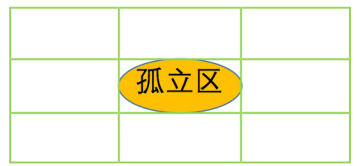
孤立區排除的出發點是:文字之間、筆畫之間應該是比較緊 湊的,如果一個區域明顯地孤立於其他區域,那麼這個區域 很可能不是文字區域。 也就是說,可以把孤立區給排除掉。 首 先我們定義孤立區的概念:
孤立區 從一個連通區域出發,可以找到該連通區域的水平外切矩形,將這個矩形中心對稱 地向外擴張為原來的9倍(長、寬變為原來的3倍,如左圖),擴充套件後的區域如果沒有包含其他 的連通區域,那麼原來的連通區域稱為孤立區。
在大多數情況,孤立區排除是一種非常簡單有效的去噪方法,因為很多噪音點都是孤立區。 但是孤立區排除是會存在一定風險的。 如果一幅影象只有一個文字,構成了唯一一個連通區域, 那麼這個連通區域就是孤立的,於是這個文字就被排除了。因此,要對孤立區加上更多的限制,一個可選的額外限制是:被排除的孤立區的佔連通區域的面積 / 外切矩形的面積要大於0.75(這個值源於圓與外切正方形的面積之比 π / 4)。