
單頁應用SPA做SEO的一種清奇的方案
單頁應用SPA做SEO的一種清奇的方案
網上有好幾種單頁應用轉seo的方案,有服務端渲染ssr、有預渲染prerender、google抓AJAX、靜態化。。。這些方案都各有優劣,開發者可以根據不同的業務場景和環境決定用哪一種方案。本文將介紹另一種思路比較清奇的SEO方案,這個方案也是有優有劣,就看讀者覺得適不適合了。
項目分析
我的項目是用react+ts+dva技術棧搭建的單頁應用,目前在線上已經有幾十個頁面,若幹個sdk和插件在裏面。
- 考慮想用服務端渲染來做seo,但是我的項目已經開發了這麽多,打包配置、代碼分割、語法兼容、摒棄瀏覽器對象,服務端思想,這麽多的點需要考慮,還不如換個框架重新開發呢,所以改造成本太大??,服務端渲染不適合我這種情況。
- 預渲染雖然是開發成本最低的,但畢竟是生成一張一張的靜態html,而我的seo需求是能夠讓蜘蛛抓取到我的社區論壇下的每一篇帖子,這樣子下來一篇帖子就是一份html,再加上分頁,那得多大的量級來存儲啊??,而且網站更新就更麻煩了,這個方案也不太適合。
- google.....Emmmm.........................下一個
- 靜態化也是跟預渲染差不多。。。
隆重介紹
以前寫過一種單頁應用seo的方案,就是自己先在本地用爬蟲做預渲染,生成同樣目錄結構的靜態化的html,前端項目服務器判斷請求的UA是搜索引擎蜘蛛的話就會轉發到我事先靜態化過的html頁面
當時的項目只是一個簡單的只有幾個頁面的企業官網,預渲染沒啥問題。
跟著這個思路,只要判斷搜索引擎蜘蛛讓蜘蛛看到另一個有數據的頁面不就行了。
至於頁面長什麽樣,蜘蛛??才不會管呢,就像是你找廣告商投放廣告,廣告商不會要求你要怎樣的主題什麽色調,只要你按照他的尺寸和要求來做,然後給錢給貨就完事了??。
所以可以針對SEO做另一套網站,沒有樣式,只有符合seo規範的html標簽和對應的數據,不需要在原有項目上改造,開發成本也不會很高,體積小加載速度更快。
缺點也有,就是需要另外維護一套網站,主網站界面變化不會影響,如果展示數據有變化就需要同步修改seo版的網站。
代碼實現
先建個單獨的seo文件夾,不需要動到原有項目,下面是代碼結構:
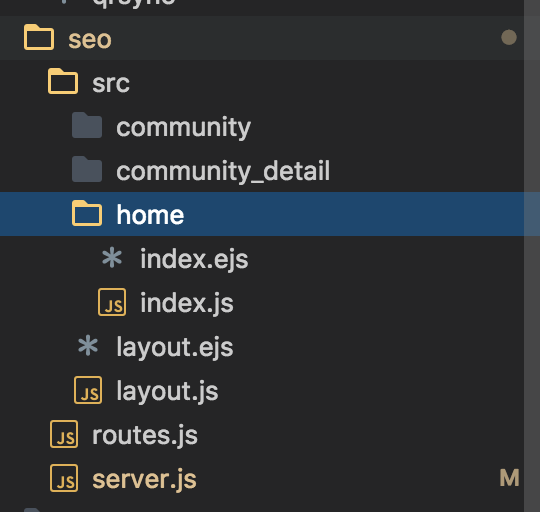
代碼實現非常之簡單,只要寫一個中間件攔截請求,鑒別蜘蛛,返回對應路徑的seo頁面即可。
我的前端服務器是用express,可以寫個express的中間件, 新建server.js:
// seo/server.js
const routes = require(‘./routes‘)
const layout_render = require(‘./src/layout‘);
module.exports = (req, res, next) => {
// 各大搜索引擎蜘蛛UA
const spiderUA = /Baiduspider|bingbot|Googlebot|360spider|Sogou|Yahoo! Slurp/
var isSpider = spiderUA.test(req.get(‘user-agent‘))
// 獲取路由表的路徑
var seoPath = Object.keys(routes)
if (isSpider) {
for (let i=0,route; route = seoPath[i]; i++) {
if (new RegExp(route).test(req.path)) {
routes[route](req).then((result) => {
// 返回對應的模板結果給蜘蛛
res.set({‘Content-Type‘: ‘text/html‘,‘charset‘: ‘utf-8mb4‘}).status(200).send(layout_render(result))
})
break;
}
}
} else {
// 未匹配到蜘蛛則繼續後面的中間件
return next()
}
}然後在前端的啟動服務器裏加入這個中間件,記得要放在其他中間件之前
// 前端啟動服務器的server文件
var express = require(‘express‘)
var app = express()
// seo
app.use(require(‘seo/server‘));
......
app.listen(xxxx)接下來就是寫模板和對應的解析了, 新建一個home文件夾,文件夾下再建一個index.ejs和index.js
<!-- seo/src/home/index.ejs -->
<div>
<h1>官網首頁</h1>
<p>友情鏈接:</p>
<p><a href="https://www.baidu.com/" target="_blank">百度</a></p>
<p><a href="https://www.gogole.com/" target="_blank">谷歌</a></p>
</div>index.js用於解析對應的ejs模板
// seo/src/home/index.js
const ejs = require(‘ejs‘)
const fs = require(‘fs‘)
const path = require(‘path‘)
const template = fs.readFileSync(path.resolve(__dirname, ‘./index.ejs‘), ‘utf8‘);
// 這裏為什麽會有個async關鍵字,往後面看就可以知道。
module.exports = async (req) => {
const result = ejs.render(template)
return result
}我們還可以建多個layout模板來管理head、title和導航欄這些公有的元素
<!-- seo/layout.ejs -->
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="content-type" content="text/html;charset=utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name=”renderer” content=”webkit”>
<meta content="網站關鍵字"" name="keywords"/>
<meta content="網站描述" name="description"/>
<title>網站標題</title>
</head>
<body>
<div id="root">
<ul>
<li><a href="/">首頁</a></li>
<li><a href="/community">社區</a></li>
</ul>
<%- children -%>
</div>
</body>
</html>解析layout.ejs,套入內容的layout_render:
// seo/layout.js
const ejs = require(‘ejs‘)
const fs = require(‘fs‘)
const path = require(‘path‘)
const template = fs.readFileSync(path.resolve(__dirname, ‘./layout.ejs‘), ‘utf8‘);
const layout_render = (children) => {
return ejs.render(template, {children: children})
}
module.exports = layout_render路由表用簡單的鍵值對就可以了,鍵名用字符串形式的正則來表示路徑的匹配規則:
// seo/routes.js
const home_route = require(‘./src/home/index‘)
module.exports = {
‘^(/?)$‘: home_route,
}那麽數據如何做請求並展示到對應的模板內呢?數據請求是異步的,怎樣等到請求完成再渲染模板呢?
我們可以用async/await來實現,現在來做一個社區的帖子列表頁面,需要先請求社區下帖子列表數據再把數據渲染到模板,新建一個community文件夾,同樣再建一個index.ejs作為帖子列表頁面模板:
<!-- seo/src/community/index.ejs -->
<div>
<h1>帖子列表</h1>
<ul>
<% forum_list.map((item) => { %>
<li><a href="/community/<%= item.id%>" target="_blank"><%= item.title-%></a></li>
<% })%>
</ul>
</div>相關的接口請求及數據操作寫在同級的index.js:
// seo/src/community/index.js
const ejs = require(‘ejs‘)
const fs = require(‘fs‘)
const path = require(‘path‘)
const template = fs.readFileSync(path.resolve(__dirname, ‘./index.ejs‘), ‘utf8‘);
const axios = require(‘axios‘);
module.exports = async (req) => {
const res = await axios.get(‘http://xxx.xx/api/community/list‘)
const result = ejs.render(template, {forum_list: res.data.list})
return result
}
這樣就實現了先取接口數據再做渲染,保證了蜘蛛訪問能給到完整的數據和html結構。
繼續實現一個帖子詳情的頁面:
<!-- seo/src/community_detail/index.ejs -->
<div>
<h1><%= forum_data.title%></h1>
<p><%= forum_data.content%></p>
<p>作者:<%= forum_data.user.nickname%></p>
</div>// seo/src/community_detail/index.js
const ejs = require(‘ejs‘)
const fs = require(‘fs‘)
const path = require(‘path‘)
const template = fs.readFileSync(path.resolve(__dirname, ‘./index.ejs‘), ‘utf8‘);
const axios = require(‘axios‘);
module.exports = async (req) => {
const forum_id = req.path.split(‘/‘)[2]
const res = await axios.get(`http://xxx.xx/api/community/${forum_id}/details?offset=1&limit=10`)
const result = ejs.render(template, {forum_data: res.data})
return result
}這樣就實現了一個簡單的seo版網站,不需要任何樣式,不需要js做彈框之類的後續交互,只要蜘蛛訪問網址的第一個請求有它要的數據即可,是不是非常的清奇??。。。
總結來說呢,就是如果你的項目處在線上運營階段並且開發到了一定的集成度了,迫於ssr的改造成本太大,又需要讓一些數據(比如每一篇文章帖子)能夠被收錄,就可以考慮一下我的這個方法??。
但是我不保證蜘蛛的防作弊機制,會不會過濾掉我這種跟瀏覽器正常訪問主站差異較大的seo版小網站??。目前這個方案還在試驗階段。
測試
測試也很簡單,寫個模擬蜘蛛請求即可,curl、爬蟲、postman都可以模擬蜘蛛的UA來測試。或者改一下搜索引擎蜘蛛的的判斷條件就可以直接用瀏覽器訪問的呢。
如果有朋友用了我這個方法並且真的有用能夠被搜索引擎收錄的話,請記得我??,要是能打賞就更好了哈哈??。
單頁應用SPA做SEO的一種清奇的方案