
Python爬蟲教程-24-數據提取-BeautifulSoup4(二)
阿新 • • 發佈:2018-09-06
筆記 rgs hub 表達 ren () tags .com desc
- 本筆記不允許任何個人和組織轉載
Python爬蟲教程-24-數據提取-BeautifulSoup4(二)
本篇介紹 bs 如何遍歷一個文檔對象
遍歷文檔對象
- contents:tag 的子節點以列表的方式輸出
- children:子節點以叠代器形式返回
- descendants:所有子孫節點
- string:用string打印出標簽的具體內容,不帶有標簽,只有內容
- 案例代碼27bs3.py文件:https://xpwi.github.io/py/py%E7%88%AC%E8%99%AB/py27bs3.py
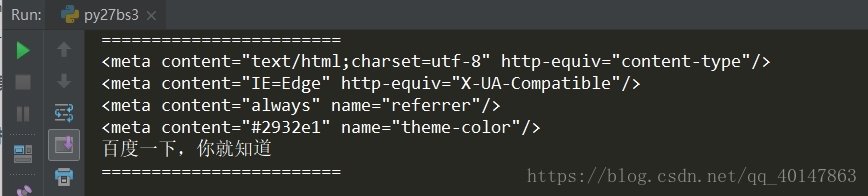
# BeautifulSoup 的使用案例 # 遍歷文檔對象 from urllib import request from bs4 import BeautifulSoup url = ‘http://www.baidu.com/‘ rsp = request.urlopen(url) content = rsp.read() soup = BeautifulSoup(content, ‘lxml‘) # bs 自動解碼 content = soup.prettify() print("=="*12) # 使用 contents for node in soup.head.contents: if node.name == "meta": print(node) if node.name == "title": print(node.string) print("=="*12)
運行結果
常用string打印出標簽的具體內容,不帶有標簽,只有內容
當然,如果覺得遍歷太耗費資源,沒有必要遍歷的時候,可以使用搜索
搜索文檔對象
- find_all(name, attrs, recursive, text, ** kwargs)
- 使用find_all(),返回的列表格式,也就是說如果 find_all(name=‘meta‘) ,如果有多個 meta 就以列表形式返回
- name 參數:按照哪個字符搜索,可以傳入的內容為
- 1.字符串
- 2.正則表達式,使用正則需要編譯:
例如:我們需要打印所有以 me 開頭的標簽內容
tags = soup.find_all(re.compile(‘^me‘)) - 3.也可以是列表
- keyword 參數,可以用來表示屬性
- text:對應 tag 的文本值
- 案例代碼27bs4.py文件:https://xpwi.github.io/py/py%E7%88%AC%E8%99%AB/py27bs4.py
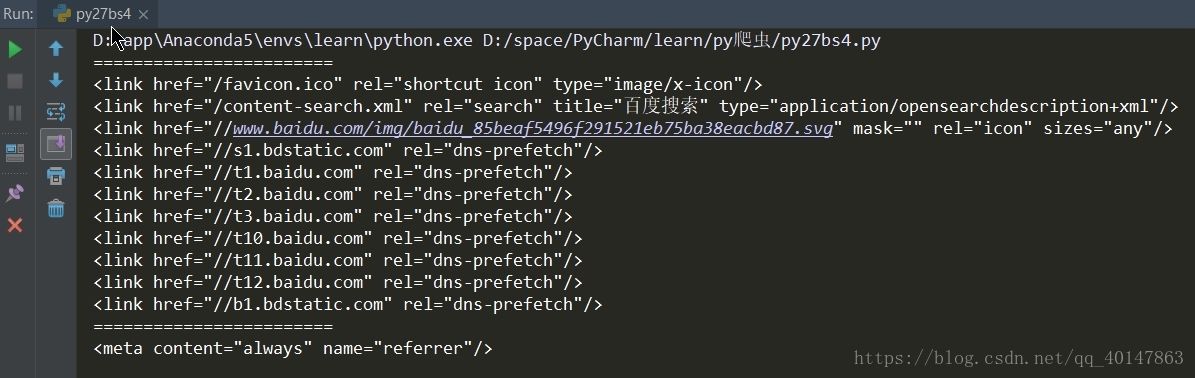
# BeautifulSoup 的使用案例 # 搜索文檔對象 from urllib import request from bs4 import BeautifulSoup import re url = ‘http://www.baidu.com/‘ rsp = request.urlopen(url) content = rsp.read() soup = BeautifulSoup(content, ‘lxml‘) # bs 自動解碼 content = soup.prettify() # 使用 find_all # 使用 name 參數 print("=="*12) tags = soup.find_all(name=‘link‘) for i in tags: print(i) # 使用正則表達式 print("=="*12) # 同時使用兩個條件 tags = soup.find_all(re.compile(‘^me‘), content=‘always‘) # 這裏直接打印 tags 會打印一個列表 for i in tags: print(i)
運行結果
因為使用兩個條件,所以只匹配到一條 meta
下一篇介紹,BeautifulSoup 的 css 選擇器
拜拜
- 本筆記不允許任何個人和組織轉載
Python爬蟲教程-24-數據提取-BeautifulSoup4(二)