
分布式存儲系統關鍵問題
數據分布
對於存儲系統,最重要的問題就是數據分布,即什麽樣的數據放置在什麽樣的節點上。數據分布時需要考慮數據是否均衡、以後是否容易擴容等一系列問題。不同的數據分布方式也存在不同的優缺點,需要根據自身數據特點進行選擇。
1)哈希分布 => 隨機讀取
取模直接哈希:將不同哈希值的數據分布到不同的服務器上
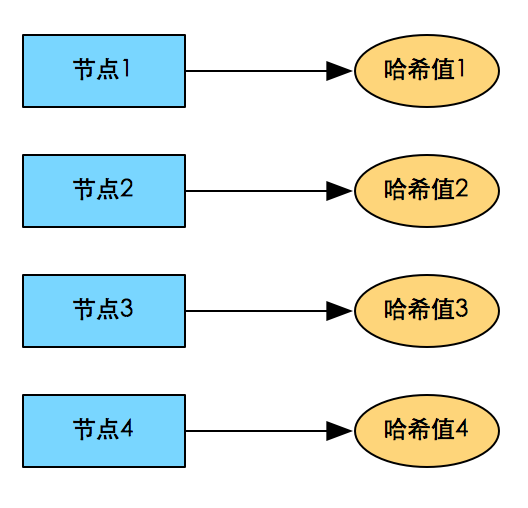
關鍵:找出一個散列特性很好的哈希函數
問題:增加、減少服務器時的大量數據遷移
解決:1)將<哈希值,服務器>元數據存儲在元數據服務器中;2)一致性哈希
一致性哈希: 給系統每個節點分配一個隨機token,這些token構成一個hash環。執行數據存放操作時,先計算key的hash值,然後存放到順時針方向第一個大於或者等於該hash值的token所在節點。
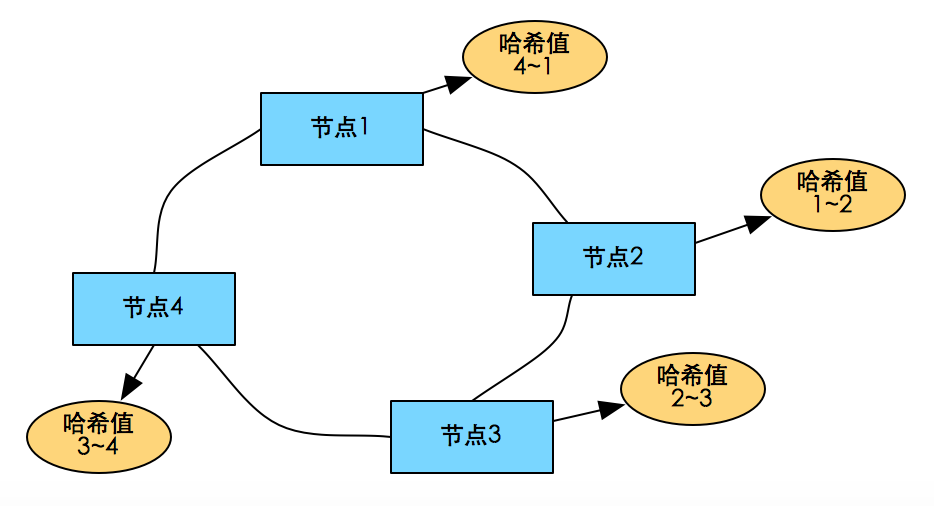
關鍵:哈希值變成了一個範圍,每個物理節點上存儲的數據是哈希值處於前一段範圍的數據。
優點: 節點增加/刪除時只會影響到在hash環中相鄰的節點,而對其他節點沒影響。
維護每臺機器在哈希環中的位置方式:1) 記錄它前一個&後一個節點的位置信息,每次查找可能遍歷整個哈希環所有服務器;2) O(logN)位置信息,查找的時間復雜度為O(logN);3) 每臺服務器維護整個集群中所有服務器的位置信息,查×××器的時間復雜度為O(1)
虛擬節點:將哈希取模的模數取得很大,就會得到更多的哈希值,這個哈希值成為邏輯節點,一個物理機器可以根據自己的能力選擇若幹個邏輯節點的存儲節點。
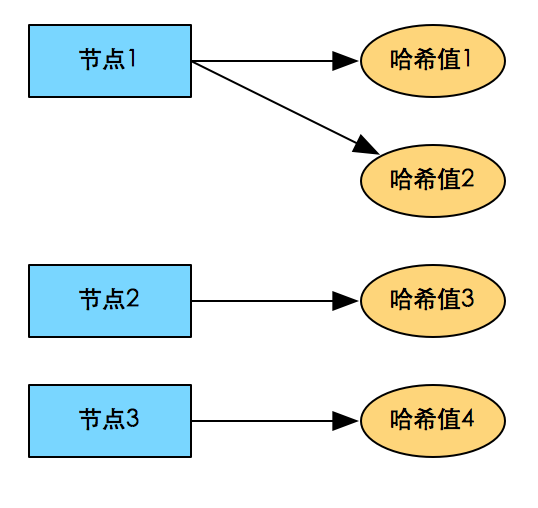
優點:將傳統哈希的一(物理節點)對一(哈希值)的分布變成了一(物理節點)對多(哈希值)的分布。可以根據物理節點的能力調整數據的分布。
2)順序分布 => 順序掃描
表格上的數據按照主鍵整體有序
負載均衡
1)數據寫入時,寫入節點的選擇(空間容量?CPU負載?)
2)運行過程中,數據的遷移
如果運行過程中有新機器的加入,導致每個機器的存儲數據量不同,需要能夠自動發現,並自動進行調整。但是在調整的過程中也要控制好速度,以免對業務產生影響。
復制&多備份
1)最大保護模式
強同步復制:至少在一個備庫上執行成功
至少成功存儲2個備份,才返回成功。
2)最大性能模式
異步復制模式:主庫執行成功即返回
只要成功存儲1個備份,就返回成功。
3)最大可用性模式
兩種模式折衷:正常情況是最大保護模式,出現故障時變成最大性能模式
數據一致性
版本號:在收到寫入數據請求時,生成對應版本號。
刪除老的版本號;讀取時,保證讀取到的是最新的版本號的數據;寫入時,保證寫入數據的版本號要新與存儲的。
容錯
1)故障檢測
心跳:S每隔一段時間向C發送一個心跳包
租約機制:帶有超時時間的授權
2)故障恢復
master:主備機制,持久化索引
datanode:永久故障,增加備份
可擴展性
1)總控節點是否成為瓶頸
不是瓶頸:舍棄小文件的處理,數據的讀寫控制權下放到工作機,通過客戶端緩存元數據減少對總控節點的訪問
內存成為瓶頸:采用兩級結構,在總控機與工作機之間加一層元數據節點
2)同構系統
存儲節點分為若幹組,每個組內的節點服務完全相同的數據
3)異構系統
將數據劃分為大小接近的分片,每個分片的多個副本分布到集群中的任何一個存儲節點,某個節點發生故障,原有的服務將由整個集群而不是某幾個固定的存儲節點來恢復

分布式存儲系統關鍵問題