
0、weka學習與使用
轉載自:https://blog.csdn.net/u011067360/article/details/20844443
數據挖掘開源軟件:WEKA基礎教程
本文檔部分來自於網絡,隨著自己的深入學習,講不斷的修訂和完善。
第一節 Weka簡介:
Weka是由新西蘭懷卡托大學開發的智能分析系統(Waikato Environment for Knowledge Analysis) 。在懷卡托大學
以外的地方,Weka通常按諧音念成Mecca,是一種現今僅存活於新西蘭島的,健壯的棕色鳥, 非常害羞,好奇心很強,但不會飛 。
Weka是用Java寫成的,它可以運行於幾乎所有的操作平臺,包括Linux,Windows等操作系統。
Weka平臺提供一個統一界面,匯集了當今最經典的機器學習算法及數據預處理工具。做為知識獲取的完整系統,
包括了數據輸入、預處理、知識獲取、模式評估等環節,以及對數據及學習結果的可視化操作。並且可以通過對不同
的學習方法所得出的結果進行比較,找出解決當前問題的最佳算法。
Weka提供了許多用於數據可視化及預處理的工具(也稱作過濾器),包括種類繁多的用於數據集轉換的工具等。所有機器學習算法對輸入數據都要求其采用ARFF格式。 Weka作為一個公開的知識過去的工作平臺,集合了大量能承擔數據(知識)挖掘任務的機器學習算法,包括分類,回歸、聚類、關聯規則等。
Weka與許多數據分析軟件一樣,Weka所處理的數據集是一個二維的表格.

下面代碼所示的二維表格存儲在如下的ARFF文件中。這也就是Weka自帶的“weather.arff”文件,在Weka安裝目錄的“data”子目錄下可以找到。
@relation weather
@attribute outlook {sunny, overcast, rainy}
@attribute temperature numeric
@attribute humidity numeric
@attribute windy {TRUE, FALSE}
@attribute play {yes, no}
@data
sunny,85,85,FALSE,no
sunny,80,90,TRUE,no
overcast,83,86,FALSE,yes
rainy,70,96,FALSE,yes
rainy,68,80,FALSE,yes
rainy,65,70,TRUE,no
overcast,64,65,TRUE,yes
sunny,72,95,FALSE,no
sunny,69,70,FALSE,yes
rainy,75,80,FALSE,yes
sunny,75,70,TRUE,yes
overcast,72,90,TRUE,yes
overcast,81,75,FALSE,yes
rainy,71,91,TRUE,no
Weka中的屬性介紹:
數據集中的每一個屬性都有它對應的“@attribute”語句,來定義它的屬性名稱和數據類型。
Weka支持的有四種,分別是
numeric-------------------------數值型
nominal-specification-----------分類(nominal)型
string----------------------------字符串型
date[]--------日期和時間型
數值屬性:是整數或者實數,但Weka把它們都當作實數看待。
字符串屬性:可以包含任意的文本。這種類型的屬性在文本挖掘中非常有用。如:@ATTRIBUTE LC string
分類屬性:由列出所有可能的類別名稱並放在花括號中,如:
@attribute outlook {sunny, overcast, rainy} 。每個實例對應的“outlook”值必是這三者之一。
日期和時間屬性:統一用“date”類型表示,它的格式是:@attribute date [] 其中是這個屬性的名稱,是一個字符
串,來規定該怎樣解析和顯示日期或時間的格式,
默認的字符串是ISO-8601所給的日期時間組合格式“yyyy-mm-dd hh:mm:ss”。
數據信息部分表達日期的字符串必須符合聲明中規定的格式要求。
“Exploer”界面:

我們根據不同的功能把這個界面分成8個區域。
區域1的幾個選項卡是用來切換不同的挖掘任務面板。這一節用到的只有“Preprocess”,其他面板的功能將在以後介紹。
區域2是一些常用按鈕。包括打開數據,保存及編輯功能。我們在這裏把"bank-data.csv"另存為"bank-data.arff"。
在區域3中“Choose”某個“Filter”,可以實現篩選數據或者對數據進行某種變換。數據預處理主要就利用它來實現。
區域4展示了數據集的一些基本情況。
區域5中列出了數據集的所有屬性。勾選一些屬性並“Remove”就可以刪除它們,刪除後還可以利用區域2的“Undo”按鈕找回。區域5上方的一排按鈕是用來實現快速勾選的。
在區域5中選中某個屬性,則區域6中有關於這個屬性的摘要。註意對於數值屬性和分類屬性,摘要的方式是不一樣的。圖中顯示的是對數值屬性“income”的摘要。
區域7是區域5中選中屬性的直方圖。若數據集的最後一個屬性(我們說過這是分類或回歸任務的默認目標變量)是分類變量(這裏的“pep”正好是),直方圖中的每個長方形就會按照該變量的比例分成不同顏色的段。要想換個分段的依據,在區域7上方的下拉框中選個不同的分類屬性就可以了。下拉框裏選上“No Class”或者一個數值屬性會變成黑白的直方圖。
區域8是狀態欄,可以查看Log以判斷是否有錯。右邊的weka鳥在動的話說明WEKA正在執行挖掘任務。右鍵點擊狀態欄還可以執行JAVA內存的垃圾回收。
接下來在簡單的看看窗口的其他幾個標簽菜單
Explorer: building “classifiers”:
nClassifiersin WEKA are models for predicting nominal or numeric quantities nImplementedlearning schemes include: uDecision trees and lists,instance-based classifiers, support vector machines, multi-layer perceptrons,logistic regression, Bayes’ nets, … n“Meta”-classifiersinclude:
Bagging,boosting, stacking, error-correcting output codes, locally weighted learning





Explorer: clustering data:
nWEKAcontains “clusterers”for finding groups of similar instances in a dataset nImplementedschemes are: uk-Means,EM, Cobweb, X-means,FarthestFirst nClusterscan be visualized and compared to “true” clusters (if given) nEvaluationbased on loglikelihood ifclustering scheme produces a probability distribution




Explorer: finding associations:
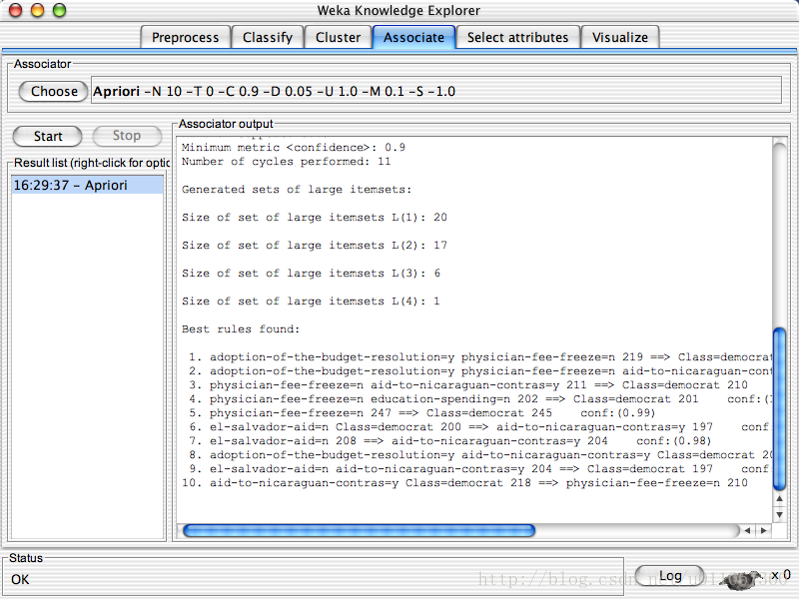
WEKAcontains an implementation of the Apriorialgorithm for learning association rules uWorks only with discrete data Canidentify statistical dependencies between groups of attributes: umilk, butter T bread, eggs (with confidence 0.9and support 2000) Apriorican compute all rules that have a given minimum support and exceed a givenconfidence


Explorer: attribute selection:
Panelthat can be used to investigate which (subsets of) attributes are the mostpredictive ones Attributeselection methods contain two parts: A search method: best-first,forward selection, random, exhaustive, genetic algorithm, ranking An evaluation method:correlation-based, wrapper, information gain, chi-squared, … Veryflexible: WEKA allows (almost) arbitrary combinations of these two

 Explorer: data visualization:
Visualizationvery useful in practice: e.g. helps to determine difficulty of the learningproblem
WEKAcan visualize single attributes (1-d) and pairs of attributes (2-d)
To do: rotating 3-dvisualizations (Xgobi-style)
Color-codedclass values
“Jitter”option to deal with nominal attributes (and to detect “hidden” data points)
“Zoom-in”function
Explorer: data visualization:
Visualizationvery useful in practice: e.g. helps to determine difficulty of the learningproblem
WEKAcan visualize single attributes (1-d) and pairs of attributes (2-d)
To do: rotating 3-dvisualizations (Xgobi-style)
Color-codedclass values
“Jitter”option to deal with nominal attributes (and to detect “hidden” data points)
“Zoom-in”function

 Performing experiments:
Experimentermakes it easy to compare the performance of different learning schemes
Forclassification and regression problems
Resultscan be written into file or database
Evaluationoptions: cross-validation, learning curve, hold-out
Canalso iterate over different parameter settings
Significance-testingbuilt in!
Performing experiments:
Experimentermakes it easy to compare the performance of different learning schemes
Forclassification and regression problems
Resultscan be written into file or database
Evaluationoptions: cross-validation, learning curve, hold-out
Canalso iterate over different parameter settings
Significance-testingbuilt in!




 The Knowledge Flow GUI:
Newgraphical user interface for WEKA
Java-Beans-basedinterface for setting up and running machine learning experiments
Datasources, classifiers, etc. are beans and can be connected graphically
Data“flows” through components: e.g.,
The Knowledge Flow GUI:
Newgraphical user interface for WEKA
Java-Beans-basedinterface for setting up and running machine learning experiments
Datasources, classifiers, etc. are beans and can be connected graphically
Data“flows” through components: e.g.,
“data source” -> “filter” ->“classifier” -> “evaluator”
Layoutscan be saved and loaded again later





0、weka學習與使用