
軟工第二次作業
阿新 • • 發佈:2018-09-12
依賴項 get nal 為我 結構 進步 cnblogs lag tro
github

解題思路
剛拿到題目,我先看了幾遍,大致的了解題目的含義。因為有些工具不會使用,如vs2017,我就先去學習工具的使用了。從工具的配置以及大致的使用過程,我都通過上網查資料以及詢問同學。查資料以及學習資料的過程花費了我不少的時間,但有很大的收獲,起碼我些許懂得如何使用當下最時髦的編譯軟件。至於編碼,因為我的代碼能力較弱,我一開始沒有自己動手打,而是去網上找了一個和題目有相似性的c代碼,自己再將c改成了c++,還補充了一些功能上去,雖然還是有bug,但是編譯過了,我也有些許安慰。
設計實現過程
以下是我的流程圖

單元測試功能因為代碼有bug,然後沒有通過,不過知道怎麽設置附加依賴項。

性能分析
由於自己水準不夠,代碼沒有實現全部的功能,所以我就只是嘗試了一下什麽是性能分析功能,不過我會利用課余時間,拿一段簡單易實現的代碼,去測試一下分析功能。

代碼說明
void readfile(struct word * &head) { FILE *fp; linecount l;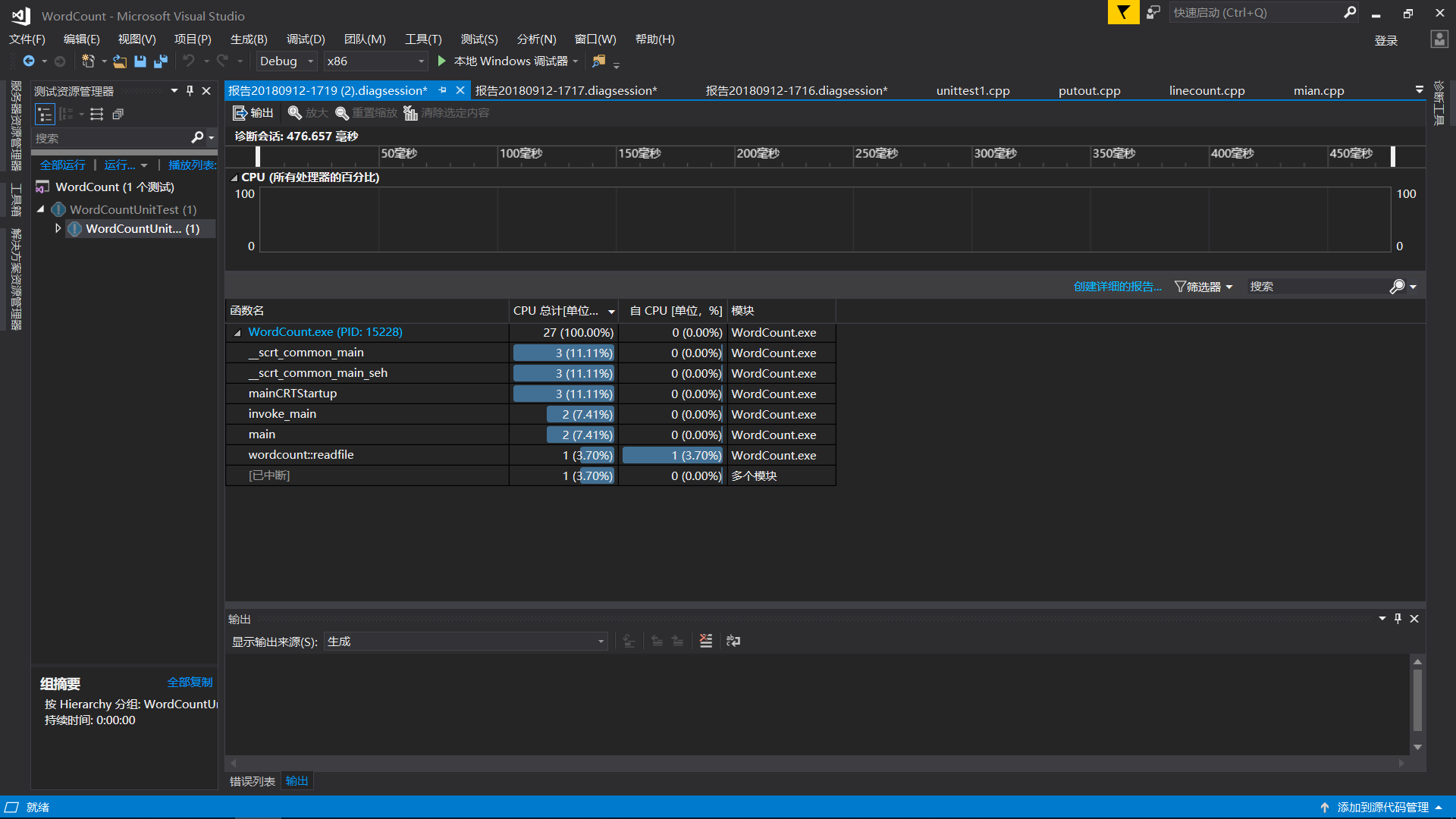 if ((fp = fopen("in.txt" ,"r") )== NULL) { printf("無法打開此文件!\n"); exit(0); } while (!feof(fp)) { int i = 0; ch = fgetc(fp); if (ch != 32 && ch != 10 && ch != 9) flag1 = 1; temp[0] = ‘ ‘; //保證單詞的開始一定是有效字符 do { charnum++; //統計字符數 if (ch >= ‘a‘&&ch <= ‘z‘ || ch >= ‘A‘&&ch <= ‘Z‘ || ch >= ‘0‘&&ch <= ‘9‘) { if (ch >= ‘A‘&&ch <= ‘Z‘) //大寫化小寫 { temp[i] = ch - 32; i++; } else { temp[i] = ch; i++; } if (i <= 3 && ch >= ‘0‘&&ch <= ‘9‘) flag = 0; //如果字符序列前四個有數字則不算單詞 } ch = fgetc(fp); if (ch != 32 && ch != 10 && ch != 9) flag1 = 1; if (ch = 10) { l.line(flag1); flag1 = 0; } if (feof(fp)) { charnum--; //多加了一個EOF break; } } while (ch >= ‘a‘&&ch <= ‘z‘ || ch >= ‘A‘&&ch <= ‘Z‘ || ch >= ‘0‘&&ch <= ‘9‘ || temp[0] == ‘ ‘); charnum++; temp[i] = ‘\0‘; p = head->next; while (p) //舊單詞,詞頻加1 { if (!strcmp(temp, p->name)) { p->num++; wordnum++; break; } p = p->next; } if (!p&&temp[0] != ‘\0‘&&flag == 1) //新單詞存入鏈表 { p = new word; strcpy_s(p->name, temp); p->num = 1; wordnum++; p->next = head->next; head->next = p; } flag = 1; } } };
以上就是我的核心代碼。我的思路是通過逐個字符的讀取文本文件,將相似於單詞的字符串存入一個字符數組,然後在通過一個判斷,判斷這個字符串是不是單詞,是就存儲進結構體鏈表中。
心得體會
這次的實踐,由於c++使用的較少,然後也是初次使用vs2017,我的代碼實現挺糟糕的,只完成字符的統計功能。如果是用c寫的話到可以完成全部的功能,由於時間問題我是不能在deadline之前實現全部功能,之後自己會找時間改進自己的代碼,讓自己能收獲到更多,總之讓我自己意識到自己的代碼水平有很大的進步空間。然後就是上網學習資料,我覺得這獲得知識都是比較實用,多看看別人的博客對自己也是有很大的提升。還有就是以前從來沒有很系統的為一道題目做很系統的安排計劃,這次實踐讓我感覺到有一個系統的過程會省事h很多。
軟工第二次作業