
AdaBoost 人臉檢測介紹(3) : AdaBoost演算法流程
本系列文章總共有七篇,目錄索引如下:
AdaBoost 人臉檢測介紹(1) : AdaBoost身世之謎
AdaBoost 人臉檢測介紹(2) : 矩形特徵和積分圖
AdaBoost 人臉檢測介紹(3) : AdaBoost演算法流程
AdaBoost 人臉檢測介紹(4) : AdaBoost演算法舉例
AdaBoost 人臉檢測介紹(5) : AdaBoost演算法的誤差界限
AdaBoost 人臉檢測介紹(6) : 使用OpenCV自帶的 AdaBoost程式訓練並檢測目標
AdaBoost 人臉檢測介紹(7) : Haar特徵CvHaarClassifierCascade等結構分析
3. AdaBoost演算法流程
Adaboost是一種迭代方法,其核心思想是針對不同的訓練集訓練同一個弱分類器,然後把在不同訓練集上得到的弱分類器集合起來,構成一個最終的強分類器。
3.1 弱分類器的訓練及選取
最初的弱分類器可能只是一個最基本的Haar-like特徵,計算輸入影象的Haar-like特徵值,和最初的弱分類器的特徵值比較,以此來判斷輸入影象是不是人臉,然而這個弱分類器太簡陋了,可能並不比隨機判斷的效果好,對弱分類器的孵化就是訓練弱分類器成為最優弱分類器,注意這裡的最優不是指強分類器,只是一個誤差相對稍低的弱分類器,訓練弱分類器實際上是為分類器進行設定的過程。至於如何設定分類器,設定什麼,我們首先分別看下弱分類器的數學結構。
其中
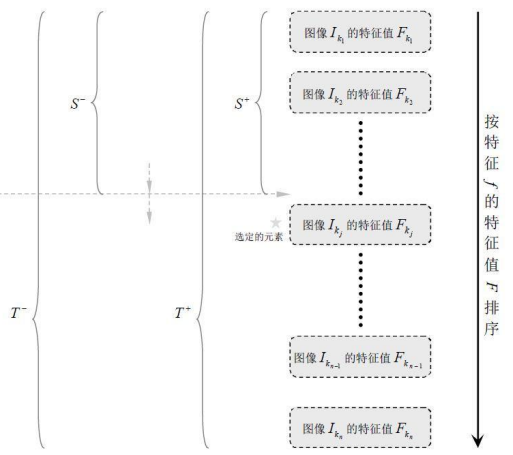
弱分類器訓練的過程大致分為如下幾步:
1)對每個特徵
2)將特徵值排序;
3)對排好序的每個元素計算:
3.1)全部正例的權重和
3.2)全部負例的權重和
3.3)該元素前正例的權重和
3.4)該元素前負例的權重和
4)選取當前元素的特徵值
於是,通過把這個排序表從頭到尾掃描一遍就可以為弱分類器選擇使分類誤差最小的閾值(最優閾值),也就是選取了一個最佳弱分類器。
3.2 訓練強分類器
給定一個訓練資料集
步驟1:首先,初始化訓練資料的權值分佈。每個訓練樣本初始都被賦予相同的權值:1/N。
步驟2:進行多輪迭代,用
a). 使用具有權值分佈
b). 計算
由上述式子可知,
c). 計算
由上述式子可知,
d). 更新訓練資料集的權值分佈(目的:得到樣本的新的權值分佈),用於下一輪迭代:
相關推薦
AdaBoost 人臉檢測介紹(3) : AdaBoost演算法流程
本系列文章總共有七篇,目錄索引如下: AdaBoost 人臉檢測介紹(1) : AdaBoost身世之謎 AdaBoost 人臉檢測介紹(2) : 矩形特徵和積分圖 AdaBoost 人臉檢測介紹(3) : AdaBoost演算法流程 AdaBoost 人臉檢
AdaBoost 人臉檢測介紹(2) : 矩形特徵和積分圖
本系列文章總共有七篇,目錄索引如下: AdaBoost 人臉檢測介紹(1) : AdaBoost身世之謎 AdaBoost 人臉檢測介紹(2) : 矩形特徵和積分圖 AdaBoost 人臉檢測介紹(3) : AdaBoost演算法流程 AdaBoost 人臉檢
adaboost 人臉檢測(3.2)
1. 弱分類器 在確定了訓練子視窗中的矩形特徵數量和特徵值後,需要對每一個特徵f ,訓練一個弱分類器h(x,f,p,O) 。 在CSDN裡編輯公式太困難了,所以這裡和公式有關的都用截圖了。 特別說明:在前期準備訓練樣本的時候,需要將樣本歸一化和灰度化到20*20的大小,
AdaBoost 人臉檢測介紹(6) : 使用OpenCV自帶的 AdaBoost程式訓練並檢測目標
6. 使用OpenCV自帶的 AdaBoost程式訓練並檢測目標 OpenCV自帶的AdaBoost程式能夠根據使用者輸入的正樣本集與負樣本集訓練分類器,常用於人臉檢測,行人檢測等。它的預設特徵採用了Haar,不支援其它特徵。人臉目標檢測分為三個
AdaBoost人臉檢測訓練演算法 (中)
(3)採用演算法選取優化的弱分類器 通過Adaboost演算法挑選數千個有效的haar特徵來組成人臉檢測器,Adaboost演算法中不同的訓練集是通過調整每個樣本對應的權重來實現的。 開始時,每個樣本對應的權重是相同的,對於h1分類錯誤的樣本,加大其對應的權重;而對於分類
AdaBoost人臉檢測訓練演算法 (下)
http://blog.csdn.net/hqw7286/article/details/5556812 就像我一開始說的,比起ViolaJones人臉檢測方法,Lienhart的人臉檢測方法只是在Harr-like特徵的選取、計算以及AdaBoost的訓練演算法上有區別。
AdaBoost人臉檢測演算法1(轉…
原文地址:AdaBoost人臉檢測演算法1(轉) 作者:shl504 目前因為做人臉識別的一個小專案,用到了AdaBoost的人臉識別演算法,因為在網上找到的所有的AdaBoost的簡介都不是很清楚,讓我看看頭腦發昏,所以在這裡打算花費比較長
AdaBoost人臉檢測原理
對人臉檢測的研究最初可以追溯到 20 世紀 70 年代,早期的研究主要致力於模板匹配、子空間方法,變形模板匹配等。近期人臉檢測的研究主要集中在基於資料驅動的學習方法,如統計模型方法,神經網路學習方法,統計知識理論和支援向量機方法,基於馬爾可夫隨機域的方法,以及基於膚色的人臉
Linux系統下利用OpenCV實現人臉檢測和基於LBPH演算法的人臉識別
本文主要的目的是進行人臉檢測和人臉識別。實驗環境為Ubuntu16.04 LTS虛擬機器版,技術為OpenCV,語言為c++。其中人臉檢測的主要過程是從一張圖片中檢測出人臉可以是一個或者是多個,然後用矩形或者圓形線圈標註出來。人臉識別是基於LBPH演算法實現
走近人臉檢測(1)——基本流程
人臉檢測的任務就是判斷給定的影象上是否存在人臉,如果人臉存在,就給出全部人臉所處的位置及其大小。由於人臉檢測在實際應用中的重要意義,早在上世紀70年代就已經有人開始研究,然而受當時落後的技術條件和有限的需求所影響,直到上世紀90年代,人臉檢測技術才開始加快向前發展的腳步,
【人臉檢測——基於機器學習3】AdaBoost算法
源代碼 夠快 等等 多個 利用 原理 設計 聯結 大量 簡介 主要工作 AdaBoost算法的人臉檢測算法包含的主要工作:(1)通過積分圖快速求得Haar特征;(2)利用AdaBoost算法從大量的特征中選擇出判別能力較強的少數特征用於人臉檢測分類;(3)提出一個
基於Adaboost的人臉檢測演算法
AdaBoost演算法是一種自適應的Boosting演算法,基本思想是選取若干弱分類器,組合成強分類器。根據人臉的灰度分佈特徵,AdaBoost選用了Haar特徵[38]。AdaBoost分類器的構造過程如圖2-4所示。 圖2-4 Adaboost分類器的構造過程 1)H
Adaboost算法詳解(haar人臉檢測)
nim -s current center one features 重疊 asc his Adaboost是一種叠代算法,其核心思想是針對同一個訓練集訓練不同的分類器(弱分類器),然後把這些弱分類器集合起來,構成一個更強的最終分類器(強分類器)。Adaboost算法本身是
基於AdaBoost算法——世紀晟結合Haar-like特征訓練人臉檢測識別
st算法 技術分享 測速 循環 family sca 假設 弱分類器 ada AdaBoost?算法是一種快速人臉檢測算法,它將根據弱學習的反饋,適應性地調整假設的錯誤率,使在效率不降低的情況下,檢測正確率得到了很大的提高。 系統在技術上的三個貢獻: 1.用簡單的H
人臉識別之人臉檢測(五)--adaboost總結,整理
20170706新增: 各種Adaboost variants的比較以及不均衡問題 1.這邊有個淺顯的解釋。 2.簡單解釋到程式碼實現。 3.相對來說,這個看起來不是個人總結。 4.手動C程式碼Adaboost + stump弱
ADABOOST做人臉檢測程式與原理
ADABOOST做人臉識別原理+程式詳解 **注意:**adaboost演算法的目的是做一個目標檢測,舉個例子在人臉識別中,adaboost只能檢測出一張圖片中的人臉,並不能區分這些人臉分別是誰。 *1. 演算法的整體流程* 人臉檢測(face det
人臉檢測(五)--adaboost總結,整理
20170706新增: 各種Adaboost variants的比較以及不均衡問題 1.這邊有個淺顯的解釋。 2.簡單解釋到程式碼實現。 3.相對來說,這個看起來不是個人總結。 4.手動C程式碼Adaboost + stump弱分類
基於haar+adaboost的人臉檢測、深度學習的人臉識別技術應用綜述
目錄 第一節 核心技術 3 一、人臉檢測 3 二、特徵點檢測 5 三、人臉歸一化 5 四、人臉驗證 5 第二節 人臉識別技術應用 6 一、入庫照片及背景要求 6 二、三種應用模式 7 三、人臉識別應用場景 7 (一
人臉檢測(Haar特徵+Adaboost級聯分類器)
一、Haar分類器的前世今生 人臉檢測屬於計算機視覺的範疇,早期人們的主要研究方向是人臉識別,即根據人臉來識別人物的身份,後來在複雜背景下的人臉檢測需求越來越大,人臉檢測也逐漸作為一個單獨的研究方向發展起來。 目前的人臉檢測方法主要有兩大類:基於知識和基於統計。 “
人臉檢測流程及正負樣本下載
http 下載 zip 流程 能夠 image 不想 lfw art 人臉檢測做訓練當然能夠用OpenCV訓練好的xml。可是豈止於此。我們也要動手做!~ 首先是樣本的選取。樣本的選取非常重要。找了非常久才發現幾個靠譜的。 人臉樣本:http://www.visio