
樸素貝葉斯分類MATLAB實現
阿新 • • 發佈:2018-10-31
原理:
首先將資料分成訓練集和測試集,計算測試集中每個類的先驗概率(就是每個類在訓練集中佔的比例),然後為樣本的每個屬性估計條件概率(就是屬性值相同的樣本在每一類中佔的比例)為了方便理解請看下面的例子:(直接用的周志華機器學習那本書上的資料)
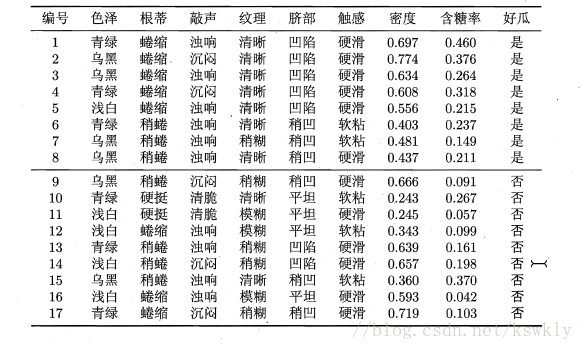
現在有一個西瓜,它的屬性值如下,讓判斷它是好瓜還是壞瓜

首先我們要求每個類的先驗概率,就是好瓜和壞瓜的比例
P(好瓜) = 8/17 = 0.471
P(壞瓜) = 9/17 = 0.529
然後為每個屬性值估計概率


然後就可以計算出它是好瓜和壞瓜的概率了,那個概率大就認為它是那種瓜

源資料鏈接:https://github.com/softwinds/Course_PR_17/edit/master/experiment1/data/synthetic_data/mix.txt
MATLAB實現:
[b] = xlsread('mix.xlsx',1,'A1:D1628'); x = b(:,1); y = b(:,2); c = b(:,3); data = [x,y]; NUM = 500;%樣本數量 Test = sortrows([x(1:NUM,1),y(1:NUM,1),c(1:NUM,1)],3);%為方便處理按類對樣本排序 temp = zeros(23,5);%用來儲存樣本中各個屬性的均值、方差和每個類的概率 %計算出樣本中各個屬性的均值、方差和每個類的概率 for i = 1:23 X = []; Y = []; count = 0; for j = 1:NUM if Test(j,3)==i X = [X;Test(j,1)]; Y = [Y;Test(j,2)]; count = count + 1; end end temp(i,1) = mean(X); temp(i,2) = std(X); temp(i,3) = mean(Y); temp(i,4) = std(Y); temp(i,5) = count/NUM; end %計算預測結果 result = []; for m = 1:1628 pre = []; for n = 1:23 PX = 1/temp(n,2)*exp(((data(m,1)-temp(n,1))^2)/-2/(temp(n,2)^2)); PY = 1/temp(n,4)*exp(((data(m,2)-temp(n,3))^2)/-2/(temp(n,4)^2)); pre = [pre;PX*PY*temp(n,5)*10^8]; end [da,index]=max(pre); result = [result;index]; end xlswrite('mix.xlsx',result,'E1:E1628'); %畫圖 for i = 1:1628 rand('seed',result(i,1)); color = rand(1,3); plot(x(i,1),y(i,1),'*','color',color); hold on; end %檢視正確率 num = 0; for i = 1:1628 if result(i)==c(i) num = num+1;%正確的個數 end end
其實MATLAB有現成的封裝好的分類方法,這裡只不過是把過程寫了一下而已。