
視訊人員行為識別(Action Recognition)
一. 提出背景
目標:給定一段視訊,通過分析,得到裡面人員的動作行為。
問題:可以定義為一個分類問題,通過對預定的樣本進行分類訓練,解決一個輸入視訊的多分類問題。
這裡提出的問題是簡單的圖片(視訊)分類問題,該問題的前提條件是:場景目標為單人,並且佔據圖片比較大的比例,如下圖所示:

還有一類問題是基於行人檢測,去估計行人的姿態和動作,暫時不在本篇討論範圍內。
二. 行為識別的發展
和其他領域一樣,我們還是先從未被深度學習攻佔的傳統方法講起,我們標記的里程碑演算法是 iDT。
iDT 方法是基於 DT(Dense Trajectories)方法,第一印象可以理解為 稠密光流 的軌跡。
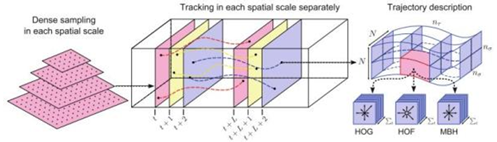
如圖所示,我們將演算法描述為以下步驟:
1)在原始影象多尺度上進行密集特徵點取樣,取樣間隔為W(上圖左);
2)進行有效的特徵點篩選(只保留有用的),這裡選用的方式是基於自相關矩陣的特徵值;
和直接通過surf去選擇特徵點的思路基本上一樣。
該 Step 形成空域資訊。
3)跟蹤特徵點,在時間軸形成特徵點的軌跡序列(上圖中);
該 Step 形成時域資訊。
4)對應每個時間片上的每個特徵點,在該點影響範圍內 分別進行特徵取樣(HOG、HOF、MBH)(上圖右),
對序列進行編碼(Fisher Vector),得到 Total 特徵;
5)採用分類器(SVM)進行分類;
具體方法不再展開,這裡可能存在的問題是: 運動的背景可能會對光流有很大的影響。
基於這個假設,iDT 的改進方法通過估計相機的運動模型來消除背景影響,即通過 SurF 特徵匹配來估算相鄰幀的投影變換矩陣。另外,論文設定了一個 Human Detector 來消除 人員變換 對運動模型估算的影響(框內不參與估算)。
三. 深度學習方法
深度學習方法攻佔該領域的時間是2014年,開山之作也是具有代表性的 Two Stream 方法。
來看其框架圖:
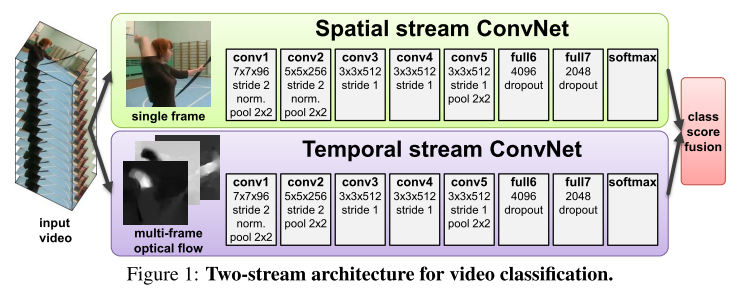
描述非常清晰,通過CNN網路對 single frame 提取影象的特徵資訊,下面通過多幀間的密集光流(與iDT類似)提出時域資訊,後面通過 fusion+分類來輸出結果。
針對 Two Stream 的改進比較多,主要思路包括 網路的改進、Fusion 方法、結合RNN(LSTM)、選擇Key Frame等, 這裡沒有太多創新的東西,可以自己refer一下。
這裡重點提一下 C3D Network,也就是3D卷積。
來看示意圖:

與傳統卷積的區別就在於將平面特徵的提取擴充套件到3維,將空域特徵和時域特徵同時提取,該方法相比傳統的2D方法,效率有明顯的提高,基於VGG-like網路幀率達到了300FPS+。
雖然精度並不高,但是C3D是該方向上的一個創新,同樣的基於視訊的Task也將C3D看作是一個比較好的方法:
四. 參考資料集
Action Recognition 相關資料庫比較多,這裡僅列出幾個常用的供參考:
相關推薦
視訊人員行為識別(Action Recognition)
一. 提出背景 目標:給定一段視訊,通過分析,得到裡面人員的動作行為。 問題:可以定義為一個分類問題,通過對預定的樣本進行分類訓練,解決一個輸入視訊的多分類問題。 這裡提出的問題是簡單的圖片(視訊)分類問題,該問題的前提條件是:場景目標為單
模式識別(Pattern Recognition)學習筆記(三十六)-- 動態聚類演算法
如果不估計樣本的概率分佈,就無法從概率分佈的角度來定義聚類,這時我們就需要有一種新的對聚類的定義,一般的,根據樣本間的某種距離或某種相似性度量來定義聚類,即把相似的或距離近的樣本聚為一類,而把不相似或距離遠的樣本聚在其他類,這種基於相似性度量的聚類方法在實際應用中非常常用,
模式識別(Pattern Recognition)學習筆記(二十七)-- 基於樹搜尋演算法的快速近鄰法
近鄰法中計算距離需要遍歷,帶來很大的計算量和儲存量,為了改善這兩方面的效能,有人提出採用分枝界定演算法(Branch-Bound Algorithm)來改進近鄰法,主要分為兩個階段:1)利用人工劃分或K-means聚類演算法或其他動態聚類演算法將樣本集X劃分
模式識別(Pattern Recognition)學習筆記(十九)--多層感知器模型(MLP)
早前已經學習了感知器學習演算法,主要通過對那些錯分類的樣本進行求和來表示對錯分樣本的懲罰,但明顯的它是一個線性的判別函式;而且上節學到了感知器神經元(閾值邏輯單元),對於單個的感知器神經元來說,儘管它能夠實現線性可分資料的分類問題(如與、或問題),但是卻無法解
模式識別(Pattern Recognition)學習筆記(一)--何為模式識別
一、什麼是模式和模式識別? 當我們人眼看到一幅畫時,我們能夠很清晰的知道其中哪裡是動物,哪裡是山,水,人等等,但是人眼又是如何識別和分辨的呢,其實很簡單,人類也是在先驗知識和對以往多
模式識別(Pattern Recognition)學習筆記(二十)--BP演算法
1.引言 在無法像線性感知器一樣利用梯度下降學習引數這一問題阻礙了MLP長達25年後的一天,有人給出了一種有效的求解這些引數的方法,就是大名鼎鼎的反向傳播演算法(Back Propagation),簡稱為我們熟知的BP演算法(特別注意,BP演算法是一種演算法,
模式識別(Pattern Recognition)學習筆記(十二)--SVM(廣義):大間隔
在學習之前,先說一些題外話,由於博主學習模式識別沒多久,所以可能對許多問題還沒有深入的認識和正確的理解,如有不妥,還望海涵,另請各路前輩不吝賜教。 好啦,我們開始學習吧。
模式識別(Pattern Recognition)學習筆記(五)——概率密度函式(pdf)的引數估計
回顧下貝葉斯決策,它的終極目標是要獲取後驗概率,而後驗概率又可以由先驗概率和類條件概率密度兩個量估計得到。先驗概率的估計相對來說比較簡單,一般有兩種方法,其一可以用訓練資料中各類出現的頻
人體行為識別(骨架提取),搭建openpose環境,VS2019(python3.7)+openpose
這幾天開始接觸人體行為識別,經過多方對比後,選擇了現在最熱的人體骨架提取開源庫,openpose。 下面就不多說了,直接開始openpose在win10下的配置: 需求如下: 1. VS2019&nb
人臉識別(初學篇)-VS2015+opencv3.2的配置
logs 點擊 環境變量 安裝 details 接下來 安裝包 png 應該 初學人臉識別,感覺安裝也是一個很大的麻煩。 寫在這裏記錄一下吧 一:先安裝好我們需要的軟件 首先安裝Vs2015,在官網或者csdn搜一下應該找的到。 安裝步驟沒有太多講究。 點擊exe文件,
視頻人員行為識別
google document src temp rtm 提高 .net 估計 下載 https://blog.csdn.net/linolzhang/article/details/78034823 一. 提出背景 目標:給定一段視頻,通過分析,得到裏面
ag視訊如何套路玩家(莊閑),學會這些技巧,勝率提高百分之十
方法 電影 導致 細心 出了 既然 你是 分享 簡單的 信譽首選【永久網址864968.C○㎡】AG視訊套路首先,我相信很多人和以前的一樣,覺得白家樂這個遊戲勝負都是五五開!只要不傻,想營(ying)錢很簡單的,但是玩兒過之後才發現,到底怎麽回事,為什麽到最後都是書(shu
ag視訊如何套路玩家(莊閑),學會這些技巧,勝率提高百分之十。。
劃算 詳解 經驗 細心 接下來 方法 如何 慢慢 容易 信譽首選【永久網址460955.c 0 m】AG視訊套路首先,我相信很多人和以前的一樣,覺得白家樂這個遊戲勝負都是五五開!只要不傻,想營(ying)錢很簡單的,但是玩兒過之後才發現,到底怎麽回事,為什麽到最後都是書(s
手把手的操作——用java呼叫科大訊飛的離線語音識別dll實現離線識別(JNA實現)(一)
#用java呼叫科大訊飛的離線語音識別dll實現離線識別(JNA實現)(一) 本人接的任務,做離線語音識別,用的是科大訊飛的離線識別,java不支援離線了,所以下載了windows的離線包,用JNA進行呼叫。之前用的是jni,但是一直沒有測試通過,本人又不會C++,研究了一個星期終究
第十八天呼叫攝像頭人臉識別(有誤判)
import cv2 as cv import numpy as np def face_detect_demo(image): gray = cv.cvtColor(image, cv.COLOR_BGR2GRAY) ##疊加分類器 face_detector = c
自然語言處理-錯字識別(基於Python)kenlm、pycorrector
轉載出處:https://blog.csdn.net/HHTNAN 中文文字糾錯劃分 中文文字糾錯任務,常見錯誤型別包括: 諧音字詞,如 配副眼睛-配副眼鏡 混淆音字詞,如 流浪織女-牛郎織女 字詞順序顛倒,如 伍迪艾倫-艾倫伍迪 字詞補全,如愛有天意-
安卓視訊播放器——ijkPlayer(Bilibili開源)
作為一個B站(Bilibili)使用者,特別喜歡B站的播放器 湊巧,發現了b站的github的地址。。嘿嘿。。B站github地址f 發現了ijkplayer播放器,支援android 和ios 我們用AndroidStudio新建project名字是bilibili_ijkplay
行為樹(Behavior Tree)實踐(進一步的討論)
本文轉自:http://www.aisharing.com/archives/99 一. 關於選擇節點的討論 我們說過選擇節點的定義是通過判斷子節點的前提條件來選擇一個節點執行,這就牽涉到判斷順序的問題,是自左向右,還是隨機選擇,或者其他的一些規則等等,這樣就延伸出各種
行為樹(Behavior Tree)實踐– 基本概念
本文轉自:http://www.aisharing.com/archives/90 通過一個例子來介紹一下行為樹的基本概念,會比較容易理解,看下圖: 這是我們為一個士兵定義的一顆行為樹(可以先不管這些綠圈和紅圈是幹嗎的),首先,可以看到這是一個樹形結構的圖,有根節點,有分
手把手的操作——用java呼叫科大訊飛的離線語音識別dll實現離線識別(JNA實現)(二)
上一篇講到了最難的地方,引數的轉換,這裡單獨寫出來 ** 三、引數的轉換(難點) ** 注:本文是以訊飛提供的C語言例子作為模板改寫,語音來源於檔案 1、先分析提供的例子 本人使用的是VS2010 下載連結連結:https://pan.baidu.com/s/