
聊一聊激活函數
聊一聊激活函數
https://mp.weixin.qq.com/s/Gm4Zp7RuTyZlRWlrbUktDA
Why激活函數?
引入激活函數是為了引入非線性因素,以此解決線性模型所不能解決的問題,讓神經網絡更加powerful!
以下解釋部分可以自行選擇跳過哦~
如果沒有激活函數,那麽神經網絡將會是這樣子

深入了解後我們會神奇的發現,咦?這樣一個神經網絡組合起來,它的輸出居然無論如何都還是一個線性方程哎!

納尼?那也就是說,就算我組合了一萬個神經元,構建了一個看起來相當了不起的神經網絡,其效力還是等同於一個線性方程,其效力等同於輸入的線性組合。
呃,這樣的神經網絡未免也太 powless 了。
這個時候就輪到拯救地球的激活函數上場了。
我們在每一個神經元後面加一個激活函數,如σ-函數,如下圖所示,這樣它就變成非線性的啦~
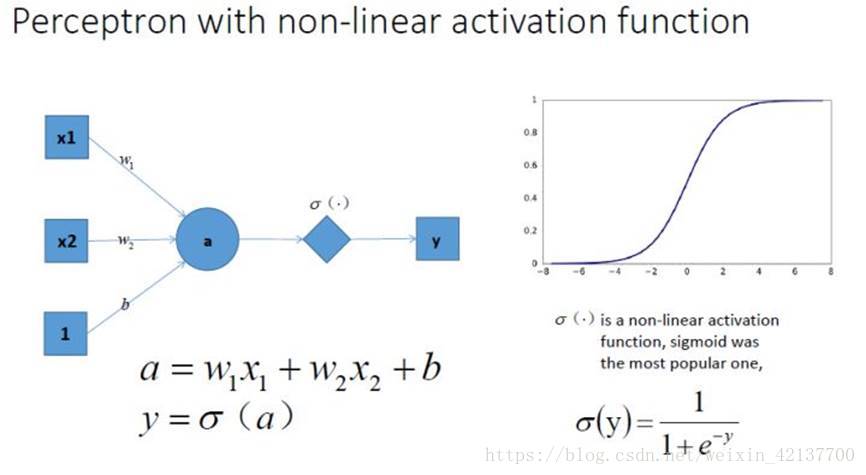
將多個像這樣有激活函數的神經元組合起來,我們就可以得到一個相當復雜的函數,復雜到誰也不知道它是什麽樣的。

引入了非線性激活函數以後, 神經網絡的表達能力更加強大了~
註:一般來說,我們說的激活函數都是非線性激活函數,而不是線性激活函數(或稱為恒等激活函數)g(z) = z
σ-函數
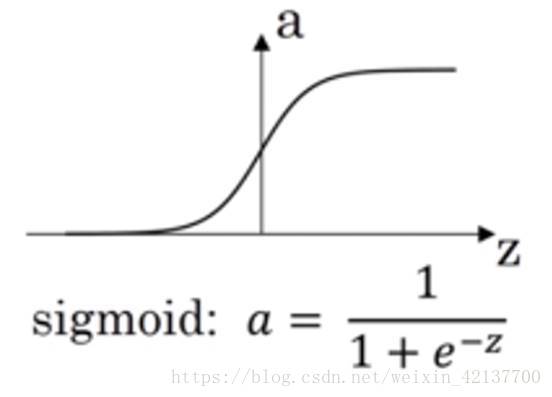
它把輸入映射到0-1區間,一般用在輸出結果為二分類的輸出層。
tanh函數
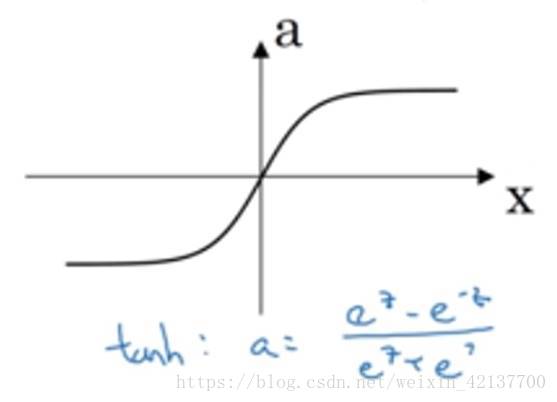

tanh函數它是一個雙曲正切函數,仔細一看,你會發現它其實是σ-函數的平移版。
tanh函數總是比σ-函數來得好。因為它介於-1到1之間,激活函數的平均值接近於0,這就有類似數據中心化的效果
ReLU
ReLU的全稱是Rectified Linear Unit,修正線性單元。它是最受歡迎的一個激活函數,幾乎已經成了隱藏層的默認選項。

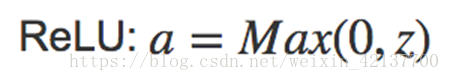
比起σ-函數和tanh函數,ReLU的梯度下降速度快很多。因為它不存在斜率接近於0,學習效率減慢的情況。
Leaky ReLU
ReLU雖好,也存在一個小缺點:當z<0時,導數為0,雖然這在實踐過程中並不會帶來什麽問題。
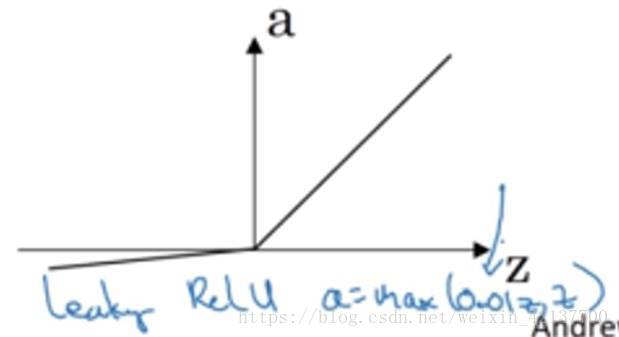
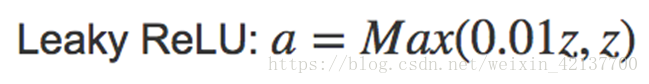
但也催生了另一個版本的ReLU,叫Leaky ReLU。當z<0時,斜率非常平緩,一般表達式為a=max(0.01z, z)。
如何選擇激活函數
1.σ-函數一般用在輸出結果為二分類的輸出層。一般隱藏層選用tanh函數或是ReLU,最常用的是ReLU,具有梯度下降速度快的優點
2.ReLU雖好,但也存在當z為負時,導數為0的小缺點,雖然這在實踐過程中並不會帶來什麽問題,但也可以用Leaky ReLU達到更好的效果,雖然目前Leaky ReLU還是比較少用。
3.凡事無絕對,具體選用什麽激活函數還需看情況而定。
參考:
知乎 - 神經網絡激勵函數的作用是什麽?有沒有形象的解釋?
吳恩達 - 神經網絡和深度學習 - 激活函數
聊一聊激活函數