
ML面試1000題系列(1-20)
本文總結ML面試常見的問題集
轉載來源:https://blog.csdn.net/v_july_v/article/details/78121924
1、簡要介紹SVM
全稱是support vector machine,中文名叫支持向量機。SVM是一個面向數據的分類算法,它的目標是為確定一個分類超平面,從而將不同的數據分隔開。
2、簡要介紹tensorflow的計算圖
Tensorflow是一個通過計算圖的形式來表述計算的編程系統,計算圖也叫數據流圖,可以把計算圖看做是一種有向圖,Tensorflow中的每一個節點都是計算圖上的一個Tensor, 也就是張量,而節點之間的邊描述了計算之間的依賴關系(定義時)和數學操作(運算時)。
3、在k-means或kNN,我們常用歐氏距離來計算最近的鄰居之間的距離,有時也用曼哈頓距離,請對比下這兩種距離的差別。
- 歐氏距離,最常見的兩點之間或多點之間的距離表示法,又稱之為歐幾裏得度量,它定義於歐幾裏得空間中,如點 x = (x1,...,xn) 和 y = (y1,...,yn) 之間的距離為:

歐氏距離雖然很有用,但也有明顯的缺點。它將樣品的不同屬性(即各指標或各變量量綱) 之間的差別等同看待,這一點有時不能滿足實際要求。例如,在教育研究中,經常遇到對人 的分析和判別,個體的不同屬性對於區分個體有著不同的重要性。因此,歐氏距離適用於向量各分量的度量標準統一的情況。
- 曼哈頓距離,我們可以定義曼哈頓距離的正式意義為L1距離或城市區塊距離,也就是在歐幾裏得空間的固定直角坐標系上兩點所形成的線段對軸產生的投影的距離總和。例如在平面上,坐標(x1, y1)的點P1與坐標(x2, y2)的點P2的曼哈頓距離為:
 ,要註意的是,曼哈頓距離依賴坐標系統的轉度,而非系統在座標軸上的平移或映射。當坐標軸變動時,點間的距離就會不同。
,要註意的是,曼哈頓距離依賴坐標系統的轉度,而非系統在座標軸上的平移或映射。當坐標軸變動時,點間的距離就會不同。
描述網絡模型中某層的厚度,通常用名詞通道channel數或者特征圖feature map數。不過人們更習慣把作為數據輸入的前層的厚度稱之為通道數(比如RGB三色圖層稱為輸入通道數為3),把作為卷積輸出的後層的厚度稱之為特征圖數。
卷積核(filter)一般是3D多層的,除了面積參數, 比如3x3之外, 還有厚度參數H(2D的視為厚度1). 還有一個屬性是卷積核的個數N。
卷積核的厚度H, 一般等於前層厚度M(輸入通道數或feature map數). 特殊情況M > H。
卷積核的個數N, 一般等於後層厚度(後層feature maps數,因為相等所以也用N表示)。
卷積核通常從屬於後層,為後層提供了各種查看前層特征的視角,這個視角是自動形成的。
卷積核厚度等於1時為2D卷積,也就是平面對應點分別相乘然後把結果加起來,相當於點積運算. 各種2D卷積動圖可以看這裏https://github.com/vdumoulin/conv_arithmetic

卷積核厚度大於1時為3D卷積(depth-wise),每片平面分別求2D卷積,然後把每片卷積結果加起來,作為3D卷積結果;1x1卷積屬於3D卷積的一個特例(point-wise),有厚度無面積, 直接把每層單個點相乘再相加。 卷積的意思就是把一個區域,不管是一維線段,二維方陣,還是三維長方塊,全部按照卷積核的維度形狀,從輸入挖出同樣維度形狀, 對應逐點相乘後求和,濃縮成一個標量值也就是降到零維度,作為輸出到一個特征圖的一個點的值. 5、關於邏輯回歸LR 把LR從頭到腳都給講一遍。建模,現場數學推導,每種解法的原理,正則化,LR和maxent模型啥關系,lr為啥比線性回歸好。有不少會背答案的人,問邏輯細節就糊塗了。原理都會? 那就問工程,並行化怎麽做,有幾種並行化方式,讀過哪些開源的實現。還會,那就準備收了吧,順便逼問LR模型發展歷史。 補充 6、overfitting怎麽解決? dropout、regularization、batch normalizatin @AntZ: overfitting就是過擬合, 其直觀的表現如下圖所示,隨著訓練過程的進行,模型復雜度增加,在training data上的error漸漸減小,但是在驗證集上的error卻反而漸漸增大——因為訓練出來的網絡過擬合了訓練集, 對訓練集外的數據卻不work, 這稱之為泛化(generalization)性能不好。泛化性能是訓練的效果評價中的首要目標,沒有良好的泛化,就等於南轅北轍, 一切都是無用功。

過擬合是泛化的反面,好比鄉下快活的劉姥姥進了大觀園會各種不適應,但受過良好教育的林黛玉進賈府就不會大驚小怪。實際訓練中, 降低過擬合的辦法一般如下:
正則化(Regularization)
L2正則化:目標函數中增加所有權重w參數的平方之和, 逼迫所有w盡可能趨向零但不為零. 因為過擬合的時候, 擬合函數需要顧忌每一個點, 最終形成的擬合函數波動很大, 在某些很小的區間裏, 函數值的變化很劇烈, 也就是某些w非常大. 為此, L2正則化的加入就懲罰了權重變大的趨勢.
L1正則化:目標函數中增加所有權重w參數的絕對值之和, 逼迫更多w為零(也就是變稀疏. L2因為其導數也趨0, 奔向零的速度不如L1給力了). 大家對稀疏規則化趨之若鶩的一個關鍵原因在於它能實現特征的自動選擇。一般來說,xi的大部分元素(也就是特征)都是和最終的輸出yi沒有關系或者不提供任何信息的,在最小化目標函數的時候考慮xi這些額外的特征,雖然可以獲得更小的訓練誤差,但在預測新的樣本時,這些沒用的特征權重反而會被考慮,從而幹擾了對正確yi的預測。稀疏規則化算子的引入就是為了完成特征自動選擇的光榮使命,它會學習地去掉這些無用的特征,也就是把這些特征對應的權重置為0。
隨機失活(dropout)
在訓練的運行的時候,讓神經元以超參數p的概率被激活(也就是1-p的概率被設置為0), 每個w因此隨機參與, 使得任意w都不是不可或缺的, 效果類似於數量巨大的模型集成。
逐層歸一化(batch normalization)
這個方法給每層的輸出都做一次歸一化(網絡上相當於加了一個線性變換層), 使得下一層的輸入接近高斯分布. 這個方法相當於下一層的w訓練時避免了其輸入以偏概全, 因而泛化效果非常好.
提前終止(early stopping)
理論上可能的局部極小值數量隨參數的數量呈指數增長, 到達某個精確的最小值是不良泛化的一個來源. 實踐表明, 追求細粒度極小值具有較高的泛化誤差。這是直觀的,因為我們通常會希望我們的誤差函數是平滑的, 精確的最小值處所見相應誤差曲面具有高度不規則性, 而我們的泛化要求減少精確度去獲得平滑最小值, 所以很多訓練方法都提出了提前終止策略. 典型的方法是根據交叉叉驗證提前終止: 若每次訓練前, 將訓練數據劃分為若幹份, 取一份為測試集, 其他為訓練集, 每次訓練完立即拿此次選中的測試集自測. 因為每份都有一次機會當測試集, 所以此方法稱之為交叉驗證. 交叉驗證的錯誤率最小時可以認為泛化性能最好, 這時候訓練錯誤率雖然還在繼續下降, 但也得終止繼續訓練了. 7、LR和SVM的聯系與區別。 1、LR和SVM都可以處理分類問題,且一般都用於處理線性二分類問題(在改進的情況下可以處理多分類問題)
2、兩個方法都可以增加不同的正則化項,如l1、l2等等。所以在很多實驗中,兩種算法的結果是很接近的。
區別:
1、LR是參數模型,SVM是非參數模型。
2、從損失函數來看,區別在於邏輯回歸采用的是logistical loss,SVM采用的是hinge loss,這兩個損失函數的目的都是增加對分類影響較大的數據點的權重,減少與分類關系較小的數據點的權重。
3、SVM的處理方法是只考慮support vectors,也就是和分類最相關的少數點,去學習分類器。而邏輯回歸通過非線性映射,大大減小了離分類平面較遠的點的權重,相對提升了與分類最相關的數據點的權重。
4、邏輯回歸相對來說模型更簡單,好理解,特別是大規模線性分類時比較方便。而SVM的理解和優化相對來說復雜一些,SVM轉化為對偶問題後,分類只需要計算與少數幾個支持向量的距離,這個在進行復雜核函數計算時優勢很明顯,能夠大大簡化模型和計算。
5、logic 能做的 svm能做,但可能在準確率上有問題,svm能做的logic有的做不了。
來源:http://blog.csdn.net/timcompp/article/details/62237986 8、說說你知道的核函數。
通常人們會從一些常用的核函數中選擇(根據問題和數據的不同,選擇不同的參數,實際上就是得到了不同的核函數),例如:
- 多項式核,顯然剛才我們舉的例子是這裏多項式核的一個特例(R = 1,d = 2)。雖然比較麻煩,而且沒有必要,不過這個核所對應的映射實際上是可以寫出來的,該空間的維度是
 ,其中 是原始空間的維度。
,其中 是原始空間的維度。 - 高斯核
 ,這個核就是最開始提到過的會將原始空間映射為無窮維空間的那個家夥。不過,如果
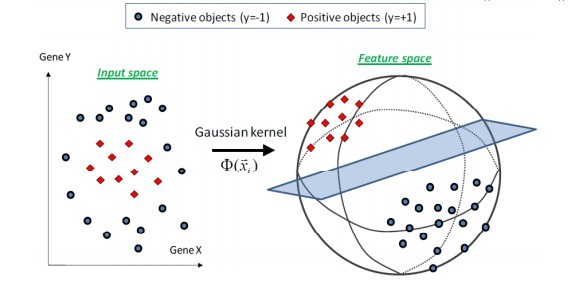
,這個核就是最開始提到過的會將原始空間映射為無窮維空間的那個家夥。不過,如果 選得很大的話,高次特征上的權重實際上衰減得非常快,所以實際上(數值上近似一下)相當於一個低維的子空間;反過來,如果選得很小,則可以將任意的數據映射為線性可分——當然,這並不一定是好事,因為隨之而來的可能是非常嚴重的過擬合問題。不過,總的來說,通過調控參數,高斯核實際上具有相當高的靈活性,也是使用最廣泛的核函數之一。下圖所示的例子便是把低維線性不可分的數據通過高斯核函數映射到了高維空間:
選得很大的話,高次特征上的權重實際上衰減得非常快,所以實際上(數值上近似一下)相當於一個低維的子空間;反過來,如果選得很小,則可以將任意的數據映射為線性可分——當然,這並不一定是好事,因為隨之而來的可能是非常嚴重的過擬合問題。不過,總的來說,通過調控參數,高斯核實際上具有相當高的靈活性,也是使用最廣泛的核函數之一。下圖所示的例子便是把低維線性不可分的數據通過高斯核函數映射到了高維空間: - 線性核
 ,這實際上就是原始空間中的內積。這個核存在的主要目的是使得“映射後空間中的問題”和“映射前空間中的問題”兩者在形式上統一起來了(意思是說,咱們有的時候,寫代碼,或寫公式的時候,只要寫個模板或通用表達式,然後再代入不同的核,便可以了,於此,便在形式上統一了起來,不用再分別寫一個線性的,和一個非線性的)。
,這實際上就是原始空間中的內積。這個核存在的主要目的是使得“映射後空間中的問題”和“映射前空間中的問題”兩者在形式上統一起來了(意思是說,咱們有的時候,寫代碼,或寫公式的時候,只要寫個模板或通用表達式,然後再代入不同的核,便可以了,於此,便在形式上統一了起來,不用再分別寫一個線性的,和一個非線性的)。
@nishizhen:個人感覺邏輯回歸和線性回歸首先都是廣義的線性回歸,
其次經典線性模型的優化目標函數是最小二乘,而邏輯回歸則是似然函數,
另外線性回歸在整個實數域範圍內進行預測,敏感度一致,而分類範圍,需要在[0,1]。邏輯回歸就是一種減小預測範圍,將預測值限定為[0,1]間的一種回歸模型,因而對於這類問題來說,邏輯回歸的魯棒性比線性回歸的要好。
@乖乖癩皮狗:邏輯回歸的模型本質上是一個線性回歸模型,邏輯回歸都是以線性回歸為理論支持的。但線性回歸模型無法做到sigmoid的非線性形式,sigmoid可以輕松處理0/1分類問題。 10、請問決策樹、隨機森林、Booting、Adaboot、GBDT、XGBoost的區別是什麽? @AntZ
集成學習的集成對象是學習器. Bagging和Boosting屬於集成學習的兩類方法. Bagging方法有放回地采樣同數量樣本訓練每個學習器, 然後再一起集成(簡單投票); Boosting方法使用全部樣本(可調權重)依次訓練每個學習器, 叠代集成(平滑加權).
決策樹屬於最常用的學習器, 其學習過程是從根建立樹, 也就是如何決策葉子節點分裂. ID3/C4.5決策樹用信息熵計算最優分裂, CART決策樹用基尼指數計算最優分裂, xgboost決策樹使用二階泰勒展開系數計算最優分裂.
下面所提到的學習器都是決策樹:
Bagging方法:
學習器間不存在強依賴關系, 學習器可並行訓練生成, 集成方式一般為投票;
Random Forest屬於Bagging的代表, 放回抽樣, 每個學習器隨機選擇部分特征去優化;
Boosting方法:
學習器之間存在強依賴關系、必須串行生成, 集成方式為加權和;
Adaboost屬於Boosting, 采用指數損失函數替代原本分類任務的0/1損失函數;
GBDT屬於Boosting的優秀代表, 對函數殘差近似值進行梯度下降, 用CART回歸樹做學習器, 集成為回歸模型;
xgboost屬於Boosting的集大成者, 對函數殘差近似值進行梯度下降, 叠代時利用了二階梯度信息, 集成模型可分類也可回歸. 由於它可在特征粒度上並行計算, 結構風險和工程實現都做了很多優化, 泛化, 性能和擴展性都比GBDT要好。
關於決策樹,這裏有篇《決策樹算法》。而隨機森林Random Forest是一個包含多個決策樹的分類器。至於AdaBoost,則是英文"Adaptive Boosting"(自適應增強)的縮寫,關於AdaBoost可以看下這篇文章《Adaboost 算法的原理與推導》。GBDT(Gradient Boosting Decision Tree),即梯度上升決策樹算法,相當於融合決策樹和梯度上升boosting算法。
@Xijun LI:xgboost類似於gbdt的優化版,不論是精度還是效率上都有了提升。與gbdt相比,具體的優點有:
1.損失函數是用泰勒展式二項逼近,而不是像gbdt裏的就是一階導數
2.對樹的結構進行了正則化約束,防止模型過度復雜,降低了過擬合的可能性
3.節點分裂的方式不同,gbdt是用的gini系數,xgboost是經過優化推導後的
更多詳見:https://xijunlee.github.io/2017/06/03/%E9%9B%86%E6%88%90%E5%AD%A6%E4%B9%A0%E6%80%BB%E7%BB%93/ 11、 為什麽xgboost要用泰勒展開,優勢在哪裏? @AntZ:xgboost使用了一階和二階偏導, 二階導數有利於梯度下降的更快更準. 使用泰勒展開取得函數做自變量的二階導數形式, 可以在不選定損失函數具體形式的情況下, 僅僅依靠輸入數據的值就可以進行葉子分裂優化計算, 本質上也就把損失函數的選取和模型算法優化/參數選擇分開了. 這種去耦合增加了xgboost的適用性, 使得它按需選取損失函數, 可以用於分類, 也可以用於回歸。 12、xgboost如何尋找最優特征?是又放回還是無放回的呢? @AntZ:xgboost在訓練的過程中給出各個特征的增益評分,最大增益的特征會被選出來作為分裂依據, 從而記憶了每個特征對在模型訓練時的重要性 -- 從根到葉子中間節點涉及某特征的次數作為該特征重要性排序.
xgboost屬於boosting集成學習方法, 樣本是不放回的, 因而每輪計算樣本不重復. 另一方面, xgboost支持子采樣, 也就是每輪計算可以不使用全部樣本, 以減少過擬合. 進一步地, xgboost 還有列采樣, 每輪計算按百分比隨機采樣一部分特征, 既提高計算速度又減少過擬合。 13 、談談判別式模型和生成式模型? 判別方法:由數據直接學習決策函數 Y = f(X),或者由條件分布概率 P(Y|X)作為預測模型,即判別模型。
生成方法:由數據學習聯合概率密度分布函數 P(X,Y),然後求出條件概率分布P(Y|X)作為預測的模型,即生成模型。
由生成模型可以得到判別模型,但由判別模型得不到生成模型。
常見的判別模型有:K近鄰、SVM、決策樹、感知機、線性判別分析(LDA)、線性回歸、傳統的神經網絡、邏輯斯蒂回歸、boosting、條件隨機場
常見的生成模型有:樸素貝葉斯、隱馬爾可夫模型、高斯混合模型、文檔主題生成模型(LDA)、限制玻爾茲曼機 14、L1和L2的區別。
L1範數(L1 norm)是指向量中各個元素絕對值之和,也有個美稱叫“稀疏規則算子”(Lasso regularization)。
比如 向量A=[1,-1,3], 那麽A的L1範數為 |1|+|-1|+|3|.
簡單總結一下就是:
L1範數: 為x向量各個元素絕對值之和。
L2範數: 為x向量各個元素平方和的1/2次方,L2範數又稱Euclidean範數或者Frobenius範數
Lp範數: 為x向量各個元素絕對值p次方和的1/p次方.
在支持向量機學習過程中,L1範數實際是一種對於成本函數求解最優的過程,因此,L1範數正則化通過向成本函數中添加L1範數,使得學習得到的結果滿足稀疏化,從而方便人類提取特征。
L1範數可以使權值稀疏,方便特征提取。
L2範數可以防止過擬合,提升模型的泛化能力。
@AntZ: L1和L2的差別,為什麽一個讓絕對值最小,一個讓平方最小,會有那麽大的差別呢?看導數一個是1一個是w便知, 在靠進零附近, L1以勻速下降到零, 而L2則完全停下來了. 這說明L1是將不重要的特征(或者說, 重要性不在一個數量級上)盡快剔除, L2則是把特征貢獻盡量壓縮最小但不至於為零. 兩者一起作用, 就是把重要性在一個數量級(重要性最高的)的那些特征一起平等共事(簡言之, 不養閑人也不要超人)。 15、L1和L2正則先驗分別服從什麽分布。 @齊同學:面試中遇到的,L1和L2正則先驗分別服從什麽分布,L1是拉普拉斯分布,L2是高斯分布。
@AntZ: 先驗就是優化的起跑線, 有先驗的好處就是可以在較小的數據集中有良好的泛化性能,當然這是在先驗分布是接近真實分布的情況下得到的了,從信息論的角度看,向系統加入了正確先驗這個信息,肯定會提高系統的性能。
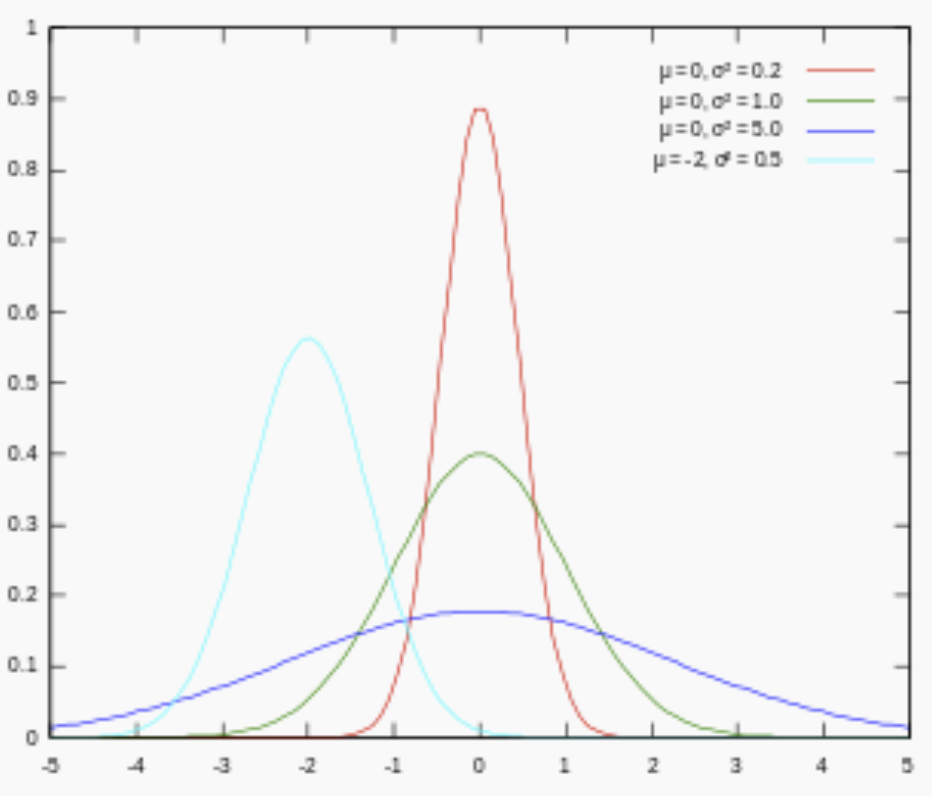
對參數引入高斯正態先驗分布相當於L2正則化, 這個大家都熟悉:
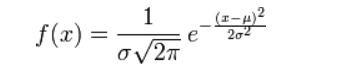
對參數引入拉普拉斯先驗等價於 L1正則化, 如下圖:
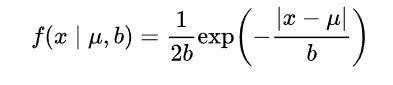
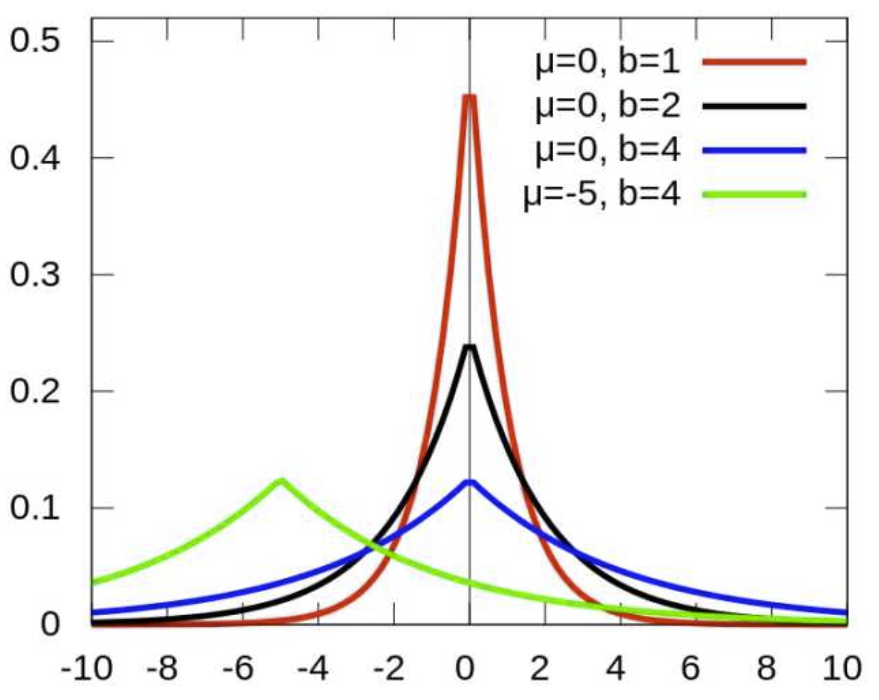
從上面兩圖可以看出, L2先驗趨向零周圍, L1先驗趨向零本身。 16、CNN最成功的應用是在CV,那為什麽NLP和Speech的很多問題也可以用CNN解出來?為什麽AlphaGo裏也用了CNN?這幾個不相關的問題的相似性在哪裏?CNN通過什麽手段抓住了這個共性? @許韓,來源:https://zhuanlan.zhihu.com/p/25005808
Deep Learning -Yann LeCun, Yoshua Bengio & Geoffrey Hinton
Learn TensorFlow and deep learning, without a Ph.D.
The Unreasonable Effectiveness of Deep Learning -LeCun 16 NIPS Keynote
以上幾個不相關問題的相關性在於,都存在局部與整體的關系,由低層次的特征經過組合,組成高層次的特征,並且得到不同特征之間的空間相關性。如下圖:低層次的直線/曲線等特征,組合成為不同的形狀,最後得到汽車的表示。

CNN抓住此共性的手段主要有四個:局部連接/權值共享/池化操作/多層次結構。
局部連接使網絡可以提取數據的局部特征;權值共享大大降低了網絡的訓練難度,一個Filter只提取一個特征,在整個圖片(或者語音/文本) 中進行卷積;池化操作與多層次結構一起,實現了數據的降維,將低層次的局部特征組合成為較高層次的特征,從而對整個圖片進行表示。如下圖:
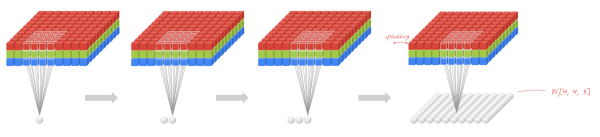
上圖中,如果每一個點的處理使用相同的Filter,則為全卷積,如果使用不同的Filter,則為Local-Conv。
另,關於CNN,這裏有篇文章《 CNN筆記:通俗理解卷積神經網絡》。 17、說一下Adaboost,權值更新公式。當弱分類器是Gm時,每個樣本的的權重是w1,w2...,請寫出最終的決策公式。
給定一個訓練數據集T={(x1,y1), (x2,y2)…(xN,yN)},其中實例 ,而實例空間
,而實例空間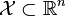 ,yi屬於標記集合{-1,+1},Adaboost的目的就是從訓練數據中學習一系列弱分類器或基本分類器,然後將這些弱分類器組合成一個強分類器。
,yi屬於標記集合{-1,+1},Adaboost的目的就是從訓練數據中學習一系列弱分類器或基本分類器,然後將這些弱分類器組合成一個強分類器。
Adaboost的算法流程如下:
- 步驟1. 首先,初始化訓練數據的權值分布。每一個訓練樣本最開始時都被賦予相同的權值:1/N。
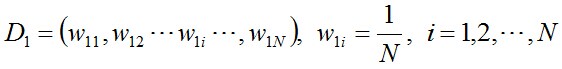
- 步驟2. 進行多輪叠代,用m = 1,2, ..., M表示叠代的第多少輪
a. 使用具有權值分布Dm的訓練數據集學習,得到基本分類器(選取讓誤差率最低的閾值來設計基本分類器):
b. 計算Gm(x)在訓練數據集上的分類誤差率
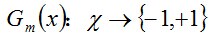
c. 計算Gm(x)的系數,am表示Gm(x)在最終分類器中的重要程度(目的:得到基本分類器在最終分類器中所占的權重):由上述式子可知,Gm(x)在訓練數據集上的誤差率em就是被Gm(x)誤分類樣本的權值之和。
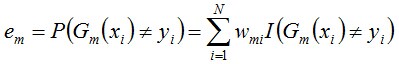
d. 更新訓練數據集的權值分布(目的:得到樣本的新的權值分布),用於下一輪叠代由上述式子可知,em <= 1/2時,am >= 0,且am隨著em的減小而增大,意味著分類誤差率越小的基本分類器在最終分類器中的作用越大。
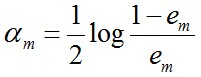
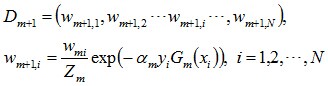
使得被基本分類器Gm(x)誤分類樣本的權值增大,而被正確分類樣本的權值減小。就這樣,通過這樣的方式,AdaBoost方法能“重點關註”或“聚焦於”那些較難分的樣本上。
其中,Zm是規範化因子,使得Dm+1成為一個概率分布:
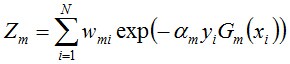
- 步驟3. 組合各個弱分類器
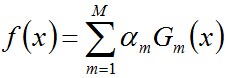
從而得到最終分類器,如下:
18、LSTM結構推導,為什麽比RNN好? 19、為什麽樸素貝葉斯如此“樸素”? 因為它假定所有的特征在數據集中的作用是同樣重要和獨立的。正如我們所知,這個假設在現實世界中是很不真實的,因此,說樸素貝葉斯真的很“樸素”。
更多請查看此文:《Adaboost 算法的原理與推導》。
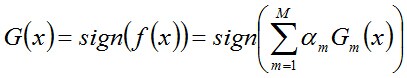
@AntZ: 樸素貝葉斯模型(Naive Bayesian Model)的樸素(Naive)的含義是"很簡單很天真"地假設樣本特征彼此獨立. 這個假設現實中基本上不存在, 但特征相關性很小的實際情況還是很多的, 所以這個模型仍然能夠工作得很好。 20、請大致對比下plsa和LDA的區別。
ML面試1000題系列(1-20)