
device-mapper deduplication (dm dedup) <2>概要
阿新 • • 發佈:2018-10-29
不重復 ima manager ext mark 數據 功能 原理 設計思想 二、dm dedup的原理
16位Hash碰撞概率為50%,則n = 301次
32位Hash碰撞概率為50%,則n = 77162次
128位MD5碰撞概率為50%,則n = 21,719,381,355,163,562,492次
具體算法公式請參見:http://www.freezhongzi.info/?p=100
從上述的碰撞百分之50的次數:我們大致可以推算出來,如果對於定長去重(那麽如果采用md5,大概得有2 x 10^19才可能有百分之50的概率出現相同的md5值),但是這樣的分析不夠全面,因為還要考慮到硬盤bit錯誤(概率大概是10 ^-18),所以考慮這個因素公式的參數要重新去填寫。
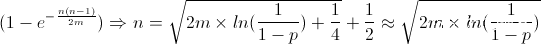
那麽n 約等於 2 ^128 x10^-18再開根,大約是2 x10^10次方,如果按照4k去算,大概能夠表示,100T的數據是不重復的。
如果看過上我上篇《linux I/O棧預習》的讀者會很容易發現,dm dedup僅僅是linux I/O棧中滄海一粟的一個附加功能,那為什麽我會對這個技術這麽感興趣?
那麽我認為有兩點比較有趣:其一是這個項目從2014年開始到如今也沒有被合並入linux kernel主線的代碼,說明其完備性不夠。其二是因為這個技術確實是比較新穎,所以可以在其中有一些思考,而不像其他dm模塊那樣穩定。
那麽直接開始,從它的設計開始說起:
dmdedup的設計思想,其實非常簡單,從圖中可以看出來三個主要的邏輯:
1、hash index
2、LBN Mapping
3、space manager
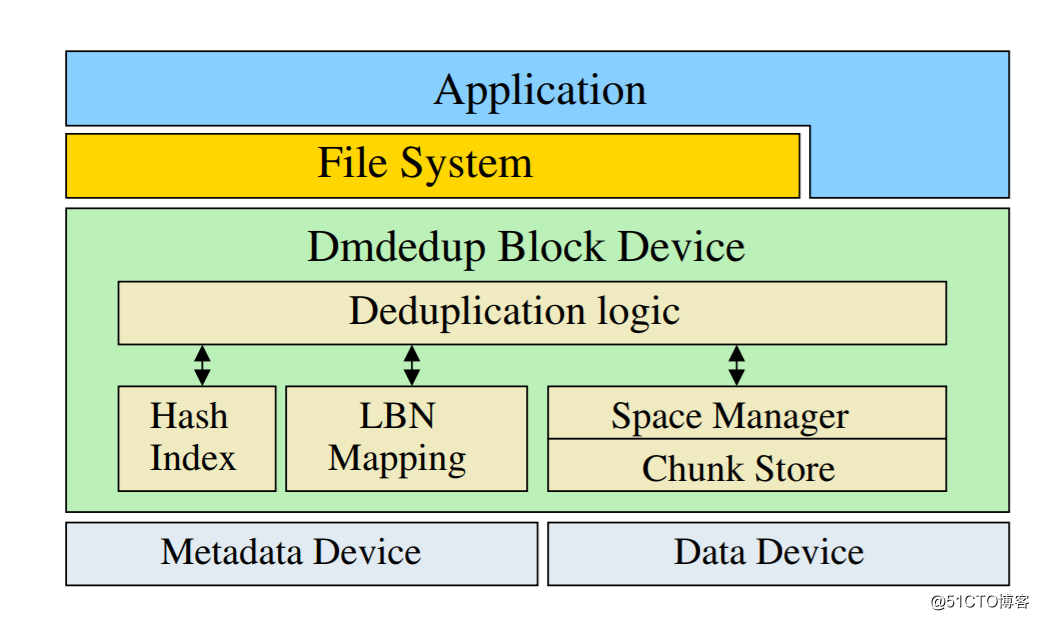
1.hash index,首先dm dmdedup支持非常多中hash算法,那麽我們這裏需要理解hash index產生的沖突概率
16位Hash碰撞概率為50%,則n = 301次
32位Hash碰撞概率為50%,則n = 77162次
128位MD5碰撞概率為50%,則n = 21,719,381,355,163,562,492次
具體算法公式請參見:http://www.freezhongzi.info/?p=100
從上述的碰撞百分之50的次數:我們大致可以推算出來,如果對於定長去重(那麽如果采用md5,大概得有2 x 10^19才可能有百分之50的概率出現相同的md5值),但是這樣的分析不夠全面,因為還要考慮到硬盤bit錯誤(概率大概是10 ^-18),所以考慮這個因素公式的參數要重新去填寫。
那麽n 約等於 2 ^128 x10^-18再開根,大約是2 x10^10次方,如果按照4k去算,大概能夠表示,100T的數據是不重復的。
device-mapper deduplication (dm dedup) <2>概要