
DataPipeline |Apache Kafka實戰作者胡夕:Apache Kafka監控與調優

胡夕,《Apache Kafka實戰》作者,北航計算機碩士畢業,現任某互金公司計算平臺總監,曾就職於IBM、搜狗、微博等公司。國內活躍的Kafka代碼貢獻者。
前言
雖然目前Apache Kafka已經全面進化成一個流處理平臺,但大多數的用戶依然使用的是其核心功能:消息隊列。對於如何有效地監控和調優Kafka是一個大話題,很多用戶都有這樣的困擾,今天我們就來討論一下。
一、Kafka綜述
在討論具體的監控與調優之前,我想用一張PPT圖來簡單說明一下當前Kafka生態系統的各個組件。就像我前面所說,Kafka目前已經進化成了一個流處理平臺,除了核心的消息隊列組件Kafka core之外,社區還新引入Kafka Connect和Kafka Streams兩個新的組件:其中前者負責Kafka與外部系統的數據傳輸;後者則負責對數據進行實時流處理計算。下圖羅列了一些關鍵的Kafka概念。
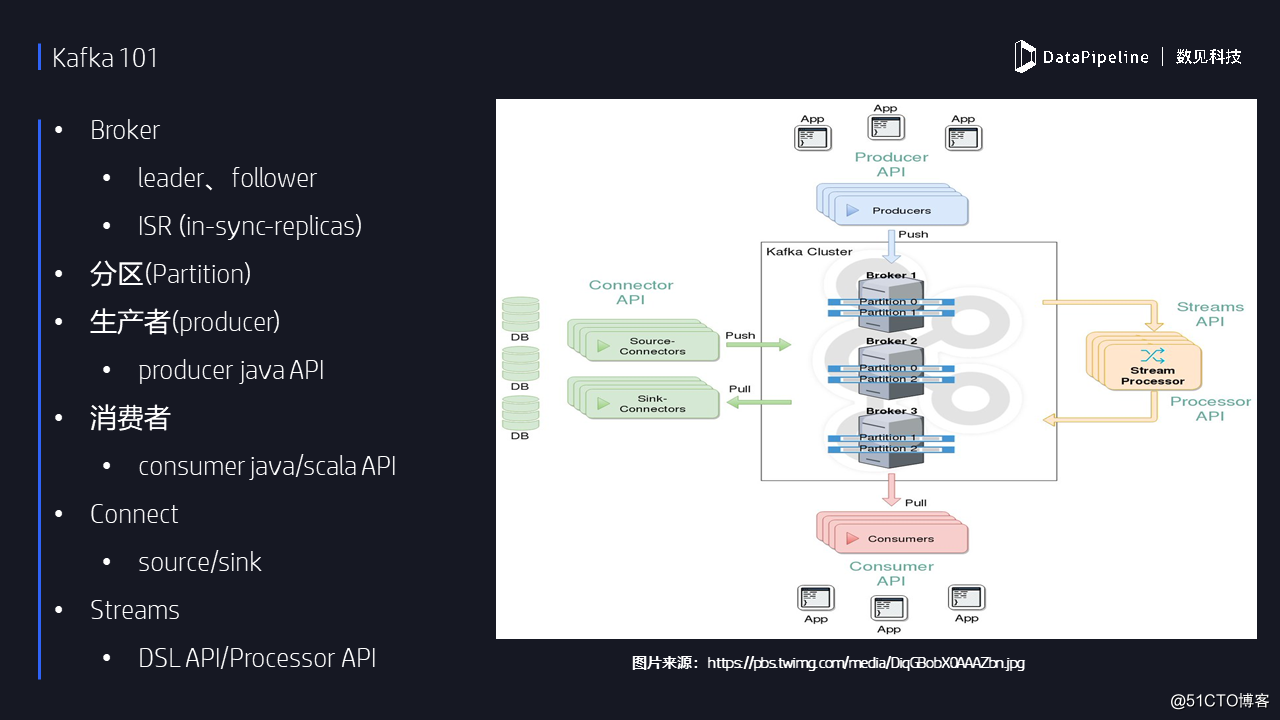
二、Kafka監控
我打算從五個維度來討論Kafka的監控。首先是要監控Kafka集群所在的主機;第二是監控Kafka broker JVM的表現;第三點,我們要監控Kafka Broker的性能;第四,我們要監控Kafka客戶端的性能。這裏的所指的是廣義的客戶端——可能是指我們自己編寫的生產者、消費者,也有可能是社區幫我們提供的生產者、消費者,比如說Connect的Sink/Source或Streams等;最後我們需要監控服務器之間的交互行為。
1.主機監控
個人認為對於主機的監控是最重要的。因為很多線上環境問題首先表現出來的癥狀就是主機的某些性能出現了明顯的問題。此時通常是運維人員首先發現了它們然後告訴我們這臺機器有什麽問題,對於Kafka主機監控通常是發現問題的第一步。這一頁列出了常見的指標,包括CPU、內存、帶寬等數據。需要註意的是CPU使用率的統計。可能大家聽過這樣的提法:我的Kafka Broker CPU使用率是400%,怎麽回事?對於這樣的問題,我們首先要搞清楚這個使用率是怎麽觀測出來的? 很多人拿top命令中的vss或rss字段來表征CPU使用率,但實際上它們並不是真正的CPU使用率——那只是所有CPU共同作用於Kafka進程所花的時間片的比例。舉個例子,如果機器上有16個CPU,那麽只要這些值沒有超過或接近1600, 那麽你的CPU使用率實際上是很低的。因此要正確理解這些命令中各個字段的含義。
這頁PPT右邊給出了一本書,如果大家想監控主機性能的話,我個人建議這本《SystemsPerformance》就足夠了。非常權威的一本書,推薦大家讀一下。

2.監控JVM
Kafka本身是一個普通的Java進程,所以任何適用於JVM監控的方法對於監控Kafka都是相通的。第一步就是要先了解Kafka應用。比方說了解Kafka broker JVM的GC頻率和延時都是多少,每次GC後存活對象的大小是怎樣的等。了解了這些信息我們才能明確後面調優的方向。當然,我們畢竟不是特別資深的JVM專家,因此也不必過多追求繁復的JVM監控與調優。只需要關註大的方面即可。另外,如果大家時間很有限但又想快速掌握JVM監控與調優,推薦閱讀《Java Performance》。
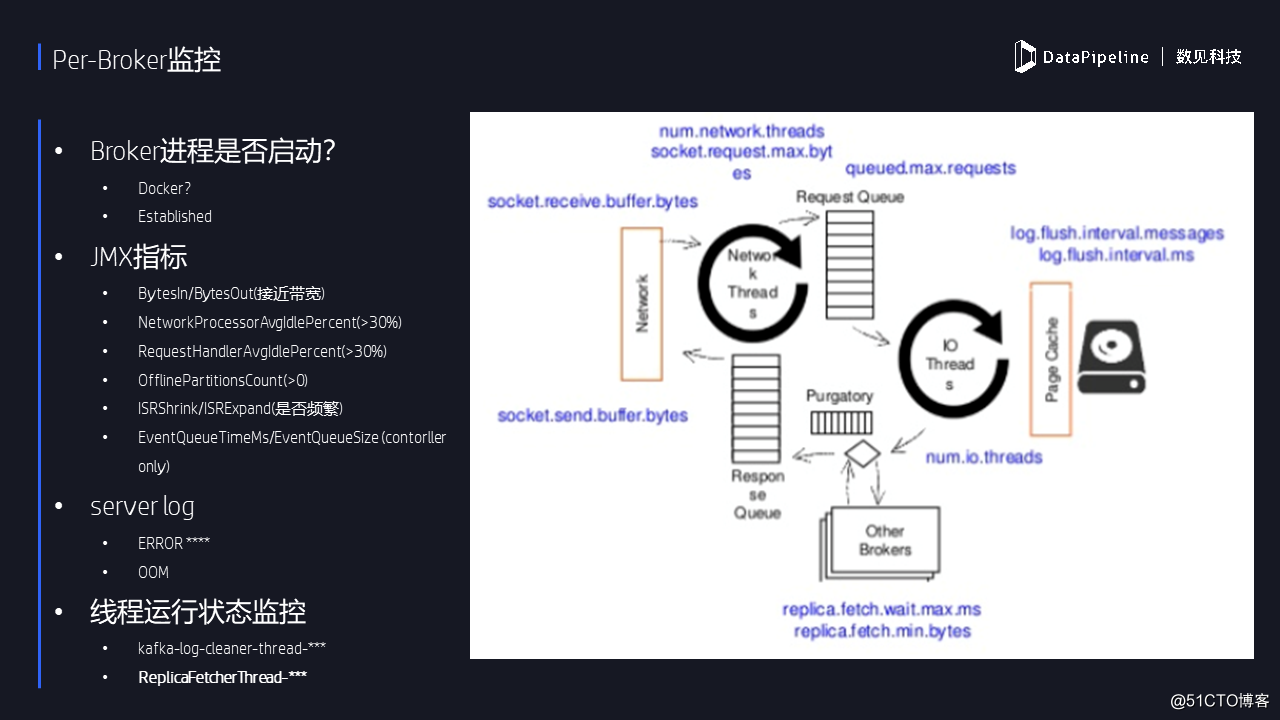
3.Per-Broker監控
首先要確保Broker進程是啟動狀態?這聽起來好像有點搞笑,但我的確遇到過這樣的情況。比如當把Kafka部署在Docker上時就容易出現進程啟動但服務沒有成功啟動的情形。正常啟動下,一個Kafka服務器起來的時候,應該有兩個端口,一個端口是9092常規端口,會建一個TCP鏈接。還有一個端口是給JMX監控用的。當然有多臺broker的話,那麽controller機器會為每臺broker都維護一個TCP連接。在實際監控時可以有意識地驗證這一點。
對於Broker的監控,我們主要是通過JMS指標來做的。用過Kafka的人知道,Kafka社區提供了特別多的JMS指標,其中很多指標用處不大。我這裏列了一些比較重要的:首先是broker機器每秒出入的字節數,就是類似於我可以監控網卡的流量,一定要把這個指標監控起來,並實時與你的網卡帶寬進行比較——如果發現該值非常接近於帶寬的話,就證明broker負載過高,要麽增加新的broker機器,要麽把該broker上的負載均衡到其他機器上。
另外還有兩個線程池空閑使用率小關註,最好確保它們的值都不要低於30%,否則說明Broker已經非常的繁忙。 此時需要調整線程池線程數。
接下來是監控broker服務器的日誌。日誌中包含了非常豐富的信息。這裏所說的日誌不僅是broker服務器的日誌,還包括Kafka controller的日誌。我們需要經常性地查看日誌中是否出現了OOM錯誤抑或是時刻關註日誌中拋出的ERROR信息。
我們還需要監控一些關鍵後臺線程的運行狀態。個人認為有兩個比較重要的線程需要監控:一個Log Cleaner線程——該線程是執行數據壓實操作的,如果該線程出問題了,用戶通常無法感知到,然後會發現所有compact策略的topic會越來越大直到占滿所有磁盤空間;另一個線程就是副本拉取線程,即follower broker使用該線程實時從leader處拉取數據。如果該線程“掛掉”了,用戶通常也是不知道的,但會發現follower不再拉取數據了。因此我們一定要定期地查看這兩個線程的狀態,如果發現它們意味終止,則去找日誌中尋找對應的報錯信息。
4.Clients監控
客戶端監控這塊,我這邊會分為兩個,分別討論對生產者和消費者的監控。生產者往Kafka發消息,在監控之前我們至少要了解一下客戶端機器與Broker端機器之間的RTT是多少。對於那種跨數據中心或者是異地的情況來說,RTT本來就很大,如果不做特殊的調優,是不可能有太高的TPS的。目前Kafka producer是雙線程的設計機制,分為用戶主線程和Sender線程,當這個Sender線程掛了的時候,前端用戶是不感知的,但表現為producer發送消息失敗,所以用戶最好監控一下這個Sender線程的狀態。
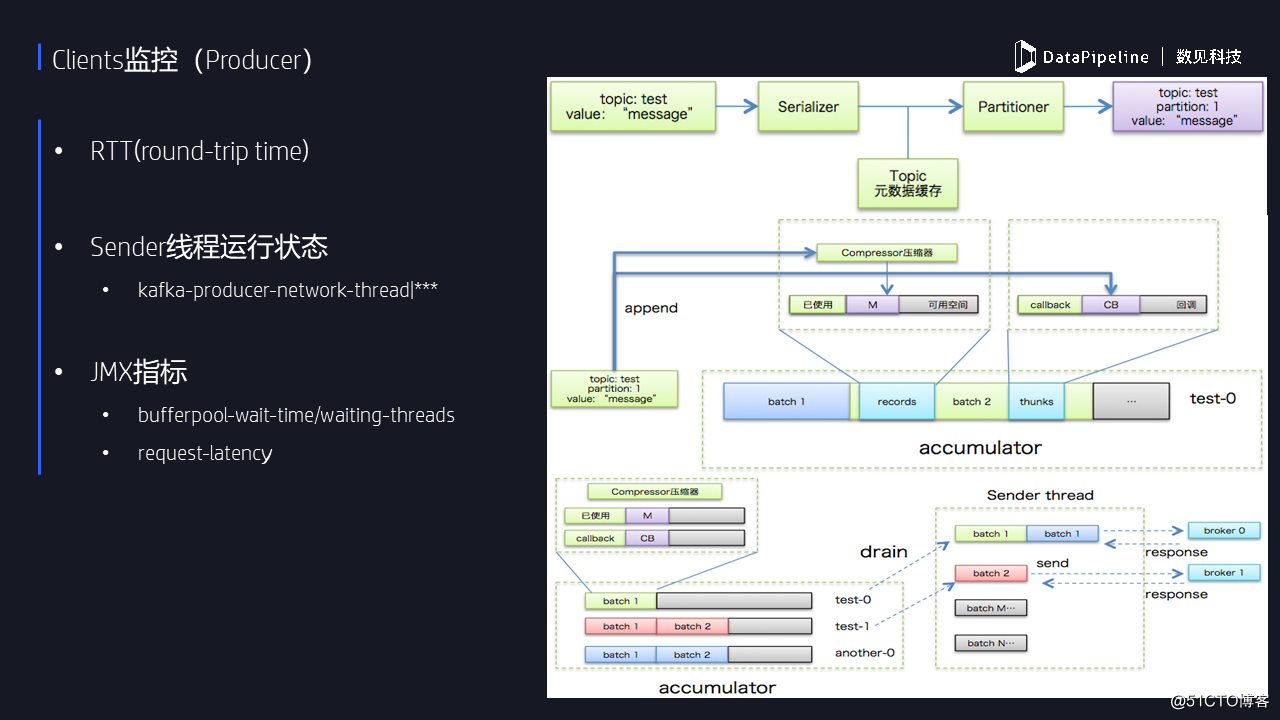
還有就是監控PRODUCE請求的處理延時。一條消息從生產者端發送到Kafka broker進行處理,之後返回給producer的總時間。整個鏈路中各個環節的耗時最好要做到心中有數。因為很多情況下,如果你要提升生產者的TPS,了解整個鏈路中的瓶頸後才能做到有的放矢。後面PPT中我會討論如何拆解這條鏈路。
現在說說消費者。這裏的消費者說的是新版本的消費者,也就是java consumer。
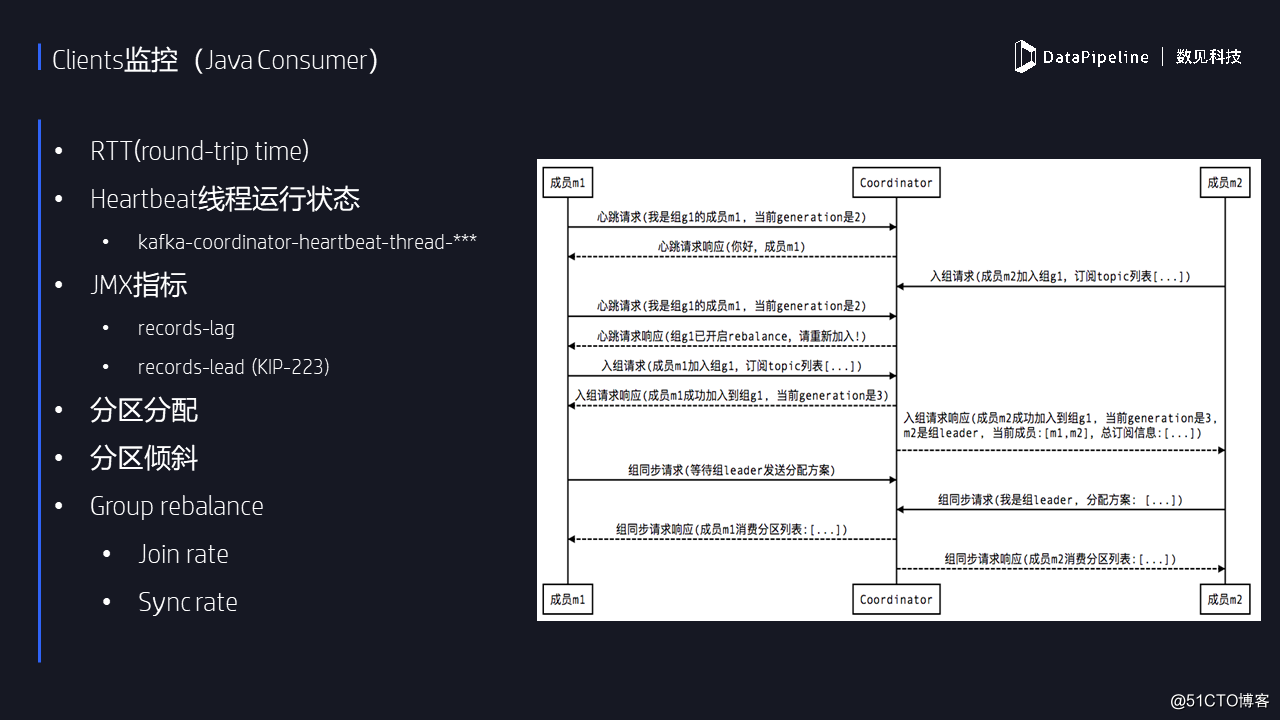
社區已經非常不推薦再繼續使用老版本的消費者了。新版本的消費者也是雙線程設計,後面有一個心跳線程,如果這個線程掛掉的話,前臺線程是不知情的。所以,用戶最好定期監控該心跳線程的存活情況。心跳線程定期發心跳請求給Kafka服務器,告訴Kafka,這個消費者實例還活著,以避免coordinator錯誤地認為此實例已“死掉”從而開啟rebalance。Kafka提供了很多的JMX指標可以用於監控消費者,最重要的消費進度滯後監控,也就是所謂的consumerlag。
假設producer生產了100條消息,消費者讀取了80條,那麽lag就是20。顯然落後的越少越好,這表明消費者非常及時,用戶也可以用工具行命令來查lag,甚至寫Java的API來查。與lag對應的還有一個lead指標,它表征的是消費者領先第一條消息的進度。比如最早的消費位移是1,如果消費者當前消費的消息是10,那麽lead就是9。對於lead而言越大越好,否則表明此消費者可能處於停頓狀態或者消費的非常慢,本質上lead和lag是一回事,之所以列出來是因為lead指標是我開發的,也算打個廣告吧。
除了以上這些,我們還需要監控消費者組的分區分配情況,避免出現某個實例被分配了過多的分區,導致負載嚴重不平衡的情況出現。一般來說,如果組內所有消費者訂閱的是相同的主題,那麽通常不會出現明顯的分配傾斜。一旦各個實例訂閱的主題不相同且每個主題分區數參差不齊時就極易發生這種不平衡的情況。Kafka目前提供了3種策略來幫助用戶完成分區分配,最新的策略是黏性分配策略,它能保證絕對的公平,大家可以去試一下。
最後就是要監控rebalance的時間——目前來看,組內超多實例的rebalance性能很差,可能都是小時級別的。而且比較悲劇的是當前無較好的解決方案。所以,如果你的Consumer特別特別多的話,一定會有這個問題,你監控一下兩個步驟所用的時間,看看是否滿足需求,如果不能滿足的話,看看能不能把消費者去除,盡量減少消費者數量。
5.Inter-Broker監控
最後一個維度就是監控Broker之間的表現,主要是指副本拉取。Follower副本實時拉取leader處的數據,我們自然希望這個拉取過程越快越好。Kafka提供了一個特別重要的JMX指標,叫做備份不足的分區數,比如說我規定了這條消息,應該在三個Broker上面保存,假設只有一個或者兩個Broker上保存該消息,那麽這條消息所在的分區就被稱為“備份不足”的分區。這種情況是特別關註的,因為有可能造成數據的丟失。《Kafka權威指南》一書中是這樣說的:如果你只能監控一個Kafka JMX指標,那麽就監控這個好了,確保在你的Kafka集群中該值是永遠是0。一旦出現大於0的情形趕緊處理。

還有一個比較重要的指標是表征controller個數的。整個集群中應該確保只能有一臺機器的指標是1,其他全應該是0,如果你發現有一臺機器是2或者是3,一定是出現腦裂了,此時應該去檢查下是否出現了網絡分區。Kafka本身是不能對抗腦裂的,完全依靠Zookeeper來做,但是如果真正出現網絡分區的話,也是沒有辦法處理的,不如趕快fail fast掉。
三、監控工具
當前沒有一款Kafka監控工具是公認比較優秀的,每個都有自己的特點但也有些致命的缺陷。我們針對一些常見的監控工具逐個討論下。
1.Kafka Manager
應該說在所有免費的監控框架中,Kafka Manager是最受歡迎的。它最早由雅虎開源,功能非常齊全,展示的數據非常豐富。另外,用戶能夠在界面上執行一些簡單的集群管理操作。更加令人欣慰的是,該框架目前還在不斷維護中,因此使用Kafka manager來監控Kafka是一個不錯的選擇。
2.Burrow
Burrow是去年下半年開源,專門監控消費者信息的框架。這個框架剛開始開源的時候,我還對它還是寄予厚望的,畢竟是Kafka社區committer親自編寫的。不過Burrow的問題在於沒有UI界面,不方便運維操作。另外由於是Go語言寫的,你要用的話,必須搭建Go語言環境,然後編譯部署,總之用起來不是很方便。還有就是它的更新不是很頻繁,已經有點半荒廢的狀態,大家不妨一試。
3.Kafka Monitor
嚴格來說,它不是監控工具,它是專門做Kafka集群系統性測試用的。待監控的指標可以由用戶自己設定,主要是做一些端到端的測試。比如說你搭了一套Kafka集群,想測試端到端的性能怎樣:從發消息到消費者讀取消息這一整體流程的性能。該框架的優勢也是由Kafka社區團隊寫的,質量有保障,但更新不是很頻繁,目前好像幾個月沒有更新了。
4.Kafka Offset Monitor
KafkaOffsetMonitor是我用的最早的一個Kafka監控工具,也是監控消費者位移,只不過那時候Kafka把位移保持在Zookeepr上。這個框架的界面非常漂亮,國內用的人很多。但是現在有一個問題,因為我們現在用了新版本的消費者,這個框架目前支持得的並不是特別好。而且還有一個問題就是它已經不再維護了,可能有1-2年沒有任何更新了。
5.Kafka Eagle
這是國人自己開發的,我不知道具體是哪個大牛開發的,但是在Kafka QQ群裏面很多人推崇,因為界面很幹凈漂亮,上面有很好的數據展現。
6.Confluent Control Center
Control Center是目前我能收集到的功能最齊全的Kafka監控框架了,只不過只有購買了Confluent企業版也有的,也就是說是付費的。
綜合來講,如果你是Kafka集群運維操作人員,推薦先用Kafka Manager來做監控,後面再根據實際監控需求定制化開發特有的工具或框架。
四、系統調優
Kafka監控的一個主要的目的就是調優Kafka集群。這裏羅列了一些常見的操作系統級的調優。
首先是保證頁緩存的大小——至少要設置頁緩存為一個日誌段的大小。我們知道Kafka大量使用頁緩存,只要保證頁緩存足夠大,那麽消費者讀取消息時就有大概率保證它能夠直接命中頁緩存中的數據而無需從底層磁盤中讀取。故只要保證頁緩存要滿足一個日誌段的大小。
第二是調優文件打開數。很多人對這個資源有點畏手畏腳。實際上這是一個很廉價的資源,設置一個比較大的初始值通常都是沒有什麽問題的。
第三是調優vm.max_map_count參數。主要適用於Kafka broker上的主題數超多的情況。Kafka日誌段的索引文件是用映射文件的機制來做的,故如果有超多日誌段的話,這種索引文件數必然是很多的,極易打爆這個資源限制,所以對於這種情況一般要適當調大這個參數。
第四是swap的設置。很多文章說把這個值設為0,就是完全禁止swap,我個人不建議這樣,因為當你設置成為0的時候,一旦你的內存耗盡了,Linux會自動開啟OOM killer然後隨機找一個進程殺掉。這並不是我們希望的處理結果。相反,我建議設置該值為一個比較接近零的較小值,這樣當我的內存快要耗盡的時候會嘗試開啟一小部分swap,雖然會導致broker變得非常慢,但至少給了用戶發現問題並處理之的機會。
第五JVM堆大小。首先鑒於目前Kafka新版本已經不支持Java7了,而Java 8本身不更新了,甚至Java9其實都不做了,直接做Java10了,所以我建議Kafka至少搭配Java8來搭建。至於堆的大小,個人認為6-10G足矣。如果出現了堆溢出,就提jira給社區,讓他們看到底是怎樣的問題。因為這種情況下即使用戶調大heap size,也只是延緩OOM而已,不太可能從根本上解決問題。

最後,建議使用專屬的多塊磁盤來搭建Kafka集群。自1.1版本起Kafka正式支持JBOD,因此沒必要在底層再使用一套RAID了。
五、Kafka調優的四個層面
Kafka調優通常可以從4個維度展開,分別是吞吐量、延遲、持久性和可用性。在具體展開這些方面之前,我想先建議用戶保證客戶端與服務器端版本一致。如果版本不一致,就會出現向下轉化的問題。舉個例子,服務器端保存高版本的消息,當低版本消費者請求數據時,服務器端就要做轉化,先把高版本消息轉成低版本再發送給消費者。這件事情本身就非常非常低效。很多文章都討論過Kafka速度快的原因,其中就談到了零拷貝技術——即數據不需要在頁緩存和堆緩存中來回拷貝。
簡單來說producer把生產的消息放到頁緩存上,如果兩邊版本一致,可以直接把此消息推給Consumer,或者Consumer直接拉取,這個過程是不需要把消息再放到堆緩存。但是你要做向下轉化或者版本不一致的話,就要額外把數據再堆上,然後再放回到Consumer上,速度特別慢。
1.Kafka調優 – 吞吐量
調優吞吐量就是我們想用更短的時間做更多的事情。這裏列出了客戶端需要調整的參數。前面說過了producer是把消息放在緩存區,後端Sender線程從緩存區拿出來發到broker。這裏面涉及到一個打包的過程,它是批處理的操作,不是一條一條發送的。因此這個包的大小就和TPS息息相關。通常情況下調大這個值都會讓TPS提升,但是也不會無限制的增加。不過調高此值的劣處在於消息延遲的增加。除了調整batch.size,設置壓縮也可以提升TPS,它能夠減少網絡傳輸IO。當前Lz4的壓縮效果是最好的,如果客戶端機器CPU資源很充足那麽建議開啟壓縮。

對於消費者端而言,調優TPS並沒有太好的辦法,能夠想到的就是調整fetch.min.bytes。適當地增加該參數的值能夠提升consumer端的TPS。對於Broker端而言,通常的瓶頸在於副本拉取消息時間過長,因此可以適當地增加num.replica.fetcher值,利用多個線程同時拉取數據,可以加快這一進程。
2.Kafka調優 – 延時
所謂的延時就是指消息被處理的時間。某些情況下我們自然是希望越快越好。針對這方面的調優,consumer端能做的不多,簡單保持fetch.min.bytes默認值即可,這樣可以保證consumer能夠立即返回讀取到的數據。講到這裏,可能有人會有這樣的疑問:TPS和延時不是一回事嗎?假設發一條消息延時是2ms,TPS自然就是500了,因為一秒只能發500消息,其實這兩者關系並不是簡單的。因為我發一條消息2毫秒,但是如果把消息緩存起來統一發,TPS會提升很多。假設發一條消息依然是2ms,但是我先等8毫秒,在這8毫秒之內可能能收集到一萬條消息,然後我再發。相當於你在10毫秒內發了一萬條消息,大家可以算一下TPS是多少。事實上,Kafka producer在設計上就是這樣的實現原理。
3.Kafka調優 –消息持久性
消息持久化本質上就是消息不丟失。Kafka對消息不丟失的承諾是有條件的。以前碰到很多人說我給Kafka發消息,發送失敗,消息丟失了,怎麽辦?嚴格來說Kafka不認為這種情況屬於消息丟失,因為此時消息沒有放到Kafka裏面。Kafka只對已經提交的消息做有條件的不丟失保障。
如果要調優持久性,對於producer而言,首先要設置重試以防止因為網絡出現瞬時抖動造成消息發送失敗。一旦開啟了重試,還需要防止亂序的問題。比如說我發送消息1與2,消息2發送成功,消息1發送失敗重試,這樣消息1就在消息2之後進入Kafka,也就是造成亂序了。如果用戶不允許出現這樣的情況,那麽還需要顯式地設置max.in.flight.requests.per.connection為1。
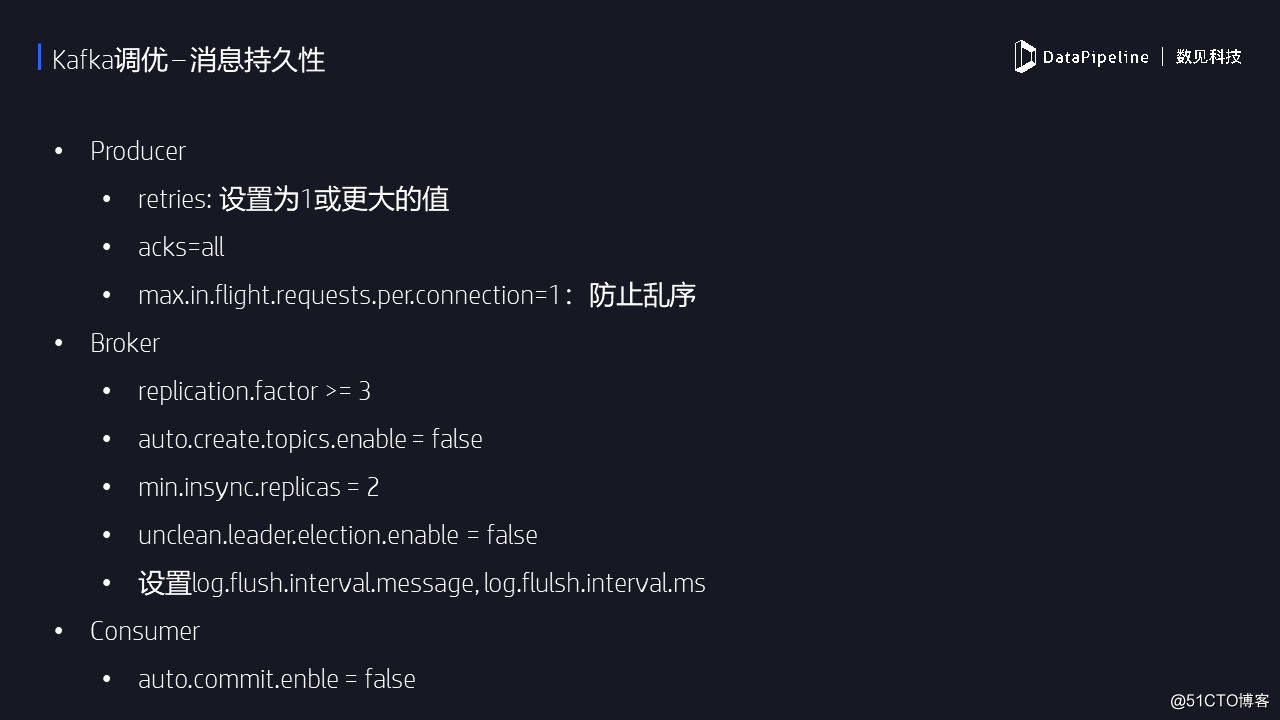
本頁PPT列出的其他參數都是很常規的參數,比如unclean.leader.election.enable參數,最好還是將其設置成false,即不允許“臟”副本被選舉為leader。
4.Kafka調優 –可用性
最後是可用性,與剛才的持久性是相反的,我允許消息丟失,只要保證系統高可用性即可。因此我需要把consumer心跳超時設置為一個比較小的值,如果給定時間內消費者沒有處理完消息,該實例可能就被踢出消費者組。我想要其他消費者更快地知道這個決定,因此調小這個參數的值。
六、定位性能瓶頸
下面就是性能瓶頸,嚴格來說這不是調優,這是解決性能問題。對於生產者來說,如果要定位發送消息的瓶頸很慢,我們需要拆解發送過程中的各個步驟。就像這張圖表示的那樣,消息的發送共有6步。第一步就是生產者把消息放到Broker,第二、三步就是Broker把消息拿到之後,寫到本地磁盤上,第四步是follower broker從Leader拉取消息,第五步是創建response;第六步是發送回去,告訴我已經處理完了。
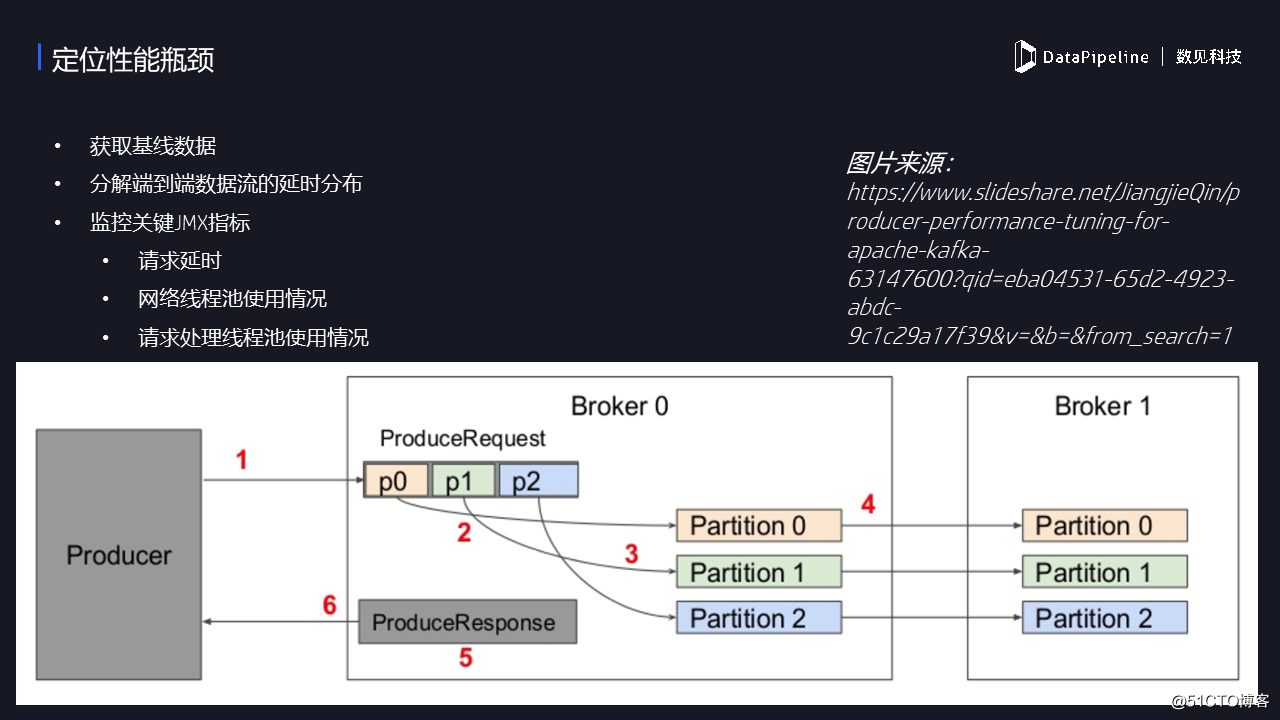
這六步當中你需要確定瓶頸在哪?怎麽確定?——通過不同的JMX指標。比如說步驟1是慢的,可能你經常碰到超時,你如果在日誌裏面經常碰到request timeout,就表示1是很慢的,此時要適當增加超時的時間。如果2、3慢的情況下,則可能體現在磁盤IO非常高,導致往磁盤上寫數據非常慢。倘若是步驟4慢的話,查看名為remote-time的JMX指標,此時可以增加fetcher線程的數量。如果5慢的話,表現為response在隊列導致待的時間過長,這時可以增加網絡線程池的大小。6與1是一樣的,如果你發現1、6經常出問題的話,查一下你的網絡。所以,就這樣來分解整個的耗時。這是到底哪一步的瓶頸在哪,需要看看什麽樣的指標,做怎樣的調優。
七、Java Consumer的調優
最後說一下Consumer的調優。目前消費者有兩種使用方式,一種是同一個線程裏面就直接處理,另一種是我采用單獨的線程,consumer線程只是做獲取消息,消息真正的處理邏輯放到單獨的線程池中做。這兩種方式有不同的使用場景:第一種方法實現較簡單,因為你的消息處理邏輯直接寫在一個線程裏面就可以了,但是它的缺陷在於TPS可能不會很高,特別是當你的客戶端的機器非常強的時候,你用單線程處理的時候是很慢的,因為你沒有充分利用線程上的CPU資源。第二種方法的優勢是能夠充分利用底層服務器的硬件資源,TPS可以做的很高,但是處理提交位移將會很難。
最後說一下參數,也是網上問的最多的,這幾個參數到底是做什麽的。第一個參數,就是控制consumer單次處理消息的最大時間。比如說設定的是600s,那麽consumer給你10分鐘來處理。如果10分鐘內consumer無法處理完成,那麽coordinator就會認為此consumer已死,從而開啟rebalance。
Coordinator是用來管理消費者組的協調者,協調者如何在有效的時間內,把消費者實例掛掉的消息傳遞給其他消費者,就靠心跳請求,因此可以設置heartbeat.interval.ms為一個較小的值,比如5s。
八、Q & A
Q1:胡老師在前面提到低版本與高版本有一個端口的問題,我想問一下高版本的、低版本的會有這個問題嗎?
A1:會有。
Q2:兩種模式,一個是Consumer怎麽做到所有的partition,在裏面做管理的。會有一個問題,某個Consumer的消費比較慢,因為所有的Partition的消費都是綁定在一個線程。一個消費比較慢,一個消費比較快,要等另一個。有沒有一種方案,消費者比較慢的可以暫定,如果涉及到暫停的話,頻繁的暫定耗費的時間,是不是會比較慢?
A2:一個線程處理所有的分區。如果從開銷來講並不大,但是的確會出現像你說的,如果一個消費者定了100個分區,目前我這邊看到的效果,某段時間內有可能會造成某些分區的餓死,比如說某些分區長期得不到數據,可能有一些分區不停的有數據,這種情況下的確有可能情況。但是你說的兩種方法本身開銷不是很大,因為它就是內存當中的結構變更,就是定位信息,如果segment,就把定位信息先暫時關掉,不涉及到很復雜的數據結構的變更。
Q3:怎麽決定順序呢?
A3:這個事情現在在Broker端做的,簡單會做輪詢,比如說有100個分區,第一批隨機給你一批分區,之後這些分區會排到整個隊列的末尾,從其他的分區開始給你,做到盡量的公平。
Q4:消費的時候會出現數據傾斜的情況,這塊如何理解?
A4:數據傾斜。這種情況下發生在每個消費者訂閱信息不一樣的情況下,特別容易出現數據傾斜。比如說我訂閱主題123,我訂閱主題456,我們又在同一個組裏面這些主題分區數極不相同,很有可能出現我訂閱了10個分區,你可能訂閱2個分區。如果你用的是有粘性的分配策略,那種保證不會出現超過兩個以上相差的情況。這個策略推出的時間也不算短了,是0.11版本推出來的。
點擊這裏,免費申請DataPipeline產品試用
DataPipeline |Apache Kafka實戰作者胡夕:Apache Kafka監控與調優