
Apache Hadoop YARN: 背景及概述
從2012年8月開始Apache Hadoop YARN(YARN = Yet Another Resource Negotiator)成了Apache Hadoop的一項子工程。自此Apache Hadoop由下面四個子工程組成:
- Hadoop Comon:核心庫,為其他部分服務
- Hadoop HDFS:分散式儲存系統
- Hadoop MapReduce:MapReduce模型的開源實現
- Hadoop YARN:新一代Hadoop資料處理框架
概括來說,Hadoop YARN的目的是使得Hadoop資料處理能力超越MapReduce。眾所周知,Hadoop HDFS是Hadoop的資料儲存層,Hadoop MapReduce是資料處理層。然而,MapReduce已經不能滿足今天廣泛的資料處理需求,如實時/準實時計算,圖計算等。而Hadoop YARN提供了一個更加通用的資源管理和分散式應用框架。在這個框架上,使用者可以根據自己需求,實現定製化的資料處理應用。而Hadoop MapReduce也是YARN上的一個應用。我們將會看到MPI,圖處理,線上服務等(例如
傳統的Apache Hadoop MapReduce架構
傳統的Apache Hadoop MapReduce系統由JobTracker和TaskTracker組成。其中JobTracker是master,只有一個;TaskTracker是slaves,每個節點部署一個。
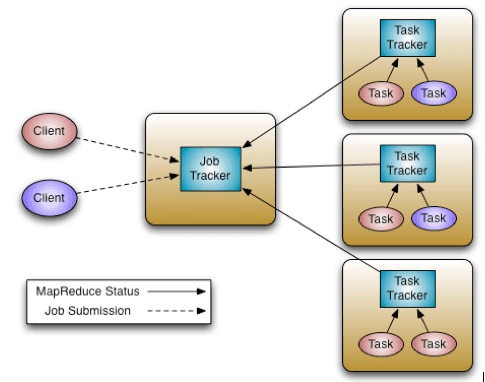
圖 1 Apache Hadoop MapReduce系統架構
JobTracker負責資源管理(通過管理TaskTracker節點),追蹤資源消費/釋放,以及Job的生命週期管理(排程Job的每個Task,追蹤Task進度,為Task提供容錯等)。而TaskTracker的職責很簡單,依次啟動和停止由JobTracker分配的Task,並且週期性的向JobTracker彙報Task進度及狀態資訊。
Apache Hadoop YARN架構
YARN的最基本思想是將JobTracker的兩個主要職責:資源管理和Job排程管理分別交給兩個角色負責。一個是全域性的ResourceManager,一個是每個應用一個的ApplicationMaster。ResourceManager以及每個節點一個的NodeManager構成了新的通用系統,實現以分散式方式管理應用。
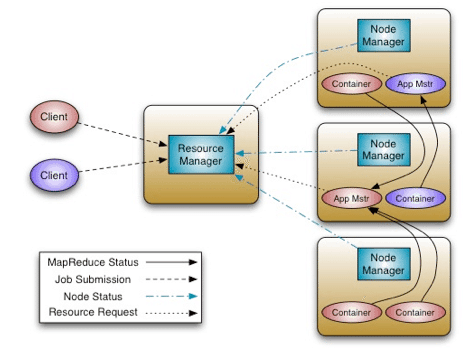
圖2 Apache Hadoop YARN架構
ResourceManager是系統中仲裁應用之間資源分配的最高權威。而每個應用一個的ApplicationMaster負責向ResourceManager協商資源,並與NodeManager協同工作來執行和管理task。ResourceManager有一個可插入的排程器,負責向各個應用分配資源以滿足容量,組等限制。這個排程器是一個純粹的排程器,意思是它不負責管理或追蹤應用的狀態,也不負責由於硬體錯誤或應用問題導致的task失敗重啟工作。排程器只依據應用的資源需求來執行排程工作,排程內容是一個抽象概念Resource Container,其中包含了資源元素,例如記憶體,CPU,網路,磁碟等。
NodeManager是每個節點一個的slave,其負責啟動應用的container,管理他們的資源使用(記憶體,CPU,網路,磁碟),並向ResourceManager彙報整體的資源使用情況。
每個應用一個的ApplicationMaster負責向ResourceManager的排程器協商合理的Resource Container並追蹤他們的狀態,管理進度。從系統角度看,ApplicationMaster本身也是以一個普通container的形式執行。
總結
由於MapReduce在計算模型方面的侷限性,Hadoop實現了更加通用的資源管理系統YARN,並將MapReduce作為其一個應用。在YARN上可以實現多種多樣計算模型的應用以滿足業務需要。另外由於YARN系統將JobTracker的主要工作進行切分,使得master的壓力大大減小(ResourceManager承擔的工作量遠小於JobTracker),這樣YARN系統就可以支援更大的叢集規模。
相關推薦
Apache Hadoop YARN: 背景及概述
從2012年8月開始Apache Hadoop YARN(YARN = Yet Another Resource Negotiator)成了Apache Hadoop的一項子工程。自此Apache Hadoop由下面四個子工程組成: Hadoop Comon:核心庫,為其他
Apache Hadoop YARN
延遲 用戶 時間 心跳 屬性 直接 選擇 方便 orm 1. Yarn通俗介紹Apache Hadoop YARN (Yet Another Resource Negotiator,另一種資源協調者)是一種新的 Hadoop 資源管理器,它是一個通用資源管理系統和調度平臺,
Apache Hadoop YARN (官網文章)
yarn的根本目標是為了分散資源管理還有任務排程以及監視功能到分離的守護程序。這個目的是擁有一個全域性ResourceManager 和每個應用程式。 應用程式可以是單個作業,也可以是作業的DAG。 resource manager和node manager 構成了資料計算框架。 reso
Hadoop Yarn 框架原理及運作機制
1.1 YARN 基本架構 YARN是Hadoop 2.0中的資源管理系統,它的基本設計思想是將MRv1中的JobTracker拆分成了兩個獨立的服務:一個全域性的資源管理器ResourceManager和每個應用程式特有的ApplicationMaster。 其中Res
hadoop寫MR程式報錯java.lang.AbstractMethodError: org.apache.hadoop.yarn.api.records.LocalResource.setShou
情況:在本地書寫mapreduce的時候,執行driver類 開始跑任務的時候,有時候可能會報 java.lang.AbstractMethodError: org.apache.hadoop.yarn.api.records.LocalResource.setShouldBeUploadedT
hadoop解決Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/yarn/util/Apps
linux+eclipse+本地執行WordCount丟擲下面異常: Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/yarn/util/Apps。 解決:沒有把yar
hadoop錯誤org.apache.hadoop.yarn.exceptions.YarnException Unauthorized request to start container
錯誤: 17/11/22 15:17:15 INFO client.RMProxy: Connecting to ResourceManager at Master/192.168.136.100:8032 17/11/22 15:17:16 INFO input.Fil
Hadoop YARN:排程效能優化實踐
背景 YARN作為Hadoop的資源管理系統,負責Hadoop叢集上計算資源的管理和作業排程。 美團的YARN以社群2.7.1版本
【2017cs231n斯坦福李飛飛視覺識別】筆記-第1講:計算機視覺概述及歷史背景
課時1 計算機視覺概述 什麼是計算機視覺? 計算機視覺:針對視覺資料的研究。 在我們的世界中,就在過去的短短几年,視覺資料量爆炸式的增長到誇張的地步,這一點很大程度上得益於世界上許許多多的視覺感測器,大家都有智慧手機,每個智慧手機都有一個、兩個、甚至3個攝像頭
hadoop初識之三:搭建hadoop環境(配置HDFS,Yarn及mapreduce 執行在yarn)上及三種執行模式(本地模式,偽分散式和分散式介)
--===============安裝jdk(解壓版)================== --root 使用者登入 --建立檔案層級目錄 /opt下分別 建 modules/softwares/datas/tools 資料夾 --檢視是否安裝jdk rpm -
排查Hive報錯:org.apache.hadoop.hive.serde2.SerDeException: java.io.IOException: Start of Array expected
arr .json span 問題 catalog pan 不支持 led open CREATE TABLE json_nested_test ( count string, usage string, pkg map<string
eclipse執行mapereduce程式時報如下錯誤:org.apache.hadoop.io.nativeio.NativeIO$Windows.createDirectoryWithMode0(
eclipse執行mapereduce程式時報如下錯誤: log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory). log4j:WARN
Kafka 溫故(一):Kafka背景及架構介紹
一.Kafka簡介 Kafka是分散式釋出-訂閱訊息系統。它最初由LinkedIn公司開發,使用Scala語言編寫,之後成為Apache專案的一部分。Kafka是一個分散式的,可劃分的,多訂閱者,冗餘備份的永續性的日誌服務。它主要用於處理活躍的流式資料(
訪問HDFS報錯:org.apache.hadoop.security.AccessControlException: Permission denied
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; public class TestHDFS { publ
React native:(StatusBar)修改狀態列背景及文字顏色
在自定義導航欄得時候,狀態列得背景顏色和狀態列得顏色是不統一得,看起來很不協調,RN中文網找到了StatusBar,可以設定狀態列。https://reactnative.cn/docs/statusbar.html#docsNav 首先我定義了一些屬性得約束,狀態列只用到
hive MapJoin 異常 : return code 3 from org.apache.hadoop.hive.ql.exec.mr.MapredLocalTask
今天寫了一個hive sql,A表往B表插入資料,如果公共欄位id相同,則不插入,即不存在則插入,否則不插入,這樣一個sql,可是執行時報了記憶體異常, 具體資訊是: 2018-08-14 13:45:17 Starting to launch local task to pro
hadoop yarn記憶體的管理及分配
理解Yarn的記憶體管理與分配機制,對於我們搭建、部署叢集,開發維護應用都是尤為重要的,對於這方面我做了一些調研供大家參考。 關於Yarn的詳細介紹請參考【Hadoop(3)-Yarn叢集 】 一、相關配置情況 關於Yarn記憶體分配與管理,主要涉及到ResourceManage、Applica
hadoop備戰:yarn框架的搭建(mapreduce2)
author welcome start profile handler prope indent 好用 機器名 昨天沒有寫好了沒有更新。今天一起更新,yarn框架也是剛搭建好的。我
ml課程:聚類概述及K-means講解(含程式碼實現)
以下是我的學習筆記,以及總結,如有錯誤之處請不吝賜教。 本文主要介紹聚類以及K均值演算法的推倒過程,最後有相關程式碼案例。 說到聚類就不得不先說說機器學習的分類。 機器學習主要分為三類: 監督學習:分類、迴歸... 無監督學習:聚類、降維... 強化學習。
Rxjava2入門:函式響應式程式設計及概述
Rxjava2入門教程一:https://www.jianshu.com/p/15b2f3d7141a Rxjava2入門教程二:https://www.jianshu.com/p/c8150187714c Rxjava2入門教程三:https://www.jianshu.com/p/6e7