
Hadoop核心組件之MapReduce
阿新 • • 發佈:2018-10-31
數據集 shu 分而治之 put 存儲 ont 監視 計算 cin
## MapReduce概述
- Google MapReduce的克隆版本
- 優點:海量數據的離線處理,易開發,易運行
- 缺點:實時流式計算
Hadoop MapReduce是一個軟件框架,用於輕松編寫應用程序,以可靠,容錯的方式在大型集群(數千個節點)的商用硬件上並行處理大量數據(多TB數據集)
## MapReduce編程模型
**思想:分而治之**
MapReduce作業通常將輸入數據集拆分為獨立的塊,這些塊由map任務以完全並行的方式處理。框架對map的輸出進行排序,然後輸入到reduce任務。通常,作業的輸入和輸出都存儲在文件系統中。該框架負責調度任務,監視它們並重新執行失敗的任務。
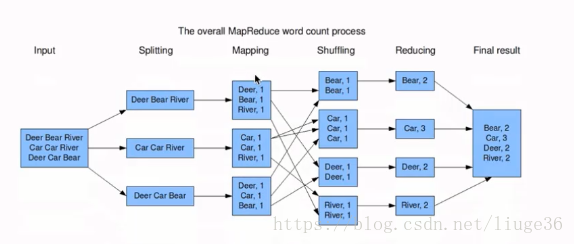
案例;統計一篇文章,各個單詞出現的次數
Input數據輸入
Splitting:拆分數據讀取到各個節點
Mapping:為每一個單詞賦1,不會做合並操作
Shuffling: 重新洗牌(指定規則),這裏把相同單詞發到同一個節點去
Reducing : 統計合並相同單詞的次數
最後把結果寫到一個文件中去就ok了
Hadoop核心組件之MapReduce