
圖文解析Spark2.0核心技術(轉載)
導語
Spark2.0於2016-07-27正式發布,伴隨著更簡單、更快速、更智慧的新特性,spark 已經逐步替代 hadoop 在大數據中的地位,成為大數據處理的主流標準。本文主要以代碼和繪圖的方式結合,對運行架構、RDD 的實現、spark 作業原理、Sort-Based Shuffle 的存儲原理、 Standalone 模式 HA 機制進行解析。
1、運行架構
Spark支持多種運行模式。單機部署下,既可以用本地(Local)模式運行,也可以使用偽分布式模式來運行;當以分布式集群部署的時候,可以根據實際情況選擇Spark自帶的獨立(Standalone)運行模式、YARN運行模式或者Mesos模式。雖然模式多,但是Spark的運行架構基本由三部分組成,包括SparkContext(驅動程序)、ClusterManager(集群資源管理器)和Executor(任務執行進程)。
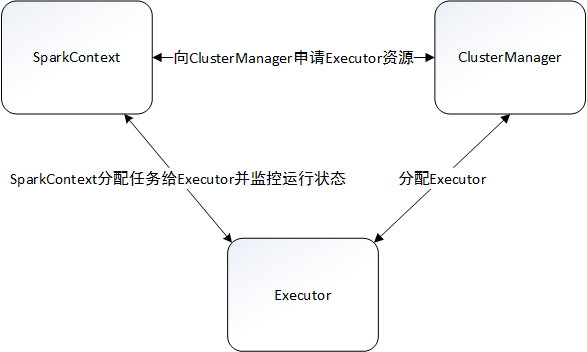
1、SparkContext提交作業,向ClusterManager申請資源;
2、ClusterManager會根據當前集群的資源使用情況,進行有條件的FIFO策略:先分配的應用程序盡可能多地獲取資源,後分配的應用程序則在剩余資源中篩選,沒有合適資源的應用程序只能等待其他應用程序釋放資源;
3、ClusterManager默認情況下會將應用程序分布在盡可能多的Worker上,這種分配算法有利於充分利用集群資源,適合內存使用多的場景,以便更好地做到數據處理的本地性;另一種則是分布在盡可能少的Worker上,這種適合CPU密集型且內存使用較少的場景;
4、Excutor創建後與SparkContext保持通訊,SparkContext分配任務集給Excutor,Excutor按照一定的調度策略執行任務集。
2、RDD
彈性分布式數據集(Resilient Distributed Datasets,RDD)作為Spark的編程模型,相比MapReduce模型有著更好的擴展和延伸:
- 提供了抽象層次更高的API
- 高效的數據共享
- 高效的容錯性
2.1、RDD 的操作類型
RDD大致可以包括四種操作類型:
- 創建操作(Creation):從內存集合和外部存儲系統創建RDD,或者是通過轉換操作生成RDD
- 轉換操作(Transformation):轉換操作是惰性操作,只是定義一個RDD並記錄依賴關系,沒有立即執行
- 控制操作(Control):進行RDD的持久化,通過設定不同級別對RDD進行緩存
- 行動操作(Action):觸發任務提交、Spark運行的操作,操作的結果是獲取到結果集或者保存至外部存儲系統
2.2、RDD 的實現
2.2.1、RDD 的分區
RDD的分區是一個邏輯概念,轉換操作前後的分區在物理上可能是同一塊內存或者存儲。在RDD操作中用戶可以設定和獲取分區數目,默認分區數目為該程序所分配到的cpu核數,如果是從HDFS文件創建,默認為文件的分片數。
2.2.2、RDD 的“血統”和依賴關系

“血統”和依賴關系:RDD 的容錯機制是通過記錄更新來實現的,且記錄的是粗粒度的轉換操作。我們將記錄的信息稱為血統(Lineage)關系,而到了源碼級別,Apache Spark 記錄的則是 RDD 之間的依賴(Dependency)關系。如上所示,每次轉換操作產生一個新的RDD(子RDD),子RDD會記錄其父RDD的信息以及相關的依賴關系。
2.2.3、依賴關系
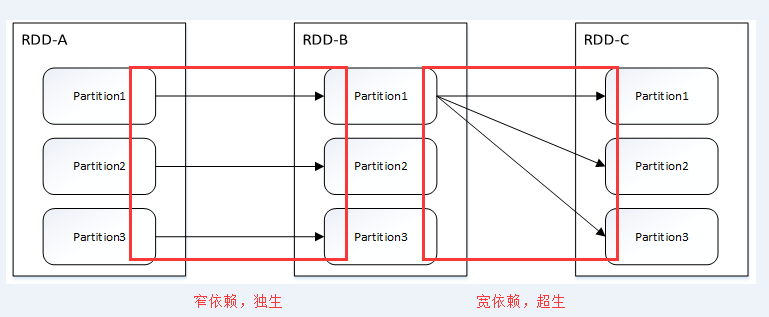
依賴關系劃分為兩種:窄依賴(Narrow Dependency)和 寬依賴(源碼中為Shuffle Dependency)。
窄依賴指的是父 RDD 中的一個分區最多只會被子 RDD 中的一個分區使用,意味著父RDD的一個分區內的數據是不能被分割的,子RDD的任務可以跟父RDD在同一個Executor一起執行,不需要經過 Shuffle 階段去重組數據。
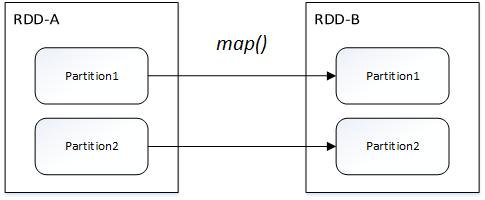
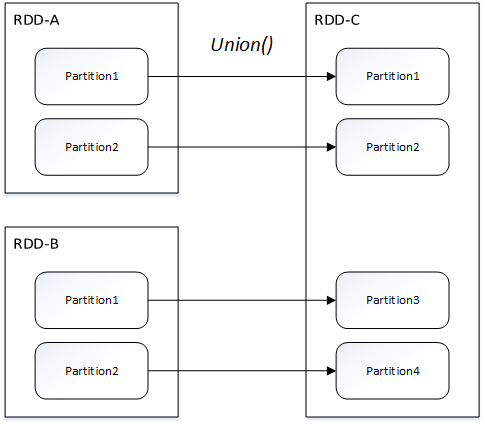
窄依賴包括兩種:一對一依賴(OneToOneDependency)和範圍依賴(RangeDependency)
一對一依賴:
範圍依賴(僅union方法):
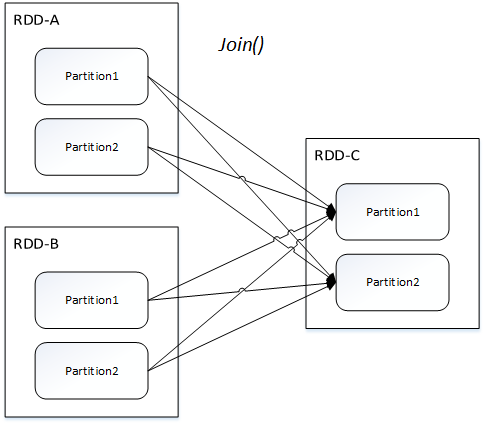
寬依賴指的是父 RDD 中的分區可能會被多個子 RDD 分區使用。因為父 RDD 中一個分區內的數據會被分割,發送給子 RDD 的所有分區,因此寬依賴也意味著父 RDD 與子 RDD 之間存在著 Shuffle 過程。
寬依賴只有一種:Shuffle依賴(ShuffleDependency)
3、作業執行原理
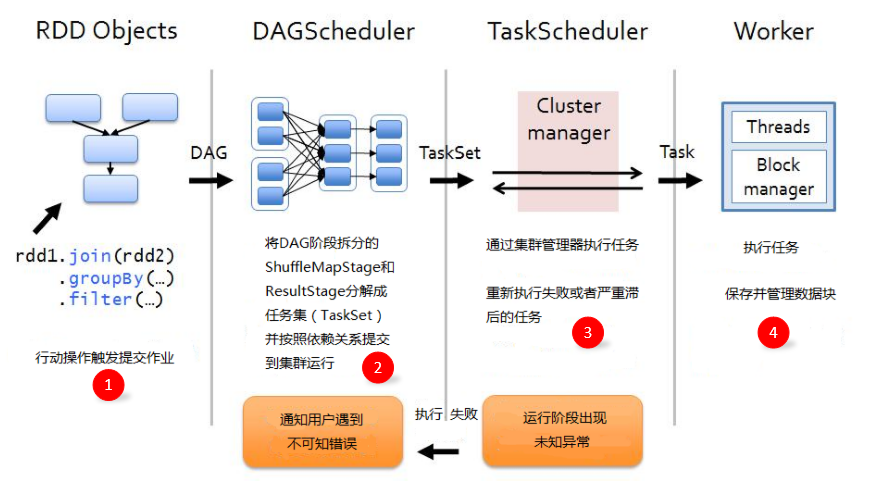
作業(Job):RDD每一個行動操作都會生成一個或者多個調度階段 調度階段(Stage):每個Job都會根據依賴關系,以Shuffle過程作為劃分,分為Shuffle Map Stage和Result Stage。每個Stage包含多個任務集(TaskSet),TaskSet的數量與分區數相同。
任務(Task):分發到Executor上的工作任務,是Spark的最小執行單元 DAGScheduler:DAGScheduler是面向調度階段的任務調度器,負責劃分調度階段並提交給TaskScheduler
TaskScheduler:TaskScheduler是面向任務的調度器,它負責將任務分發到Woker節點,由Executor進行執行
3.1、提交作業及作業調度策略(適用於調度階段)

每一次行動操作都會觸發SparkContext的runJob方法進行作業的提交。
這些作業之間可以沒有任何依賴關系,對於多個作業之間的調度,共有兩種:一種是默認的FIFO模式,另一種則是FAIR模式,該模式的調度可以通過設定minShare(最小任務數)和weight(任務的權重)來決定Job執行的優先級。
FIFO調度策略:優先比較作業優先級(作業編號越小優先級越高),再比較調度階段優先級(調度階段編號越小優先級越高)
FAIR調度策略:先獲取兩個調度的饑餓程度,是否處於饑餓狀態由當前正在運行的任務是否小於最小任務決定,獲取後進行如下比較:
- 優先滿足處於饑餓狀態的調度
- 同處於饑餓狀態,優先滿足資源比小的調度
- 同處於非饑餓狀態,優先滿足權重比小的調度
- 以上情況均相同的情況下,根據調度名稱進行排序
3.2、劃分調度階段(DAG構建)
DAG構建圖:
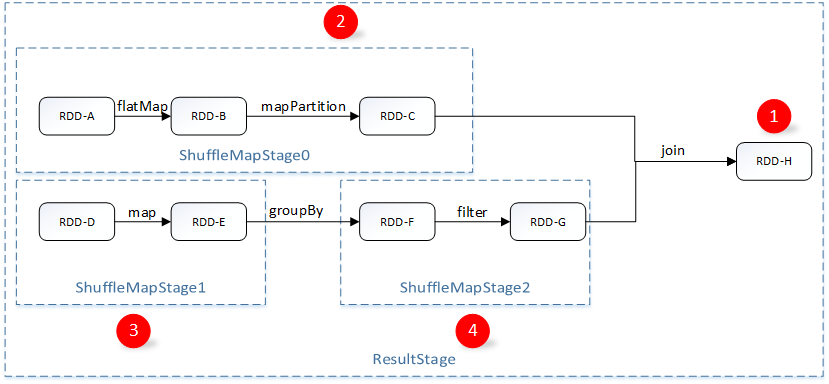
DAG的構建:主要是通過對最後一個RDD進行遞歸,使用廣度優先遍歷每個RDD跟父RDD的依賴關系(前面提到子RDD會記錄依賴關系),碰到ShuffleDependency的則進行切割。切割後形成TaskSet傳遞給TaskScheduler進行執行。
DAG的作用:讓窄依賴的RDD操作合並為同一個TaskSet,將多個任務進行合並,有利於任務執行效率的提高。
TaskSet結構圖:假設數據有兩個Partition時,TaskSet是一組關聯的,但相互之間沒有Shuffle依賴關系的Task集合,TaskSet的ShuffleMapStage數量跟Partition個數相關,主要包含task的集合,stage中的rdd信息等等。Task會被序列化和壓縮
4、存儲原理(Sort-Based Shuffle分析)
4.1、Shuffle過程解析(wordcount實例)
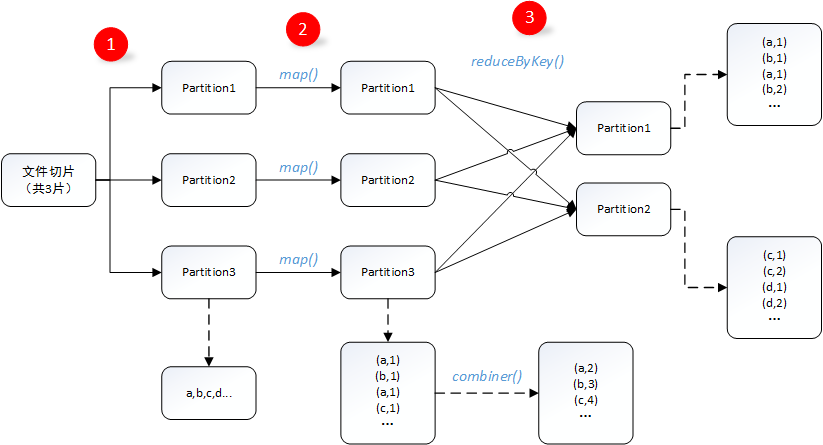
1. 數據處理:文件在hdfs中以多個切片形式存儲,讀取時每一個切片會被分配給一個Excutor進行處理;
2. map端操作:map端對文件數據進行處理,格式化為(key,value)鍵值對,每個map都可能包含a,b,c,d等多個字母,如果在map端使用了combiner,則數據會被壓縮,value值會被合並;(註意:這個過程的使用需要保證對最終結果沒有影響,有利於減少shuffle過程的數據傳輸);
3.reduce端操作:reduce過程中,假設a和b,c和d在同一個reduce端,需要將map端被分配在同一個reduce端的數據進行洗牌合並,這個過程被稱之為shuffle。
4.2、map端的寫操作
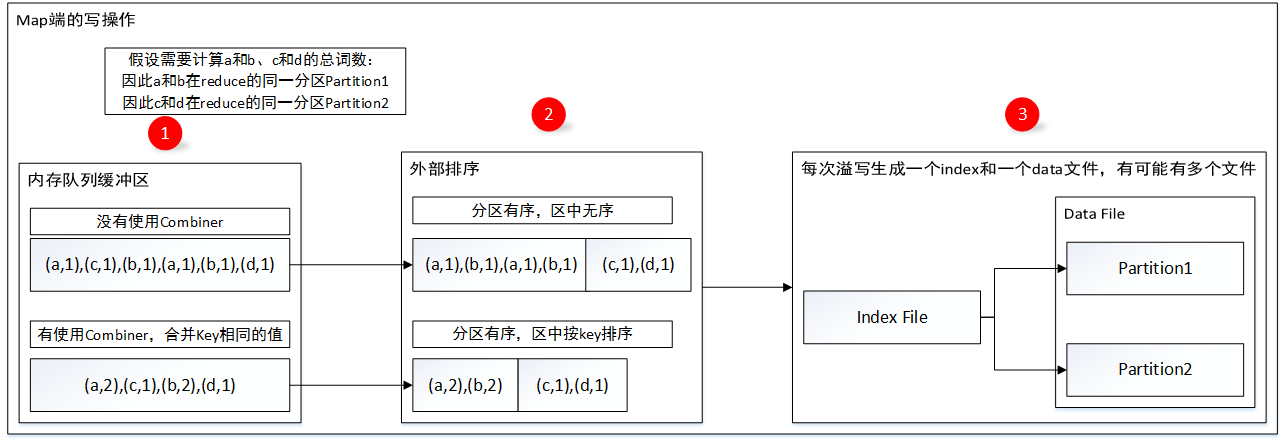
1.map端處理數據的時候,先判斷這個過程是否使用了combiner,如果使用了combiner則采用PartitionedAppendOnlyMap數據結構作為內存緩沖區進行數據存儲,對於相同key的數據每次都會進行更新合並;如果沒有使用combiner,則采用PartitionedPairBuffer數據結構,把每次處理的數據追加到隊列末尾;
2.寫入數據的過程中如果出現內存不夠用的情況則會發生溢寫,溢寫;使用combiner的則會將數據按照分區id和數據key進行排序,做到分區有序,區中按key排序,其實就是將partitionId和數據的key作為key進行排序;沒有使用combiner的則只是分區有序;
3.按照排序後的數據溢寫文件,文件分為data文件和index文件,index文件作為索引文件索引data文件的數據,有利於reduce端的讀取;(註意:每次溢寫都會形成一個index和data文件,在map完全處理完後會將多個inde和data文件Merge為一個index和data文件)
4.3、reduce端的讀操作
有了map端的處理,reduce端只需要根據index文件就可以很好地獲取到數據並進行相關的處理操作。這裏主要講reduce端讀操作時對數據讀取的策略:
如果在本地有,那麽可以直接從BlockManager中獲取數據;如果需要從其他的節點上獲取,由於Shuffle過程的數據量可能會很大,為了減少請求數據的時間並且充分利用帶寬,因此這裏的網絡讀有以下的策略:
1.每次最多啟動5個線程去最多5個節點上讀取數據;
2.每次請求的數據大小不會超過spark.reducer.maxMbInFlight(默認值為48MB)/5
5、Spark的HA機制(Standalone模式)
5.1、Executor異常
當Executor發生異常退出的情況,Master會嘗試獲取可用的Worker節點並啟動Executor,這個Worker很可能是失敗之前運行Executor的Worker節點。這個過程系統會嘗試10次,限定失敗次數是為了避免因為應用程序存在bug而反復提交,占用集群寶貴的資源。
5.2、Worker異常
Worker會定時發送心跳給Master,Master也會定時檢測註冊的Worker是否超時,如果Worker異常,Master會告知Driver,並且同時將這些Executor從其應用程序列表中刪除。
5.3、Master異常
1、ZooKeeper:將集群元數據持久化到ZooKeeper,由ZooKeeper通過選舉機制選舉出新的Master,新的Master從ZooKeeper中獲取集群信息並恢復集群狀態;
2、FileSystem:集群元數據持久化到本地文件系統中,當Master出現異常只需要重啟Master即可;
3、Custom:通過對StandaloneRecoveryModeFactory抽象類進行實現並配置到系統中,由用戶自定義恢復方式。
圖文解析Spark2.0核心技術(轉載)