
Spark on Yarn作業運行架構原理解析
阿新 • • 發佈:2018-10-07
狀態 區別 通訊 含義 啟動應用 follow 關於 containe yar [TOC]
0 前言
可以先參考之前寫的《Yarn流程、Yarn與MapReduce 1相比》,之後再參考《Spark作業運行架構原理解析》,然後再閱讀下面的內容,就很容易理解了。
下面內容參考:https://blog.csdn.net/gamer_gyt/article/details/51833681
1 Client模式
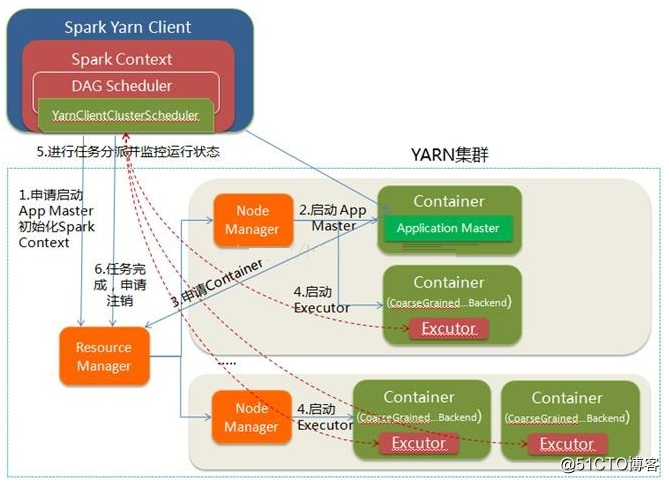
說明如下:
- Spark Yarn Client向YARN的ResourceManager申請啟動Application Master。同時在SparkContent初始化中將創建DAGScheduler和TASKScheduler等,由於我們選擇的是Yarn-Client模式,程序會選擇YarnClientClusterScheduler和YarnClientSchedulerBackend;
- ResourceManager收到請求後,在集群中選擇一個NodeManager,為該應用程序分配第一個Container,要求它在這個Container中啟動應用程序的ApplicationMaster,與YARN-Cluster區別的是在該ApplicationMaster不運行SparkContext,只與SparkContext進行聯系進行資源的分派;
- Client中的SparkContext初始化完畢後,與ApplicationMaster建立通訊,向ResourceManager註冊,根據任務信息向ResourceManager申請資源(Container);
- 一旦ApplicationMaster申請到資源(也就是Container)後,便與對應的NodeManager通信,要求它在獲得的Container中啟動CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend啟動後會向Client中的SparkContext註冊並申請Task;
- client中的SparkContext分配Task給CoarseGrainedExecutorBackend執行,CoarseGrainedExecutorBackend運行Task並向Driver匯報運行的狀態和進度,以讓Client隨時掌握各個任務的運行狀態,從而可以在任務失敗時重新啟動任務;
- 應用程序運行完成後,Client的SparkContext向ResourceManager申請註銷並關閉自己;
2 Cluster模式
在YARN-Cluster模式中,當用戶向YARN中提交一個應用程序後,YARN將分兩個階段運行該應用程序:
-
1.第一個階段是把Spark的Driver作為一個ApplicationMaster在YARN集群中先啟動;
- 2.第二個階段是由ApplicationMaster創建應用程序,然後為它向ResourceManager申請資源,並啟動Executor來運行Task,同時監控它的整個運行過程,直到運行完成
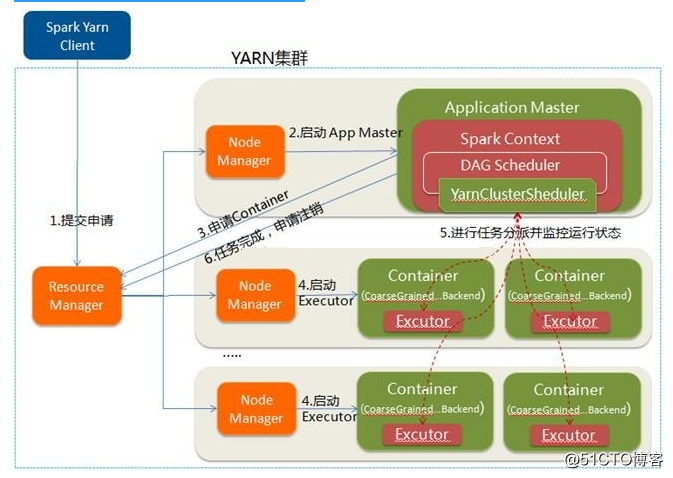
說明如下:
- Spark Yarn Client向YARN中提交應用程序,包括ApplicationMaster程序、啟動ApplicationMaster的命令、需要在Executor中運行的程序等;
- ResourceManager收到請求後,在集群中選擇一個NodeManager,為該應用程序分配第一個Container,要求它在這個Container中啟動應用程序的ApplicationMaster,其中ApplicationMaster進行SparkContext等的初始化;
- ApplicationMaster向ResourceManager註冊,這樣用戶可以直接通過ResourceManage查看應用程序的運行狀態,然後它將采用輪詢的方式通過RPC協議為各個任務申請資源,並監控它們的運行狀態直到運行結束;
- 一旦ApplicationMaster申請到資源(也就是Container)後,便與對應的NodeManager通信,要求它在獲得的Container中啟動CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend啟動後會向ApplicationMaster中的SparkContext註冊並申請Task。這一點和Standalone模式一樣,只不過SparkContext在Spark Application中初始化時,使用CoarseGrainedSchedulerBackend配合YarnClusterScheduler進行任務的調度,其中YarnClusterScheduler只是對TaskSchedulerImpl的一個簡單包裝,增加了對Executor的等待邏輯等;
- ApplicationMaster中的SparkContext分配Task給CoarseGrainedExecutorBackend執行,CoarseGrainedExecutorBackend運行Task並向ApplicationMaster匯報運行的狀態和進度,以讓ApplicationMaster隨時掌握各個任務的運行狀態,從而可以在任務失敗時重新啟動任務;
- 應用程序運行完成後,ApplicationMaster向ResourceManager申請註銷並關閉自己;
3 Client模式 vs Cluster模式
- 理解YARN-Client和YARN-Cluster深層次的區別之前先清楚一個概念:Application Master。在YARN中,每個Application實例都有一個ApplicationMaster進程,它是Application啟動的第一個容器。它負責和ResourceManager打交道並請求資源,獲取資源之後告訴NodeManager為其啟動Container。從深層次的含義講YARN-Cluster和YARN-Client模式的區別其實就是ApplicationMaster進程的區別;
- YARN-Cluster模式下,Driver運行在AM(Application Master)中,它負責向YARN申請資源,並監督作業的運行狀況。當用戶提交了作業之後,就可以關掉Client,作業會繼續在YARN上運行,因而YARN-Cluster模式不適合運行交互類型的作業;
- YARN-Client模式下,Application Master僅僅向YARN請求Executor,Client會和請求的Container通信來調度他們工作,也就是說Client不能離開;
xpleaf Note:因為在Spark作業運行過程中,一般情況下會有大量數據在Driver和集群中進行交互,所以如果是基於yarn-client的模式,則會在程序運行過程中產生大量的網絡數據傳輸,造成網卡流量激增;而基於yarn-cluster這種模式,因為driver本身就在集群內部,所以數據的傳輸也是在集群內部來完成,那麽網絡傳輸壓力相對要小;所以在企業生產環境下多使用yarn-cluster這種模式,測試多用yarn-client這種模式。但是帶來一個問題,就是不方便監控日誌,yarn-cluster這種模式要想監控日誌,必須要到每一臺機器上面去查看,但這都不是問題,因為我們有sparkUI,同時也有各種各樣的日誌監控組件(可以參考前面寫的關於Spark日誌監控的文章)。
Spark on Yarn作業運行架構原理解析