
Apache Hadoop YARN
Apache Hadoop YARN (Yet Another Resource Negotiator,另一種資源協調者)是一種新的 Hadoop 資源管理器,它是一個通用資源管理系統和調度平臺,可為上層應用提供統一的資源管理和調度,它的引入為集群在利用率、資源統一管理和數據共享等方面帶來了巨大好處。
可以把yarn理解為相當於一個分布式的操作系統平臺,而mapreduce等運算程序則相當於運行於操作系統之上的應用程序,Yarn為這些程序提供運算所需的資源(內存、cpu)。
l yarn並不清楚用戶提交的程序的運行機制
l yarn只提供運算資源的調度(用戶程序向yarn申請資源,yarn就負責分配資源)
l yarn中具體提供運算資源的角色叫NodeManager
l yarn與運行的用戶程序完全解耦,意味著yarn上可以運行各種類型的分布式運算程序,比如mapreduce、storm,spark,tez ……
l spark、storm等運算框架都可以整合在yarn上運行,只要他們各自的框架中有符合yarn規範的資源請求機制即可
l yarn成為一個通用的資源調度平臺.企業中以前存在的各種運算集群都可以整合在一個物理集群上,提高資源利用率,方便數據共享
2.Yarn基本架構
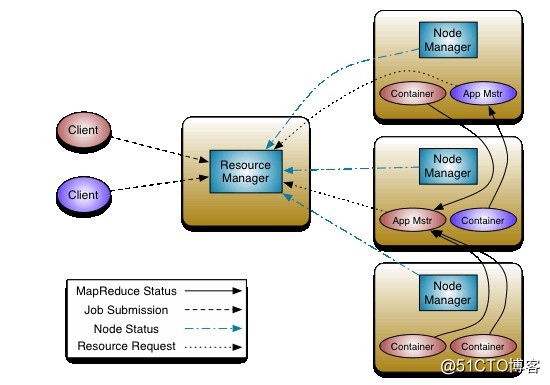
YARN是一個資源管理、任務調度的框架,主要包含三大模塊:ResourceManager(RM)、NodeManager(NM)、ApplicationMaster(AM)。
ApplicationMaster負責每一個具體應用程序的調度和協調;
NodeManager負責每一個節點的維護。
對於所有的applications,RM擁有絕對的控制權和對資源的分配權。而每個AM則會和RM協商資源,同時和NodeManager通信來執行和監控task。
3. Yarn三大組件介紹3.1. ResourceManager
l ResourceManager負責整個集群的資源管理和分配,是一個全局的資源管理系統。
l NodeManager以心跳的方式向ResourceManager匯報資源使用情況(目前主要是CPU和內存的使用情況)。RM只接受NM的資源回報信息,對於具體的資源處理則交給NM自己處理。
3.2. NodeManager
l NodeManager是每個節點上的資源和任務管理器,它是管理這臺機器的代理,負責該節點程序的運行,以及該節點資源的管理和監控。YARN集群每個節點都運行一個NodeManager。
l NodeManager定時向ResourceManager匯報本節點資源(CPU、內存)的使用情況和Container的運行狀態。當ResourceManager宕機時NodeManager自動連接RM備用節點。
l NodeManager接收並處理來自ApplicationMaster的Container啟動、停止等各種請求。
3.3. ApplicationMaster
l 用戶提交的每個應用程序均包含一個ApplicationMaster,它可以運行在ResourceManager以外的機器上。
l 負責與RM調度器協商以獲取資源(用Container表示)。
l 將得到的任務進一步分配給內部的任務(資源的二次分配)。
l 與NM通信以啟動/停止任務。
l 監控所有任務運行狀態,並在任務運行失敗時重新為任務申請資源以重啟任務。
l 當前YARN自帶了兩個ApplicationMaster實現,一個是用於演示AM編寫方法的實例程序DistributedShell,它可以申請一定數目的Container以並行運行一個Shell命令或者Shell腳本;另一個是運行MapReduce應用程序的AM—MRAppMaster。
註:RM只負責監控AM,並在AM運行失敗時候啟動它。RM不負責AM內部任務的容錯,任務的容錯由AM完成。
4. Yarn運行流程
l client向RM提交應用程序,其中包括啟動該應用的ApplicationMaster的必須信息,例如ApplicationMaster程序、啟動ApplicationMaster的命令、用戶程序等。
l ResourceManager啟動一個container用於運行ApplicationMaster。
l 啟動中的ApplicationMaster向ResourceManager註冊自己,啟動成功後與RM保持心跳。
l ApplicationMaster向ResourceManager發送請求,申請相應數目的container。
l ResourceManager返回ApplicationMaster的申請的containers信息。申請成功的container,由ApplicationMaster進行初始化。container的啟動信息初始化後,AM與對應的NodeManager通信,要求NM啟動container。AM與NM保持心跳,從而對NM上運行的任務進行監控和管理。
l container運行期間,ApplicationMaster對container進行監控。container通過RPC協議向對應的AM匯報自己的進度和狀態等信息。
l 應用運行期間,client直接與AM通信獲取應用的狀態、進度更新等信息。
l 應用運行結束後,ApplicationMaster向ResourceManager註銷自己,並允許屬於它的container被收回。
5. Yarn 調度器Scheduler
理想情況下,我們應用對Yarn資源的請求應該立刻得到滿足,但現實情況資源往往是有限的,特別是在一個很繁忙的集群,一個應用資源的請求經常需要等待一段時間才能的到相應的資源。在Yarn中,負責給應用分配資源的就是Scheduler。其實調度本身就是一個難題,很難找到一個完美的策略可以解決所有的應用場景。為此,Yarn提供了多種調度器和可配置的策略供我們選擇。
在Yarn中有三種調度器可以選擇:FIFO Scheduler ,Capacity Scheduler,Fair Scheduler。
5.1. FIFO Scheduler
FIFO Scheduler把應用按提交的順序排成一個隊列,這是一個先進先出隊列,在進行資源分配的時候,先給隊列中最頭上的應用進行分配資源,待最頭上的應用需求滿足後再給下一個分配,以此類推。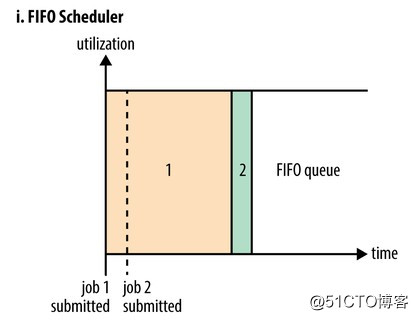
FIFO Scheduler是最簡單也是最容易理解的調度器,也不需要任何配置,但它並不適用於共享集群。大的應用可能會占用所有集群資源,這就導致其它應用被阻塞。在共享集群中,更適合采用Capacity Scheduler或Fair Scheduler,這兩個調度器都允許大任務和小任務在提交的同時獲得一定的系統資源。
5.2. Capacity Scheduler
Capacity 調度器允許多個組織共享整個集群,每個組織可以獲得集群的一部分計算能力。通過為每個組織分配專門的隊列,然後再為每個隊列分配一定的集群資源,這樣整個集群就可以通過設置多個隊列的方式給多個組織提供服務了。除此之外,隊列內部又可以垂直劃分,這樣一個組織內部的多個成員就可以共享這個隊列資源了,在一個隊列內部,資源的調度是采用的是先進先出(FIFO)策略。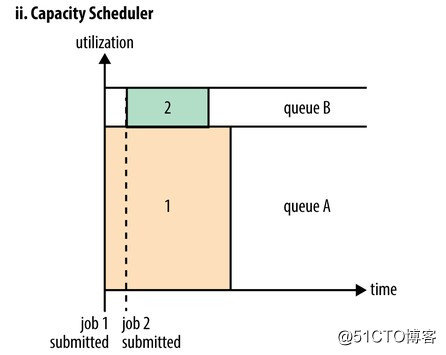
5.3. Fair Scheduler
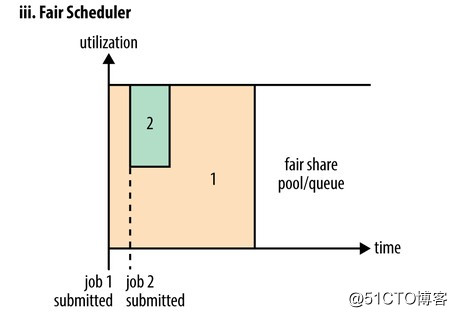
在Fair調度器中,我們不需要預先占用一定的系統資源,Fair調度器會為所有運行的job動態的調整系統資源。如下圖所示,當第一個大job提交時,只有這一個job在運行,此時它獲得了所有集群資源;當第二個小任務提交後,Fair調度器會分配一半資源給這個小任務,讓這兩個任務公平的共享集群資源。
需要註意的是,在下圖Fair調度器中,從第二個任務提交到獲得資源會有一定的延遲,因為它需要等待第一個任務釋放占用的Container。小任務執行完成之後也會釋放自己占用的資源,大任務又獲得了全部的系統資源。最終效果就是Fair調度器即得到了高的資源利用率又能保證小任務及時完成。
5.4. 示例:Capacity調度器配置使用
調度器的使用是通過yarn-site.xml配置文件中的
yarn.resourcemanager.scheduler.class參數進行配置的,默認采用Capacity Scheduler調度器。
假設我們有如下層次的隊列:
root
├── prod
└── dev
├── mapreduce
└── spark
下面是一個簡單的Capacity調度器的配置文件,文件名為capacity-scheduler.xml。在這個配置中,在root隊列下面定義了兩個子隊列prod和dev,分別占40%和60%的容量。需要註意,一個隊列的配置是通過屬性yarn.sheduler.capacity.<queue-path>.<sub-property>指定的,<queue-path>代表的是隊列的繼承樹,如root.prod隊列,<sub-property>一般指capacity和maximum-capacity。
<configuration>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>prod,dev</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.queues</name>
<value>mapreduce,spark</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.prod.capacity</name>
<value>40</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.capacity</name>
<value>60</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.maximum-capacity</name>
<value>75</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.mapreduce.capacity</name>
<value>50</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.spark.capacity</name>
<value>50</value>
</property>
</configuration>我們可以看到,dev隊列又被分成了mapreduce和spark兩個相同容量的子隊列。dev的maximum-capacity屬性被設置成了75%,所以即使prod隊列完全空閑dev也不會占用全部集群資源,也就是說,prod隊列仍有25%的可用資源用來應急。我們註意到,mapreduce和spark兩個隊列沒有設置maximum-capacity屬性,也就是說mapreduce或spark隊列中的job可能會用到整個dev隊列的所有資源(最多為集群的75%)。而類似的,prod由於沒有設置maximum-capacity屬性,它有可能會占用集群全部資源。
關於隊列的設置,這取決於我們具體的應用。比如,在MapReduce中,我們可以通過mapreduce.job.queuename屬性指定要用的隊列。如果隊列不存在,我們在提交任務時就會收到錯誤。如果我們沒有定義任何隊列,所有的應用將會放在一個default隊列中。
註意:對於Capacity調度器,我們的隊列名必須是隊列樹中的最後一部分,如果我們使用隊列樹則不會被識別。比如,在上面配置中,我們使用prod和mapreduce作為隊列名是可以的,但是如果我們用root.dev.mapreduce或者dev. mapreduce是無效的。
Apache Hadoop YARN