
深入淺出kubernetes之client-go的Indexer
記得大學剛畢業那年看了侯俊傑的《深入淺出MFC》,就對深入淺出這四個字特別偏好,並且成為了自己對技術的要求標準——對於技術的理解要足夠的深刻以至於可以用很淺顯的道理給別人講明白。以下內容為個人見解,如有雷同,純屬巧合,如有錯誤,煩請指正。
本文基於kubernetes1.11版本,後續會根據kubernetes版本更新及時更新文件,所有程式碼引用為了簡潔都去掉了日誌列印相關的程式碼,儘量只保留有價值的內容。
目錄
Indexer功能介紹
Informer是client-go的重要組成部分,在瞭解client-go之前,瞭解一下Informer的實現是很有必要的,下面引用了官方的圖,可以看到Informer在client-go中的位置。
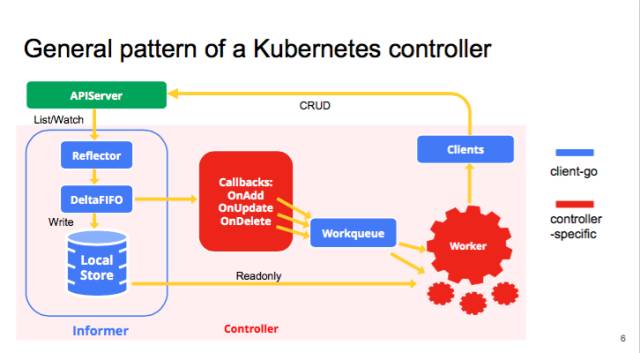
由於Informer比較龐大,所以我們把它拆解成接獨立的模組分析,本文分析的就是Indexer模組。Indexer是什麼,從字面上看是索引器,他所在的位置就是Informer的LocalStore。肯定有人會問索引和儲存有啥關係,那資料庫建索引不也是儲存和索引建立了關係麼?索引構建在儲存之上,使得按照某些條件查詢速度會非常快。我先從程式碼上證實client-go中的Indexer就是儲存:
-
// 程式碼源自client-go/tools/cache/index.go -
type Indexer interface { -
Store // 此處繼承了Store這個interface,定義在cliet-go/tool/cache/store.go中 -
...... -
}
Indexer在Store基礎上擴充套件了索引能力,那Indexer是如何實現索引的呢?讓我們來看看幾個非常關鍵的型別:
-
// 程式碼源自client-go/tools/cache/index.go -
type IndexFunc func(obj interface{}) ([]string, error) // 計算索引的函式,傳入物件,輸出字串索引,注意是陣列哦! -
type Indexers map[string]IndexFunc // 計算索引的函式有很多,用名字分類 -
type Indices map[string]Index // 由於有多種計算索引的方式,那就又要按照計算索引的方式組織索引 -
type Index map[string]sets.String // 每種計算索引的方式會輸出多個索引(陣列) -
// 而多個目標可能會算出相同索引,所以就有了這個型別
我相信很多人初次(不要看我的註釋)看到上面的定義肯定懵逼了,不用說別的,就型別命名根本看不出是幹啥的,而且還相似~我在這裡給大家解釋一下定義這些型別的目的。何所謂索引,索引目的就是為了快速查詢。比如,我們需要查詢某個節點上的所有Pod,那就要Pod按照節點名稱排序,對應上面的Index型別就是map[nodename]sets.podname。我們可能有很多種查詢方式,這就是Indexers這個型別作用了。下面的圖幫助讀者理解,不代表真正實現:
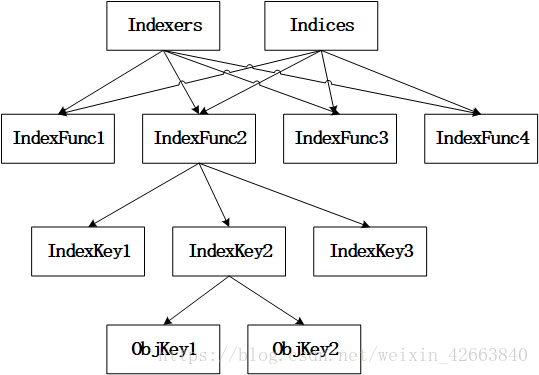
Indexers和Indices都是按照IndexFunc(名字)分組, 每個IndexFunc輸出多個IndexKey,產生相同IndexKey的多個物件儲存在一個集合中。注意:上圖中不代表Indexers和Indices都指向了同一個資料,只是示意都用相同的IndexFunc的名字。
為了方便後面內容的開展,我們先統一一些概念:
- IndexFunc1.....這些都是索引函式的名稱,我們稱之為索引類,大概意思就是把索引分類了;
- IndexKey1....這些是同一個物件在同一個索引類中的多個索引鍵值,我們稱為索引鍵,切記索引鍵有多個;
- ObjKey1.....這些是物件鍵,每個物件都有唯一的名稱;
有了上面的基礎,我們再來看看Indexer與索引相關的介面都定義了哪些?
-
// 程式碼源自client-go/tools/cache/index.go -
type Indexer interface { -
// 集成了儲存的介面,前面提到了,後面會有詳細說明 -
Store -
// indexName索引類,obj是物件,計算obj在indexName索引類中的索引鍵,通過索引鍵把所有的物件取出來 -
// 基本就是獲取符合obj特徵的所有物件,所謂的特徵就是物件在索引類中的索引鍵 -
Index(indexName string, obj interface{}) ([]interface{}, error) -
// indexKey是indexName索引類中一個索引鍵,函式返回indexKey指定的所有物件鍵 -
// 這個物件鍵是Indexer內唯一的,在新增的時候會計算,後面講具體Indexer例項的會講解 -
IndexKeys(indexName, indexKey string) ([]string, error) -
// 獲取indexName索引類中的所有索引鍵 -
ListIndexFuncValues(indexName string) []string -
// 這個函式和Index類似,只是返回值不是物件鍵,而是所有物件 -
ByIndex(indexName, indexKey string) ([]interface{}, error) -
// 返回Indexers -
GetIndexers() Indexers -
// 新增Indexers,就是增加更多的索引分類 -
AddIndexers(newIndexers Indexers) error -
}
我相信通過我的註釋很多人已經對Indexer有了初步認識,我們再來看看Store這個interface有哪些介面:
-
// 程式碼源自client-go/tools/cache/store.go -
type Store interface { -
// 新增物件 -
Add(obj interface{}) error -
// 更新物件 -
Update(obj interface{}) error -
// 刪除物件 -
Delete(obj interface{}) error -
// 列舉物件 -
List() []interface{} -
// 列舉物件鍵 -
ListKeys() []string -
// 返回obj相同物件鍵的物件,物件鍵是通過物件計算出來的字串 -
Get(obj interface{}) (item interface{}, exists bool, err error) -
// 通過物件鍵獲取物件 -
GetByKey(key string) (item interface{}, exists bool, err error) -
// 用[]interface{}替換Store儲存的所有物件,等同於刪除全部原有物件在逐一新增新的物件 -
Replace([]interface{}, string) error -
// 重新同步 -
Resync() error -
}
從Store的抽象來看,要求每個物件都要有唯一的鍵,至於鍵的計算方式就看具體實現了。我們看了半天的各種抽象,是時候講解一波具體實現了。
Indexer實現之cache
cache是Indexer的一種非常經典的實現,所有的物件快取在記憶體中,而且從cache這個型別的名稱來看屬於包內私有型別,外部無法直接使用,只能通過專用的函式建立。其實cache的定義非常簡單,如下所以:
-
// 程式碼源自client-go/tools/cache/store.go -
type cache struct { -
cacheStorage ThreadSafeStore // 執行緒安全的儲存 -
keyFunc KeyFunc // 計算物件鍵的函式 -
} -
// 計算物件鍵的函式 -
type KeyFunc func(obj interface{}) (string, error)
這裡可以看出來cache有一個計算物件鍵的函式,建立cache物件的時候就要指定這個函數了。
ThreadSafeStore
從cache的定義來看,所有的功能基本是通過ThreadSafeStore這個型別實現的,keyFunc就是用來計算物件鍵的。所以,我們在分析cache之前,分析ThreadSafeStore是非常重要的,接下來就看看這個型別是如何定義的:
-
// 程式碼源自client-go/tools/cache/thread_safe_store.go -
type ThreadSafeStore interface { -
Add(key string, obj interface{}) -
Update(key string, obj interface{}) -
Delete(key string) -
Get(key string) (item interface{}, exists bool) -
List() []interface{} -
ListKeys() []string -
Replace(map[string]interface{}, string) -
Index(indexName string, obj interface{}) ([]interface{}, error) -
IndexKeys(indexName, indexKey string) ([]string, error) -
ListIndexFuncValues(name string) []string -
ByIndex(indexName, indexKey string) ([]interface{}, error) -
GetIndexers() Indexers -
AddIndexers(newIndexers Indexers) error -
Resync() error -
}
我為什麼沒有對ThreadSafeStore做註釋呢?乍一看和Indexer這個itnerface基本一樣,但還是有差別的,就是跟儲存相關的介面。Indexer因為繼承了Store,儲存相關的增刪改查輸入都是物件,而ThreadSafeStore是需要提供物件鍵的。所以ThreadSafeStore和Indexer基本一樣,也就沒必要再寫一遍註釋,我們可以把精力主要放在具體的實現類上:
-
// 程式碼源自client-go/tools/cache/thread_safe_store.go -
type threadSafeMap struct { -
lock sync.RWMutex // 讀寫鎖,畢竟讀的多寫的少,讀寫鎖效能要更好 -
items map[string]interface{} // 儲存物件的map,物件鍵:物件 -
indexers Indexers // 這個不用多解釋了把,用於計算索引鍵的函式map -
indices Indices // 快速索引表,通過索引可以快速找到物件鍵,然後再從items中取出物件 -
}
看了具體的實現類是不是感覺很簡單?其實就是很簡單,如果沒有經過系統的梳理,如此簡單的實現也不見的很容易看明白。我還是要在此強調一次,索引鍵和物件鍵是兩個重要概念,索引鍵是用於物件快速查詢的,經過索引建在map中排序查詢會更快;物件鍵是為物件在儲存中的唯一命名的,物件是通過名字+物件的方式儲存的。
後續內容會簡單很多,所以會把多個函式放在一起註釋,下面就是和儲存相關的函式的統一說明:
-
// 程式碼源自client-go/tools/cache/thread_safe_store.go -
// 新增物件函式 -
func (c *threadSafeMap) Add(key string, obj interface{}) { -
// 加鎖,因為是寫操作,所以是全部互斥的那種 -
c.lock.Lock() -
defer c.lock.Unlock() -
// 把老的物件取出來 -
oldObject := c.items[key] -
// 寫入新的物件 -
c.items[key] = obj -
// 由於物件的新增就要更新索引 -
c.updateIndices(oldObject, obj, key) -
} -
// 更新物件函式,和新增物件一模一樣,所以就不解釋了,為啥Add函式不直接呼叫Update呢? -
func (c *threadSafeMap) Update(key string, obj interface{}) { -
c.lock.Lock() -
defer c.lock.Unlock() -
oldObject := c.items[key] -
c.items[key] = obj -
c.updateIndices(oldObject, obj, key) -
} -
// 刪除物件 -
func (c *threadSafeMap) Delete(key string) { -
// 加鎖,因為是寫操作,所以是全部互斥的那種 -
c.lock.Lock() -
defer c.lock.Unlock() -
// 判斷物件是否存在? -
if obj, exists := c.items[key]; exists { -
// 刪除物件的索引 -
c.deleteFromIndices(obj, key) -
// 刪除物件本身 -
delete(c.items, key) -
} -
} -
// 獲取物件 -
func (c *threadSafeMap) Get(key string) (item interface{}, exists bool) { -
// 此處只用了讀鎖 -
c.lock.RLock() -
defer c.lock.RUnlock() -
// 利用物件鍵取出物件 -
item, exists = c.items[key] -
return item, exists -
} -
// 列舉物件 -
func (c *threadSafeMap) List() []interface{} { -
// 此處只用了讀鎖 -
c.lock.RLock() -
defer c.lock.RUnlock() -
// 直接遍歷物件map就可以了 -
list := make([]interface{}, 0, len(c.items)) -
for _, item := range c.items { -
list = append(list, item) -
} -
return list -
} -
// 列舉物件鍵 -
func (c *threadSafeMap) ListKeys() []string { -
// 此處只用了讀鎖 -
c.lock.RLock() -
defer c.lock.RUnlock() -
// 同樣是遍歷物件map,但是隻輸出物件鍵 -
list := make([]string, 0, len(c.items)) -
for key := range c.items { -
list = append(list, key) -
} -
return list -
} -
// 取代所有物件,相當於重新構造了一遍threadSafeMap -
func (c *threadSafeMap) Replace(items map[string]interface{}, resourceVersion string) { -
// 此處必須要用全域性鎖,因為有寫操作 -
c.lock.Lock() -
defer c.lock.Unlock() -
// 直接覆蓋以前的物件 -
c.items = items -
// 重建索引 -
c.indices = Indices{} -
for key, item := range c.items { -
c.updateIndices(nil, item, key) -
} -
// 發現沒有,resourceVersion此處沒有用到,估計是其他的Indexer實現有用 -
}
下面就是跟索引相關的函數了,也是我主要講解的內容,所以每個函式都是獨立註釋的,我們一個一個的過:
-
// 程式碼源自client-go/tools/cache/thread_safe_store.go -
// 這個函式就是通過指定的索引函式計算物件的索引鍵,然後把索引鍵的物件全部取出來 -
func (c *threadSafeMap) Index(indexName string, obj interface{}) ([]interface{}, error) { -
// 只讀,所以用讀鎖 -
c.lock.RLock() -
defer c.lock.RUnlock() -
// 取出indexName這個分類索引函式 -
indexFunc := c.indexers[indexName] -
if indexFunc == nil { -
return nil, fmt.Errorf("Index with name %s does not exist", indexName) -
} -
// 計算物件的索引鍵 -
indexKeys, err := indexFunc(obj) -
if err != nil { -
return nil, err -
} -
// 取出indexName這個分類所有索引 -
index := c.indices[indexName] -
// 返回物件的物件鍵的集合 -
returnKeySet := sets.String{} -
// 遍歷剛剛計算出來的所有索引鍵 -
for _, indexKey := range indexKeys { -
// 取出索引鍵的所有物件鍵 -
set := index[indexKey] -
// 把所有的物件鍵輸出到物件鍵的集合中 -
for _, key := range set.UnsortedList() { -
returnKeySet.Insert(key) -
} -
} -
// 通過物件鍵逐一的把物件取出 -
list := make([]interface{}, 0, returnKeySet.Len()) -
for absoluteKey := range returnKeySet { -
list = append(list, c.items[absoluteKey]) -
} -
return list, nil -
}
這個函式比較有意思,利用一個物件計算出來的索引鍵,然後把所有具備這些索引鍵的物件全部取出來,為了方便理解我都是這樣告訴自己的:比如取出一個Pod所在節點上的所有Pod,這樣理解就會非常方便,但是kubernetes可能就不這麼用。如果更抽象一點,就是符合物件某些特徵的所有物件,而這個特徵就是我們指定的索引函式計算出來的。
好啦,下一個函式:
-
// 程式碼源自client-go/tools/cache/thread_safe_store.go -
// 這個函式和上面的函式基本一樣,只是索引鍵不用再計算了,使用者提供 -
func (c *threadSafeMap) ByIndex(indexName, indexKey string) ([]interface{}, error) { -
// 同樣是讀鎖 -
c.lock.RLock() -
defer c.lock.RUnlock() -
// 判斷indexName這個索引分類是否存在 -
indexFunc := c.indexers[indexName] -
if indexFunc == nil { -
return nil, fmt.Errorf("Index with name %s does not exist", indexName) -
} -
// 取出索引分類的所有索引 -
index := c.indices[indexName] -
// 再出去索引鍵的所有物件鍵 -
set := index[indexKey] -
// 遍歷物件鍵輸出 -
list := make([]interface{}, 0, set.Len()) -
for _, key := range set.List() { -
list = append(list, c.items[key]) -
} -
return list, nil -
}
這個函式相比於上一個函式功能略微簡單一點,獲取的是一個具體索引鍵的全部物件。Come on,沒幾個函數了!
-
// 程式碼源自client-go/tools/cache/thread_safe_store.go -
// 你會發現這個函式和ByIndex()基本一樣,只是輸出的是物件鍵 -
func (c *threadSafeMap) IndexKeys(indexName, indexKey string) ([]string, error) { -
// 同樣是讀鎖 -
c.lock.RLock() -
defer c.lock.RUnlock() -
// 判斷indexName這個索引分類是否存在 -
indexFunc := c.indexers[indexName] -
if indexFunc == nil { -
return nil, fmt.Errorf("Index with name %s does not exist", indexName) -
} -
// 取出索引分類的所有索引 -
index := c.indices[indexName] -
// 直接輸出索引鍵內的所有物件鍵 -
set := index[indexKey] -
return set.List(), nil -
}
還有最後一個(其他的對外介面函式太簡單了,讀者自行分析就好了):
-
// 程式碼源自client-go/tools/cache/thread_safe_store.go -
// 這個函式用來獲取索引分類內的所有索引鍵的 -
func (c *threadSafeMap) ListIndexFuncValues(indexName string) []string { -
// 依然是讀鎖 -
c.lock.RLock() -
defer c.lock.RUnlock() -
// 獲取索引分類的所有索引 -
index := c.indices[indexName] -
// 直接遍歷後輸出索引鍵 -
names := make([]string, 0, len(index)) -
for key := range index { -
names = append(names, key) -
} -
return names -
}
至於AddIndexers()和GetIndexers()因為沒有難度,而且不影響理解核心邏輯,所以此處不再浪費文字了。看了半天程式碼是不是感覺缺點什麼?為什麼沒有看到索引是如何組織的?那就對了,因為還有兩個最為重要的私有函式沒有分析呢!
-
// 程式碼源自client-go/tools/cache/thread_safe_store.go -
// 當有物件新增或者更新是,需要更新索引,因為代用該函式的函式已經加鎖了,所以這個函式沒有加鎖操作 -
func (c *threadSafeMap) updateIndices(oldObj interface{}, newObj interface{}, key string) { -
// 在新增和更新的時候都會獲取老物件,如果存在老物件,那麼就要刪除老物件的索引,後面有說明 -
if oldObj != nil { -
c.deleteFromIndices(oldObj, key) -
} -
// 遍歷所有的索引函式,因為要為物件在所有的索引分類中建立索引鍵 -
for name, indexFunc := range c.indexers { -
// 計算索引鍵 -
indexValues, err := indexFunc(newObj) -
if err != nil { -
panic(fmt.Errorf("unable to calculate an index entry for key %q on index %q: %v", key, name, err)) -
} -
// 獲取索引分類的所有索引 -
index := c.indices[name] -
if index == nil { -
// 為空說明這個索引分類還沒有任何索引 -
index = Index{} -
c.indices[name] = index -
} -
// 遍歷物件的索引鍵,上面剛剛用索引函式計算出來的 -
for _, indexValue := range indexValues { -
// 找到索引鍵的物件集合 -
set := index[indexValue] -
// 為空說明這個索引鍵下還沒有物件 -
if set == nil { -
// 建立物件鍵集合 -
set = sets.String{} -
index[indexValue] = set -
} -
// 把物件鍵新增到集合中 -
set.Insert(key) -
} -
} -
} -
// 這個函式用於刪除物件的索引的 -
func (c *threadSafeMap) deleteFromIndices(obj interface{}, key string) { -
// 遍歷索引函式,也就是把所有索引分類 -
for name, indexFunc := range c.indexers { -
// 計算物件的索引鍵 -
indexValues, err := indexFunc(obj) -
if err != nil { -
panic(fmt.Errorf("unable to calculate an index entry for key %q on index %q: %v", key, name, err)) -
} -
// 獲取索引分類的所有索引 -
index := c.indices[name] -
if index == nil { -
continue -
} -
// 遍歷物件的索引鍵 -
for _, indexValue := range indexValues { -
把物件從索引鍵指定對物件集合刪除 -
set := index[indexValue] -
if set != nil { -
set.Delete(key) -
} -
} -
} -
}
cache的實現
因為cache就是在ThreadSafeStore的再封裝,實現也非常簡單,我不做過多說明,只把程式碼羅列出來,讀者一看便知。
-
// 程式碼源自client-go/tools/cache/store.go -
func (c *cache) Add(obj interface{}) error { -
key, err := c.keyFunc(obj) -
if err != nil { -
return KeyError{obj, err} -
} -
c.cacheStorage.Add(key, obj) -
return nil -
} -
func (c *cache) Update(obj interface{}) error { -
key, err := c.keyFunc(obj) -
if err != nil { -
return KeyError{obj, err} -
} -
c.cacheStorage.Update(key, obj) -
return nil -
} -
func (c *cache) Delete(obj interface{}) error { -
key, err := c.keyFunc(obj) -
if err != nil { -
return KeyError{obj, err} -
} -
c.cacheStorage.Delete(key) -
return nil -
} -
func (c *cache) List() []interface{} { -
return c.cacheStorage.List() -
} -
func (c *cache) ListKeys() []string { -
return c.cacheStorage.ListKeys() -
} -
func (c *cache) GetIndexers() Indexers { -
return c.cacheStorage.GetIndexers() -
} -
func (c *cache) Index(indexName string, obj interface{}) ([]interface{}, error) { -
return c.cacheStorage.Index(indexName, obj) -
} -
func (c *cache) IndexKeys(indexName, indexKey string) ([]string, error) { -
return c.cacheStorage.IndexKeys(indexName, indexKey) -
} -
func (c *cache) ListIndexFuncValues(indexName string) []string { -
return c.cacheStorage.ListIndexFuncValues(indexName) -
} -
func (c *cache) ByIndex(indexName, indexKey string) ([]interface{}, error) { -
return c.cacheStorage.ByIndex(indexName, indexKey) -
} -
func (c *cache) AddIndexers(newIndexers Indexers) error { -
return c.cacheStorage.AddIndexers(newIndexers) -
} -
func (c *cache) Get(obj interface{}) (item interface{}, exists bool, err error) { -
key, err := c.keyFunc(obj) -
if err != nil { -
return nil, false, KeyError{obj, err} -
} -
return c.GetByKey(key) -
} -
func (c *cache) GetByKey(key string) (item interface{}, exists bool, err error) { -
item, exists = c.cacheStorage.Get(key) -
return item, exists, nil -
} -
func (c *cache) Replace(list []interface{}, resourceVersion string) error { -
items := map[string]interface{}{} -
for _, item := range list { -
key, err := c.keyFunc(item) -
if err != nil { -
return KeyError{item, err} -
} -
items[key] = item -
} -
c.cacheStorage.Replace(items, resourceVersion) -
return nil -
} -
func (c *cache) Resync() error { -
return c.cacheStorage.Resync() -
}
kubernetes中主要的索引函式
我搜遍了kubernetes程式碼,發現最主要的索引的函式大概就下面幾種:
- MetaNamespaceIndexFunc,定義在client-go/tools/cache/index.go中,從名字看就是獲取物件元資料的namesapce欄位,也就是所有物件以namespace作為索引鍵,這個就很好理解了;
- indexByPodNodeName,定義在kubernetes/pkg/controller/daemon/deamon_controller.go,該索引函式計算的是Pod物件所在節點的名字;
為了方便理解,我們可以假設kubernetes主要就是一種索引函式(MetaNamespaceIndexFunc),也就是在索引中大部分就一個分類,這個分類的索引鍵就是namesapce。那麼有人肯定會問,如果這樣的話,所有的物件都存在一個namesapce索引鍵下面,這樣的效率豈不是太低了?其實client-go為每類物件都建立了Informer(Informer內有Indexer),所以即便儲存在相同namesapce下的物件都是同一類,這個問題自然也就沒有了,詳情可以看我針對Informer寫的文章。
大家一定要區分MetaNamespaceIndexFunc和MetaNamespaceKeyFunc的區分,第一個索引鍵計算函式,第二個是物件鍵計算函式,第一個返回的是namespace,第二個返回的是物件包含namespace在內的物件全程。
總結
如果讀者還對所謂的索引、索引分類、索引鍵、物件鍵比較混亂的話,我就要拿出我更加大白話的總結了:所有的物件(Pod、Node、Service等等)都是有屬性/標籤的,如果屬性/標籤就是索引鍵,Indexer就會把相同屬性/標籤的所有物件放在一個集合中,如果在對屬性/標籤分一下類,也就就是我們本文的將的Indexer的核心內容了。甚至你可以簡單的理解為Indexer就是簡單的把相同namesapce物件放在一個集合中,kubernetes就是基於屬相/標籤檢索的,這麼理解也不偏頗,方法不重要,只要能幫助理解都是好方法。
有人肯定會說你早說不就完了麼?其實如果沒有上面的分析,直接給出總結是不是顯得我很沒水平?關鍵是讀者理解的也不會深刻!
原文轉載於:https://blog.csdn.net/weixin_42663840/article/details/81530606