
相似度算法之余弦相似度
轉自:http://blog.csdn.net/u012160689/article/details/15341303
余弦距離,也稱為余弦相似度,是用向量空間中兩個向量夾角的余弦值作為衡量兩個個體間差異的大小的度量。
余弦值越接近1,就表明夾角越接近0度,也就是兩個向量越相似,這就叫"余弦相似性"。
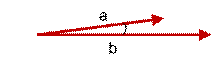
上圖兩個向量a,b的夾角很小可以說a向量和b向量有很高的的相似性,極端情況下,a和b向量完全重合。如下圖:

如上圖二:可以認為a和b向量是相等的,也即a,b向量代表的文本是完全相似的,或者說是相等的。如果a和b向量夾角較大,或者反方向。如下圖
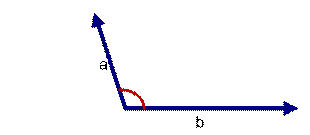
如上圖三: 兩個向量a,b的夾角很大可以說a向量和b向量有很低的的相似性,或者說a和b向量代表的文本基本不相似。那麽是否可以用兩個向量的夾角大小的函數值來計算個體的相似度呢?
向量空間余弦相似度理論就是基於上述來計算個體相似度的一種方法。下面做詳細的推理過程分析。
想到余弦公式,最基本計算方法就是初中的最簡單的計算公式,計算夾角
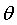
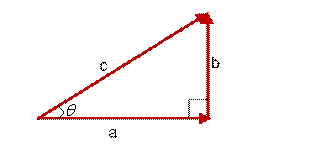
圖(4)
的余弦定值公式為:

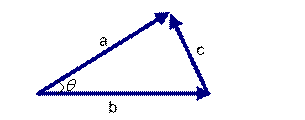
但是這個是只適用於直角三角形的,而在非直角三角形中,余弦定理的公式是
圖(5)
三角形中邊a和b的夾角 的余弦計算公式為:
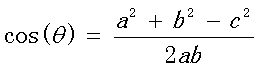
公式(2)
在向量表示的三角形中,假設a向量是(x1, y1),b向量是(x2, y2),那麽可以將余弦定理改寫成下面的形式:

圖(6)
向量a和向量b的夾角 的余弦計算如下
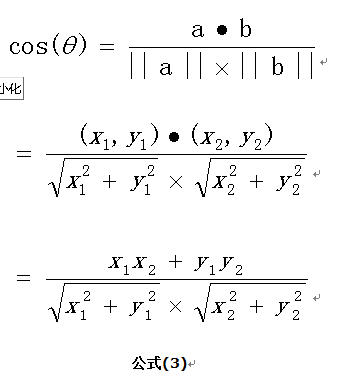
擴展,如果向量a和b不是二維而是n維,上述余弦的計算法仍然正確。假定a和b是兩個n維向量,a是 ,b是 ,則a與b的夾角 的余弦等於:
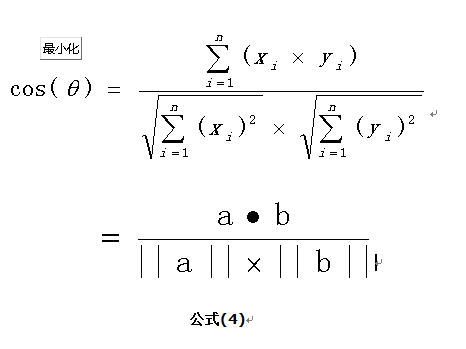
余弦值越接近1,就表明夾角越接近0度,也就是兩個向量越相似,夾角等於0,即兩個向量相等,這就叫"余弦相似性"。
另外:余弦距離使用兩個向量夾角的余弦值作為衡量兩個個體間差異的大小。相比歐氏距離,余弦距離更加註重兩個向量在方向上的差異。
借助三維坐標系來看下歐氏距離和余弦距離的區別:

從上圖可以看出,歐氏距離衡量的是空間各點的絕對距離,跟各個點所在的位置坐標直接相關;而余弦距離衡量的是空間向量的夾角,更加體現在方向上的差異,而不是位置。如果保持A點位置不變,B點朝原方向遠離坐標軸原點,那麽這個時候余弦距離  是保持不變的(因為夾角沒有發生變化),而A、B兩點的距離顯然在發生改變,這就是歐氏距離和余弦距離之間的不同之處。
是保持不變的(因為夾角沒有發生變化),而A、B兩點的距離顯然在發生改變,這就是歐氏距離和余弦距離之間的不同之處。
歐氏距離和余弦距離各自有不同的計算方式和衡量特征,因此它們適用於不同的數據分析模型:
歐氏距離能夠體現個體數值特征的絕對差異,所以更多的用於需要從維度的數值大小中體現差異的分析,如使用用戶行為指標分析用戶價值的相似度或差異。
余弦距離更多的是從方向上區分差異,而對絕對的數值不敏感,更多的用於使用用戶對內容評分來區分興趣的相似度和差異,同時修正了用戶間可能存在的度量標準不統一的問題(因為余弦距離對絕對數值不敏感)。
正因為余弦相似度在數值上的不敏感,會導致這樣一種情況存在:
用戶對內容評分,按5分制,X和Y兩個用戶對兩個內容的評分分別為(1,2)和(4,5),使用余弦相似度得到的結果是0.98,兩者極為相似。但從評分上看X似乎不喜歡2這個 內容,而Y則比較喜歡,余弦相似度對數值的不敏感導致了結果的誤差,需要修正這種不合理性就出現了調整余弦相似度,即所有維度上的數值都減去一個均值,比如X和Y的評分均值都是3,那麽調整後為(-2,-1)和(1,2),再用余弦相似度計算,得到-0.8,相似度為負值並且差異不小,但顯然更加符合現實。
那麽是否可以在(用戶-商品-行為數值)矩陣的基礎上使用調整余弦相似度計算呢?從算法原理分析,復雜度雖然增加了,但是應該比普通余弦夾角算法要強。
【下面舉一個例子,來說明余弦計算文本相似度】
舉一個例子來說明,用上述理論計算文本的相似性。為了簡單起見,先從句子著手。
句子A:這只皮靴號碼大了。那只號碼合適
句子B:這只皮靴號碼不小,那只更合適
怎樣計算上面兩句話的相似程度?
基本思路是:如果這兩句話的用詞越相似,它們的內容就應該越相似。因此,可以從詞頻入手,計算它們的相似程度。
第一步,分詞。
句子A:這只/皮靴/號碼/大了。那只/號碼/合適。
句子B:這只/皮靴/號碼/不/小,那只/更/合適。
第二步,列出所有的詞。
這只,皮靴,號碼,大了。那只,合適,不,小,很
第三步,計算詞頻。
句子A:這只1,皮靴1,號碼2,大了1。那只1,合適1,不0,小0,更0
句子B:這只1,皮靴1,號碼1,大了0。那只1,合適1,不1,小1,更1
第四步,寫出詞頻向量。
句子A:(1,1,2,1,1,1,0,0,0)
句子B:(1,1,1,0,1,1,1,1,1)
到這裏,問題就變成了如何計算這兩個向量的相似程度。我們可以把它們想象成空間中的兩條線段,都是從原點([0, 0, ...])出發,指向不同的方向。兩條線段之間形成一個夾角,如果夾角為0度,意味著方向相同、線段重合,這是表示兩個向量代表的文本完全相等;如果夾角為90度,意味著形成直角,方向完全不相似;如果夾角為180度,意味著方向正好相反。因此,我們可以通過夾角的大小,來判斷向量的相似程度。夾角越小,就代表越相似。
使用上面的公式(4)

計算兩個句子向量
句子A:(1,1,2,1,1,1,0,0,0)
和句子B:(1,1,1,0,1,1,1,1,1)的向量余弦值來確定兩個句子的相似度。
計算過程如下:
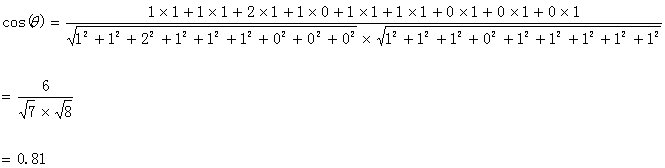
計算結果中夾角的余弦值為0.81非常接近於1,所以,上面的句子A和句子B是基本相似的
由此,我們就得到了文本相似度計算的處理流程是:
(1)找出兩篇文章的關鍵詞;
(2)每篇文章各取出若幹個關鍵詞,合並成一個集合,計算每篇文章對於這個集合中的詞的詞頻
(3)生成兩篇文章各自的詞頻向量;
(4)計算兩個向量的余弦相似度,值越大就表示越相似。
代碼實現如下:
- #余弦相似度算法
- def CosSimilarity(UL,p1,p2):
- si = GetSameItem(UL,p1,p2)
- n = len(si)
- if n == 0:
- return 0
- s = sum([UL[p1][item]*UL[p2][item] for item in si])
- den1 = math.sqrt(sum([pow(UL[p1][item],2) for item in si]))
- den2 = math.sqrt(sum([pow(UL[p2][itme],2) for item in si]))
- return s/(den1*den2)
相似度算法之余弦相似度