
Eclipse環境搭建並且執行wordcount程式
阿新 • • 發佈:2018-10-31
一、安裝Hadoop外掛
1. 所需環境
hadoop2.0偽分散式環境平臺正常執行
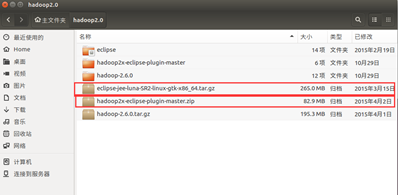
所需壓縮包:eclipse-jee-luna-SR2-linux-gtk-x86_64.tar.gz
在Linux環境下執行的eclipse軟體壓縮包,解壓後文件名為eclipse
hadoop2x-eclipse-plugin-master.zip
在eclipse中需要安裝的Hadoop外掛,解壓後文件名為hadoop2x-eclipse-plugin-master
如圖所示,將所有的壓縮包放在同一個資料夾下並解壓。
2.編譯jar包
編譯hadoop2x-eclipse-plugin-master的plugin 的外掛原始碼,需要先安裝ant工具
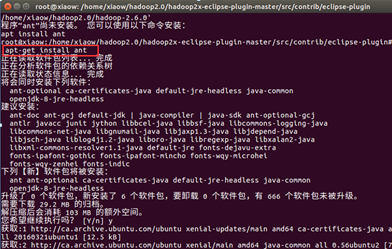
接著輸入命令:
ant jar -Dversion=2.6.0 -Declipse.home='/home/xiaow/hadoop2.0/eclipse' # 剛才放進去的eclipse軟體包的路徑 -Dhadoop.home='/home/xiaow/hadoop2.0/hadoop-2.6.0' # hadoop安裝檔案的路徑
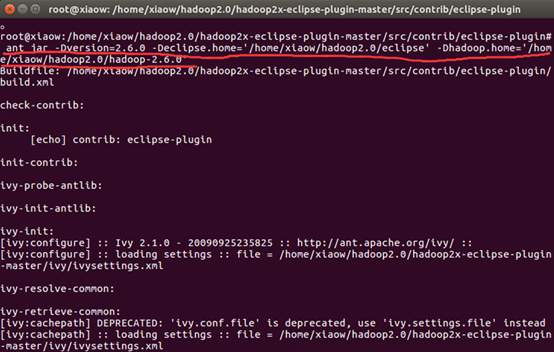
等待一小會時間就好了
編譯成功後,找到放在 /home/xiaow/ hadoop2.0/hadoop2x-eclipse-pluginmaster/build/contrib/eclipse-plugin下, 名為hadoop-eclipse-plugin-2.6.0.jar的jar包, 並將其拷貝到/hadoop2.0/eclipse/plugins下
輸入命令:
cp -r /home/xiaow/hadoop2.0/hadoop2x-eclipse-plugin-master/build/contrib/eclipse-plugin/hadoop-eclipse-plugin-2.6.0.jar /home/xiaow/hadoop2.0/eclipse/plugins/
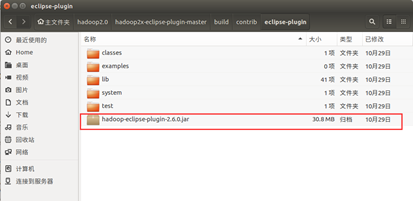


二、Eclipse配置
接下來開啟eclipse軟體
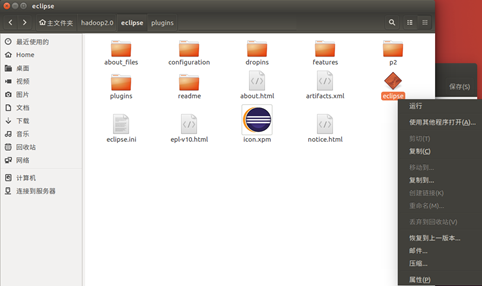
一定要出現這個圖示,沒有出現的話前面步驟可能錯了,或者重新啟動幾次Eclipse
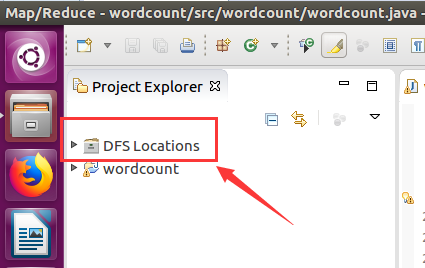
然後按照下面的截圖操作:
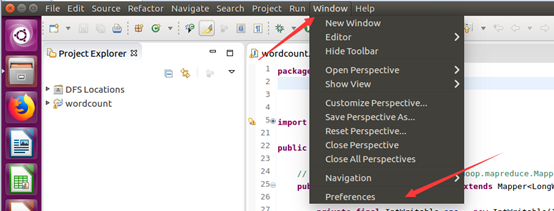
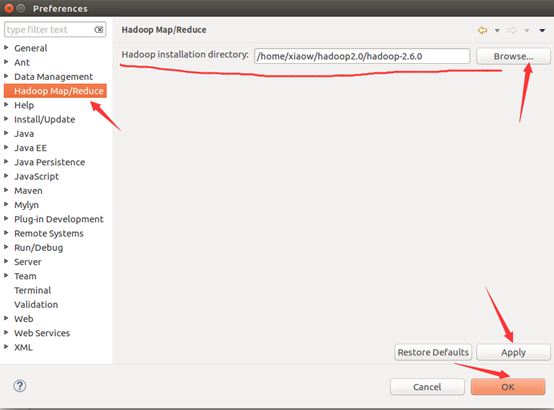
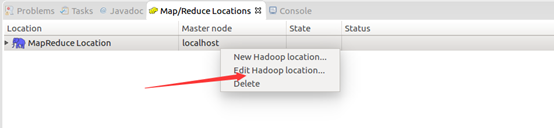

如此,Eclipse環境搭建完成。
三、wordcount程式
建工程:
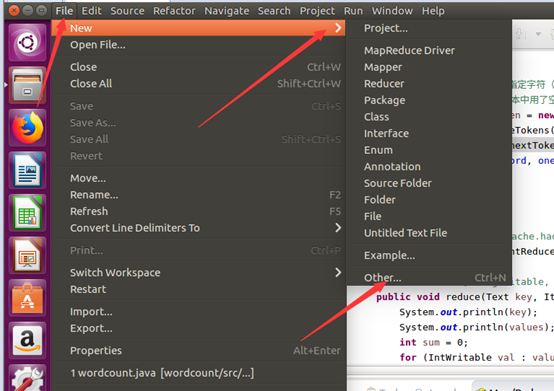
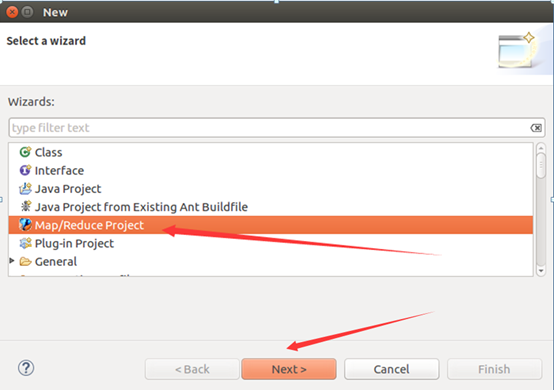
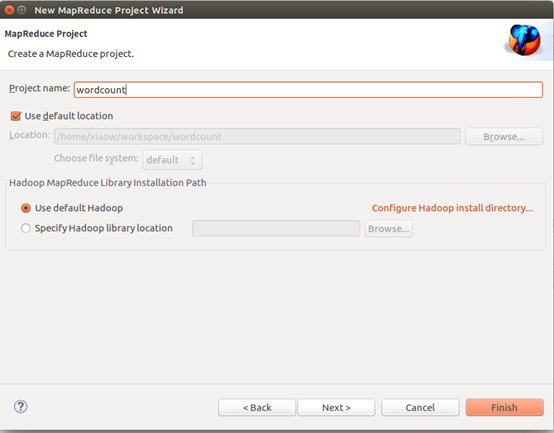
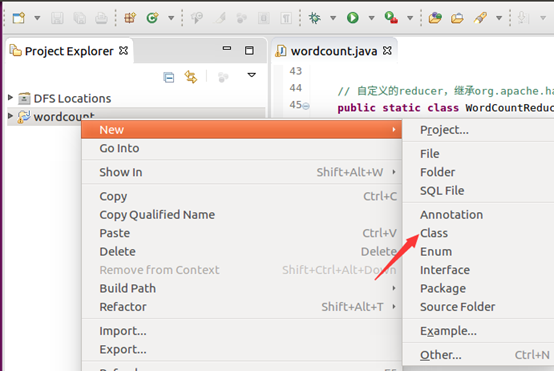
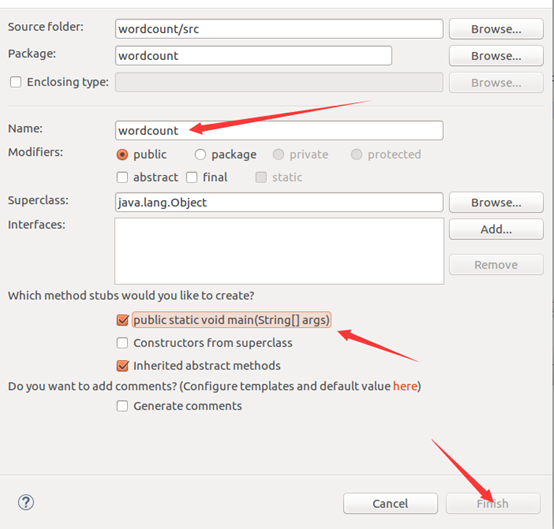
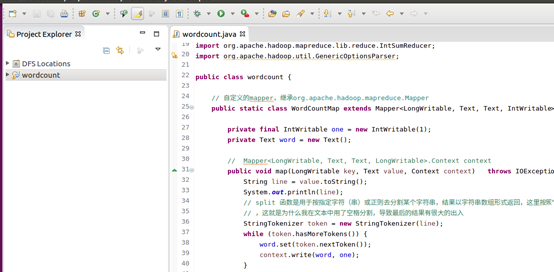
輸入如下程式碼:
package wordcount;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.reduce.IntSumReducer;
import org.apache.hadoop.util.GenericOptionsParser;
public class wordcount {
// 自定義的mapper,繼承org.apache.hadoop.mapreduce.Mapper
public static class WordCountMap extends Mapper<LongWritable, Text, Text, IntWritable> {
private final IntWritable one = new IntWritable(1);
private Text word = new Text();
// Mapper<LongWritable, Text, Text, LongWritable>.Context context
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
System.out.println(line);
// split 函式是用於按指定字元(串)或正則去分割某個字串,結果以字串陣列形式返回,這裡按照“\t”來分割text檔案中字元,即一個製表符
// ,這就是為什麼我在文字中用了空格分割,導致最後的結果有很大的出入
StringTokenizer token = new StringTokenizer(line);
while (token.hasMoreTokens()) {
word.set(token.nextToken());
context.write(word, one);
}
}
}
// 自定義的reducer,繼承org.apache.hadoop.mapreduce.Reducer
public static class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
// Reducer<Text, LongWritable, Text, LongWritable>.Context context
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
System.out.println(key);
System.out.println(values);
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
// 客戶端程式碼,寫完交給ResourceManager框架去執行
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf,"word count");
// 打成jar執行
job.setJarByClass(wordcount.class);
// 資料在哪裡?
FileInputFormat.addInputPath(job, new Path(args[0]));
// 使用哪個mapper處理輸入的資料?
job.setMapperClass(WordCountMap.class);
// map輸出的資料型別是什麼?
//job.setMapOutputKeyClass(Text.class);
//job.setMapOutputValueClass(LongWritable.class);
job.setCombinerClass(IntSumReducer.class);
// 使用哪個reducer處理輸入的資料
job.setReducerClass(WordCountReduce.class);
// reduce輸出的資料型別是什麼?
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// job.setInputFormatClass(TextInputFormat.class);
// job.setOutputFormatClass(TextOutputFormat.class);
// 資料輸出到哪裡?
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 交給yarn去執行,直到執行結束才退出本程式
job.waitForCompletion(true);
/*
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length<2){
System.out.println("Usage:wordcount <in> [<in>...] <out>");
System.exit(2);
}
for(int i=0;i<otherArgs.length-1;i++){
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
System.exit(job.waitForCompletion(tr0ue)?0:1);
*/
}
}
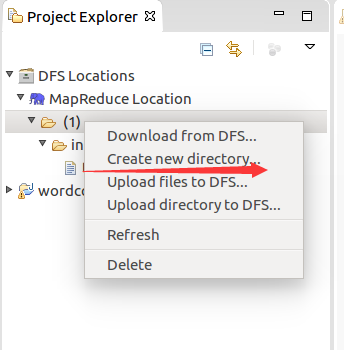
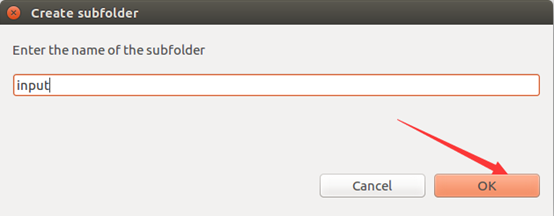
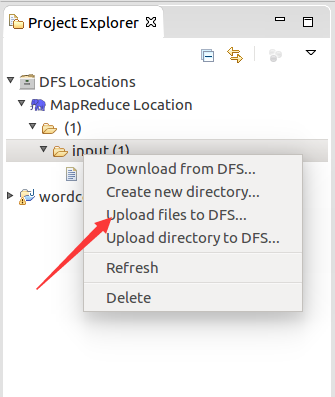
將準備到的文件匯入進去
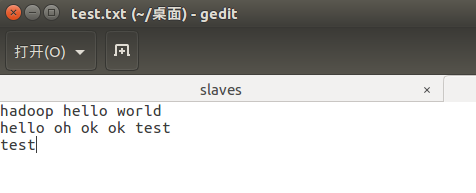
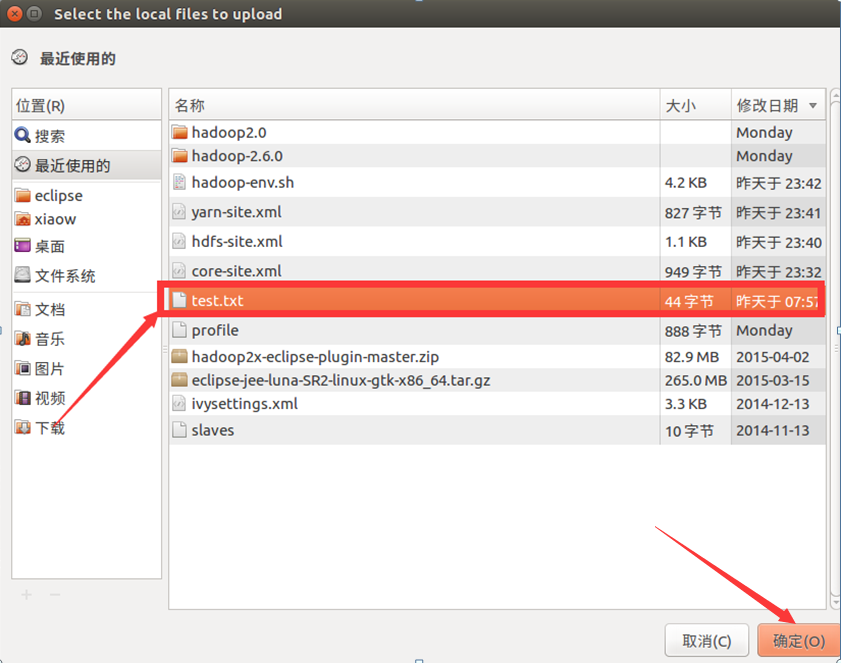
目錄結構如下:
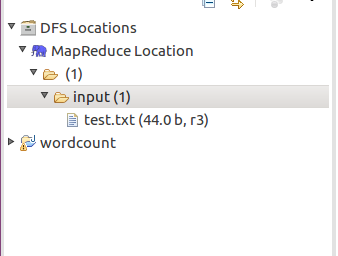
執行mapreduce程式
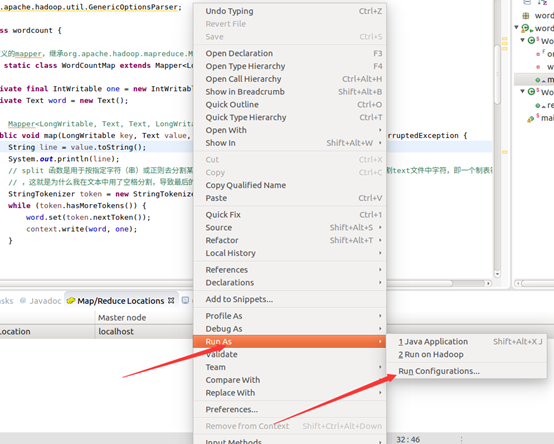
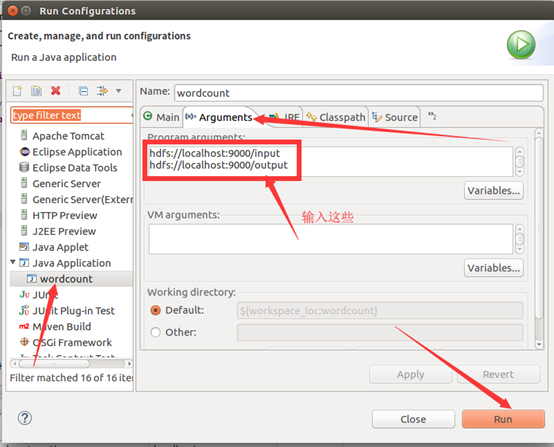
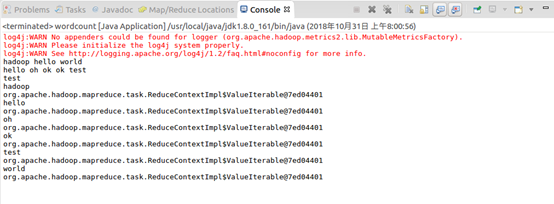
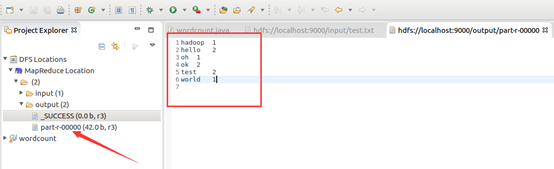
OK,搞定收工!!!