
人工智能,如何建立一個神經網絡?
什麽是神經網絡?
在我們開始之前與如何建立一個神經網絡,我們需要了解什麽第一。
神經網絡可能會讓人感到恐懼,特別是對於新手機器學習的人來說。但是,本教程將分解神經網絡的工作原理,最終您將擁有靈活的神經網絡。讓我們開始吧!
了解過程
擁有大約100億個神經元,人類大腦以268英裏的速度處理數據!實質上,神經網絡是由突觸連接的神經元集合。該集合分為三個主要層:輸入層,隱藏層和輸出層。你可以有許多隱藏層,這就是深度學習這個術語的起源。在人造神經網絡中,有幾個輸入,稱為特征,並產生單個輸出,稱為標簽。
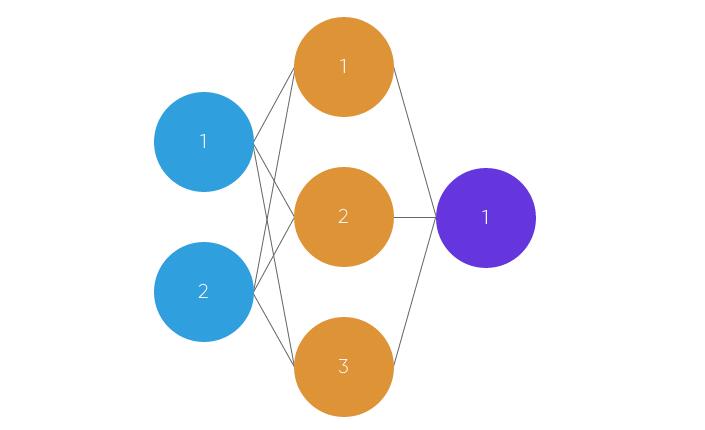
圓圈表示神經元,而線條表示突觸。突觸的作用是將輸入和權重相乘。你可以將體重看作神經元之間連接的“強度”。權重主要定義了神經網絡的輸出。但是,他們非常靈活。之後,應用激活功能返回輸出。
以下簡要介紹一個簡單的前饋神經網絡的工作原理:
1.將輸入作為矩陣(數字的二維數組)
2.將輸入乘以設定權重(執行點積乘以矩陣乘法)
3.應用激活功能
4.返回一個輸出
5.通過從數據的期望輸出和預測輸出的差異來計算誤差。這創建了我們的漸變下降,我們可以使用它來改變權重
6.然後根據錯誤輕微改變權重。
7.為了訓練,這個過程重復1000次以上。數據訓練得越多,我們的輸出結果就越準確。
神經網絡的核心是簡單的。他們只是使用輸入和權重執行點積並應用激活函數。當權重通過損失函數的梯度進行調整時,網絡適應變化以產生更準確的輸出。
我們的神經網絡將模擬一個具有三個輸入和一個輸出的隱藏層。在網絡中,我們將根據我們研究多少小時以及我們前一天睡了多少小時的輸入來預測考試成績。我們的測試分數是輸出。以下是我們將在以下方面培訓我們的神經網絡的示例數據:
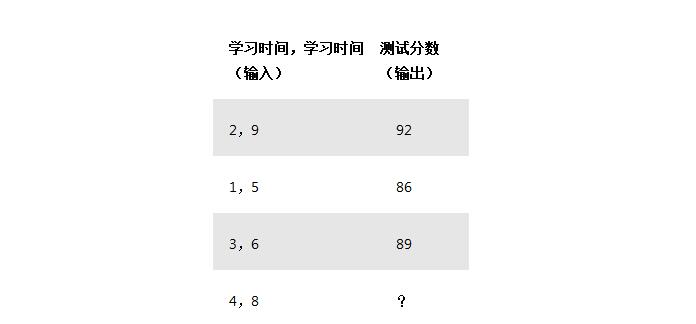
正如你可能已經註意到的那樣,?在這種情況下代表了我們希望我們的神經網絡預測的東西。在這種情況下,我們預測根據他們之前的表現,學習了四個小時並睡了八個小時的人的測試分數。
向前傳播
讓我們開始編碼這個壞男孩!打開一個新的python文件。您需要導入,numpy因為它可以幫助我們進行某些計算。
首先,讓我們使用numpy數組導入我們的數據np.array。我們也希望我們的單位標準化,因為我們的輸入是以小時為單位的,但是我們的輸出是從0到100的測試分數。因此,我們需要通過除以每個變量的最大值來縮放數據。

接下來,讓我們定義一個pythonclass並寫一個init函數,我們將在其中指定我們的參數,如輸入層,隱藏層和輸出層。

現在是我們第一次計算的時候了。請記住,我們的突觸執行點積或輸入和權重的矩陣乘法。請註意,權重是隨機生成的,介於0和1之間。
我們網絡背後的計算
在數據集中,我們的輸入數據X是一個3x2的矩陣。我們的輸出數據y是一個3x1矩陣。矩陣中的每個元素X需要乘以相應的權重,然後與隱藏層中每個神經元的所有其他結果一起添加。以下是第一個輸入數據元素(2小時學習和9小時睡眠)將如何計算網絡中的輸出:
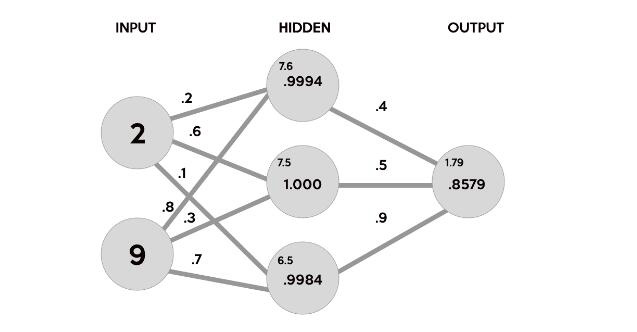
這張圖片分解了我們的神經網絡實際上產生輸出的過程。首先,將每個突觸上隨機生成的權重(.2,.6,.1,.8,.3,.7)和相應輸入的乘積相加,作為隱層的第一個值。這些總和字體較小,因為它們不是隱藏層的最終值。
(2*.2)+(9*.8)=7.6
(2*.6)+(9*.3)=3.9
(2*.1)+(9*.7)=6.5
為了獲得隱藏層的最終值,我們需要應用激活函數。激活函數的作用是引入非線性。這樣做的一個優點是輸出從0到1的範圍映射,使得將來更容易改變權重。
那裏有很多激活功能。在這種情況下,我們將堅持一個更受歡迎的--Sigmoid函數。
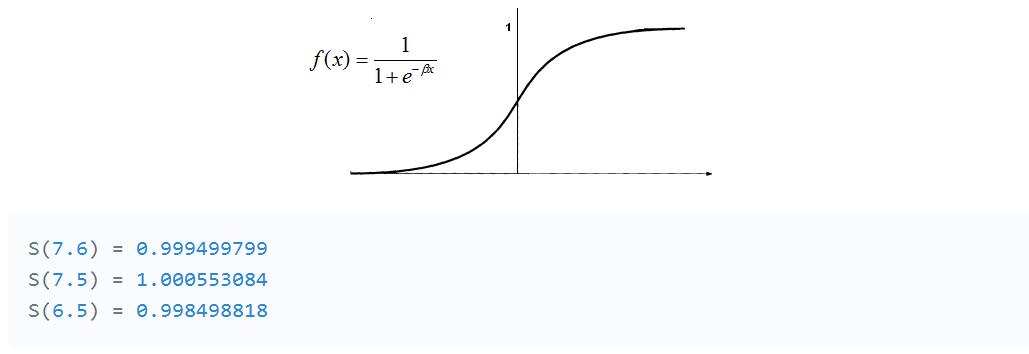
現在,我們需要再次使用矩陣乘法和另一組隨機權重來計算我們的輸出圖層值。
(.9994*.4)+(1.000*.5)+(.9984*.9)=1.79832
最後,為了標準化輸出,我們再次應用激活函數。
S(1.79832)=.8579443067
而且,你去了!理論上,用這些權重,out神經網絡將計算.85為我們的測試分數!但是,我們的目標是.92。我們的結果並不差,但它不是最好的。當我為這個例子選擇隨機權重時,我們有點幸運。
我們如何訓練我們的模型來學習?那麽,我們很快就會發現。現在,我們來統計我們的網絡編碼。
如果您仍然感到困惑,我強烈建議您查看這個帶有相同示例的神經網絡結構的信息性視頻。
實施計算
現在,讓我們隨機生成我們的權重np.random.randn()。請記住,我們需要兩組權重。一個從輸入到隱藏層,另一個從隱藏層到輸出層。
#weights
self.W1=np.random.randn(self.inputSize,self.hiddenSize)#(3x2)weightmatrixfrominputtohiddenlayer
self.W2=np.random.randn(self.hiddenSize,self.outputSize)#(3x1)weightmatrixfromhiddentooutputlayer
一旦我們有了所有的變量,我們就可以編寫我們的forward傳播函數了。讓我們傳入我們的輸入,X在這個例子中,我們可以使用變量z來模擬輸入層和輸出層之間的活動。正如所解釋的那樣,我們需要獲取輸入和權重的點積,應用激活函數,取另一個隱藏層的點積和第二組權重,最後應用最終激活函數來接收我們的輸出:
defforward(self,X):
#forwardpropagationthroughournetwork
self.z=np.dot(X,self.W1)#dotproductofX(input)andfirstsetof3x2weights
self.z2=self.sigmoid(self.z)#activationfunction
self.z3=np.dot(self.z2,self.W2)#dotproductofhiddenlayer(z2)andsecondsetof3x1weights
o=self.sigmoid(self.z3)#finalactivationfunction
returno
最後,我們需要定義我們的sigmoid函數:
defsigmoid(self,s):
#activationfunction
return1/(1+np.exp(-s))
我們終於得到它了!一個能夠產生輸出的(未經訓練的)神經網絡。
importnumpyasnp
#X=(hourssleeping,hoursstudying),y=scoreontest
X=np.array(([2,9],[1,5],[3,6]),dtype=float)
y=np.array(([92],[86],[89]),dtype=float)
#scaleunits
X=X/np.amax(X,axis=0)#maximumofXarray
y=y/100#maxtestscoreis100
classNeural_Network(object):
def__init__(self):
#parameters
self.inputSize=2
self.outputSize=1
self.hiddenSize=3
#weights
self.W1=np.random.randn(self.inputSize,self.hiddenSize)#(3x2)weightmatrixfrominputtohiddenlayer
self.W2=np.random.randn(self.hiddenSize,self.outputSize)#(3x1)weightmatrixfromhiddentooutputlayer
defforward(self,X):
#forwardpropagationthroughournetwork
self.z=np.dot(X,self.W1)#dotproductofX(input)andfirstsetof3x2weights
self.z2=self.sigmoid(self.z)#activationfunction
self.z3=np.dot(self.z2,self.W2)#dotproductofhiddenlayer(z2)andsecondsetof3x1weights
o=self.sigmoid(self.z3)#finalactivationfunction
returno
defsigmoid(self,s):
#activationfunction
return1/(1+np.exp(-s))
NN=Neural_Network()
#definingouroutput
o=NN.forward(X)
print"PredictedOutput:\n"+str(o)
print"ActualOutput:\n"+str(y)
正如您可能已經註意到的那樣,我們需要訓練我們的網絡來計算更準確的結果。
反向傳播
由於我們有一組隨機的權重,我們需要對它們進行修改,以使我們的輸入等於我們數據集的相應輸出。這是通過一種稱為反向傳播的方法完成的。
反向傳播通過使用丟失函數來計算網絡與目標輸出的距離。
在這個函數中,o是我們的預測輸出,並且y是我們的實際輸出。既然我們有損失函數,那麽我們的目標就是盡可能接近零。這意味著我們將需要接近完全沒有損失。當我們正在訓練我們的網絡時,我們所做的一切就是盡量減少損失。
為了找出改變我們的權重的方向,我們需要找出我們的損失相對於權重的變化率。換句話說,我們需要使用損失函數的導數來理解權重如何影響輸入。
在這種情況下,我們將使用偏導數來允許我們考慮另一個變量。
? 這種方法被稱為梯度下降。通過知道哪種方式來改變我們的權重,我們的輸出只能得到更準確的結果。
以下是我們將如何計算對權重的增量更改:
通過計算預測輸出和實際輸出(y)的差值來找出輸出層(o)的誤差幅度,
將sigmoid激活函數的導數應用於輸出圖層錯誤。我們把這個結果稱為delta輸出和。
使用輸出層誤差的delta輸出總和來計算我們的z2(隱藏)層通過使用我們的第二個權重矩陣執行點積來導致輸出誤差的程度。我們可以稱之為z2錯誤。
應用我們的sigmoid激活函數的導數(與第2步一樣),計算z2層的delta輸出和。
通過執行輸入層與隱藏(z2)增量輸出和的點積來調整第一層的權重。對於第二層,執行隱藏(z2)圖層和輸出(o)delta輸出和的點積。
計算delta輸出和然後應用sigmoid函數的導數對於反向傳播非常重要。S型的衍生物,也被稱為S型素數,將給我們輸出和的激活函數的變化率或斜率。
讓我們繼續Neural_Network通過添加sigmoidPrime(sigmoid的衍生)函數來編寫我們的類:
defsigmoidPrime(self,s):
#derivativeofsigmoid
returns*(1-s)
然後,我們要創建我們的backward傳播函數,它執行上述四個步驟中指定的所有內容:
defbackward(self,X,y,o):
#backwardpropgatethroughthenetwork
self.o_error=y-o#errorinoutput
self.o_delta=self.o_error*self.sigmoidPrime(o)#applyingderivativeofsigmoidtoerror
self.z2_error=self.o_delta.dot(self.W2.T)#z2error:howmuchourhiddenlayerweightscontributedtooutputerror
self.z2_delta=self.z2_error*self.sigmoidPrime(self.z2)#applyingderivativeofsigmoidtoz2error
self.W1+=X.T.dot(self.z2_delta)#adjustingfirstset(input-->hidden)weights
self.W2+=self.z2.T.dot(self.o_delta)#adjustingsecondset(hidden-->output)weights
我們現在可以通過啟動前向傳播來定義我們的輸出,並通過在函數中調用後向函數來啟動它train:
deftrain(self,X,y):
o=self.forward(X)
self.backward(X,y,o)
為了運行網絡,我們所要做的就是運行該train功能。當然,我們會想要做到這一點,甚至可能是成千上萬次。所以,我們將使用一個for循環。
NN=Neural_Network()
foriinxrange(1000):#trainstheNN1,000times
print"Input:\n"+str(X)
print"ActualOutput:\n"+str(y)
print"PredictedOutput:\n"+str(NN.forward(X))
print"Loss:\n"+str(np.mean(np.square(y-NN.forward(X))))#meansumsquaredloss
print"\n"
NN.train(X,y)
太棒了,我們現在有一個神經網絡!如何使用這些訓練後的權重來預測我們不知道的測試分數?
預測
為了預測我們的輸入測試分數[4,8],我們需要創建一個新的數組來存儲這些數據xPredicted。
xPredicted=np.array(([4,8]),dtype=float)
我們還需要按照我們對輸入和輸出變量所做的那樣進行擴展:
xPredicted=xPredicted/np.amax(xPredicted,axis=0)#maximumofxPredicted(ourinputdatafortheprediction)
然後,我們將創建一個打印我們的預測輸出的新函數xPredicted。相信與否,我們必須運行的是forward(xPredicted)返回輸出!
defpredict(self):
print"Predicteddatabasedontrainedweights:";
print"Input(scaled):\n"+str(xPredicted);
print"Output:\n"+str(self.forward(xPredicted));
要運行這個函數,只需在for循環中調用它。
NN.predict()
如果你想保存你的訓練重量,你可以這樣做np.savetxt:
defsaveWeights(self):
np.savetxt("w1.txt",self.W1,fmt="%s")
np.savetxt("w2.txt",self.W2,fmt="%s")
最終的結果如下:
importnumpyasnp
#X=(hoursstudying,hourssleeping),y=scoreontest,xPredicted=4hoursstudying&8hourssleeping(inputdataforprediction)
X=np.array(([2,9],[1,5],[3,6]),dtype=float)
y=np.array(([92],[86],[89]),dtype=float)
xPredicted=np.array(([4,8]),dtype=float)
#scaleunits
X=X/np.amax(X,axis=0)#maximumofXarray
xPredicted=xPredicted/np.amax(xPredicted,axis=0)#maximumofxPredicted(ourinputdatafortheprediction)
y=y/100#maxtestscoreis100
classNeural_Network(object):
def__init__(self):
#parameters
self.inputSize=2
self.outputSize=1
self.hiddenSize=3
#weights
self.W1=np.random.randn(self.inputSize,self.hiddenSize)#(3x2)weightmatrixfrominputtohiddenlayer
self.W2=np.random.randn(self.hiddenSize,self.outputSize)#(3x1)weightmatrixfromhiddentooutputlayer
defforward(self,X):
#forwardpropagationthroughournetwork
self.z=np.dot(X,self.W1)#dotproductofX(input)andfirstsetof3x2weights
self.z2=self.sigmoid(self.z)#activationfunction
self.z3=np.dot(self.z2,self.W2)#dotproductofhiddenlayer(z2)andsecondsetof3x1weights
o=self.sigmoid(self.z3)#finalactivationfunction
returno
defsigmoid(self,s):
#activationfunction
return1/(1+np.exp(-s))
defsigmoidPrime(self,s):
#derivativeofsigmoid
returns*(1-s)
defbackward(self,X,y,o):
#backwardpropgatethroughthenetwork
self.o_error=y-o#errorinoutput
self.o_delta=self.o_error*self.sigmoidPrime(o)#applyingderivativeofsigmoidtoerror
self.z2_error=self.o_delta.dot(self.W2.T)#z2error:howmuchourhiddenlayerweightscontributedtooutputerror
self.z2_delta=self.z2_error*self.sigmoidPrime(self.z2)#applyingderivativeofsigmoidtoz2error
self.W1+=X.T.dot(self.z2_delta)#adjustingfirstset(input-->hidden)weights
self.W2+=self.z2.T.dot(self.o_delta)#adjustingsecondset(hidden-->output)weights
deftrain(self,X,y):
o=self.forward(X)
self.backward(X,y,o)
defsaveWeights(self):
np.savetxt("w1.txt",self.W1,fmt="%s")
np.savetxt("w2.txt",self.W2,fmt="%s")
defpredict(self):
print"Predicteddatabasedontrainedweights:";
print"Input(scaled):\n"+str(xPredicted);
print"Output:\n"+str(self.forward(xPredicted));
NN=Neural_Network()
foriinxrange(1000):#trainstheNN1,000times
print"#"+str(i)+"\n"
print"Input(scaled):\n"+str(X)
print"ActualOutput:\n"+str(y)
print"PredictedOutput:\n"+str(NN.forward(X))
print"Loss:\n"+str(np.mean(np.square(y-NN.forward(X))))#meansumsquaredloss
print"\n"
NN.train(X,y)
NN.saveWeights()
NN.predict()
為了看到網絡的實際準確程度,我跑了10萬次訓練,看看能否得到完全正確的輸出結果。這就是我得到的:
#99999
Input(scaled):
[[0.666666671.]
[0.333333330.55555556]
[1.0.66666667]]
ActualOutput:
[[0.92]
[0.86]
[0.89]]
PredictedOutput:
[[0.92]
[0.86]
[0.89]]
Loss:
1.94136958194e-18
Predicteddatabasedontrainedweights:
Input(scaled):
[0.51.]
Output:
[0.91882413]
你有它!一個完整的神經網絡,可以學習和適應產生準確的輸出。雖然我們將我們的輸入視為學習和睡眠的小時數,並將我們的輸出視為測試分數,但隨時可以將這些輸入更改為任何您喜歡的內容,並觀察網絡的適應情況!畢竟,所有的網絡都是數字。我們所做的計算雖然很復雜,但都在我們的學習模型中發揮了重要作用。(黑客周刊)
人工智能,如何建立一個神經網絡?