
爬蟲技巧-西瓜視訊MP4地址獲取
記錄一下西瓜視訊MP4地址的獲取步驟
目標:
指定西瓜視訊地址,如 https://www.ixigua.com/a6562763969642103303/#mid=6602323830,獲取其視訊MP4檔案的下載地址
以下使用chrome瀏覽器
開始分析:
首先在瀏覽器中開啟視訊頁面,開啟審查元素(右鍵-> 審查元素 或 F12)並重新整理頁面,檢視network選項中抓到的包
技巧1:
由於我們獲取的是視訊檔案的下載地址,而視訊檔案一般比較大,所以可以在network的包列表中使用 Size 排序一下 檢視最大的幾個包
如圖:
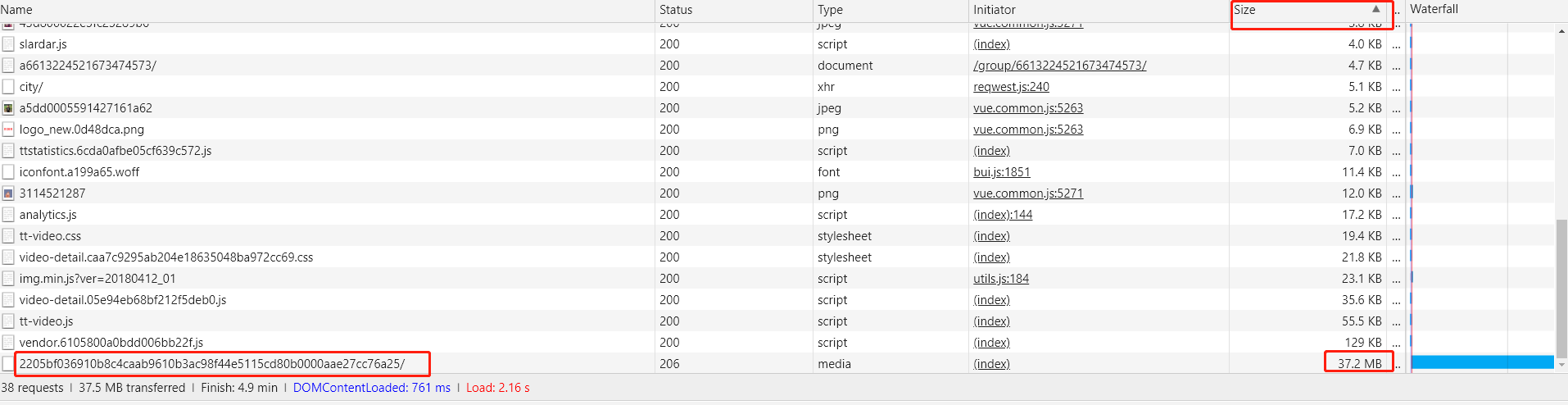
這裡我們很容易就能確定視訊檔案的地址
http://v11-tt.ixigua.com/5cc4c0ae0f7d6f87014dc0f0058157e0/5bcc7300/video/m/220f87599d445a14a53803fd01d86816e971157c7a70000cab5121742cc/
(你得到的地址和我得到的可能不一樣,不過url路徑中的最後一串字串應該是一樣的)
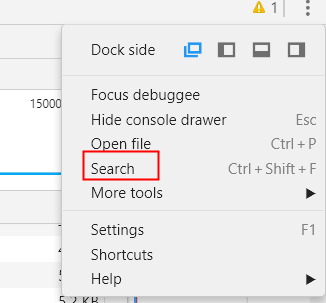
下面我們就要尋找這個地址是從哪裡獲取的,一般做法就是擷取url中比較有代表的部分(這個看經驗,你應該懂的)來搜尋,搜尋可以使用chrome審查元素的Search功能
相關推薦
爬蟲技巧-西瓜視訊MP4地址獲取
記錄一下西瓜視訊MP4地址的獲取步驟 目標: 指定西瓜視訊地址,如 https://www.ixigua.com/a6562763969642103303/#mid=6602323830,獲取其視訊MP4檔案的下載地址 以下使用chrome瀏覽器 開始分析: 首先在瀏覽器中開啟視訊頁
獲取優酷(youku),土豆(tudou),樂視(letv),愛奇藝(iqiyi)等HTML5頁面上的視訊真正地址
http://blog.csdn.net/conowen/article/details/24027401 /********************************************************************************
獲取網頁中的視訊下載地址(利用抓包)
根據上篇文章的思路,我用了監聽網絡卡流量的方式來改進了我的程式。速度得到了大大的提升。 思路 下圖是我用wireshark做的實驗。把請求路徑中帶.mp4, .flv的請求留下來,得到的就是請求的視訊資源了。 在wireshark的試驗下,我確定了
視訊學習 ---------如何獲取Mp4某個box下面的資料
學習是需要積累的,是需要記錄的,非常的抱歉,這麼久都沒有記錄我學習的過程了。今天記錄的是獲取MP4視訊下某個特定Box的資料。首先大致介紹下MP4下面的box組成。 結構圖如下: 這是在PC端用工具開啟的,從這個可以看到MP4裡面主要有4個主Box,分別是 ftyp、fre
視訊網站(網頁)上獲取視訊源地址 詳細過程
此方式獲得的視訊源地址,可以用來Android網路視訊程式設計。 下面詳細說一下如何獲取視訊源地址 0.視訊碼源舉例 http://10.10.254.2/mp4files/51650000008304B3/58.205.214.149/vmind.qqvideo.tc.q
獲取視訊真實地址的初中高三個階段
看到你自己喜愛的音樂動畫或是自己心儀的絢麗無比的FLASH素材,你一定會想:在我的部落格上發表多好!可是你找不到FLASH的真實地址,只採取複製的辦法,往往會不盡人意。我這裡給你介紹幾個如何找到FLASH地址的辦法,你不妨試試,看看滿意嗎? 一,初級篇 想要把喜歡
PHP開發小技巧②③—根據ip地址獲取城市
這個方法我們用的還是比較多的,便於收集資訊用於資料探勘分析。此方法不光根據ip地址進行獲取當前城市還可以根據http請求獲取使用者的城市位置。 實現方法:主要是根據高德地圖API進行獲取,首先註冊成為高德地圖使用者,然後認證成為開發者,建
獲取網頁中的視訊下載地址(用headless browser)
介紹 前面通過兩篇文章講了怎麼去抓取HTTP的請求包,包括用代理伺服器和抓包的方法。正因為現在的視訊網站的視訊地址都不是直接在html頁面上獲取的,視訊的獲取是通過瀏覽器動態解釋js指令碼,再向視訊伺服器發去視訊請求。所以我們通過獲取瀏覽器產生的HTTP請求來
python實現同服站點地址獲取
.cn class return 字符串 ... urlencode 一個 req exc 說明:程序使用http://s.tool.chinaz.com/same此站點查詢的結果。使用python簡單的實現抓取結果 先隨便查詢一個結果,抓包分析,如圖:
爬蟲小探-Python3 urllib.request獲取頁面數據
text height urlopen -s mozilla 使用 pri 爬蟲 size 使用Python3 urllib.request中的Requests()和urlopen()方法獲取頁面源碼,並用re正則進行正則匹配查找需要的數據。 #forex.py#co
jQuery通過地址獲取經緯度demo
text console 服務器 展示 content 百度地圖 index min 類型 在開始之前,首先需要登錄百度地圖API控制臺申請密鑰ak。 1、登錄百度地圖開放平臺http://lbsyun.baidu.com 註冊賬號,完善信息,點擊網站右上角的“API控制臺
第三百三十三節,web爬蟲講解2—Scrapy框架爬蟲—Scrapy模擬瀏覽器登錄—獲取Scrapy框架Cookies
pid 設置 ade form 需要 span coo decode firefox 第三百三十三節,web爬蟲講解2—Scrapy框架爬蟲—Scrapy模擬瀏覽器登錄 模擬瀏覽器登錄 start_requests()方法,可以返回一個請求給爬蟲的起始網站,這個返回的請求相
【小程序】獲取微信 自帶的 收貨地址獲取和整理
code blog itl ucc success span .info toa pan 1、wx.chooseAddress(OBJECT) if(wx.chooseAddress){ wx.chooseAddress({ success: function (r
C# 通過url地址獲取頁面內容
pre .html res htm 頁面 ons light ebr dto using System.Net; using System.IO; HttpWebRequest request = (HttpWebRequest)WebRequest
C#實現根據給出的相對地址獲取網站絕對地址的方法
nor 區別 ike orm add index div path 鏈接 本文實例講述了C#實現根據給出的相對地址獲取網站絕對地址的方法。分享給大家供大家參考。具體分析如下: 這段C#代碼在ASP.NET的項目中可以根據給定的相對地址獲取絕對訪問地址,例如:給出 /cod
Python:爬蟲技巧總結!
gen name server 解析 num erro dde 資料 pre 一些常用的爬蟲技巧歸納與以下幾點: 1、基本抓取網頁 get方法 import urllib2 url "http://www.baidu.com" respons = urllib2.urlop
.net從網絡接口地址獲取json,然後解析成對象(二)
ESS 代碼 ring amp type .get div cep quest 整理代碼,這是第二種方法來讀取json,然後反序列化成對象的,代碼如下: 1 public static Order GetOrderInfo(string _tid, string _or
百度地圖根據輸入地址獲取坐標
pan nav 慣性 nbsp 滾輪 tle ner .com 一次 首先新建一個html頁面,然後引用百度地圖api: <html xmlns="http://www.w3.org/1999/xhtml"> <head> <titl
Python網絡爬蟲技巧小總結,靜態、動態網頁輕松爬取數據
開發者工具 cap 簡單 pos 動態網頁 class 查看 這樣的 bsp 很多人學用python,用得最多的還是各類爬蟲腳本:有寫過抓代理本機驗證的腳本,有寫過自動收郵件的腳本,還有寫過簡單的驗證碼識別的腳本,那麽我們今天就來總結下python爬蟲抓站的一些實用技巧。
Python 爬蟲技巧1 | 將爬取網頁中的相對路徑轉換為絕對路徑
1.背景: 在爬取網頁中的過程中,我對目前爬蟲專案後端指令碼中拼接得到絕對路徑的方法很不滿意,今天很無意瞭解到在python3 的 urllib.parse模組對這個問題有著非常完善的解決策略,真的是上天有眼,感動! 2.urllib.parse模組 This module define