
視頻人員行為識別
https://blog.csdn.net/linolzhang/article/details/78034823
一. 提出背景
目標:給定一段視頻,通過分析,得到裏面人員的動作行為。
問題:可以定義為一個分類問題,通過對預定的樣本進行分類訓練,解決一個輸入視頻的多分類問題。
這裏提出的問題是簡單的圖片(視頻)分類問題,該問題的前提條件是:場景目標為單人,並且占據圖片比較大的比例,如下圖所示:

還有一類問題是基於行人檢測,去估計行人的姿態和動作,暫時不在本篇討論範圍內。
二. 行為識別的發展
和其他領域一樣,我們還是先從未被深度學習攻占的傳統方法講起,我們標記的裏程碑算法是 iDT。
論文:Action Recognition with Improved Trajectories
iDT 方法是基於 DT(Dense Trajectories)方法,第一印象可以理解為 稠密光流 的軌跡。
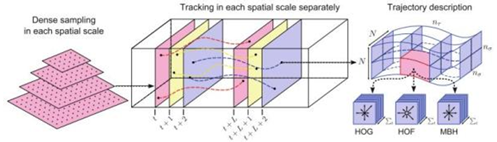
如圖所示,我們將算法描述為以下步驟:
1)在原始圖像多尺度上進行密集特征點采樣,采樣間隔為W(上圖左);
2)進行有效的特征點篩選(只保留有用的),這裏選用的方式是基於自相關矩陣的特征值;
和直接通過surf去選擇特征點的思路基本上一樣。
該 Step 形成空域信息。
3)跟蹤特征點,在時間軸形成特征點的軌跡序列(上圖中);
該 Step 形成時域信息。
4)對應每個時間片上的每個特征點,在該點影響範圍內 分別進行特征采樣(HOG、HOF、MBH)(上圖右),
對序列進行編碼(Fisher Vector),得到 Total 特征;
5)采用分類器(SVM)進行分類;
具體方法不再展開,這裏可能存在的問題是: 運動的背景可能會對光流有很大的影響。
基於這個假設,iDT 的改進方法通過估計相機的運動模型來消除背景影響,即通過 SurF 特征匹配來估算相鄰幀的投影變換矩陣。另外,論文設置了一個 Human Detector 來消除 人員變換 對運動模型估算的影響(框內不參與估算)。
三. 深度學習方法
深度學習方法攻占該領域的時間是2014年,開山之作也是具有代表性的 Two Stream 方法。
論文下載:Two-Stream Convolutional Networks for Action Recognition in Videos
來看其框架圖:
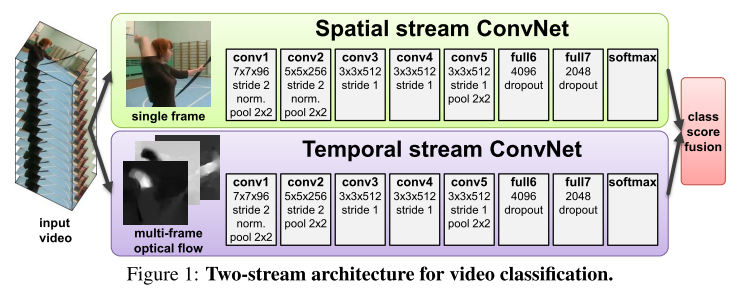
描述非常清晰,通過CNN網絡對 single frame 提取圖像的特征信息,下面通過多幀間的密集光流(與iDT類似)提出時域信息,後面通過 fusion+分類來輸出結果。
針對 Two Stream 的改進比較多,主要思路包括 網絡的改進、Fusion 方法、結合RNN(LSTM)、選擇Key Frame等, 這裏沒有太多創新的東西,可以自己refer一下。
這裏重點提一下 C3D Network,也就是3D卷積。
論文下載:Learning Spatiotemporal Features with 3D Convolutional Networks
來看示意圖:

與傳統卷積的區別就在於將平面特征的提取擴展到3維,將空域特征和時域特征同時提取,該方法相比傳統的2D方法,效率有明顯的提高,基於VGG-like網絡幀率達到了300FPS+。
雖然精度並不高,但是C3D是該方向上的一個創新,同樣的基於視頻的Task也將C3D看作是一個比較好的方法:
Code:http://vlg.cs.dartmouth.edu/c3d/
四. 參考數據集
Action Recognition 相關數據庫比較多,這裏僅列出幾個常用的供參考:
UCF101: http://crcv.ucf.edu/data/UCF101.php
HMDB51: http://serre-lab.clps.brown.edu/resource/hmdb-a-large-human-motion-database
Sports-1M: http://cs.stanford.edu/people/karpathy/deepvideo
YouTube-8M: https://research.google.com/youtube8m/download.html
ActivityNet: http://activity-net.org/download.html
視頻人員行為識別