
Raft算法和Gossip協議
簡單介紹下集群數據同步,集群監控用到的兩種常見算法。
Raft算法
raft 集群中的每個節點都可以根據集群運行的情況在三種狀態間切換:follower, candidate 與 leader。leader 向 follower 同步日誌,follower 只從 leader 處獲取日誌。在節點初始啟動時,節點的 raft 狀態機將處於 follower 狀態並被設定一個 election timeout,如果在這一時間周期內沒有收到來自 leader 的 heartbeat,節點將發起選舉:節點在將自己的狀態切換為 candidate 之後,向集群中其它 follower 節點發送請求,詢問其是否選舉自己成為 leader。當收到來自集群中過半數節點的接受投票後,節點即成為 leader,開始接收保存 client 的數據並向其它的 follower 節點同步日誌。leader 節點依靠定時向 follower 發送 heartbeat 來保持其地位。任何時候如果其它 follower 在 election timeout 期間都沒有收到來自 leader 的 heartbeat,同樣會將自己的狀態切換為 candidate 並發起選舉。每成功選舉一次,新 leader 的步進數都會比之前 leader 的步進數大1。
Raft一致性算法處理日誌復制以保證強一致性。
follower 節點不可用
follower 節點不可用的情況相對容易解決。因為集群中的日誌內容始終是從 leader 節點同步的,只要這一節點再次加入集群時重新從 leader 節點處復制日誌即可。
leader 不可用
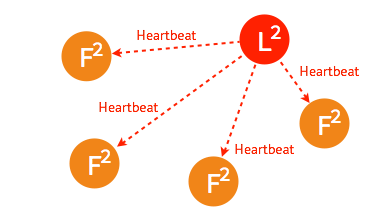
一般情況下,leader 節點定時發送 heartbeat 到 follower 節點。
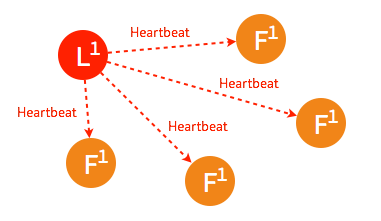
由於某些異常導致 leader 不再發送 heartbeat ,或 follower 無法收到 heartbeat 。
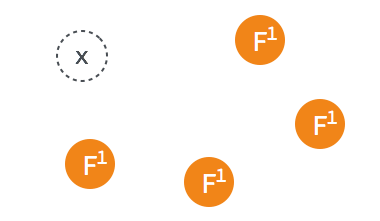
當某一 follower 發生 election timeout 時,其狀態變更為 candidate,並向其他 follower 發起投票。
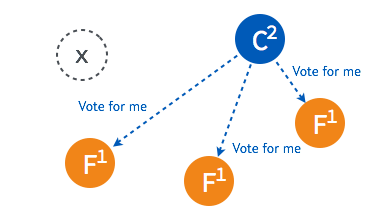
當超過半數的 follower 接受投票後,這一節點將成為新的 leader,leader 的步進數加1並開始向 follower 同步日誌。
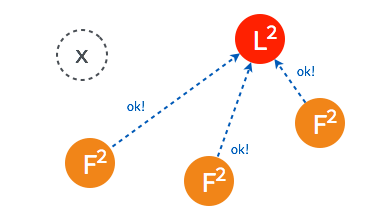
當一段時間之後,如果之前的 leader 再次加入集群,則兩個 leader 比較彼此的步進數,步進數低的 leader 將切換自己的狀態為 follower。
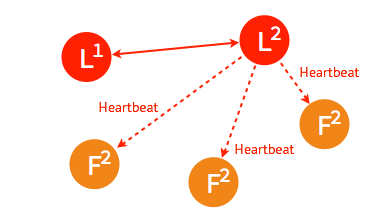
較早前 leader 中不一致的日誌將被清除,並與現有 leader 中的日誌保持一致。
Gossip協議
傳統的監控,如ceilometer,由於每個節點都會向server報告狀態,隨著節點數量的增加server的壓力隨之增大。分布式健康檢查可以解決這類性能瓶頸,降節點數量從數百臺擴至數千臺,甚至更多。
Agent在每臺節點上運行,可以在每個Agent上添加一些健康檢查的動作,Agent會周期性的運行這些動作。用戶可以添加腳本或者請求一個URL鏈接。一旦有健康檢查報告失敗,Agent就把這個事件上報給服務器節點。用戶可以在服務器節點上訂閱健康檢查事件,並處理這些報錯消息。
在所有的Agent之間(包括服務器模式和普通模式)運行著Gossip協議。服務器節點和普通Agent都會加入這個Gossip集群,收發Gossip消息。每隔一段時間,每個節點都會隨機選擇幾個節點發送Gossip消息,其他節點會再次隨機選擇其他幾個節點接力發送消息。這樣一段時間過後,整個集群都能收到這條消息。示意圖如下。
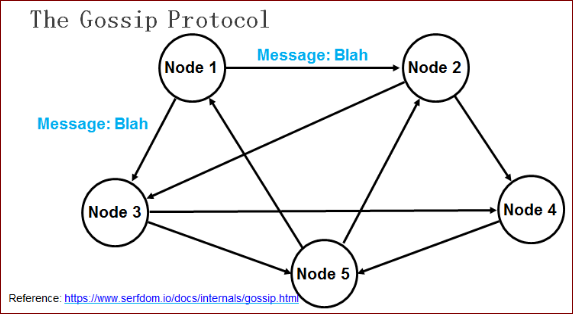
Gossip協議已經是P2P網絡中比較成熟的協議了。Gossip協議的最大的好處是,即使集群節點的數量增加,每個節點的負載也不會增加很多,幾乎是恒定的。這就允許Consul管理的集群規模能橫向擴展到數千個節點。
Consul的每個Agent會利用Gossip協議互相檢查在線狀態,本質上是節點之間互Ping,分擔了服務器節點的心跳壓力。如果有節點掉線,不用服務器節點檢查,其他普通節點會發現,然後用Gossip廣播給整個集群。
Gossip算法又被稱為反熵(Anti-Entropy),熵是物理學上的一個概念,代表雜亂無章,而反熵就是在雜亂無章中尋求一致,這充分說明了Gossip的特點:在一個有界網絡中,每個節點都隨機地與其他節點通信,經過一番雜亂無章的通信,最終所有節點的狀態都會達成一致。每個節點可能知道所有其他節點,也可能僅知道幾個鄰居節點,只要這些節可以通過網絡連通,最終他們的狀態都是一致的,當然這也是疫情傳播的特點。
要註意到的一點是,即使有的節點因宕機而重啟,有新節點加入,但經過一段時間後,這些節點的狀態也會與其他節點達成一致,也就是說,Gossip天然具有分布式容錯的優點。
Raft算法和Gossip協議