
十五周二次課
- 主流開源軟件LVS、keepalived、haproxy、nginx等
- 其中LVS屬於4層(網絡OSI 7層模型),nginx屬於7層,haproxy既可以認為是4層,也可以當做7層使用
- keepalived的負載均衡功能其實就是lvs
- lvs這種4層的負載均衡是可以分發TCP協議,web服務是80端口,除了分發80端口,還有其他的端口通信的,比如MySQL的負載均衡,就可以用LVS實現,而nginx僅僅支持http,https,mail,haproxy;haproxy也支持MySQL這種TCP負載均衡的
- 相比較來說,LVS這種4層的更穩定,能承受更多的請求,承載的並發量更高,而nginx這種7層的更加靈活,能實現更多的個性化需求
18.7 LVS介紹
- LVS是由國人章文嵩開發
- 流行度不亞於apache的httpd,基於TCP/IP做的路由和轉發,穩定性和效率很高
- LVS最新版本基於Linux內核2.6,有好多年不更新了
- LVS有三種常見的模式:NAT、DR、IP Tunnel
- LVS架構中有一個核心角色叫做分發器(Load balance),它用來分發用戶的請求,還有諸多處理用戶請求的服務器(Real Server,簡稱rs)
LVS NAT模式
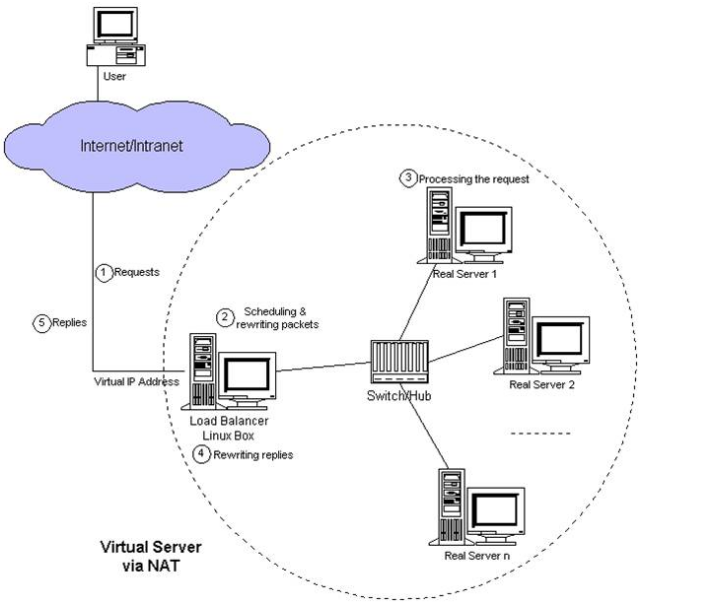
- 借助iptables的nat表來實現
- 用戶的請求到分發器後,通過預設的iptables規則,把請求的數據包轉發到後端的rs上去
- rs需要設定網關為分發器的內網ip
- 用戶請求的數據包和返回給用戶的數據包全部經過分發器,所以分發器成為瓶頸
- 在nat模式中,只需要分發器有公網ip即可,所以比較節省公網ip資源
LVS IP Tunnel模式
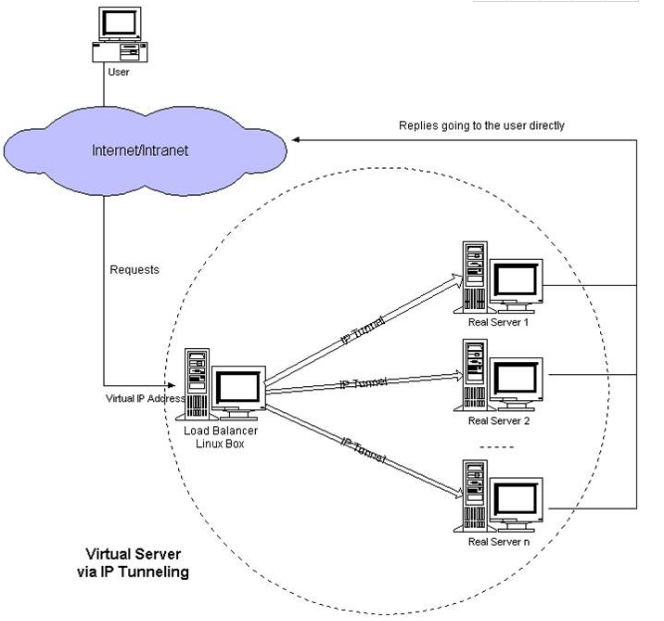
- 這種模式,需要有一個公共的IP配置在分發器和所有rs上,我們把它叫做vip
- 客戶端請求的目標IP為vip,分發器接收到請求數據包後,會對數據包做一個加工,會把目標IP改為rs的IP,這樣數據包就到了rs上
- rs接收數據包後,會還原原始數據包,這樣目標IP為vip,因為所有rs上配置了這個vip,所以它會認為是它自己
LVS DR模式
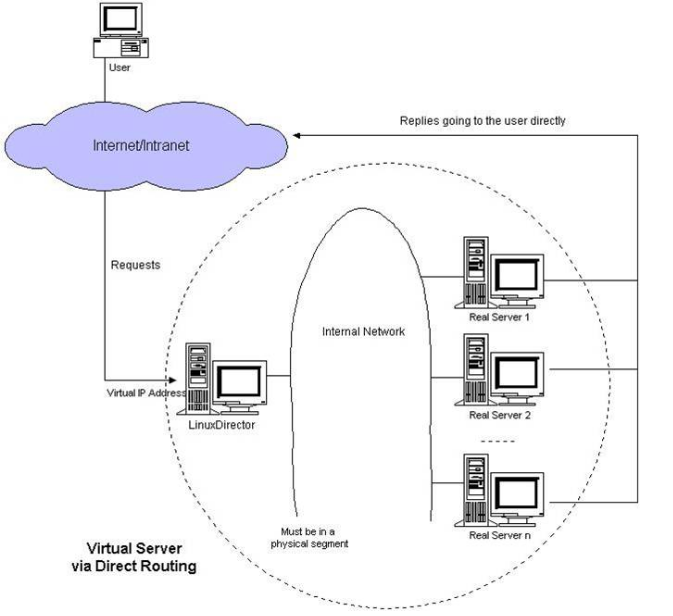
- 這種模式,也需要有一個公共的IP配置在分發器和所有rs上,也就是vip
- 和IP Tunnel不同的是,它會把數據包的MAC地址修改為rs的MAC地址
- rs接收數據包後,會還原原始數據包,這樣目標IP為vip,因為所有rs上配置了這個vip,所以它會認為是它自己
LVS調度算法
- 輪詢 Round-Robin rr
- 加權輪詢 Weight Round-Robin wrr
- 最小連接 Least-Connection lc
- 加權最小連接 Weight Least-Connection wlc
- 基於局部性的最小連接 Locality-Based Least Connections lblc
- 帶復制的基於局部性最小連接 Locality-Based Least Connections with Replication lblcr
- 目標地址散列調度 Destination Hashing dh
- 源地址散列調度 Source Hashing sh
常用的算法是前四種
18.9/18.10 LVS NAT模式搭建
| 環境: |
主機 | 內網ip | 外網IP |
|---|---|---|---|
| 分發器,可以叫調度器(簡寫為dir) | 192.168.0.220 | 172.16.22.220 | |
| rs1 | 192.168.0.221,網關192.168.0.220 | ||
| rs2 | 192.168.0.222,網關192.168.0.220 |

開啟遠程ssh反向連接
目的是為了遠程管理rs1,rs2
dr操作:
vim /etc/ssh/sshd_config#取消註釋
GatewayPorts yesservice sshd restartrs1,rs2操作:
ssh -ngfNTR 1122:192.168.0.221:22 [email protected] -o ServerAliveInterval=300ssh -ngfNTR 1222:192.168.0.222:22 [email protected] -o ServerAliveInterval=300[root@test221 ~]# w
20:38:21 up 11 days, 18 min, 1 user, load average: 0.00, 0.01, 0.05
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root pts/1 gateway 12:07 5.00s 0.05s 0.05s -bash
[root@test221 ~]# netstat -antp | grep sshd
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 27731/sshd
tcp 0 0 192.168.0.221:22 192.168.0.220:60408 ESTABLISHED 32072/sshd: root@pt
tcp6 0 0 :::22 :::* LISTEN 27731/sshd
[root@test222 ~]# w
20:37:34 up 9 days, 23:42, 1 user, load average: 0.00, 0.01, 0.05
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root pts/2 gateway 12:18 6.00s 0.02s 0.02s -bash
[root@test222 ~]# netstat -antp | grep sshd
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1113/sshd
tcp 0 0 192.168.0.222:22 192.168.0.220:52484 ESTABLISHED 32179/sshd: root@pt
tcp6 0 0 :::22 :::* LISTEN 1113/sshd 開啟防火墻nat轉發
dr:
[root@test220 ~]# firewall-cmd --permanent --direct --passthrough ipv4 -t nat POSTROUTING -o eth0 -j MASQUERADE -s 192.168.0.0/24[root@test220 ~]# firewall-cmd --reload 啟動網卡間核心轉發功能
[root@test220 ~]# sysctl -w net.ipv4.ip_forward=1
net.ipv4.ip_forward = 1
[root@test220 ~]# cat /proc/sys/net/ipv4/ip_forward #驗證是否打開
1安裝ipvsadm組件
yum install -y ipvsadmwlc算法:
#創建腳本,內容如下:
[root@test220 ~]# cat /usr/local/sbin/lvs_nat.sh#!/bin/bash
#director 服務器上開啟路由轉發功能,可省略
echo 1 > /proc/sys/net/ipv4/ip_forward
#關閉icmp的重定向
echo 0 > /proc/sys/net/ipv4/conf/all/send_redirects
echo 0 > /proc/sys/net/ipv4/conf/default/send_redirects
#註意區分網卡名字
echo 0 > /proc/sys/net/ipv4/conf/eth0/send_redirects
echo 0 > /proc/sys/net/ipv4/conf/eth1/send_redirects
#director 設置nat防火墻,使用iptables時有效,使用firewall-cmd使用上面的#firewall-cmd腳本
iptables -t nat -F
iptables -t nat -X
iptables -t nat -A POSTROUTING -s 192.168.0.0/24 -j MASQUERADE
#director設置ipvsadm
IPVSADM=‘/usr/sbin/ipvsadm‘
$IPVSADM -C
$IPVSADM -A -t 172.16.22.220:80 -s wlc -p 3
$IPVSADM -a -t 172.16.22.220:80 -r 192.168.0.221:80 -m -w 1
$IPVSADM -a -t 172.16.22.220:80 -r 192.168.0.222:80 -m -w 1
$IPVSADM -L -n#測試
使用curl -I http://172.16.22.220測試
~ Aiker$ curl -I 172.16.22.220
HTTP/1.1 200 OK
Server: nginx
Date: Tue, 27 Mar 2018 14:38:29 GMT
Content-Type: text/html
Content-Length: 1326
Last-Modified: Wed, 26 Apr 2017 08:03:46 GMT
Connection: keep-alive
Vary: Accept-Encoding
ETag: "59005462-52e"
Accept-Ranges: bytes
~ Aiker$ curl -I 172.16.22.220
HTTP/1.1 301 Moved Permanently
Server: nginx
Date: Tue, 27 Mar 2018 14:38:31 GMT
Content-Type: text/html; charset=UTF-8
Connection: keep-alive
X-Powered-By: PHP/5.6.34
location: forum.php
rr算法
定義ipvsadm負載均衡集群規則,並查看
此處定義DIP是以-s指定為rr算法進行輪詢調度,-m指定模式為lvs-nat,配置命令如下:
[root@test220 ~]# /usr/sbin/ipvsadm -C
[root@test220 ~]# /usr/sbin/ipvsadm -A -t 172.16.22.220:80 -s rr
[root@test220 ~]# /usr/sbin/ipvsadm -a -t 172.16.22.220:80 -r 192.168.0.221:80 -m
[root@test220 ~]# /usr/sbin/ipvsadm -a -t 172.16.22.220:80 -r 192.168.0.222:80 -m
測試
~ Aiker$ curl -I 172.16.22.220
HTTP/1.1 200 OK
Server: nginx
Date: Tue, 27 Mar 2018 14:38:26 GMT
Content-Type: text/html
Content-Length: 1326
Last-Modified: Wed, 26 Apr 2017 08:03:46 GMT
Connection: keep-alive
Vary: Accept-Encoding
ETag: "59005462-52e"
Accept-Ranges: bytes
~ Aiker$ curl -I 172.16.22.220
HTTP/1.1 301 Moved Permanently
Server: nginx
Date: Tue, 27 Mar 2018 14:38:28 GMT
Content-Type: text/html; charset=UTF-8
Connection: keep-alive
X-Powered-By: PHP/5.6.34
location: forum.phpwrr算法
[root@test220 ~]# cat !$
cat /usr/local/sbin/lvs_nat_wrr.sh
IPVSADM=‘/usr/sbin/ipvsadm‘
$IPVSADM -C
$IPVSADM -A -t 172.16.22.220:80 -s wrr
$IPVSADM -a -t 172.16.22.220:80 -r 192.168.0.221:80 -m -w 1
$IPVSADM -a -t 172.16.22.220:80 -r 192.168.0.222:80 -m -w 3
$IPVSADM -L -n
測試
~ Aiker$ curl -I 172.16.22.220
HTTP/1.1 200 OK
Server: nginx
Date: Wed, 28 Mar 2018 13:34:47 GMT
Content-Type: text/html
Content-Length: 1326
Last-Modified: Wed, 26 Apr 2017 08:03:46 GMT
Connection: keep-alive
Vary: Accept-Encoding
ETag: "59005462-52e"
Accept-Ranges: bytes
~ Aiker$ curl -I 172.16.22.220
HTTP/1.1 200 OK
Server: nginx
Date: Wed, 28 Mar 2018 13:34:48 GMT
Content-Type: text/html
Content-Length: 1326
Last-Modified: Wed, 26 Apr 2017 08:03:46 GMT
Connection: keep-alive
Vary: Accept-Encoding
ETag: "59005462-52e"
Accept-Ranges: bytes
~ Aiker$ curl -I 172.16.22.220
HTTP/1.1 200 OK
Server: nginx
Date: Wed, 28 Mar 2018 13:34:50 GMT
Content-Type: text/html
Content-Length: 1326
Last-Modified: Wed, 26 Apr 2017 08:03:46 GMT
Connection: keep-alive
Vary: Accept-Encoding
ETag: "59005462-52e"
Accept-Ranges: bytes
~ Aiker$ curl -I 172.16.22.220
HTTP/1.1 301 Moved Permanently
Server: nginx
Date: Wed, 28 Mar 2018 13:34:52 GMT
Content-Type: text/html; charset=UTF-8
Connection: keep-alive
X-Powered-By: PHP/5.6.34
location: forum.php
~ Aiker$ curl -I 172.16.22.220
HTTP/1.1 200 OK
Server: nginx
Date: Wed, 28 Mar 2018 13:35:04 GMT
Content-Type: text/html
Content-Length: 1326
Last-Modified: Wed, 26 Apr 2017 08:03:46 GMT
Connection: keep-alive
Vary: Accept-Encoding
ETag: "59005462-52e"
Accept-Ranges: bytes擴展
lvs 三種模式詳解
一、集群簡介
什麽是集群
計算機集群簡稱集群是一種計算機系統,它通過一組松散集成的計算機軟件和/或硬件連接起來高度緊密地協作完成計算工作。在某種意義上,他們可以被看作是一臺計算機。集群系統中的單個計算機通常稱為節點,通常通過局域網連接,但也有其它的可能連接方式。集群計算機通常用來改進單個計算機的計算速度和/或可靠性。一般情況下集群計算機比單個計算機,比如工作站或超級計算機性能價格比要高得多。
集群就是一組獨立的計算機,通過網絡連接組合成一個組合來共同完一個任務
LVS在企業架構中的位置:

以上的架構只是眾多企業裏面的一種而已。綠色的線就是用戶訪問請求的數據流向。用戶-->LVS負載均衡服務器--->apahce服務器--->mysql服務器&memcache服務器&共享存儲服務器。並且我們的mysql、共享存儲也能夠使用LVS再進行負載均衡。
---------------小結-------------------------
集群:就是一組相互獨立的計算機,通過高速的網絡組成一個計算機系統,每個集群節點都是運行其自己進程的一個獨立服務器。對網絡用戶來講,網站後端就是一個單一的系統,協同起來向用戶提供系統資源,系統服務。
為什麽要使用集群
集群的特點
1)高性能performance。一些需要很強的運算處理能力比如天氣預報,核試驗等。這就不是幾臺計算機能夠搞定的。這需要上千臺一起來完成這個工作的。
2)價格有效性
通常一套系統集群架構,只需要幾臺或數十臺服務器主機即可,與動則上百王的專用超級計算機具有更高的性價比。
3)可伸縮性
當服務器負載壓力增長的時候,系統能夠擴展來滿足需求,且不降低服務質量。
4)高可用性
盡管部分硬件和軟件發生故障,整個系統的服務必須是7*24小時運行的。
集群的優勢
1)透明性
如果一部分服務器宕機了業務不受影響,一般耦合度沒有那麽高,依賴關系沒有那麽高。比如NFS服務器宕機了其他就掛載不了了,這樣依賴性太強。
2)高性能
訪問量增加,能夠輕松擴展。
3)可管理性
整個系統可能在物理上很大,但很容易管理。
4)可編程性
在集群系統上,容易開發應用程序,門戶網站會要求這個。
集群分類及不同分類的特點
計算機集群架構按照功能和結構一般分成以下幾類:
1)負載均衡集群(Loadbalancingclusters)簡稱LBC
2)高可用性集群(High-availabilityclusters)簡稱HAC
3)高性能計算集群(High-perfomanceclusters)簡稱HPC
4)網格計算(Gridcomputing)
網絡上面一般認為是有三個,負載均衡和高可用集群式我們互聯網行業常用的集群架構。
(1)負載均衡集群
負載均衡集群為企業提供了更為實用,性價比更高的系統架構解決方案。負載均衡集群把很多客戶集中訪問的請求負載壓力可能盡可能平均的分攤到計算機集群中處理。客戶請求負載通常包括應用程度處理負載和網絡流量負載。這樣的系統非常適合向使用同一組應用程序為大量用戶提供服務。每個節點都可以承擔一定的訪問請求負載壓力,並且可以實現訪問請求在各節點之間動態分配,以實現負載均衡。
負載均衡運行時,一般通過一個或多個前端負載均衡器將客戶訪問請求分發到後端一組服務器上,從而達到整個系統的高性能和高可用性。這樣計算機集群有時也被稱為服務器群。一般高可用性集群和負載均衡集群會使用類似的技術,或同時具有高可用性與負載均衡的特點。
負載均衡集群的作用
1)分擔訪問流量(負載均衡)
2)保持業務的連續性(高可用)
(2)高可用性集群
一般是指當集群中的任意一個節點失效的情況下,節點上的所有任務自動轉移到其他正常的節點上,並且此過程不影響整個集群的運行,不影響業務的提供。
類似是集群中運行著兩個或兩個以上的一樣的節點,當某個主節點出現故障的時候,那麽其他作為從 節點的節點就會接替主節點上面的任務。從節點可以接管主節點的資源(IP地址,架構身份等),此時用戶不會發現提供服務的對象從主節點轉移到從節點。
高可用性集群的作用:當一個機器宕機另一臺進行接管。比較常用的高可用集群開源軟件有:keepalive,heardbeat。
(3)高性能計算集群
高性能計算集群采用將計算任務分配到集群的不同計算節點兒提高計算能力,因而主要應用在科學計算領域。比較流行的HPC采用Linux操作系統和其它一些免費軟件來完成並行運算。這一集群配置通常被稱為Beowulf集群。這類集群通常運行特定的程序以發揮HPCcluster的並行能力。這類程序一般應用特定的運行庫, 比如專為科學計算設計的MPI庫。
HPC集群特別適合於在計算中各計算節點之間發生大量數據通訊的計算作業,比如一個節點的中間結果或影響到其它節點計算結果的情況。
常用集群軟硬件
常用開源集群軟件有:lvs,keepalived,haproxy,nginx,apache,heartbeat
常用商業集群硬件有:F5,Netscaler,Radware,A10等
二、LVS負載均衡集群介紹
負載均衡集群的作用:提供一種廉價、有效、透明的方法,來擴展網絡設備和服務器的負載帶寬、增加吞吐量,加強網絡數據處理能力、提高網絡的靈活性和可用性。
1)把單臺計算機無法承受的大規模的並發訪問或數據流量分擔到多臺節點設備上分別處理,減少用戶等待響應的時間,提升用戶體驗。
2)單個重負載的運算分擔到多臺節點設備上做並行處理,每個節點設備處理結束後,將結果匯總,返回給用戶,系統處理能力得到大幅度提高。
3)7*24小時的服務保證,任意一個或多個設備節點設備宕機,不能影響到業務。在負載均衡集群中,所有計算機節點都應該提供相同的服務,集群負載均衡獲取所有對該服務的如站請求。
LVS介紹
LVS是linux virtual server的簡寫linux虛擬服務器,是一個虛擬的服務器集群系統,可以再unix/linux平臺下實現負載均衡集群功能。該項目在1998年5月由章文嵩博士組織成立。
以下是LVS官網提供的4篇文章:(非常詳細,我覺得有興趣還是看官方文檔比較正宗吧!!)
http://www.linuxvirtualserver.org/zh/lvs1.html
http://www.linuxvirtualserver.org/zh/lvs2.html
http://www.linuxvirtualserver.org/zh/lvs3.html
http://www.linuxvirtualserver.org/zh/lvs4.html
IPVS發展史
早在2.2內核時,IPVS就已經以內核補丁的形式出現。
從2.4.23版本開始ipvs軟件就是合並到linux內核的常用版本的內核補丁的集合。
從2.4.24以後IPVS已經成為linux官方標準內核的一部分

從上圖可以看出lpvs是工作在內核層,我們不能夠直接操作ipvs,vs負載均衡調度技術是在linux內核中實現的。因此,被稱之為linux虛擬服務器。我們使用該軟件配置lvs的時候,不能直接配置內核中的ipvs,而需要使用ipvs的管理工具ipvsadm進行管理。通過keepalived也可以管理LVS。
LVS體系結構與工作原理簡單描述
LVS集群負載均衡器接受服務的所有入展客戶端的請求,然後根據調度算法決定哪個集群節點來處理回復客戶端的請求。
LVS虛擬服務器的體系如下圖所示,一組服務器通過高速的局域網或者地理分布的廣域網相互連接,在這組服務器之前有一個負載調度器(load balance)。負載調度器負責將客戶的請求調度到真實服務器上。這樣這組服務器集群的結構對用戶來說就是透明的。客戶訪問集群系統就如只是訪問一臺高性能,高可用的服務器一樣。客戶程序不受服務器集群的影響,不做任何修改。
就比如說:我們去飯店吃飯點菜,客戶只要跟服務員點菜就行。並不需要知道具體他們是怎麽分配工作的,所以他們內部對於我們來說是透明的。此時這個服務員就會按照一定的規則把他手上的活,分配到其他人員上去。這個服務員就是負載均衡器(LB)而後面這些真正做事的就是服務器集群。
底下是官網提供的結構圖:

LVS的基本工作過程

客戶請發送向負載均衡服務器發送請求。負載均衡器接受客戶的請求,然後先是根據LVS的調度算法(8種)來決定要將這個請求發送給哪個節點服務器。然後依據自己的工作模式(3種)來看應該如何把這些客戶的請求如何發送給節點服務器,節點服務器又應該如何來把響應數據包發回給客戶端。
恩,那這樣我們就只要接下來搞懂LVS的3中工作模式,8種調度算法就可以了。
LVS的三種工作模式:
1)VS/NAT模式(Network address translation)
2)VS/TUN模式(tunneling)
3)DR模式(Direct routing)
1、NAT模式-網絡地址轉換
Virtualserver via Network address translation(VS/NAT)
這個是通過網絡地址轉換的方法來實現調度的。首先調度器(LB)接收到客戶的請求數據包時(請求的目的IP為VIP),根據調度算法決定將請求發送給哪個後端的真實服務器(RS)。然後調度就把客戶端發送的請求數據包的目標IP地址及端口改成後端真實服務器的IP地址(RIP),這樣真實服務器(RS)就能夠接收到客戶的請求數據包了。真實服務器響應完請求後,查看默認路由(NAT模式下我們需要把RS的默認路由設置為LB服務器。)把響應後的數據包發送給LB,LB再接收到響應包後,把包的源地址改成虛擬地址(VIP)然後發送回給客戶端。
調度過程IP包詳細圖:

原理圖簡述:
1)客戶端請求數據,目標IP為VIP
2)請求數據到達LB服務器,LB根據調度算法將目的地址修改為RIP地址及對應端口(此RIP地址是根據調度算法得出的。)並在連接HASH表中記錄下這個連接。
3)數據包從LB服務器到達RS服務器webserver,然後webserver進行響應。Webserver的網關必須是LB,然後將數據返回給LB服務器。
4)收到RS的返回後的數據,根據連接HASH表修改源地址VIP&目標地址CIP,及對應端口80.然後數據就從LB出發到達客戶端。
5)客戶端收到的就只能看到VIP\DIP信息。
NAT模式優缺點:
1、NAT技術將請求的報文和響應的報文都需要通過LB進行地址改寫,因此網站訪問量比較大的時候LB負載均衡調度器有比較大的瓶頸,一般要求最多之能10-20臺節點
2、只需要在LB上配置一個公網IP地址就可以了。
3、每臺內部的節點服務器的網關地址必須是調度器LB的內網地址。
4、NAT模式支持對IP地址和端口進行轉換。即用戶請求的端口和真實服務器的端口可以不一致。
2、TUN模式
virtual server via ip tunneling模式:采用NAT模式時,由於請求和響應的報文必須通過調度器地址重寫,當客戶請求越來越多時,調度器處理能力將成為瓶頸。為了解決這個問題,調度器把請求的報文通過IP隧道轉發到真實的服務器。真實的服務器將響應處理後的數據直接返回給客戶端。這樣調度器就只處理請求入站報文,由於一般網絡服務應答數據比請求報文大很多,采用VS/TUN模式後,集群系統的最大吞吐量可以提高10倍。
VS/TUN的工作流程圖如下所示,它和NAT模式不同的是,它在LB和RS之間的傳輸不用改寫IP地址。而是把客戶請求包封裝在一個IP tunnel裏面,然後發送給RS節點服務器,節點服務器接收到之後解開IP tunnel後,進行響應處理。並且直接把包通過自己的外網地址發送給客戶不用經過LB服務器。
Tunnel原理流程圖:

原理圖過程簡述:
1)客戶請求數據包,目標地址VIP發送到LB上。
2)LB接收到客戶請求包,進行IP Tunnel封裝。即在原有的包頭加上IP Tunnel的包頭。然後發送出去。
3)RS節點服務器根據IP Tunnel包頭信息(此時就又一種邏輯上的隱形隧道,只有LB和RS之間懂)收到請求包,然後解開IP Tunnel包頭信息,得到客戶的請求包並進行響應處理。
4)響應處理完畢之後,RS服務器使用自己的出公網的線路,將這個響應數據包發送給客戶端。源IP地址還是VIP地址。(RS節點服務器需要在本地回環接口配置VIP,後續會講)
3、DR模式(直接路由模式)
Virtual server via direct routing (vs/dr)
DR模式是通過改寫請求報文的目標MAC地址,將請求發給真實服務器的,而真實服務器響應後的處理結果直接返回給客戶端用戶。同TUN模式一樣,DR模式可以極大的提高集群系統的伸縮性。而且DR模式沒有IP隧道的開銷,對集群中的真實服務器也沒有必要必須支持IP隧道協議的要求。但是要求調度器LB與真實服務器RS都有一塊網卡連接到同一物理網段上,必須在同一個局域網環境。
DR模式是互聯網使用比較多的一種模式。
DR模式原理圖:

DR模式原理過程簡述:
VS/DR模式的工作流程圖如上圖所示,它的連接調度和管理與NAT和TUN中的一樣,它的報文轉發方法和前兩種不同。DR模式將報文直接路由給目標真實服務器。在DR模式中,調度器根據各個真實服務器的負載情況,連接數多少等,動態地選擇一臺服務器,不修改目標IP地址和目標端口,也不封裝IP報文,而是將請求報文的數據幀的目標MAC地址改為真實服務器的MAC地址。然後再將修改的數據幀在服務器組的局域網上發送。因為數據幀的MAC地址是真實服務器的MAC地址,並且又在同一個局域網。那麽根據局域網的通訊原理,真實復位是一定能夠收到由LB發出的數據包。真實服務器接收到請求數據包的時候,解開IP包頭查看到的目標IP是VIP。_(此時只有自己的IP符合目標IP才會接收進來,所以我們需要在本地的回環借口上面配置VIP。另:由於網絡接口都會進行ARP廣播響應,但集群的其他機器都有這個VIP的lo接口,都響應就會沖突。所以我們需要把真實服務器的lo接口的ARP__響應關閉掉。)_然後真實服務器做成請求響應,之後根據自己的路由信息將這個響應數據包發送回給客戶,並且源IP地址還是VIP。
DR模式小結:
1、通過在調度器LB上修改數據包的目的MAC地址實現轉發。註意源地址仍然是CIP,目的地址仍然是VIP地址。
2、請求的報文經過調度器,而RS響應處理後的報文無需經過調度器LB,因此並發訪問量大時使用效率很高(和NAT模式比)
3、因為DR模式是通過MAC地址改寫機制實現轉發,因此所有RS節點和調度器LB只能在一個局域網裏面
4、RS主機需要綁定VIP地址在LO接口上,並且需要配置ARP抑制。
5、RS節點的默認網關不需要配置成LB,而是直接配置為上級路由的網關,能讓RS直接出網就可以。
6、由於DR模式的調度器僅做MAC地址的改寫,所以調度器LB就不能改寫目標端口,那麽RS服務器就得使用和VIP相同的端口提供服務。
官方三種負載均衡技術比較總結表:
工作模式
VS/NAT
VS/TUN
VS/DR
Real server
(節點服務器)
Config dr gw
Tunneling
Non-arp device/tie vip
Server Network
Private
LAN/WAN
LAN
Server number
(節點數量)
Low 10-20
High 100
High 100
Real server gateway
Load balance
Own router
Own router
優點
地址和端口轉換
Wan環境加密數據
性能最高
缺點
效率低
需要隧道支持
不能跨域LAN
LVS調度算法
最好參考此文章:http://www.linuxvirtualserver.org/zh/lvs4.html
Lvs的調度算法決定了如何在集群節點之間分布工作負荷。當director調度器收到來自客戶端訪問VIP的上的集群服務的入站請求時,director調度器必須決定哪個集群節點應該處理請求。Director調度器用的調度方法基本分為兩類:
固定調度算法:rr,wrr,dh,sh
動態調度算法:wlc,lc,lblc,lblcr
算法
說明
rr
輪詢算法,它將請求依次分配給不同的rs節點,也就是RS節點中均攤分配。這種算法簡單,但只適合於RS節點處理性能差不多的情況
wrr
加權輪訓調度,它將依據不同RS的權值分配任務。權值較高的RS將優先獲得任務,並且分配到的連接數將比權值低的RS更多。相同權值的RS得到相同數目的連接數。
Wlc
加權最小連接數調度,假設各臺RS的全職依次為Wi,當前tcp連接數依次為Ti,依次去Ti/Wi為最小的RS作為下一個分配的RS
Dh
目的地址哈希調度(destination hashing)以目的地址為關鍵字查找一個靜態hash表來獲得需要的RS
SH
源地址哈希調度(source hashing)以源地址為關鍵字查找一個靜態hash表來獲得需要的RS
Lc
最小連接數調度(least-connection),IPVS表存儲了所有活動的連接。LB會比較將連接請求發送到當前連接最少的RS.
Lblc
基於地址的最小連接數調度(locality-based least-connection):將來自同一個目的地址的請求分配給同一臺RS,此時這臺服務器是尚未滿負荷的。否則就將這個請求分配給連接數最小的RS,並以它作為下一次分配的首先考慮。
LVS調度算法的生產環境選型:
1、一般的網絡服務,如http,mail,mysql等常用的LVS調度算法為:
a.基本輪詢調度rr
b.加權最小連接調度wlc
c.加權輪詢調度wrc
2、基於局部性的最小連接lblc和帶復制的給予局部性最小連接lblcr主要適用於web cache和DB cache
3、源地址散列調度SH和目標地址散列調度DH可以結合使用在防火墻集群中,可以保證整個系統的出入口唯一。
實際適用中這些算法的適用範圍很多,工作中最好參考內核中的連接調度算法的實現原理,然後根據具體的業務需求合理的選型。
-----------------後續自我小結--------------------------------------------------
基本上lvs的原理部分就到這裏,個人還是覺得像要對LVS有一個比較全面的認識,還是需要去將官方文檔認真的看過一遍。主要部分還是在於3種工作方式和8種調度算法。以及實際工作種什麽樣的生產環境適用哪種調度算法。
http://www.it165.net/admin/html/201401/2248.html
lvs幾種算法
LVS主要的調度算法
輪詢調度-加權輪詢調度-最小連接調度-加權最小連接調度-基於局部性的最少連接-
帶復制的基於局部性的最少連接-目標地址散列調度-源地址散列調度
1:輪詢算法(RR)就是按依次循環的方式將請求調度到不同的服務器上,該算法最大的特點就是實現簡單。輪詢算法假設所有的服務器處理請求的能力都是一樣的,調度器會將所有的請求平均分配給每個真實服務器
2:加權輪詢算法(WRR)主要是對輪詢算法的一種優化與補充,LVS會考慮每臺服務器的性能,並給每臺服務器添加一個權值,如果服務器A的權值為1,服務器B的權值為2,則調度到服務器B的請求會是服務器A的兩倍。權值越高的服務器,處理的請求越多。
3:最小連接調度算法(LC)將把請求調度到連續數量最小的服務器上,
4:加權最小連接算法(WLC)則是給每臺服務器一個權值,調度器會盡可能保持服務器連接數量與權值之間的平衡
5:基於局部性的最少連接調度算法(lblc)是請求數據包的目標IP地址的一種調度算法,該算法先根據請求的目標IP地址尋找最近的該目標IP地址所有使用的服務器,如果這臺服務器依然可用,並且用能力處理該請求,調度器會盡量選擇相同的服務器,否則會繼續選擇其他可行的服務器。
6:帶復雜的基於局部性最少的連接算法(lblcr)激勵的不是一個目標IP與一臺服務器之間的連接記錄,他會維護一個目標IP到一組服務器之間的映射關系,防止單點服務器負責過高
7:目標地址散列調度算法(DH)也是根據目標IP地址通過散列函數將目標IP與服務器建立映射關系,出現服務器不可用或負載過高的情況下,發往該目標IP的請求會固定發給該服務器。
8:源地址散列調度算法(SH)與目標地址散列調度算法類似,但它是根據源地址散列算法進行靜態分配固定的服務器資源
http://www.aminglinux.com/bbs/thread-7407-1-1.html
關於arp_ignore和 arp_announce
先簡單的介紹下關於LVS負載均衡
LVS(Linux Virtual Server)Linux服務器集群系統
針對高可伸縮,高可用服務的需求,給予IP層和內容請求分發的負載均衡調度解決方法,並在Linux的內核中實現,將一組服務器構成一個實現可伸縮,高可用網絡服務的虛擬服務器
負載均衡
1.大量的兵法訪問或數據流量分擔到多態節點設備分別處理,減少用戶的等待時間
2.單個重負載的運算分擔到多態節點設備上做並行處理,每個節點設備處理結束後,將結果匯總,返回給用戶
負載調度器
一組服務器通過高速的局域網或者地理分布的廣域網相互相連,在他們的前端有一個負載均衡調度器(Load Balancer),負載均衡調度器能無縫的將網絡請求調度到真實的服務器上,從而使得服務器集群的結構對用戶是透明的,用戶通過訪問集群系統提供的網絡服務,就像訪問一臺高性能,高可用的服務器。
IP負載均衡技術(三種)
1.VS/NAT(網絡地址轉換)
通過網絡地址轉換,調度器重寫請求報文的目標地址,根據預設的調度算法,將請求分發給後端的真實服務器,真實服務器的響應報文通過調度器時,報文的源地址被重寫,再返回到客戶端,完成整個調度的過程
2.VS/TUN(IP隧道模式)
調度器將請求的報文通過IP隧道轉發至真實服務器,而真實的服務器直接將結果返回給用戶,調度器只處理請求報文,由於一般網路服務的應答大於請求,采用IP隧道模式,集群系統的最大吞吐量可以提高10倍。
3.VS/DR(直接路由)
通過改寫請求報文的MAC地址,將請求發送到真是服務器,真實服務器將響應直接返回給用戶,之際額路由模式可以極大的提高集群系統的伸縮性,這種方法沒有IP隧道的開銷,集群中真實的服務器也沒有必要必須支持IP隧道協議,只是需要調度器與真實服務器有一塊網卡連在同一物理網段上。
其中在這三種IP負載均衡的技術中,DR和TUN模式都需要在真實服務器上對arp_ignore和arp_announce參數進行配置,主要是實現禁止響應對VIP的ARP請求。
在lvs環境中,需要設定以下的參數
echo "1" > /proc/sys/net/ipv4/conf/all/arp_ignore
echo "1" > /proc/sys/net/ipv4/conf/lo/arp_ignore
echo "2" > /proc/sys/net/ipv4/conf/lo/arp_announce
echo "2" > /proc/sys/net/ipv4/conf/all/arp_announce先來看看關於arp_ignore和arp_announce的有關介紹
有關arp_ignore的相關介紹:
arp_ignore - INTEGER
Define different modes for sending replies in response to
received ARP requests that resolve local target IP addresses:
0 - (default): reply for any local target IP address, configured
on any interface
1 - reply only if the target IP address is local address
configured on the incoming interface
2 - reply only if the target IP address is local address
configured on the incoming interface and both with the
sender‘s IP address are part from same subnet on this interface
3 - do not reply for local addresses configured with scope host,
only resolutions for global and link addresses are replied
4-7 - reserved
8 - do not reply for all local addresses
The max value from conf/{all,interface}/arp_ignore is used
when ARP request is received on the {interface}arp_ignore:定義對目標地址為本地IP的ARP詢問不同的應答模式0
0 - (默認值): 回應任何網絡接口上對任何本地IP地址的arp查詢請求
1 - 只回答目標IP地址是來訪網絡接口本地地址的ARP查詢請求
2 -只回答目標IP地址是來訪網絡接口本地地址的ARP查詢請求,且來訪IP必須在該網絡接口的子網段內
3 - 不回應該網絡界面的arp請求,而只對設置的唯一和連接地址做出回應
4-7 - 保留未使用
8 -不回應所有(本地地址)的arp查詢
有關arp_announce的相關介紹:
arp_announce - INTEGER
Define different restriction levels for announcing the local
source IP address from IP packets in ARP requests sent on
interface:
0 - (default) Use any local address, configured on any interface
1 - Try to avoid local addresses that are not in the target‘s
subnet for this interface. This mode is useful when target
hosts reachable via this interface require the source IP
address in ARP requests to be part of their logical network
configured on the receiving interface. When we generate the
request we will check all our subnets that include the
target IP and will preserve the source address if it is from
such subnet. If there is no such subnet we select source
address according to the rules for level 2.
2 - Always use the best local address for this target.
In this mode we ignore the source address in the IP packet
and try to select local address that we prefer for talks with
the target host. Such local address is selected by looking
for primary IP addresses on all our subnets on the outgoing
interface that include the target IP address. If no suitable
local address is found we select the first local address
we have on the outgoing interface or on all other interfaces,
with the hope we will receive reply for our request and
even sometimes no matter the source IP address we announce.
The max value from conf/{all,interface}/arp_announce is used.
Increasing the restriction level gives more chance for
receiving answer from the resolved target while decreasing
the level announces more valid sender‘s information.arp_announce:對網絡接口上,本地IP地址的發出的,ARP回應,作出相應級別的限制: 確定不同程度的限制,宣布對來自本地源IP地址發出Arp請求的接口
0 - (默認) 在任意網絡接口(eth0,eth1,lo)上的任何本地地址
1 -盡量避免不在該網絡接口子網段的本地地址做出arp回應. 當發起ARP請求的源IP地址是被設置應該經由路由達到此網絡接口的時候很有用.此時會檢查來訪IP是否為所有接口上的子網段內ip之一.如果改來訪IP不屬於各個網絡接口上的子網段內,那麽將采用級別2的方式來進行處理.
2 - 對查詢目標使用最適當的本地地址.在此模式下將忽略這個IP數據包的源地址並嘗試選擇與能與該地址通信的本地地址.首要是選擇所有的網絡接口的子網中外出訪問子網中包含該目標IP地址的本地地址. 如果沒有合適的地址被發現,將選擇當前的發送網絡接口或其他的有可能接受到該ARP回應的網絡接口來進行發送.
關於對arp_announce 理解的一點補充
Assume that a linux box X has three interfaces - eth0, eth1 and eth2. Each interface has an IP address IP0,
IP1 and IP2. When a local application tries to send an IP packet with IP0 through the eth2. Unfortunately,
the target node’s mac address is not resolved. Thelinux box X will send the ARP request to know
the mac address of the target(or the gateway). In this case what is the IP source address of the
“ARP request message”? The IP0- the IP source address of the transmitting IP or IP2 - the outgoing
interface? Until now(actually just 3 hours before) ARP request uses the IP address assigned to
the outgoing interface(IP2 in the above example) However the linux’s behavior is a little bit
different. Actually the selection of source address in ARP request is totally configurable
bythe proc variable “arp_announce”
If we want to use the IP2 not the IP0 in the ARP request, we should change the value to 1 or 2.
The default value is 0 - allow IP0 is used for ARP request.
其實就是路由器的問題,因為路由器一般是動態學習ARP包的(一般動態配置DHCP的話),當內網的機器要發送一個到外部的ip包,那麽它就會請求 路由器的Mac地址,發送一個arp請求,這個arp請求裏面包括了自己的ip地址和Mac地址,而linux默認是使用ip的源ip地址作為arp裏面 的源ip地址,而不是使用發送設備上面的 ,這樣在lvs這樣的架構下,所有發送包都是同一個VIP地址,那麽arp請求就會包括VIP地址和設備 Mac,而路由器收到這個arp請求就會更新自己的arp緩存,這樣就會造成ip欺騙了,VIP被搶奪,所以就會有問題。
arp緩存為什麽會更新了,什麽時候會更新呢,為了減少arp請求的次數,當主機接收到詢問自己的arp請求的時候,就會把源ip和源Mac放入自 己的arp表裏面,方便接下來的通訊。如果收到不是詢問自己的包(arp是廣播的,所有人都收到),就會丟掉,這樣不會造成arp表裏面無用數據太多導致 有用的記錄被刪除。
在設置參數的時候將arp_ignore 設置為1,意味著當別人的arp請求過來的時候,如果接收的設備上面沒有這個ip,就不做出響應,默認是0,只要這臺機器上面任何一個設備上面有這個ip,就響應arp請求,並發送mac地址
其它的相關資料:
http://kb.linuxvirtualserver.org/wiki/Using_arp_announce/arp_ignore_to_disable_ARP]
http://itnihao.blog.51cto.com/1741976/752472
http://www.cnblogs.com/lgfeng/archive/2012/10/16/2726308.html
lvs原理相關的
LVS簡介
Internet的快速增長使多媒體網絡服務器面對的訪問數量快速增加,服務器需要具備提供大量並發訪問服務的能力,因此對於大負載的服務器來講, CPU、I/O處理能力很快會成為瓶頸。由於單臺服務器的性能總是有限的,簡單的提高硬件性能並不能真正解決這個問題。為此,必須采用多服務器和負載均衡技術才能滿足大量並發訪問的需要。Linux 虛擬服務器(Linux Virtual Servers,LVS) 使用負載均衡技術將多臺服務器組成一個虛擬服務器。它為適應快速增長的網絡訪問需求提供了一個負載能力易於擴展,而價格低廉的解決方案。
LVS結構與工作原理
一.LVS的結構
LVS由前端的負載均衡器(Load Balancer,LB)和後端的真實服務器(Real Server,RS)群組成。RS間可通過局域網或廣域網連接。LVS的這種結構對用戶是透明的,用戶只能看見一臺作為LB的虛擬服務器(Virtual Server),而看不到提供服務的RS群。當用戶的請求發往虛擬服務器,LB根據設定的包轉發策略和負載均衡調度算法將用戶請求轉發給RS。RS再將用戶請求結果返回給用戶。
二.LVS內核模型
1.當客戶端的請求到達負載均衡器的內核空間時,首先會到達PREROUTING鏈。
2.當內核發現請求數據包的目的地址是本機時,將數據包送往INPUT鏈。
3.LVS由用戶空間的ipvsadm和內核空間的IPVS組成,ipvsadm用來定義規則,IPVS利用ipvsadm定義的規則工作,IPVS工作在INPUT鏈上,當數據包到達INPUT鏈時,首先會被IPVS檢查,如果數據包裏面的目的地址及端口沒有在規則裏面,那麽這條數據包將被放行至用戶空間。
4.如果數據包裏面的目的地址及端口在規則裏面,那麽這條數據報文將被修改目的地址為事先定義好的後端服務器,並送往POSTROUTING鏈。
5.最後經由POSTROUTING鏈發往後端服務器。


三.LVS的包轉發模型
1.NAT模型:
①.客戶端將請求發往前端的負載均衡器,請求報文源地址是CIP(客戶端IP),後面統稱為CIP),目標地址為VIP(負載均衡器前端地址,後面統稱為VIP)。
②.負載均衡器收到報文後,發現請求的是在規則裏面存在的地址,那麽它將客戶端請求報文的目標地址改為了後端服務器的RIP地址並將報文根據算法發送出去。
③.報文送到Real Server後,由於報文的目標地址是自己,所以會響應該請求,並將響應報文返還給LVS。
④.然後lvs將此報文的源地址修改為本機並發送給客戶端。
註意:在NAT模式中,Real Server的網關必須指向LVS,否則報文無法送達客戶端。

2.DR模型:
①.客戶端將請求發往前端的負載均衡器,請求報文源地址是CIP,目標地址為VIP。
②.負載均衡器收到報文後,發現請求的是在規則裏面存在的地址,那麽它將客戶端請求報文的源MAC地址改為自己DIP的MAC地址,目標MAC改為了RIP的MAC地址,並將此包發送給RS。
③.RS發現請求報文中的目的MAC是自己,就會將次報文接收下來,處理完請求報文後,將響應報文通過lo接口送給eth0網卡直接發送給客戶端。
註意:需要設置lo接口的VIP不能響應本地網絡內的arp請求。

3.TUN模型:
①.客戶端將請求發往前端的負載均衡器,請求報文源地址是CIP,目標地址為VIP。
②.負載均衡器收到報文後,發現請求的是在規則裏面存在的地址,那麽它將在客戶端請求報文的首部再封裝一層IP報文,將源地址改為DIP,目標地址改為RIP,並將此包發送給RS。
③.RS收到請求報文後,會首先拆開第一層封裝,然後發現裏面還有一層IP首部的目標地址是自己lo接口上的VIP,所以會處理次請求報文,並將響應報文通過lo接口送給eth0網卡直接發送給客戶端。
註意:需要設置lo接口的VIP不能在共網上出現。

四.LVS的調度算法
LVS的調度算法分為靜態與動態兩類。
1.靜態算法(4種):只根據算法進行調度 而不考慮後端服務器的實際連接情況和負載情況
①.RR:輪叫調度(Round Robin)
調度器通過”輪叫”調度算法將外部請求按順序輪流分配到集群中的真實服務器上,它均等地對待每一臺服務器,而不管服務器上實際的連接數和系統負載?②.WRR:加權輪叫(Weight RR)
調度器通過“加權輪叫”調度算法根據真實服務器的不同處理能力來調度訪問請求。這樣可以保證處理能力強的服務器處理更多的訪問流量。調度器可以自動問詢真實服務器的負載情況,並動態地調整其權值。③.DH:目標地址散列調度(Destination Hash )
根據請求的目標IP地址,作為散列鍵(HashKey)從靜態分配的散列表找出對應的服務器,若該服務器是可用的且未超載,將請求發送到該服務器,否則返回空。④.SH:源地址 hash(Source Hash)
源地址散列”調度算法根據請求的源IP地址,作為散列鍵(HashKey)從靜態分配的散列表找出對應的服務器,若該服務器是可用的且未超載,將請求發送到該服務器,否則返回空?
2.動態算法(6種):前端的調度器會根據後端真實服務器的實際連接情況來分配請求
①.LC:最少鏈接(Least Connections)
調度器通過”最少連接”調度算法動態地將網絡請求調度到已建立的鏈接數最少的服務器上。如果集群系統的真實服務器具有相近的系統性能,采用”最小連接”調度算法可以較好地均衡負載。②.WLC:加權最少連接(默認采用的就是這種)(Weighted Least Connections)
在集群系統中的服務器性能差異較大的情況下,調度器采用“加權最少鏈接”調度算法優化負載均衡性能,具有較高權值的服務器將承受較大比例的活動連接負載?調度器可以自動問詢真實服務器的負載情況,並動態地調整其權值。③.SED:最短延遲調度(Shortest Expected Delay )
在WLC基礎上改進,Overhead = (ACTIVE+1)*256/加權,不再考慮非活動狀態,把當前處於活動狀態的數目+1來實現,數目最小的,接受下次請求,+1的目的是為了考慮加權的時候,非活動連接過多缺陷:當權限過大的時候,會倒置空閑服務器一直處於無連接狀態。④.NQ永不排隊/最少隊列調度(Never Queue Scheduling NQ)
無需隊列。如果有臺 realserver的連接數=0就直接分配過去,不需要再進行sed運算,保證不會有一個主機很空間。在SED基礎上無論+幾,第二次一定給下一個,保證不會有一個主機不會很空閑著,不考慮非活動連接,才用NQ,SED要考慮活動狀態連接,對於DNS的UDP不需要考慮非活動連接,而httpd的處於保持狀態的服務就需要考慮非活動連接給服務器的壓力。⑤.LBLC:基於局部性的最少鏈接(locality-Based Least Connections)
基於局部性的最少鏈接”調度算法是針對目標IP地址的負載均衡,目前主要用於Cache集群系統?該算法根據請求的目標IP地址找出該目標IP地址最近使用的服務器,若該服務器是可用的且沒有超載,將請求發送到該服務器;若服務器不存在,或者該服務器超載且有服務器處於一半的工作負載,則用“最少鏈接”的原則選出一個可用的服務器,將請求發送到該服務器?⑥. LBLCR:帶復制的基於局部性最少連接(Locality-Based Least Connections with Replication)
帶復制的基於局部性最少鏈接”調度算法也是針對目標IP地址的負載均衡,目前主要用於Cache集群系統?它與LBLC算法的不同之處是它要維護從一個目標IP地址到一組服務器的映射,而LBLC算法維護從一個目標IP地址到一臺服務器的映射?該算法根據請求的目標IP地址找出該目標IP地址對應的服務器組,按”最小連接”原則從服務器組中選出一臺服務器,若服務器沒有超載,將請求發送到該服務器;若服務器超載,則按“最小連接”原則從這個集群中選出一臺服務器,將該服務器加入到服務器組中,將請求發送到該服務器?同時,當該服務器組有一段時間沒有被修改,將最忙的服務器從服務器組中刪除,以降低復制的程度。
http://blog.csdn.net/pi9nc/article/details/23380589
十五周二次課