
BAT機器學習面試1000題系列 第1 305題
@齊同學:面試中遇到的,L1和L2正則先驗分別服從什麼分佈,L1是拉普拉斯分佈,L2是高斯分佈。
@AntZ: 先驗就是優化的起跑線, 有先驗的好處就是可以在較小的資料集中有良好的泛化效能,當然這是在先驗分佈是接近真實分佈的情況下得到的了,從資訊理論的角度看,向系統加入了正確先驗這個資訊,肯定會提高系統的效能。
對引數引入高斯正態先驗分佈相當於L2正則化, 這個大家都熟悉:
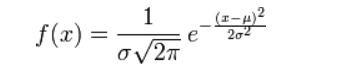
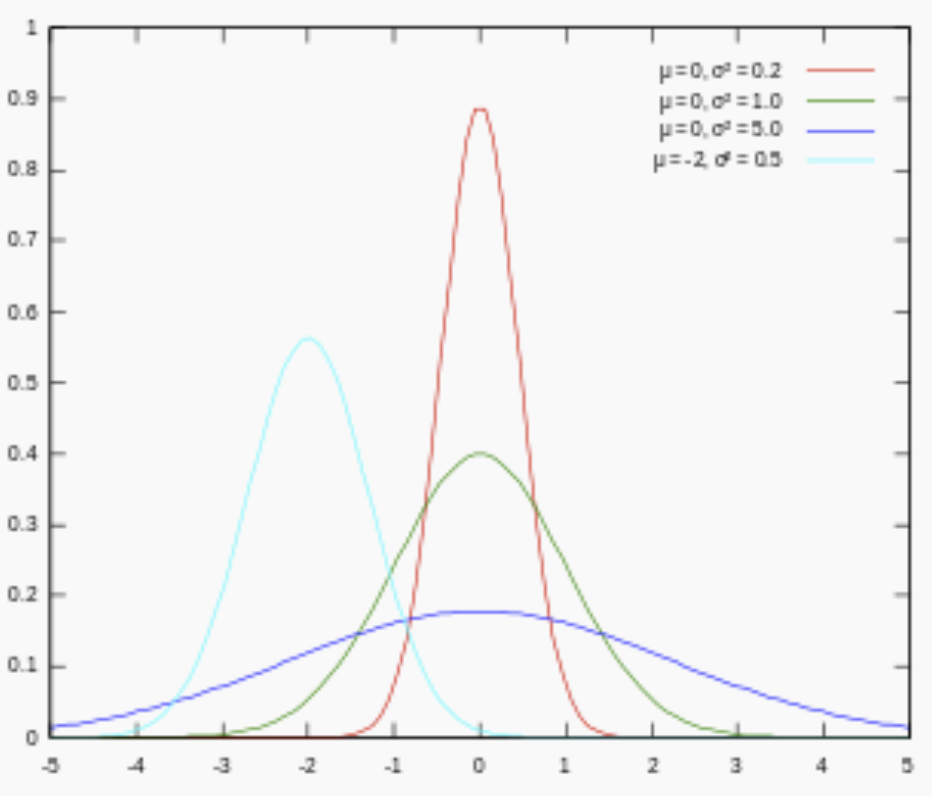
對引數引入拉普拉斯先驗等價於 L1正則化, 如下圖:
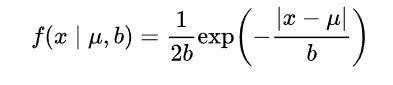
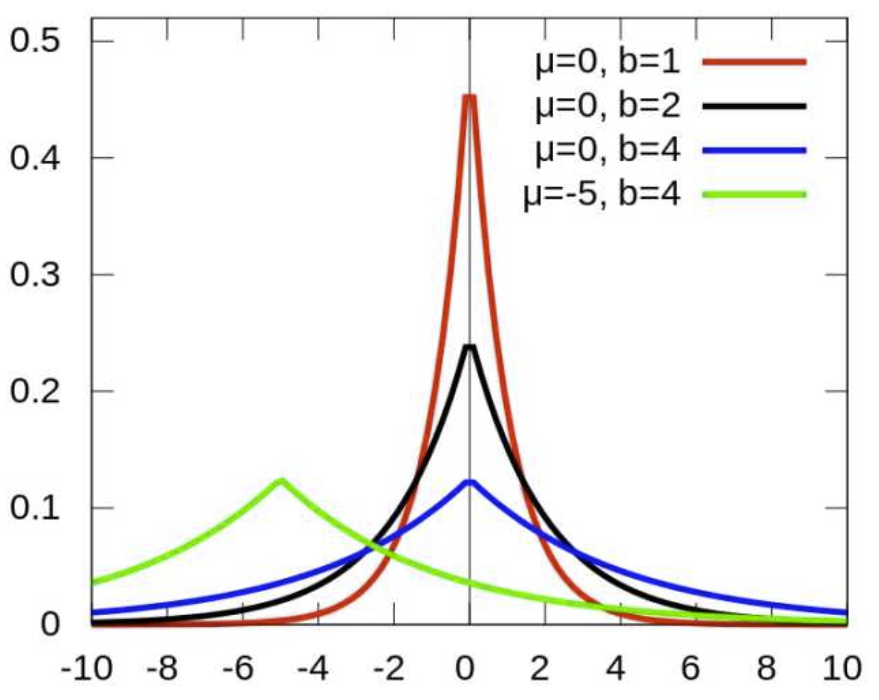
從上面兩圖可以看出, L2先驗趨向零周圍, L1先驗趨向零本身。
15 CNN最成功的應用是在CV,那為什麼NLP和Speech的很多問題也可以用CNN解出來?為什麼AlphaGo裡也用了CNN?這幾個不相關的問題的相似性在哪裡?CNN通過什麼手段抓住了這個共性?深度學習 DL應用 難
@許韓,來源:https://zhuanlan.zhihu.com/p/25005808
Deep Learning -Yann LeCun, Yoshua Bengio & Geoffrey Hinton
Learn TensorFlow and deep learning, without a Ph.D.
The Unreasonable Effectiveness of Deep Learning -LeCun 16 NIPS Keynote
以上幾個不相關問題的相關性在於,都存在區域性與整體的關係,由低層次的特徵經過組合,組成高層次的特徵,並且得到不同特徵之間的空間相關性。如下圖:低層次的直線/曲線等特徵,組合成為不同的形狀,最後得到汽車的表示。

CNN抓住此共性的手段主要有四個:區域性連線/權值共享/池化操作/多層次結構。
區域性連線使網路可以提取資料的區域性特徵;權值共享大大降低了網路的訓練難度,一個Filter只提取一個特徵,在整個圖片(或者語音/文字) 中進行卷積;池化操作與多層次結構一起,實現了資料的降維,將低層次的區域性特徵組合成為較高層次的特徵,從而對整個圖片進行表示。如下圖:
上圖中,如果每一個點的處理使用相同的Filter,則為全卷積,如果使用不同的Filter,則為Local-Conv。
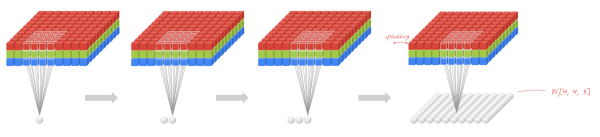
另,關於CNN,這裡有篇文章《 CNN筆記:通俗理解卷積神經網路》。16 說一下Adaboost,權值更新公式。當弱分類器是Gm時,每個樣本的的權重是w1,w2...,請寫出最終的決策公式。機器學習 ML模型 難
給定一個訓練資料集T={(x1,y1), (x2,y2)…(xN,yN)},其中例項 ,而例項空間
,而例項空間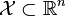 ,yi屬於標記集合{-1,+1},Adaboost的目的就是從訓練資料中學習一系列弱分類器或基本分類器,然後將這些弱分類器組合成一個強分類器。
,yi屬於標記集合{-1,+1},Adaboost的目的就是從訓練資料中學習一系列弱分類器或基本分類器,然後將這些弱分類器組合成一個強分類器。
Adaboost的演算法流程如下:
- 步驟1. 首先,初始化訓練資料的權值分佈。每一個訓練樣本最開始時都被賦予相同的權值:1/N。
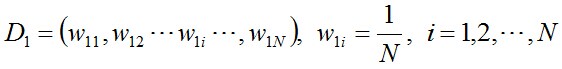
- 步驟2. 進行多輪迭代,用m = 1,2, ..., M表示迭代的第多少輪
a. 使用具有權值分佈Dm的訓練資料集學習,得到基本分類器(選取讓誤差率最低的閾值來設計基本分類器):
b. 計算Gm(x)在訓練資料集上的分類誤差率
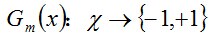
c. 計算Gm(x)的係數,am表示Gm(x)在最終分類器中的重要程度(目的:得到基本分類器在最終分類器中所佔的權重):由上述式子可知,Gm(x)在訓練資料集上的誤差率em就是被Gm(x)誤分類樣本的權值之和。
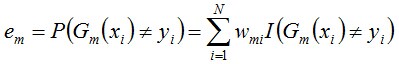
d. 更新訓練資料集的權值分佈(目的:得到樣本的新的權值分佈),用於下一輪迭代由上述式子可知,em <= 1/2時,am >= 0,且am隨著em的減小而增大,意味著分類誤差率越小的基本分類器在最終分類器中的作用越大。
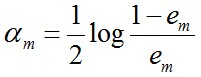
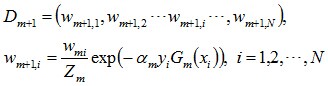
使得被基本分類器Gm(x)誤分類樣本的權值增大,而被正確分類樣本的權值減小。就這樣,通過這樣的方式,AdaBoost方法能“重點關注”或“聚焦於”那些較難分的樣本上。
其中,Zm是規範化因子,使得Dm+1成為一個概率分佈:
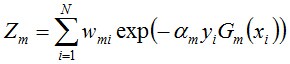
- 步驟3. 組合各個弱分類器
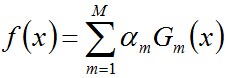
從而得到最終分類器,如下:
17 LSTM結構推導,為什麼比RNN好?深度學習 DL模型 難
推導forget gate,input gate,cell state, hidden information等的變化;因為LSTM有進有出且當前的cell informaton是通過input gate控制之後疊加的,RNN是疊乘,因此LSTM可以防止梯度消失或者爆炸
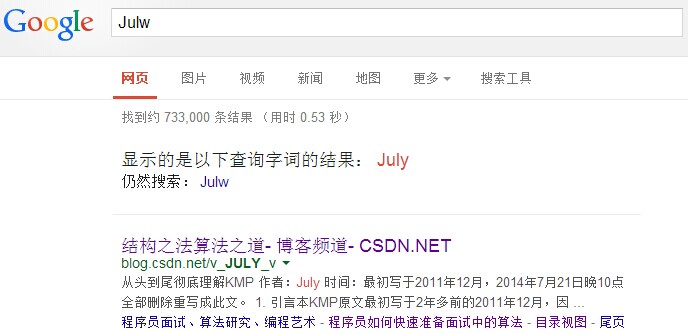
經常在網上搜索東西的朋友知道,當你不小心輸入一個不存在的單詞時,搜尋引擎會提示你是不是要輸入某一個正確的單詞,比如當你在Google中輸入“Julw”時,系統會猜測你的意圖:是不是要搜尋“July”,如下圖所示:
這叫做拼寫檢查。根據谷歌一員工寫的文章顯示,Google的拼寫檢查基於貝葉斯方法。請說說的你的理解,具體Google是怎麼利用貝葉斯方法,實現"拼寫檢查"的功能。機器學習 ML應用 難
使用者輸入一個單詞時,可能拼寫正確,也可能拼寫錯誤。如果把拼寫正確的情況記做c(代表correct),拼寫錯誤的情況記做w(代表wrong),那麼"拼寫檢查"要做的事情就是:在發生w的情況下,試圖推斷出c。換言之:已知w,然後在若干個備選方案中,找出可能性最大的那個c,也就是求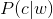
而根據貝葉斯定理,有:
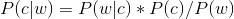
由於對於所有備選的c來說,對應的都是同一個w,所以它們的P(w)是相同的,因此我們只要最大化
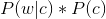
即可。其中:
- P(c)表示某個正確的詞的出現"概率",它可以用"頻率"代替。如果我們有一個足夠大的文字庫,那麼這個文字庫中每個單詞的出現頻率,就相當於它的發生概率。某個詞的出現頻率越高,P(c)就越大。比如在你輸入一個錯誤的詞“Julw”時,系統更傾向於去猜測你可能想輸入的詞是“July”,而不是“Jult”,因為“July”更常見。
- P(w|c)表示在試圖拼寫c的情況下,出現拼寫錯誤w的概率。為了簡化問題,假定兩個單詞在字形上越接近,就有越可能拼錯,P(w|c)就越大。舉例來說,相差一個字母的拼法,就比相差兩個字母的拼法,發生概率更高。你想拼寫單詞July,那麼錯誤拼成Julw(相差一個字母)的可能性,就比拼成Jullw高(相差兩個字母)。值得一提的是,一般把這種問題稱為“編輯距離”,參見部落格中的這篇文章。
18 為什麼樸素貝葉斯如此“樸素”?機器學習 ML模型 易
因為它假定所有的特徵在資料集中的作用是同樣重要和獨立的。正如我們所知,這個假設在現實世界中是很不真實的,因此,說樸素貝葉斯真的很“樸素”。
@AntZ: 樸素貝葉斯模型(Naive Bayesian Model)的樸素(Naive)的含義是"很簡單很天真"地假設樣本特徵彼此獨立. 這個假設現實中基本上不存在, 但特徵相關性很小的實際情況還是很多的, 所以這個模型仍然能夠工作得很好。
19 請大致對比下plsa和LDA的區別。機器學習 ML模型 中等
- pLSA中,主題分佈和詞分佈確定後,以一定的概率(
、
)分別選取具體的主題和詞項,生成好文件。而後根據生成好的文件反推其主題分佈、詞分佈時,最終用EM演算法(極大似然估計思想)求解出了兩個未知但固定的引數的值:
(由
(由
- 文件d產生主題z的概率,主題z產生單詞w的概率都是兩個固定的值。
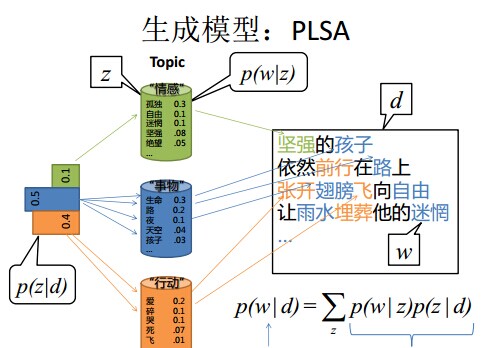
- 舉個文件d產生主題z的例子。給定一篇文件d,主題分佈是一定的,比如{ P(zi|d), i = 1,2,3 }可能就是{0.4,0.5,0.1},表示z1、z2、z3,這3個主題被文件d選中的概率都是個固定的值:P(z1|d) = 0.4、P(z2|d) = 0.5、P(z3|d) = 0.1,如下圖所示(圖擷取自沈博PPT上):
- 文件d產生主題z的概率,主題z產生單詞w的概率都是兩個固定的值。
- 但在貝葉斯框架下的LDA中,我們不再認為主題分佈(各個主題在文件中出現的概率分佈)和詞分佈(各個詞語在某個主題下出現的概率分佈)是唯一確定的(而是隨機變數),而是有很多種可能。但一篇文件總得對應一個主題分佈和一個詞分佈吧,怎麼辦呢?LDA為它們弄了兩個Dirichlet先驗引數,這個Dirichlet先驗為某篇文件隨機抽取出某個主題分佈和詞分佈。
- 文件d產生主題z(準確的說,其實是Dirichlet先驗為文件d生成主題分佈Θ,然後根據主題分佈Θ產生主題z)的概率,主題z產生單詞w的概率都不再是某兩個確定的值,而是隨機變數。
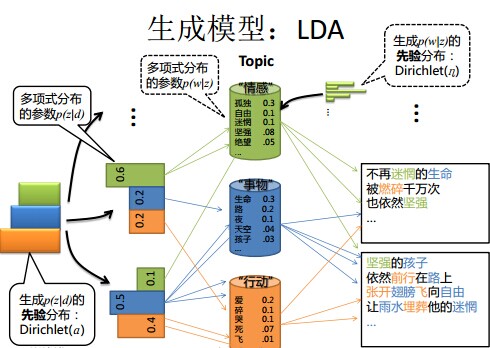
- 還是再次舉下文件d具體產生主題z的例子。給定一篇文件d,現在有多個主題z1、z2、z3,它們的主題分佈{ P(zi|d), i = 1,2,3 }可能是{0.4,0.5,0.1},也可能是{0.2,0.2,0.6},即這些主題被d選中的概率都不再認為是確定的值,可能是P(z1|d) = 0.4、P(z2|d) = 0.5、P(z3|d) = 0.1,也有可能是P(z1|d) = 0.2、P(z2|d) = 0.2、P(z3|d) = 0.6等等,而主題分佈到底是哪個取值集合我們不確定(為什麼?這就是貝葉斯派的核心思想,把未知引數當作是隨機變數,不再認為是某一個確定的值),但其先驗分佈是dirichlet 分佈,所以可以從無窮多個主題分佈中按照dirichlet 先驗隨機抽取出某個主題分佈出來。如下圖所示(圖擷取自沈博PPT上):
- 文件d產生主題z(準確的說,其實是Dirichlet先驗為文件d生成主題分佈Θ,然後根據主題分佈Θ產生主題z)的概率,主題z產生單詞w的概率都不再是某兩個確定的值,而是隨機變數。
換言之,LDA在pLSA的基礎上給這兩引數(
 、)加了兩個先驗分佈的引數(貝葉斯化):一個主題分佈的先驗分佈Dirichlet分佈
、)加了兩個先驗分佈的引數(貝葉斯化):一個主題分佈的先驗分佈Dirichlet分佈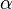 ,和一個詞語分佈的先驗分佈Dirichlet分佈
,和一個詞語分佈的先驗分佈Dirichlet分佈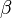 。 綜上,LDA真的只是pLSA的貝葉斯版本,文件生成後,兩者都要根據文件去推斷其主題分佈和詞語分佈,只是用的引數推斷方法不同,在pLSA中用極大似然估計的思想去推斷兩未知的固定引數,而LDA則把這兩引數弄成隨機變數,且加入dirichlet先驗。更多請參見:《通俗理解LDA主題模型》。
。 綜上,LDA真的只是pLSA的貝葉斯版本,文件生成後,兩者都要根據文件去推斷其主題分佈和詞語分佈,只是用的引數推斷方法不同,在pLSA中用極大似然估計的思想去推斷兩未知的固定引數,而LDA則把這兩引數弄成隨機變數,且加入dirichlet先驗。更多請參見:《通俗理解LDA主題模型》。20 請簡要說說EM演算法。機器學習 ML模型 中等
@tornadomeet,本題解析來源:http://www.cnblogs.com/tornadomeet/p/3395593.html
有時候因為樣本的產生和隱含變數有關(隱含變數是不能觀察的),而求模型的引數時一般採用最大似然估計,由於含有了隱含變數,所以對似然函式引數求導是求不出來的,這時可以採用EM演算法來求模型的引數的(對應模型引數個數可能有多個),EM演算法一般分為2步:
E步:選取一組引數,求出在該引數下隱含變數的條件概率值;
M步:結合E步求出的隱含變數條件概率,求出似然函式下界函式(本質上是某個期望函式)的最大值。
重複上面2步直至收斂。
公式如下所示:

M步公式中下界函式的推導過程:

EM演算法一個常見的例子就是GMM模型,每個樣本都有可能由k個高斯產生,只不過由每個高斯產生的概率不同而已,因此每個樣本都有對應的高斯分佈(k箇中的某一個),此時的隱含變數就是每個樣本對應的某個高斯分佈。
GMM的E步公式如下(計算每個樣本對應每個高斯的概率):

更具體的計算公式為:

M步公式如下(計算每個高斯的比重,均值,方差這3個引數):

21 KNN中的K如何選取的?機器學習 ML模型 易
關於什麼是KNN,可以檢視此文:《從K近鄰演算法、距離度量談到KD樹、SIFT+BBF演算法》。KNN中的K值選取對K近鄰演算法的結果會產生重大影響。如李航博士的一書「統計學習方法」上所說:
- 如果選擇較小的K值,就相當於用較小的領域中的訓練例項進行預測,“學習”近似誤差會減小,只有與輸入例項較近或相似的訓練例項才會對預測結果起作用,與此同時帶來的問題是“學習”的估計誤差會增大,換句話說,K值的減小就意味著整體模型變得複雜,容易發生過擬合;
- 如果選擇較大的K值,就相當於用較大領域中的訓練例項進行預測,其優點是可以減少學習的估計誤差,但缺點是學習的近似誤差會增大。這時候,與輸入例項較遠(不相似的)訓練例項也會對預測器作用,使預測發生錯誤,且K值的增大就意味著整體的模型變得簡單。
- K=N,則完全不足取,因為此時無論輸入例項是什麼,都只是簡單的預測它屬於在訓練例項中最多的累,模型過於簡單,忽略了訓練例項中大量有用資訊。
22 防止過擬合的方法。機器學習 ML基礎 易
過擬合的原因是演算法的學習能力過強;一些假設條件(如樣本獨立同分布)可能是不成立的;訓練樣本過少不能對整個空間進行分佈估計。
處理方法:
- 早停止:如在訓練中多次迭代後發現模型效能沒有顯著提高就停止訓練
- 資料集擴增:原有資料增加、原有資料加隨機噪聲、重取樣
- 正則化
- 交叉驗證
- 特徵選擇/特徵降維
- 建立一個驗證集是最基本的防止過擬合的方法。我們最終訓練得到的模型目標是要在驗證集上面有好的表現,而不訓練集。
- 正則化可以限制模型的複雜度。
機器學習模型被網際網路行業廣泛應用,如排序(參見:)、推薦、反作弊、定位(參見:)等。一般做機器學習應用的時候大部分時間是花費在特徵處理上,其中很關鍵的一步就是對特徵資料進行歸一化,為什麼要歸一化呢?很多同學並未搞清楚,維基百科給出的解釋:1)歸一化後加快了梯度下降求最優解的速度;2)歸一化有可能提高精度。下面再簡單擴充套件解釋下這兩點。
1 歸一化為什麼能提高梯度下降法求解最優解的速度?
如下圖所示,藍色的圈圈圖代表的是兩個特徵的等高線。其中左圖兩個特徵X1和X2的區間相差非常大,X1區間是[0,2000],X2區間是[1,5],其所形成的等高線非常尖。當使用梯度下降法尋求最優解時,很有可能走“之字型”路線(垂直等高線走),從而導致需要迭代很多次才能收斂;
而右圖對兩個原始特徵進行了歸一化,其對應的等高線顯得很圓,在梯度下降進行求解時能較快的收斂。
因此如果機器學習模型使用梯度下降法求最優解時,歸一化往往非常有必要,否則很難收斂甚至不能收斂。

2 歸一化有可能提高精度
一些分類器需要計算樣本之間的距離(如歐氏距離),例如KNN。如果一個特徵值域範圍非常大,那麼距離計算就主要取決於這個特徵,從而與實際情況相悖(比如這時實際情況是值域範圍小的特徵更重要)。
3 歸一化的型別
1)線性歸一化
這種歸一化方法比較適用在數值比較集中的情況。這種方法有個缺陷,如果max和min不穩定,很容易使得歸一化結果不穩定,使得後續使用效果也不穩定。實際使用中可以用經驗常量值來替代max和min。
2)標準差標準化
經過處理的資料符合標準正態分佈,即均值為0,標準差為1,其轉化函式為:
其中μ為所有樣本資料的均值,σ為所有樣本資料的標準差。
3)非線性歸一化
經常用在資料分化比較大的場景,有些數值很大,有些很小。通過一些數學函式,將原始值進行對映。該方法包括 log、指數,正切等。需要根據資料分佈的情況,決定非線性函式的曲線,比如log(V, 2)還是log(V, 10)等。
談談深度學習中的歸一化問題。深度學習 DL基礎 易
詳情參見此視訊:《深度學習中的歸一化》。

24 哪些機器學習演算法不需要做歸一化處理?機器學習 ML基礎 易
概率模型不需要歸一化,因為它們不關心變數的值,而是關心變數的分佈和變數之間的條件概率,如決策樹、rf。而像adaboost、svm、lr、KNN、KMeans之類的最優化問題就需要歸一化。
@管博士:我理解歸一化和標準化主要是為了使計算更方便 比如兩個變數的量綱不同 可能一個的數值遠大於另一個那麼他們同時作為變數的時候 可能會造成數值計算的問題,比如說求矩陣的逆可能很不精確 或者梯度下降法的收斂比較困難,還有如果需要計算歐式距離的話可能 量綱也需要調整 所以我估計lr 和 knn 保準話一下應該有好處。至於其他的演算法 我也覺得如果變數量綱差距很大的話 先標準化一下會有好處。
@寒小陽:一般我習慣說樹形模型,這裡說的概率模型可能是差不多的意思。
25 對於樹形結構為什麼不需要歸一化?機器學習 ML基礎 易
答:數值縮放,不影響分裂點位置。因為第一步都是按照特徵值進行排序的,排序的順序不變,那麼所屬的分支以及分裂點就不會有不同。對於線性模型,比如說LR,我有兩個特徵,一個是(0,1)的,一個是(0,10000)的,這樣運用梯度下降時候,損失等高線是一個橢圓的形狀,這樣我想迭代到最優點,就需要很多次迭代,但是如果進行了歸一化,那麼等高線就是圓形的,那麼SGD就會往原點迭代,需要的迭代次數較少。
另外,注意樹模型是不能進行梯度下降的,因為樹模型是階躍的,階躍點是不可導的,並且求導沒意義,所以樹模型(迴歸樹)尋找最優點事通過尋找最優分裂點完成的。
26 資料歸一化(或者標準化,注意歸一化和標準化不同)的原因。機器學習 ML基礎 易
@我愛大泡泡,來源:http://blog.csdn.net/woaidapaopao/article/details/77806273
要強調:能不歸一化最好不歸一化,之所以進行資料歸一化是因為各維度的量綱不相同。而且需要看情況進行歸一化。
- 有些模型在各維度進行了不均勻的伸縮後,最優解與原來不等價(如SVM)需要歸一化。
- 有些模型伸縮有與原來等價,如:LR則不用歸一化,但是實際中往往通過迭代求解模型引數,如果目標函式太扁(想象一下很扁的高斯模型)迭代演算法會發生不收斂的情況,所以最壞進行資料歸一化。
補充:其實本質是由於loss函式不同造成的,SVM用了尤拉距離,如果一個特徵很大就會把其他的維度dominated。而LR可以通過權重調整使得損失函式不變。
27 請簡要說說一個完整機器學習專案的流程。機器學習 ML應用 中
@寒小陽、龍心塵
1 抽象成數學問題
明確問題是進行機器學習的第一步。機器學習的訓練過程通常都是一件非常耗時的事情,胡亂嘗試時間成本是非常高的。
這裡的抽象成數學問題,指的我們明確我們可以獲得什麼樣的資料,目標是一個分類還是迴歸或者是聚類的問題,如果都不是的話,如果劃歸為其中的某類問題。
2 獲取資料
資料決定了機器學習結果的上限,而演算法只是儘可能逼近這個上限。
資料要有代表性,否則必然會過擬合。
而且對於分類問題,資料偏斜不能過於嚴重,不同類別的資料數量不要有數個數量級的差距。
而且還要對資料的量級有一個評估,多少個樣本,多少個特徵,可以估算出其對記憶體的消耗程度,判斷訓練過程中記憶體是否能夠放得下。如果放不下就得考慮改進演算法或者使用一些降維的技巧了。如果資料量實在太大,那就要考慮分散式了。
3 特徵預處理與特徵選擇
良好的資料要能夠提取出良好的特徵才能真正發揮效力。
特徵預處理、資料清洗是很關鍵的步驟,往往能夠使得演算法的效果和效能得到顯著提高。歸一化、離散化、因子化、缺失值處理、去除共線性等,資料探勘過程中很多時間就花在它們上面。這些工作簡單可複製,收益穩定可預期,是機器學習的基礎必備步驟。
篩選出顯著特徵、摒棄非顯著特徵,需要機器學習工程師反覆理解業務。這對很多結果有決定性的影響。特徵選擇好了,非常簡單的演算法也能得出良好、穩定的結果。這需要運用特徵有效性分析的相關技術,如相關係數、卡方檢驗、平均互資訊、條件熵、後驗概率、邏輯迴歸權重等方法。
4 訓練模型與調優
直到這一步才用到我們上面說的演算法進行訓練。現在很多演算法都能夠封裝成黑盒供人使用。但是真正考驗水平的是調整這些演算法的(超)引數,使得結果變得更加優良。這需要我們對演算法的原理有深入的理解。理解越深入,就越能發現問題的癥結,提出良好的調優方案。
5 模型診斷
如何確定模型調優的方向與思路呢?這就需要對模型進行診斷的技術。
過擬合、欠擬合 判斷是模型診斷中至關重要的一步。常見的方法如交叉驗證,繪製學習曲線等。過擬合的基本調優思路是增加資料量,降低模型複雜度。欠擬合的基本調優思路是提高特徵數量和質量,增加模型複雜度。
誤差分析 也是機器學習至關重要的步驟。通過觀察誤差樣本,全面分析誤差產生誤差的原因:是引數的問題還是演算法選擇的問題,是特徵的問題還是資料本身的問題……
診斷後的模型需要進行調優,調優後的新模型需要重新進行診斷,這是一個反覆迭代不斷逼近的過程,需要不斷地嘗試, 進而達到最優狀態。
6 模型融合
一般來說,模型融合後都能使得效果有一定提升。而且效果很好。
工程上,主要提升演算法準確度的方法是分別在模型的前端(特徵清洗和預處理,不同的取樣模式)與後端(模型融合)上下功夫。因為他們比較標準可複製,效果比較穩定。而直接調參的工作不會很多,畢竟大量資料訓練起來太慢了,而且效果難以保證。
7 上線執行
這一部分內容主要跟工程實現的相關性比較大。工程上是結果導向,模型在線上執行的效果直接決定模型的成敗。 不單純包括其準確程度、誤差等情況,還包括其執行的速度(時間複雜度)、資源消耗程度(空間複雜度)、穩定性是否可接受。
這些工作流程主要是工程實踐上總結出的一些經驗。並不是每個專案都包含完整的一個流程。這裡的部分只是一個指導性的說明,只有大家自己多實踐,多積累專案經驗,才會有自己更深刻的認識。
故,基於此,七月線上每一期ML演算法班都特此增加特徵工程、模型調優等相關課。比如,這裡有個公開課視訊《特徵處理與特徵選擇》。
28 邏輯斯特迴歸為什麼要對特徵進行離散化。機器學習 ML模型 中等
@嚴林,本題解析來源:https://www.zhihu.com/question/31989952
在工業界,很少直接將連續值作為邏輯迴歸模型的特徵輸入,而是將連續特徵離散化為一系列0、1特徵交給邏輯迴歸模型,這樣做的優勢有以下幾點:
0. 離散特徵的增加和減少都很容易,易於模型的快速迭代;
1. 稀疏向量內積乘法運算速度快,計算結果方便儲存,容易擴充套件;
相關推薦
BAT機器學習面試1000題系列 第1 305題
14 L1和L2正則先驗分別服從什麼分佈。機器學習 ML基礎 易@齊同學:面試中遇到的,L1和L2正則先驗分別服從什麼分佈,L1是拉普拉斯分佈,L2是高斯分佈。@AntZ: 先驗就是優化的起跑線, 有先驗的好處就是可以在較小的資料集中有良好的泛化效能,當然這是在先驗分佈是接近真實分佈的情況下得到的了,從資訊理
BAT機器學習面試1000題系列(第76~149題)
正文共43140個字,124張圖,預計閱讀時間:108分鐘。76、看你是搞視覺的,熟悉哪些CV框
BAT機器學習面試1000題系列(第150~279題)
長文~可先收藏再看喲~150、在感知機中(Perceptron)的任務順序是什麼?深度學習 DL
BAT機器學習面試1000題系列(第1~305題
1 請簡要介紹下SVM,機器學習 ML模型 易SVM,全稱是support vector machine,中文名叫支援向量機。SVM是一個面向資料的分類演算法,它的目標是為確定一個分類超平面,從而將不同的資料分隔開。 擴充套件:這裡有篇文章詳盡介紹了SVM的原理、推導,《支援
BAT機器學習面試1000題系列(第1~60題)
@寒小陽、龍心塵 1 抽象成數學問題 明確問題是進行機器學習的第一步。機器學習的訓練過程通常都是一件非常耗時的事情,胡亂嘗試時間成本是非常高的。 這裡的抽象成數學問題,指的我們明確我們可以獲得什麼樣的資料,目標是一個分類還是迴歸或者是聚類的問題,如果都不是的話,如果劃歸為其中的某類問題。 2 獲取
BAT機器學習面試1000題系列(第1~305題)
引言在今年的神經網路頂級會議NIPS2016上,深度學習三大牛之一的Yann Lecun教授給出了一個關於機器學習中的有監督學習、無監督學習和增強學習的一個有趣的比喻,他說:如果把智慧(Intelligence)比作一個蛋糕,那麼無監督學習就是蛋糕本體,增強學習是蛋糕上的櫻桃,那麼監督學習,僅僅能算作蛋糕上的
BAT機器學習面試1000題系列大集合整理(320)
BAT機器學習面試1000題系列大集合整理(已整理至320題)此博文整合了全部發布的最新題目,排版已經經過本人整理,公式已用latex語法表示,方便讀者閱讀。同時連結形式也做了優化,可直接跳轉至相應頁面,希望能夠幫助讀者提高閱讀體驗,文中如果因為本人的整理出
BAT題庫 | 機器學習面試1000題系列(第246~250題)
246.對於神經網路的說法, 下面正確的是 : 1. 增加神經網路層數, 可能會增加測試資料集的分類錯誤率 2. 減少神經網路層數, 總是能減小測試資料集的分類錯誤率 3. 增加神經網路層數,
Hulu機器學習問題與解答系列 | 第九彈:循環神經網絡
AD 新的 價值 sep tts wiki 今天 捕獲 huang 大噶好,今天是有關RNN問題的解答。記得多多思考和轉發,公式供應充足的Hulu機器學習系列,怎麽能只自己知 (shou)道 (nue) ~ 今天的內容是 【循環神經網絡】 場景描述 循環神經網
Hulu機器學習問題與解答系列 | 第六彈:PCA算法
iad 效果 其中 struct 並不是 系統資源 gic 文章 協方差 好久不見,Hulu機器學習問題與解答系列又又又更新啦! 你可以點擊菜單欄的“機器學習”,回顧本系列前幾期的全部內容,並留言發表你的感悟與想法,說不定會在接下來的文章中看到你的感言噢~ 今天
斯坦福大學(吳恩達) 機器學習課後習題詳解 第四周 程式設計題 多分類和神經網路
作業下載地址:https://download.csdn.net/download/wwangfabei1989/103008901. 邏輯迴歸代價函式 lrCostFuctionfunction [J, grad] = lrCostFunction(theta, X, y,
機器學習--周志華(第1章)
第1章 緒論 符號學習--->統計機器學習 機器學習中代數一般是作為基礎工具來使用 總結:出頭露面的是概率和統計,埋頭苦幹的是代數和邏輯。 機器學習是關於在計算機上從資料中產生“模型”的演算法,即學習演算法。 學得模型對應了關於資料的某種潛在的規律,因此亦稱“假設”。這
2018最新實用BAT機器學習演算法崗位系列面試總結(結構化資料特徵工程)
特徵工程,是對原始資料進行一系列工程處理,目的是去除原始資料中的雜質和冗餘,設計更高效的特徵來描述求解的問題與預測模型之間的關係。 特徵工程主要對以下兩種常用的資料型別做處理: (1)結構化資料。結構化資料型別可以看作關係型資料庫的一張表,每列都有清晰的定義,包
BAT機器學習面試題1000題(311~315題)
《BAT機器學習面試1000題》系列作為國內首個AI題庫,囊括絕大部分機器學習和深度學習的筆試面
BAT機器學習面試題1000題(316~320題)
《BAT機器學習面試1000題》系列作為國內首個AI題庫,囊括絕大部分機器學習和深度學習的筆試面
BAT機器學習面試題1000題(306~310題)
《BAT機器學習面試1000題》系列作為國內首個AI題庫,囊括絕大部分機器學習和深度學習的筆試面
ML面試1000題系列(1-20)
曲面 數值 次方 一次 決策樹算法 nlp 直接 類關系 先驗分布 本文總結ML面試常見的問題集 轉載來源:https://blog.csdn.net/v_july_v/article/details/78121924 1、簡要介紹SVM 全稱是support vect
2018最新BAT機器學習演算法崗位面試分享
從18年6月份開始,參加了一些公司的演算法工程師/機器學習工程師崗位的社會招聘,拿到了一線知名 網際網路比如BAT的演算法崗位offer, 做一些總結,希望可以給大家準備這個職位提供些資訊。 一、需要掌握的基本技能 資料結構知識 掌握一門程式語言,建議最好會Py
機器學習面試總結(第三篇)
9、整合學習大致分類?通俗理解怎樣才能提高整合學習的效能? 10、Booststrap sampling需要解決的問題?Booststrap sampling的思想?Bagging的基本思想?從偏差方差角度解釋bagging? 11、隨機森林RandomForest的思想?RF與bagg