
獨家解密:阿裏是如何應對超大規模集群資源管理挑戰的?
你辦得到嗎?

互聯網應用和現代數據中心
雲計算已經火了很多年了,早已開始惠及我們每一個人。今天火熱的大數據、機器學習、人工智能、以及我們看到的像淘寶、天貓、優酷等大規模的互聯網應用都是運行在雲上的。而支撐雲的,是大型雲計算服務商部署在世界各地的多個數據中心,每個數據中心都有大量的物理服務器。為了有效的管理這些服務器,我們需要集群資源管理系統(Cluster Resource Management System),後面簡稱資源管理系統。資源管理系統的價值,用一句話說,是Datacenter as a Computer,像管理和使用一個臺電腦一樣簡單地管理和使用數據中心。
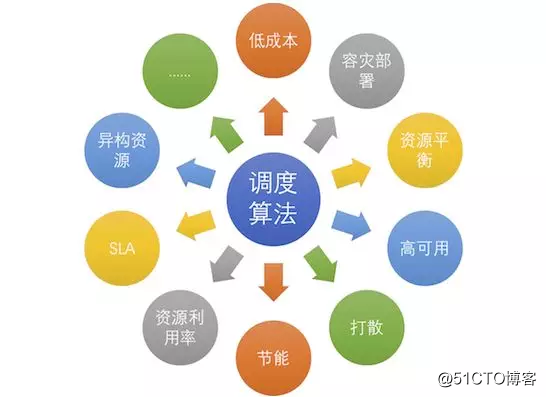
資源管理系統作為將數據中心資源向上抽象的關鍵一層,需要全面的能力。從保障應用的穩定性、性能(保證SLA,Service Level Agreement)到全面提高數據中心運行的效率,節約能源等等,今天這篇文章,我們重點講一講調度算法在資源管理中的作用。
調度算法的價值
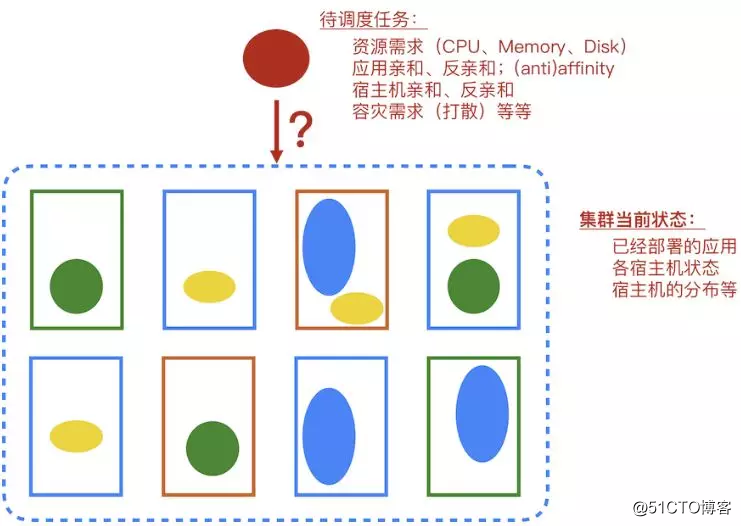
調度算法在是整個資源管理系統中的一個重要組成部分,簡單的說,調度算法的作用是決定一個計算任務需要放在集群中的哪臺機器上面。
在容器化的今天,集群中調度器的調度對象很可能是一個容器實例,Docker或者是PouchContainer。為容器選擇合適的宿主機顯然是一個值得考慮的問題,這裏我們說一說調度算法能夠幫助我們實現的價值,這些價值可以從單個容器、到應用、再到數據中心,這三個不同的層面展示出來。
單個容器層面
滿足容器運行的資源需求:確保每個容器在運行的時候擁有足夠的資源,CPU、Memory、Disk、網絡帶寬等等。除了用數量衡量的資源,很多容器在運行的時候還需要一些特殊的資源,例如特定的操作系統版本、特定的硬件等等。
讓容器在更“舒適”的環境下運行:容器之間可能發生資源的搶占現象,例如兩個對Memory消耗很大的容器部署在同一臺機器上,很容易造成Memory資源的吃緊。雖然我們可以通過容器和內核提供的資源隔離技術降低這種影響,但是最好的辦法還是在一開始不讓這種“容易吵架的人做鄰居”。
應用層面
每個應用在提供服務的時候往往是多個容器實例同時支持的,調度器需要考慮應用的需求。
應用的高可用:分布式環境下宿主機失敗或者單個容器的失敗是正常現象,因此我們要保證每個應用同時有多個實例在運行,這樣即使有一個實例掛了,整個應用不會受很大影響。
應用的容災:容災其實也經常和高可用放在一起,如果一個應用有多個應用實例,但是都部署在一個機房,如果機房斷電,那麽應用也就不能提供服務了,沒有高可用了。解決這個問題需要的容災部署,也就不同維度的打散。調度算法需要盡量讓同一個應用的不同實例部署在不同的宿主機、不同的機架、不同的機房、不同的數據中心、不同的城市、甚至是不同的國家;這種容災甚至可以體現在更高一層,幾個重要應用之間的所有實例,也要盡量打散。
很多應用因為其提供服務特性往往需要調度器做更多的事情,例如:按照一定的順序調度實例、將計算任務調度到離數據最近的地方,等等,這裏不一一列舉了。
數據中心層面
降低數據中心的成本:合理的調度能夠節省數據中心大量的成本,如果用裝箱問題來表示,就是用更少的服務器裝下了更多的應用。服務器數目的減少不僅僅是采購成本的下降,服務器的占地、用電、冷卻等都是一筆很大的開銷,合理的資源調度能夠為數據中心節省大量成本。
除了以上這些內容,實際中調度算法要考慮的內容還有很多,例如公平性的問題、應用間的幹擾問題、不同應用間資源共享(互相借用)的問題、單機資源的調配問題(超線程、內存帶框等)等等。例如,實際管理阿裏巴巴集團在線服的資源管理系統Sigma的調度規則,就十分復雜。
為了讓更多的學生、研究者能夠接觸到我們的調度問題,並鼓勵他們與我們一起應對挑戰,我們舉辦了“阿裏巴巴全球調度算法挑戰賽”。這個算法大賽是怎麽回事兒呢?讓我們介紹一下。
首屆阿裏全球調度算法大賽
大家可以想象下,阿裏巴巴擁有如此大規模的數據中心,1%的資源利用率的提升都將為阿裏巴巴自身和整個社會帶來可觀的能源節約讓用戶享受更加綠色的計算資源。所以最近我們發起了首屆阿裏全球調度算法大賽,初賽賽題來自我們生產環境中的一個真實的場景,簡化了一些約束條件,方便一些對這個領域剛剛開始了解的同學找到一個求解的方法,但是即使對於在該領域有一定經驗的同學、工程師、研究者們,我們也相信這份題目能夠讓你花費一些精力才能得到一個優化的解。
在這次算法大賽中,我們提供了大約6K個宿主機,68K個實例(其中一部分已經部署,一部分尚未部署),約束類型主要有3類:資源約束、重要應用高可用約束和應用間反親和約束。
資源約束
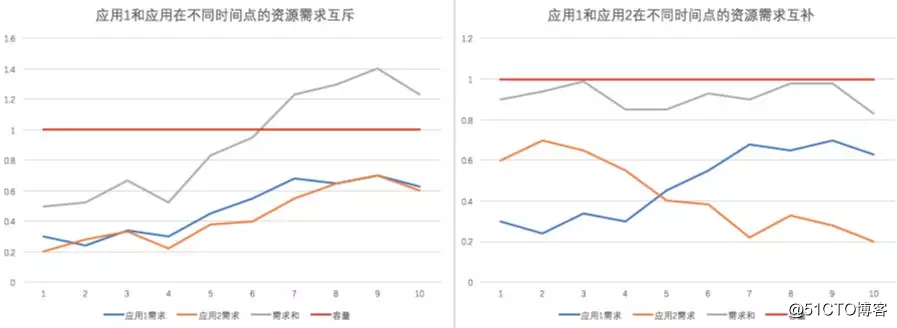
資源約束是最容易理解的,每個屬於不同應用的實例都有不同的計算資源要求。我們本次比賽的一個重要特點是,CPU和Mem的數量約束是以時間曲線的形式給出的。每個應用的對應資源需求的時間曲線是我們通過對該應用下多個實例(一個應用由很多實例組成)的24小時的歷史數據進行觀察並整理得到的需求曲線,描述了每個應用下面的實例在一天當中每個采樣點需要的對應資源的數量。映射的場景是我們假定各個應用的實例的資源需求的有著24小時的變化周期(即98個點的變化周期),第二天、第三天甚至再往後,應用的實例還是按照這個需求長時間存在。註意,這裏提到的應用是長應用(Long Running Service),沒有特殊原因是不會下線的(例如淘寶網),這種長應用與一些分布式計算中的有限持續時間計算任務是不一樣。
這樣的時間曲線比普通的標量規定的資源需求具有更多的優化空間,但也帶來了更多的復雜度。下面這個圖是兩個應用在不同時間點的資源需求對於滿足機器容量的互斥(左)與互補(右)的例子。
重要應用高可用約束
除了CPU、Mem、Disk這樣計算資源的約束,我們還有三類名為P、M、PM的約束,這個約束名字大家可能會覺得有些奇怪,但這是我們通過調度來保障重要應用高可用的重要約束。我們把一些重要應用標記為P類、M類、或者PM類,通過限制每臺機器上可以承載的P、M、PM類型應用實例的上限來保證在機器發生故障的時候(宕機、斷網等),重要應用受到的影響最小。
應用間反親和約束
在上述兩種約束之外,我們提供第三種的約束類型是應用之間的反親和,以<App_1, App_2, k>的形式給出,其語義是:如果一臺機器上已經部署了一個App_1的實例,那麽這臺機器上最多可以部署k個來自App_2的實例。這種約束在實際中的意義是什麽呢?這些約束使我們通過觀測和經驗,確定這兩個應用間可能存在幹擾因素,如果有超過一定數量的兩類應用的實例部署在一起,會影響彼此的性能,因此,在進行調度決策的時候盡量不讓這種互相幹擾的應用的實例出現“紮堆”的現象。
優化的目標
我們的優化目標是在維持每臺機器的資源使用率在一定水平的基礎上(具體數字不透露,你好好看一下題目的描述,相信你可以判斷出來的),盡量減少使用的機器的數目(即實際部署了容器的機器的數目)。為什麽這樣設計呢?較少機器的數目很容易想到是節省成本,而維持機器的資源利用率在一定水平,而不是100%,在實際生產中是很有意義的。因為每個應用都會有一定的、不可準確預計的負載增加,因此,我們需要在每臺機器上流出一定的“余量”來應對每個實例可能突然需要的計算資源。
這些余量的資源在平時也可以為我們所用,但這並在不在我們初賽的考察範圍內。也許復賽中我們會涉及到這些內容。另外,有經驗的朋友可能會發現我們這裏沒有對應用的遷移做出限制,沒錯,我們這樣做的目的是為了降低初賽的難度。實際生產中,應用的遷移,尤其我們這次考慮的在線應用的遷移是一件頗有代價的事情,你能否在設計算法的時候考慮一下應用遷移的代價呢?
我們誠摯的邀請所有對資源調度、運籌優化、資源管理、算法有興趣的同學、學者來參加我們的大賽,獎金豐厚而且有前往美國參加Hackathon的機會!
獨家解密:阿裏是如何應對超大規模集群資源管理挑戰的?