
深入淺出kubernetes之device-plugins
記得大學剛畢業那年看了侯俊傑的《深入淺出MFC》,就對深入淺出這四個字特別偏好,並且成為了自己對技術的要求標準——對於技術的理解要足夠的深刻以至於可以用很淺顯的道理給別人講明白。以下內容為個人見解,如有雷同,純屬巧合,如有錯誤,煩請指正。
本文基於kubernetes1.11版本,後續會根據kubernetes版本更新及時更新文件,所有程式碼引用為了簡潔都去掉了日誌列印相關的程式碼,儘量只保留有價值的內容。
延續我個人風格,在個人發揮前,先看看官方對於device-plugins的定義是什麼?
Starting in version 1.8, Kubernetes provides a device plugin framework for vendors to advertise their resources to the kubelet without changing Kubernetes core code. Instead of writing custom Kubernetes code, vendors can implement a device plugin that can be deployed manually or as a DaemonSet. The targeted devices include GPUs, High-performance NICs, FPGAs, InfiniBand, and other similar computing resources that may require vendor specific initialization and setup.
大概意思是:從kubernetes1.8版本開始,提供了裝置外掛框架,裝置廠商無需修改kubernetes核心程式碼就可以將自己生產的裝置的資源(kubernetes可管理的資源包括CPU、記憶體和儲存資源)可以讓kubelet使用(這一點與作業系統一樣,所有裝置廠商自己實現驅動)。裝置廠商可以自己人工或者以DaemonSet方式部署,而不是定製kubernetes程式碼。目標裝置包括GPU、高效能NIC(網路介面卡)、FPGA、InfiniBand以及其他類似的需要廠商指定初始化和安裝的計算資源。上文引用自kubernetes官方文件,讀者可以自行了解一下官方對於device-plugin的說明,如下圖所示(用圖比連結好,擔心連結以後會變):
瞭解device-plugin的是什麼了,接下來就是看看kubernetes是如何實現並工作的。我寫這篇文章的核心目的是瞭解kubernetes如何管理GPU的,因為我的專案需要一個叢集同時管理CPU和GPU,根據使用者的需求選擇合適的資源計算。所以,後面所有的分析都是以GPU為例,讀者如果需要了解其他型別的裝置根據本文的思路自行分析即可。
好了,我們可以進入正題了。讓我們先忘記一部分內容,看看下面這個圖:
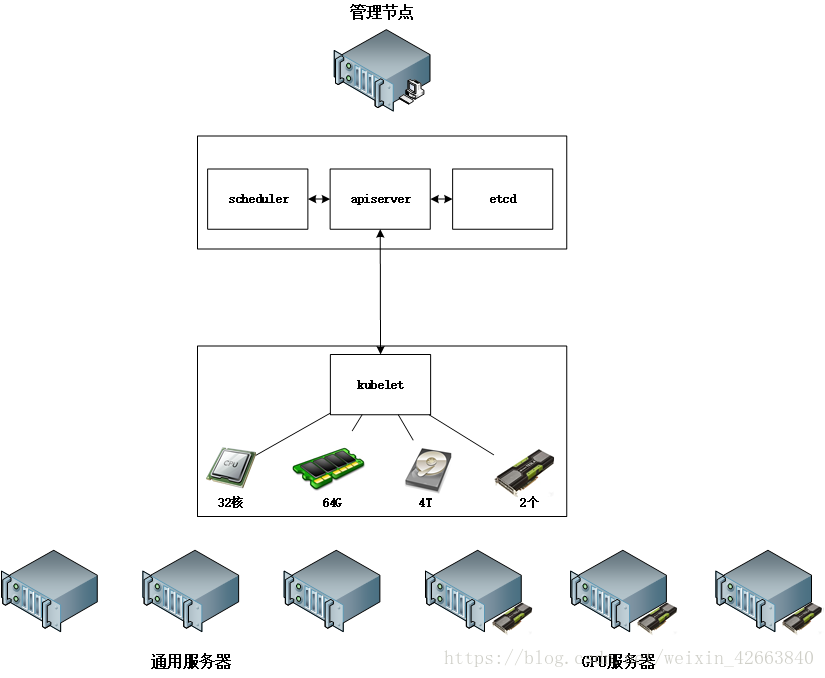
如果我作為kubernetes開發者,思路是由kubelet彙總所有的資源,然後在彙總到管理端,kubernetes也就是apiserver。當建立Pod時,請求會發送給scheduler,scheduler根據節點狀態選擇一個最優的節點,最後由最優節點的kubelet建立這個Pod。嗯,這個思路應該沒什麼大毛病,至少我開發的一個分散式計算系統採用的就是這個方式,沒問題!好,我們先假設這個想法是就是kubernetes的設計方案,此處我們不講記憶體、CPU、儲存這些資源是kubelet是怎麼獲取的,因為本文的重點是device-plugins,我們只說GPU這個kubelet是怎麼獲取的。
上面說到了,kubernetes有裝置外掛框架,那這個框架又是什麼樣的呢?說白了也很簡單,就是kubernetes定義了一套機制和介面,各裝置廠商按照協議開發就可以了,這個和Linux驅動原理是一樣的,只是實現方式不一樣而已。我們來看看kubernetes是怎麼實現的,首先我們先說說機制:
- 廠商自行實現一個管理裝置資源的程式,部署到相應的節點上,我們稱之為外掛;
- 外掛需要向kubelet註冊,註冊內容要包含自己的endpoint(endpoint就是一個用於通訊的地址)以及一些其他資訊(後面會說明);
- kubelet連線外掛的endpoint,就此kubelet和外掛就建立了聯絡;
- kubelet監聽/var/lib/kubelet/device-plugins/kubelet.sock(unix sockets)這個地址,外掛監聽的也是類似的地址,只是地址變成了/var/lib/kubelet/device-plugins/gpu.sock(舉個例子)
以上是外掛如何讓kubernetes發現自己,接下來就是外掛和kubelet之間的通訊介面了,kubelet與外掛採用grpc通訊,通訊介面定義在kubernetes/pkg/kubelet/apis/deviceplugin/v1beta1/api.proto(不瞭解protobuf和grpc的同學請自行學習)中。檔案中定義了兩個用於通訊的介面:
service Registration {
rpc Register(RegisterRequest) returns (Empty) {}
}
service DevicePlugin {
rpc GetDevicePluginOptions(Empty) returns (DevicePluginOptions) {}
rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse) {}
rpc Allocate(AllocateRequest) returns (AllocateResponse) {}
rpc PreStartContainer(PreStartContainerRequest) returns (PreStartContainerResponse) {}
}
第一個介面用於外掛向kubelet註冊,kubelet是服務端,外掛是客戶端;第二個介面是kubelet向外掛索要支援,kubelet是客戶端,外掛是服務端,我們會在後面的程式碼分析中證明這一點。我們接下來看看外掛註冊的時候需要提供哪些資訊(程式碼源於api.proto)?
message RegisterRequest {
string version = 1; // 版本資訊
string endpoint = 2; // 外掛的endpoint
string resource_name = 3; // 資源名稱
DevicePluginOptions options = 4; // 外掛選項
}
// 那外掛選項又包含什麼呢?
message DevicePluginOptions {
bool pre_start_required = 1; // 啟動容器前是否呼叫DevicePlugin.PreStartContainer()
}version、endpoint、resource_name都比較好理解,pre_start_required 不是很明確,其實就是啟動容器前先通知外掛做一下準備,多一個機制擴充套件性要好一些。接下來我們看看外掛能為kubelet提供什麼樣的服務,亦或說kubelet需要外掛提供什麼樣的功能。
1.rpc GetDevicePluginOptions(Empty) returns (DevicePluginOptions) {},這個和註冊提供的資訊是一樣的,只是變成了kubelet可以再獲取;
2.rpc PreStartContainer(PreStartContainerRequest) returns (PreStartContainerResponse) {},這個就是kubelet啟動容器前呼叫的,其中PreStartContainerRequest,PreStartContainerResponse定義如下,非常簡單:
message PreStartContainerRequest {
repeated string devicesIDs = 1; // 需要使用裝置的所有ID,陣列形式
}
message PreStartContainerResponse { // 什麼也沒有
}3.rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse) {},kubelet監聽裝置變化,一旦有裝置更新,外掛就會通知kubelet,注意此處返回是stream型別。我們再來看看外掛返回的結果都有什麼?
message ListAndWatchResponse {
repeated Device devices = 1; //裝置陣列
}
message Device {
string ID = 1; // 裝置唯一ID
string health = 2; // 裝置健康情況,就是是好的還是壞的
}
// 內容非常少,其實內容越少彈性越大,內容越多約束越多。
4.rpc Allocate(AllocateRequest) returns (AllocateResponse) {},這個就是kubelet向外掛申請資源的介面了,申請資源需要提供如下資訊:
message AllocateRequest {
repeated ContainerAllocateRequest container_requests = 1;
}
message ContainerAllocateRequest {
repeated string devicesIDs = 1; // 裝置ID陣列
}從上面的型別可以看出申請資源介面可以同時為多個容器申請資源,AllocateRequest .container_requests代表的是多個容器對於資源的需求,ContainerAllocateRequest.devicesIDs是一個容器對於資源的需求。我們再來看看外掛返回給kubelet什麼資訊?
message AllocateResponse {
repeated ContainerAllocateResponse container_responses = 1;
}
message ContainerAllocateResponse {
map<string, string> envs = 1; // 環境變數,需要為容器新增這些環境變數
repeated Mount mounts = 2; // 掛載資訊
repeated DeviceSpec devices = 3; // 裝置資訊
map<string, string> annotations = 4; // 需要加入到容器的annotations欄位
}
message Mount {
string container_path = 1; // 裝置在容器中的路徑
string host_path = 2; // 裝置在宿主機上的路徑
bool read_only = 3; // 是否只讀
}
message DeviceSpec {
string container_path = 1; // 裝置在容器中的路徑
string host_path = 2; // 裝置在宿主機上的路徑
string permissions = 3; // 訪問裝置需要的許可權
}和AllocateRequest一樣,返回的申請結果也是多容器的。綜合以上資訊,我們要把圖調整一下:
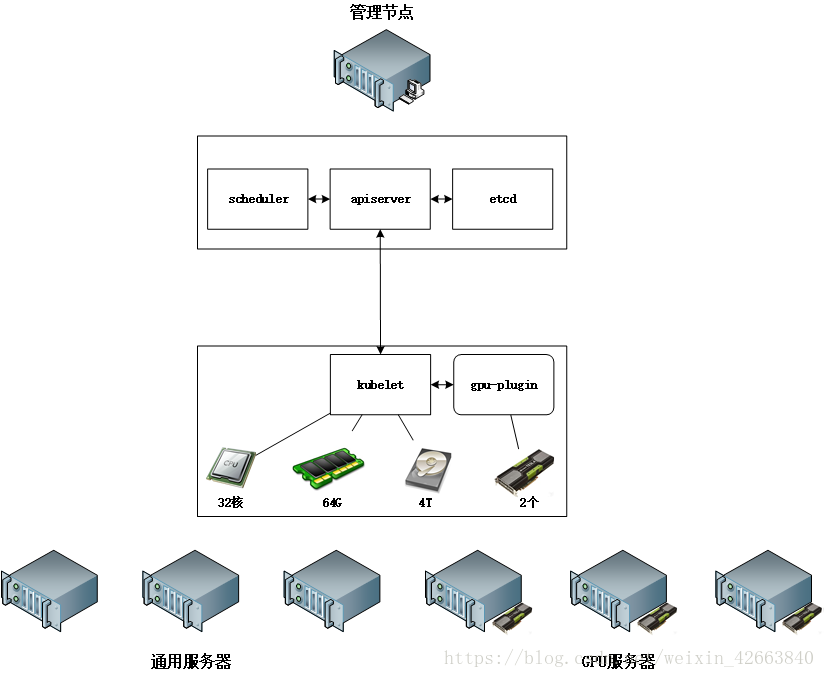
接下來我們就要探索一下kubelet是如何管理者外掛以及相關資源的,開啟我們的程式碼分析之旅啦,我個人的理解會用註釋混合在程式碼中!我們先從kubernetes/pkg/kubelet/cm/devicemanager包開始,不要問我為什麼從這裡開始,反正從字面意思看這裡是裝置管理器就是了(cm是容器管理器的意思)~首先我們來看看kubernetes對於裝置管理器的定義是什麼(源於kubernetes/pkg/kubelet/cm/devicemanager/types.go)?
type Manager interface {
Start(activePods ActivePodsFunc, sourcesReady config.SourcesReady) error
Devices() map[string][]pluginapi.Device
Allocate(node *schedulercache.NodeInfo, attrs *lifecycle.PodAdmitAttributes) error
Stop() error
GetDeviceRunContainerOptions(pod *v1.Pod, container *v1.Container) (*DeviceRunContainerOptions, error)
GetCapacity() (v1.ResourceList, v1.ResourceList, []string)
}Manager是個interface型別,而實現在kubernetes/pkg/kubelet/cm/devicemanager/manager.go檔案中的ManagerImpl,這名字起得非常易懂!知道實現的地方了,我們就要用程式碼證明前面的說法,至少先找到kubelet監聽/var/lib/kubelet/device-plugins/kubelet.sock的地方吧?
func (m *ManagerImpl) Start(activePods ActivePodsFunc, sourcesReady config.SourcesReady) error {
......
// 建立socket目錄,也就是/var/lib/kubelet/device-plugins/
socketPath := filepath.Join(m.socketdir, m.socketname)
os.MkdirAll(m.socketdir, 0755)
// 刪除socket目錄下的所有檔案(資料夾除外)
if err := m.removeContents(m.socketdir); err != nil {
glog.Errorf("Fail to clean up stale contents under %s: %+v", m.socketdir, err)
}
// 監聽socket檔案
s, err := net.Listen("unix", socketPath)
if err != nil {
glog.Errorf(errListenSocket+" %+v", err)
return err
}
// 建立grpc的server端
m.wg.Add(1)
m.server = grpc.NewServer([]grpc.ServerOption{}...)
// 將ManagerImpl註冊為Registration這個grpc介面的服務端處理器
pluginapi.RegisterRegistrationServer(m.server, m)
// 開啟協程啟動grpc服務端
go func() {
defer m.wg.Done()
m.server.Serve(s)
}()
return nil
}上面程式碼足以證明kubelet是通過devicemanager.Manager實現的外掛註冊服務,其中m.socketdir和m.socketname是如何賦值的請看下面的程式碼:
//以下程式碼來自kubernetes/pkg/kubelet/cm/devicemanager/manager.go
func NewManagerImpl() (*ManagerImpl, error) {
return newManagerImpl(pluginapi.KubeletSocket)
}
func newManagerImpl(socketPath string) (*ManagerImpl, error) {
if socketPath == "" || !filepath.IsAbs(socketPath) {
return nil, fmt.Errorf(errBadSocket+" %v", socketPath)
}
dir, file := filepath.Split(socketPath)
manager := &ManagerImpl{
endpoints: make(map[string]endpoint),
socketname: file,
socketdir: dir,
healthyDevices: make(map[string]sets.String),
unhealthyDevices: make(map[string]sets.String),
allocatedDevices: make(map[string]sets.String),
pluginOpts: make(map[string]*pluginapi.DevicePluginOptions),
podDevices: make(podDevices),
}
......
}
//以下程式碼來自kubernetes/pkg/kubelet/apis/deviceplugin/v1beta1/constants.go
const (
Healthy = "Healthy"
Unhealthy = "Unhealthy"
Version = "v1beta1"
DevicePluginPath = "/var/lib/kubelet/device-plugins/"
KubeletSocket = DevicePluginPath + "kubelet.sock"
KubeletPreStartContainerRPCTimeoutInSecs = 30
)上面的程式碼不需要我多說,非常簡單,在例項化ManagerImpl的時候把socket路徑傳進去了,關鍵是要找到程式碼的位置。socket路徑已經通過常數方式定義了,所以想通過配置選項調整也是不可能了,除非自己修改程式碼。下面就是分析當外掛註冊後Manager是如何處理的,位置也非常好找,只要找到ManagerImpl的Register函式就可以了。因為在啟動grpc服務的時候將ManagerImpl註冊為外掛註冊服務的處理器,那麼ManagerImpl就必須要有相應的註冊函式。下面是相應的程式碼:
// 程式碼來自kubernetes/pkg/kubelet/cm/devicemanager/manager.go
func (m *ManagerImpl) Register(ctx context.Context, r *pluginapi.RegisterRequest) (*pluginapi.Empty, error) {
metrics.DevicePluginRegistrationCount.WithLabelValues(r.ResourceName).Inc()
// 檢測外掛是否是相容的版本,此處就用到了api.proto中定義的註冊資訊中的版本
// 從程式碼中可以看出,kubelet是可以相容多個版本的,當前只相容一個版本
// var SupportedVersions = [...]string{"v1beta1"},這段程式碼定義在
// kubernetes/pkg/kubelet/apis/deviceplugin/v1beta1/constants.go檔案中
var versionCompatible bool
for _, v := range pluginapi.SupportedVersions {
if r.Version == v {
versionCompatible = true
break
}
}
// 如果版本不相容報錯,因為外掛和kubelet是兩個獨立的工程,版本校驗非常重要
if !versionCompatible {
errorString := fmt.Sprintf(errUnsupportedVersion, r.Version, pluginapi.SupportedVersions)
return &pluginapi.Empty{}, fmt.Errorf(errorString)
}
// 校驗資源名稱的合法性,乍一看以為是判斷是不是擴充套件資源(Is ExtendResource Name)的名稱呢,但是分析邏輯是
// 錯誤的,是擴充套件資源的名字反而報錯了。其實這裡就是判斷資源名稱的合法性(Is Extend ResourceName),
// kubernetes為資源定義了格式,vendor/device,比如nvidia.com/gpu
// kubernetes的native資源格式kubernetes.io/name此處資源名稱不能以kubernetes.io/開頭
// 同時也不能以requests.開頭,因為這是kubernetes預設的資源請求字首
if !v1helper.IsExtendedResourceName(v1.ResourceName(r.ResourceName)) {
errorString := fmt.Sprintf(errInvalidResourceName, r.ResourceName)
return &pluginapi.Empty{}, fmt.Errorf(errorString)
}
// 開啟協程新增外掛,此處為什麼要開協程?我猜是需要建立與外掛的連線,一個協程內
// 形成rpc的呼叫者被呼叫的環形操作,容易形成死鎖
go m.addEndpoint(r)
return &pluginapi.Empty{}, nil
}ManagerImpl通過註冊資訊新增endpoint,一個endpoint就代表一個外掛,下面是新增外掛的程式碼:
// 程式碼源自kubernetes/pkg/kubelet/cm/devicemanager/manager.go
func (m *ManagerImpl) addEndpoint(r *pluginapi.RegisterRequest) {
// 申請記憶體用於儲存已經存在的裝置
existingDevs := make(map[string]pluginapi.Device)
m.mutex.Lock()
// 看看外掛是不是已經註冊過了,判斷方法就是資源名稱(唯一)
old, ok := m.endpoints[r.ResourceName]
if ok && old != nil {
// 如果是已經註冊過的外掛,獲取外掛所有的裝置,並且標記為不健康狀態
evices := make(map[string]pluginapi.Device)
for _, device := range old.getDevices() {
device.Health = pluginapi.Unhealthy
devices[device.ID] = device
}
// 這些已經註冊過的外掛的裝置儲存在臨時變數中,作為已經存在的裝置
existingDevs = devices
}
m.mutex.Unlock()
// 在ManagerImpl中用endpointImpl表一個外掛,要為新註冊的外掛建立一個
// 新的endpointImpl物件,建立endpointImpl用到了已經存在的裝置,後面會有詳細說明
socketPath := filepath.Join(m.socketdir, r.Endpoint)
e, err := newEndpointImpl(socketPath, r.ResourceName, existingDevs, m.callback)
if err != nil {
return
}
m.mutex.Lock()
// 儲存外掛的選項,前面在proto中有說明選項有什麼意義
if r.Options != nil {
m.pluginOpts[r.ResourceName] = r.Options
}
// 這段程式碼肯定有一些人懵逼,前面不是已經賦值給old了麼,現在有獲取一次並且判斷
// 和old是否相同,這個重點在於這個函式鎖的位置,上面程式碼建立endpointImpl的時候
// 已經解鎖了,再加鎖存在一種可能就是外掛又註冊了一次,並且被其他協程處理完了
// 為了安全起見,多一次判斷是非常必要的。如果別的協程處理完了,此處就要停止
// 已經建立的endpointImpl。
ext := m.endpoints[r.ResourceName]
if ext != old {
m.mutex.Unlock()
e.stop()
return
}
// 新增到endpointImpl的map中,基本算是註冊。
m.endpoints[r.ResourceName] = e
m.mutex.Unlock()
// 如果同名的外掛存在,那麼就把老的外掛停止掉
if old != nil {
old.stop()
}
// 開啟協程執行endpointImpl,可以看出來ManagerImpl為每個外掛都開一個協程與之互動
go func() {
e.run() // 這個函式一直執行直到沒法從外掛獲取裝置狀態或者被停止
e.stop() // 退出後就停止的endpointImpl
m.mutex.Lock()
// 這裡要判斷一次endpointImpl是不是自己建立的,如果是就把外掛資源標記為不健康
// 如果不是說明在別的協程中已經把這個外掛處理過了,為什麼這麼做,還是鎖定問題
// 程式碼寫的還是非常漂亮的,贊一個!
if old, ok := m.endpoints[r.ResourceName]; ok && old == e {
m.markResourceUnhealthy(r.ResourceName)
}
m.mutex.Unlock()
}()
}這裡我們要做一些簡單的總結:
- ManagerImpl有兩個map,endpoints和pluginOpts,他們的key都是資源名稱,也就是外掛註冊時提供的RegisterRequest.resource_name,定義在api.proto中,你會發現proto定義的名稱在經過編譯輸出的go程式碼卻變成了RegisterRequest.ResourceName,這是因為go語言的大小寫約束,同時go可以在定義型別的時候指定序列化和反序列化變數的名稱,這一點注意一下,否則就對應不上了;
- endpoints的value型別是endpoint,用於儲存外掛在ManagerImpl的例項物件的,也就是說一個外掛在ManagerImpl裡面對應一個endpoint物件,其中endpoint是interface型別,endpointImpl是endpoint的實現類,所有對於外掛的操作都是通過endpointImpl實現的,可以斷定介面DevicePlugin的客戶端放在了endpointImpl裡面;
- pluginOpts裡面記錄了哪些外掛支援“選項”特性;
以上總結是對ManagerImpl一部分成員變數的說明,如果上來就把ManagerImpl的定義程式碼解釋一遍,估計很多人不好理解,我們通過“相對合理”的流程逐一把ManagerImpl的成員變數過一邊也就自然非常容易的理解ManagerImpl的原理與實現了。接下來很多人肯定會想後面的內容就是endpointImpl的定義是什麼了,這是普遍的“深度優先”的思路,這裡我打算採用“廣度優先”的思路分析。我們暫且知道有endpointImpl這個東西就行了,我們來看看ManagerImpl是如何實現Manager這個interface的其他介面函式的。我們先看GetCapacity() (v1.ResourceList, v1.ResourceList, []string)這個函式,為什麼我會選擇這個函式呢?那就要先說一些題外話:因為我一直在想kubelet通過外掛的方式擴充套件了資源,那麼資源是如何彙總到apiserver的,同時又是如何被scheduler分配的,所以我就找kubernetes/pkg/apis/core/types.go裡面對於Node的定義(Node是kubelet和apiserver之間同步節點狀態的資料型別,擴充套件資源應該儲存在這裡),有一個NodeStatus型別,裡面有Capacity(資源總容量)和Allocatable(資源分配量)兩個成員變數,型別都是ResourceList。看到了麼這兩個變數的型別和ManagerImpl.GetCapacity()返回的型別是一樣的,他們肯定有著什麼關係,只是少ManagerImpl.GetCapacity()是獲取節點上所有擴充套件資源(通過外掛方式提供)的容量的。通過這條線我們就可以找到這些擴充套件資源是如何管理的了。在分析ManagerImpl.GetCapacity()前,我們先看看ResourceList的定義:
// 源自kubernetes/pkg/apis/core/types.go,內嵌的型別讀者需要了解細節自行跳轉
type ResourceName string
type Quantity struct { // kubernetes/staging/src/k8s.io/apimachinery/pkg/api/resource/quantity.go
i int64Amount
d infDecAmount
s string
Format
}
type ResourceList map[ResourceName]resource.Quantity
// 此處我們不用關心細節,只要知道資源列表是一個map,key是資源名,value是資源量,資源量是可以採用多種方式表達的,這道這些就可以了。現在我們可以開始看看ManagerImpl.GetCapacity()的程式碼了:
// 程式碼源自kubernetes/pkg/kubelet/cm/devicemanager/manager.go
func (m *ManagerImpl) GetCapacity() (v1.ResourceList, v1.ResourceList, []string) {
needsUpdateCheckpoint := false
// 臨時變數,用於儲存資源總容量,可分配資源量和已經刪除的資源名稱
var capacity = v1.ResourceList{}
var allocatable = v1.ResourceList{}
deletedResources := sets.NewString()
m.mutex.Lock()
// 遍歷健康的裝置,ManagerImpl用healthyDevices成員變數儲存著全部的健康裝置
// ManagerImpl.healthyDevices是一個map,key是資源名稱,value是裝置裝置名稱集合
// ManagerImpl.healthyDevices按照資源名稱分類,每個分類下面是所有的裝置名稱
for resourceName, devices := range m.healthyDevices {
e, ok := m.endpoints[resourceName]
// 外掛不存在或者外掛長時間過期?
if (ok && e.stopGracePeriodExpired()) || !ok {
delete(m.endpoints, resourceName) // 刪除外掛
delete(m.healthyDevices, resourceName) // 刪除這個資源名稱的健康裝置
deletedResources.Insert(resourceName) // 記錄所有已刪除的資源名稱
needsUpdateCheckpoint = true
} else {
// 把健康的裝置新增到總資源容量和可分配資源容量兩個列表中
// 前面沒有深究資源容量定義,看看這裡採用了固定的單位
// DecimalSI是10進位制,精度為一百萬(M),這個和CPU資源定義是一樣的
// 裝置數*1000000就是節點上改資源名稱的資源量
capacity[v1.ResourceName(resourceName)] = *resource.NewQuantity(int64(devices.Len()), resource.DecimalSI)
allocatable[v1.ResourceName(resourceName)] = *resource.NewQuantity(int64(devices.Len()), resource.DecimalSI)
}
}
// 遍歷不健康的裝置
for resourceName, devices := range m.unhealthyDevices {
e, ok := m.endpoints[resourceName]
// 此處的處理方式和處理健康裝置方式一樣,不贅述
if (ok && e.stopGracePeriodExpired()) || !ok {
delete(m.endpoints, resourceName)
delete(m.unhealthyDevices, resourceName)
deletedResources.Insert(resourceName)
needsUpdateCheckpoint = true
} else {
// 獲取健康的資源數,因為上面先統計的是將康裝置
capacityCount := capacity[v1.ResourceName(resourceName)]
// 計算不健康的資源數
unhealthyCount := *resource.NewQuantity(int64(devices.Len()), resource.DecimalSI)
// 該資源總量是健康+不講康的總和
capacityCount.Add(unhealthyCount)
// 更新資源總容量
capacity[v1.ResourceName(resourceName)] = capacityCount
}
}
m.mutex.Unlock()
if needsUpdateCheckpoint {
m.writeCheckpoint()
}
// 這裡可以到該函式返回的是擴充套件資源總量、可分配資源總量以及刪除的資源
return capacity, allocatable, deletedResources.UnsortedList()
}那麼ManagerImpl.GetCapacity()是被誰呼叫的呢?在哪裡呼叫就有可能在哪裡找到資源管理方法,那利用比較好的IDE查詢一下,就會發現kubelet有一個ContainerManager的型別(前面介紹devicemanager包的時候提到過cm是什麼,就是ContainerManager的縮寫),ContainerManager有一個介面函式定義為:
// 程式碼源自kubernetes/pkg/kubelet/cm/container_manager.go
type ContainerManager interface {
......
// 看看這個函式的返回值和ManagerImpl.GetCapacity()一樣
// 而且函式名稱更加直觀了,就是獲取裝置外掛的資源容量
GetDevicePluginResourceCapacity() (v1.ResourceList, v1.ResourceList, []string)
......
}
// ContainerManager是interface型別,具體實現在別的檔案,本文引用linux系統的實現
// 程式碼源自kubernetes/pkg/kubelet/cm/container_manager_linux.go
func (cm *containerManagerImpl) GetDevicePluginResourceCapacity() (v1.ResourceList, v1.ResourceList, []string) {
return cm.deviceManager.GetCapacity()
}
// containerManagerImpl是通過deviceManager成員變數返回的,該變數是在下面程式碼初始化的
func NewContainerManager(mountUtil mount.Interface, cadvisorInterface cadvisor.Interface, nodeConfig NodeConfig, failSwapOn bool, devicePluginEnabled bool, recorder record.EventRecorder) (ContainerManager, error) {
......
if devicePluginEnabled {
// 就是這裡,我們前面分析的ManagerImpl在這裡被構造
cm.deviceManager, err = devicemanager.NewManagerImpl()
} else {
// 從1.10開始預設裝置外掛是使能的,所以這裡我們就不關注了
cm.deviceManager, err = devicemanager.NewManagerStub()
}
......
}前後可以聯絡起來了,containerManagerImpl是通過devicemanager.ManagerImpl實現裝置外掛資源管理的。而ContainerManager是Kubelet這個類的成員變數(這個讀者自行查詢,此處不列舉相關程式碼了),基本找到根兒了,因為Kubelet類基本代表了kubelet這個程式的全部。此處可以推出Kubelet利用ContainerManager獲取外掛資源,然後再將資源彙報給apiserver。我們繼續用IDE的查詢功能看看GetDevicePluginResourceCapacity()這個函式在哪裡引用?
//程式碼源自kubernetes/pkg/kubelet/kubelet_node_status.go
func (kl *Kubelet) defaultNodeStatusFuncs() []func(*v1.Node) error {
......
// 函式返回一個函式陣列,每個函式用於設定一種節點狀態,這種實現方式挺好玩兒
var setters []func(n *v1.Node) error
setters = append(setters,
......
// 這裡可以看到外掛資源容量作為節點MachineInfo的一部分
nodestatus.MachineInfo(string(kl.nodeName), kl.maxPods, kl.podsPerCore,
kl.GetCachedMachineInfo, kl.containerManager.GetCapacity,
kl.containerManager.GetDevicePluginResourceCapacity,
kl.containerManager.GetNodeAllocatableReservation, kl.recordEvent),
......)
......
}
// 那就有必要看看MachineInfo裡面是怎麼使用外掛資源的?
// 程式碼源於kubernetes/pkg/kubelet/nodestatus/setters.go
func MachineInfo(nodeName string, maxPods int, podsPerCore int,
machineInfoFunc func() (*cadvisorapiv1.MachineInfo, error),
capacityFunc func() v1.ResourceList,
devicePluginResourceCapacityFunc func() (v1.ResourceList, v1.ResourceList, []string),
nodeAllocatableReservationFunc func() v1.ResourceList, Kubelet.containerManager.GetNodeAllocatableReservation
recordEventFunc func(eventType, event, message string), ) Setter {
// 從函式名來看就是用來獲取機器資訊的,這個函式返回一個匿名函式設定節點資訊
// 這個函式傳入了好多獲取各種分類資訊的函式,此函式算是統一完成節點資訊的地方
return func(node *v1.Node) error {
// 申請記憶體用於設定節點狀態中的資源容量列表
if node.Status.Capacity == nil {
node.Status.Capacity = v1.ResourceList{}
}
var devicePluginAllocatable v1.ResourceList
var devicePluginCapacity v1.ResourceList
var removedDevicePlugins []string
// 不是我們關心的重點,不做過多註釋
info, err := machineInfoFunc()
if err != nil {
node.Status.Capacity[v1.ResourceCPU] = *resource.NewMilliQuantity(0, resource.DecimalSI)
node.Status.Capacity[v1.ResourceMemory] = resource.MustParse("0Gi")
node.Status.Capacity[v1.ResourcePods] = *resource.NewQuantity(int64(maxPods), resource.DecimalSI)
} else {
......
// 呼叫了我們上面提到的ContainerManager.GetDevicePluginResourceCapacity()
devicePluginCapacity, devicePluginAllocatable, removedDevicePlugins = devicePluginResourceCapacityFunc()
// 算是把所有外掛的資源列表拷貝了一遍吧
if devicePluginCapacity != nil {
for k, v := range devicePluginCapacity {
node.Status.Capacity[k] = v
}
}
// 把已經刪除的裝置也記錄在資源容量列表中,只是資源量為0,此處的目的暫不知
for _, removedResource := range removedDevicePlugins {
node.Status.Capacity[v1.ResourceName(removedResource)] = *resource.NewQuantity(int64(0), resource.DecimalSI)
}
}
......
// 拷貝可分配裝置資源列表
if devicePluginAllocatable != nil {
for k, v := range devicePluginAllocatable {
node.Status.Allocatable[k] = v
}
}
......
return nil
}
}我們已經跟蹤了好多程式碼,之後如何再呼叫defaultNodeStatusFuncs的分析讀者用一個IDE基本就能搞定,不再繼續分析了,是時候做一些總結性思考了,:
- Node.Status.Capacity和Node.Status.Allocatable記錄了節點全部資源,包括可用於分配的資源,其中Node是型別,定義在kubernetes/staging/src/k8s.io/api/core/v1/types.go中,Status、Capacity、Allocatable是成員變數名稱,這樣描述利於讀者理解;
- Kubelet.ContainerManager.DeviceManager是用於獲取所有外掛化資源資訊的3個型別,其中ContainerManager和DeviceManager是interface,他們的實現分別為containerManagerImpl和deviceManagerImpl,注意ContainerManager的實現會根據作業系統的型別有不同的實現;
- 資源列定義為type ResourceList map[ResourceName]resource.Quantity,就是一個資源名稱和資源量組合的map,所以必須要求所有外掛資源名稱要唯一,這也是為什麼nvidia定義的gpu資源是nvidia.com/gpu,cpu資源是kubernetes.io/cpu,kubernetes.io/字首是內部預定義的資源,不可以使用
- 從官方介紹外掛式裝置的文件來看,沒有看到關於排程相關的內容,只有介紹怎麼將裝置加入到系統中。資源是名字唯一的,如果不修改核心程式碼就可以用的話,新擴充套件進來的資源scheduler只能通過名字匹配的方式找到擁有該資源的節點,比如通過yaml檔案中spec.containers[i].resources.limits.nvidia.com/gpu:2;
上面程式碼的分析大概可以總結為下圖:
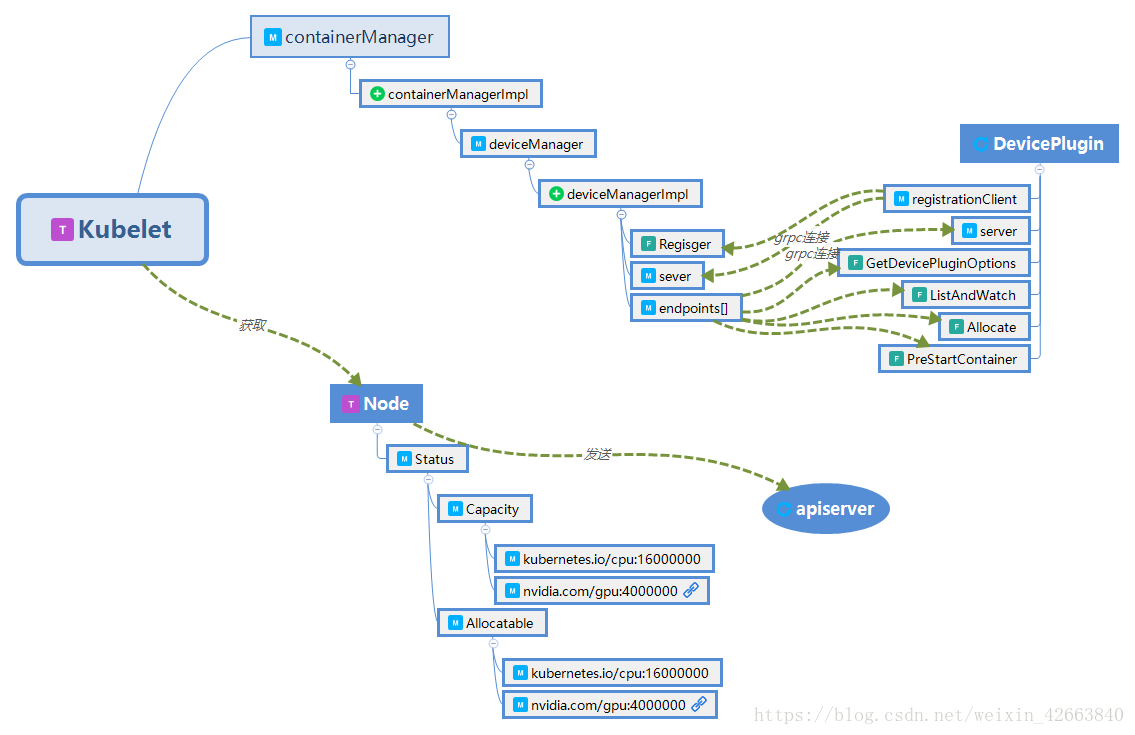
注:T為型別,M為成員,+為基類
接下來我們再來看看Scheduler是如何使用這些資源的, 由於我會專門針對kubernetes的Scheduler的原理與實現寫一篇文章,所以此處不詳細說明Scheduler。先直接奔重點,看下面的程式碼:
// 程式碼源於kubernetes/pkg/scheduler/cache/node_info.go
type Resource struct {
MilliCPU int64 // CPU,單位為1/百萬
Memory int64 // 記憶體,單位為位元組
EphemeralStorage int64 // 儲存,單位為位元組
AllowedPodNumber int // 允許的pod數量
ScalarResources map[v1.ResourceName]int64 // 擴充套件資源,這個和ResourceList沒差
}
// 通過ResourceList構造Resource 物件
func NewResource(rl v1.ResourceList) *Resource {
r := &Resource{} // 建立資源物件
r.Add(rl) // 新增資源
return r // 返回資源物件
}
// 向Resource 物件新增資源
func (r *Resource) Add(rl v1.ResourceList) {
if r == nil {
return
}
// 遍歷所有資源
for rName, rQuant := range rl {
switch rName {
case v1.ResourceCPU: // 累加CPU資源
r.MilliCPU += rQuant.MilliValue()
case v1.ResourceMemory: // 累加記憶體資源
r.Memory += rQuant.Value()
case v1.ResourcePods: // 累加pod數量
r.AllowedPodNumber += int(rQuant.Value())
case v1.ResourceEphemeralStorage: //累加儲存資源
r.EphemeralStorage += rQuant.Value()
default: // 其他的全部歸屬為擴充套件資源
if v1helper.IsScalarResourceName(rName) {
r.AddScalar(rName, rQuant.Value())
}
}
}
}
// 新增擴充套件資源
func (r *Resource) AddScalar(name v1.ResourceName, quantity int64) {
r.SetScalar(name, r.ScalarResources[name]+quantity)
}
// 設定擴充套件資源
func (r *Resource) SetScalar(name v1.ResourceName, quantity int64) {
// 擴充套件資源如果沒有初始化就新建map
if r.ScalarResources == nil {
r.ScalarResources = map[v1.ResourceName]int64{}
}
r.ScalarResources[name] = quantity
}從上面的程式碼可以看出,Scheduler對於資源重新進行了定義,這個很正常,兩個不同的模組(Scheduler和Kubelet)對於同一個事物的看的角度不同,定義自然不同。對於Scheduler來說主要排程的就是CPU、記憶體這些資源,專門定義一個變數儲存,這樣訪問效率要比每次都用名字從map中獲取高很多,當然也有歷史實現的原因。
知道Scheduler如何定義資源後,我們就要看Scheduler在排程的時候怎麼使用這些資源。如下程式碼所示:
// 程式碼源自kubernetes/pkg/scheduler/algorithms/predicates/predicates.go
var (
predicatesOrdering = []string{CheckNodeConditionPred, CheckNodeUnschedulablePred,
GeneralPred, HostNamePred, PodFitsHostPortsPred,
MatchNodeSelectorPred, PodFitsResourcesPred, NoDiskConflictPred,
PodToleratesNodeTaintsPred, PodToleratesNodeNoExecuteTaintsPred, CheckNodeLabelPresencePred,
CheckServiceAffinityPred, MaxEBSVolumeCountPred, MaxGCEPDVolumeCountPred,
MaxAzureDiskVolumeCountPred, CheckVolumeBindingPred, NoVolumeZoneConflictPred,
CheckNodeMemoryPressurePred, CheckNodePIDPressurePred, CheckNodeDiskPressurePred, MatchInterPodAffinityPred}
)
//上面的全域性變數定義了predicates的順序,我們只關注GeneralPred,其他的這裡不說明
func GeneralPredicates(pod *v1.Pod, meta algorithm.PredicateMetadata, nodeInfo *schedulercache.NodeInfo) (bool, []algorithm.PredicateFailureReason, error) {
var predicateFails []algorithm.PredicateFailureReason
fit, reasons, err := noncriticalPredicates(pod, meta, nodeInfo) // 下面有說明
......
}
func noncriticalPredicates(pod *v1.Pod, meta algorithm.PredicateMetadata, nodeInfo *schedulercache.NodeInfo) (bool, []algorithm.PredicateFailureReason, error) {
var predicateFails []algorithm.PredicateFailureReason
fit, reasons, err := PodFitsResources(pod, meta, nodeInfo) // 下面有說明
......
}
// 上面的程式碼就是為了展示呼叫順序,下面的才是主要內容,這個函式用於判斷
// 節點資源是否匹配,從這點可以看出呼叫這個函式肯定是用一個pod對於資源的請求
// 來遍歷所有的節點
func PodFitsResources(pod *v1.Pod, meta algorithm.PredicateMetadata, nodeInfo *schedulercache.NodeInfo) (bool, []algorithm.PredicateFailureReason, error) {
// 節點不存在返回錯誤
node := nodeInfo.Node()
if node == nil {
return false, nil, fmt.Errorf("node not found")
}
// 節點允許的Pod數量是否超過上限
var predicateFails []algorithm.PredicateFailureReason
allowedPodNumber := nodeInfo.AllowedPodNumber()
if len(nodeInfo.Pods())+1 > allowedPodNumber {
predicateFails = append(predicateFails, NewInsufficientResourceError(v1.ResourcePods, 1, int64(len(nodeInfo.Pods())), int64(allowedPodNumber)))
}
// 此處不是討論重點,不做過多介紹,就是獲取Pod的資源請求
ignoredExtendedResources := sets.NewString()
var podRequest *schedulercache.Resource
if predicateMeta, ok := meta.(*predicateMetadata); ok {
podRequest = predicateMeta.podRequest
if predicateMeta.ignoredExtendedResources != nil {
ignoredExtendedResources = predicateMeta.ignoredExtendedResources
}
} else {
podRequest = GetResourceRequest(pod)
}
// 如果pod沒有任何資源請求,那就直接返回,這裡的資源請求就是我們在yaml裡寫的
if podRequest.MilliCPU == 0 && podRequest.Memory == 0 &&
podRequest.EphemeralStorage == 0 && len(podRequest.ScalarResources) == 0 {
return len(predicateFails) == 0, predicateFails, nil
}
// 看到沒有,這裡就在用我們全文都在提到的資源,主要判斷的就是可用於分配的資源
allocatable := nodeInfo.AllocatableResource()
// 是否有足夠的CPU資源?
if allocatable.MilliCPU < podRequest.MilliCPU+nodeInfo.RequestedResource().MilliCPU {
predicateFails = append(predicateFails, NewInsufficientResourceError(v1.ResourceCPU, podRequest.MilliCPU, nodeInfo.RequestedResource().MilliCPU, allocatable.MilliCPU))
}
// 是否有足夠的記憶體資源?
if allocatable.Memory < podRequest.Memory+nodeInfo.RequestedResource().Memory {
predicateFails = append(predicateFails, NewInsufficientResourceError(v1.ResourceMemory, podRequest.Memory, nodeInfo.RequestedResource().Memory, allocatable.Memory))
}
// 是否有足夠的儲存資源
if allocatable.EphemeralStorage < podRequest.EphemeralStorage+nodeInfo.RequestedResource().EphemeralStorage {
predicateFails = append(predicateFails, NewInsufficientResourceError(v1.ResourceEphemeralStorage, podRequest.EphemeralStorage, nodeInfo.RequestedResource().EphemeralStorage, allocatable.EphemeralStorage))
}
// 對於擴充套件資源的判斷就在這裡了,遍歷pod所有擴充套件資源的需求
for rName, rQuant := range podRequest.ScalarResources {
// 判斷資源名稱是否合法,這個在前面提到過了
if v1helper.IsExtendedResourceName(rName) {
if ignoredExtendedResources.Has(string(rName)) {
continue
}
}
// 如果可用的擴充套件資源不足(包括不存在)則失敗,就這麼簡單應該符合大部分讀者的預期
if allocatable.ScalarResources[rName] < rQuant+nodeInfo.RequestedResource().ScalarResources[rName] {
predicateFails = append(predicateFails, NewInsufficientResourceError(rName, podRequest.ScalarResources[rName], nodeInfo.RequestedResource().ScalarResources[rName], allocatable.ScalarResources[rName]))
}
}
return len(predicateFails) == 0, predicateFails, nil
}以上是Scheduler排程的第一階段predicate,滿足條件的Node還會進入第二階段priorities,第一階段主要用於過濾,第二階段主要用於計算最優。我沒有在第二階段找到關於擴充套件資源相關的程式碼,所以我猜測Scheduler在排程擴充套件資源的時候不會計算擴充套件裝置的負載率,這一點在有些場合可能不符合預期,開發人員你可以自行設計更優的排程策略。
至此,我們把外掛化的裝置資源如何加入到kubernetes中,並且如何排程使用的基本講完了,關於DeviceManager和Plugin裝置的互動細節暫時不做說明,讀者應該可以看明白,等有時間我再補充上,畢竟這些內容的缺失不影響讀者對本文的理解。