
配置 hadoop 開發環境+執行 wordcount 程式
一. eclipse 中 hadoop 環境部署概覽
eclipse 中部署 Hadoop 包括兩大部分:Hdfs 環境部署和 MapReduce 任務執行環境部署。一般 Hdfs 環境部署比較簡單,部署後就可以在 eclipse 中像操作 windows 目錄一樣操作 Hdfs 檔案。而 MapReduce 任務執行環境的部署就比較複雜一點,不同版本對環境的要求度高低不同就導致部署的複雜度大相徑庭。例如 Hadoop1 包括以前的版本部署就比較簡單,可在 Windows 和 Linux 執行部署執行,而 Hadoop2 及以上版本對環境要求就比較嚴格,一般只能在 Linux 中部署,如果需要在 windows 中部署需要使用 cygwin 等軟體模擬 Linux 環境,該篇介紹在 Linux 環境中部署 Hadoop 環境。該篇假設 hadoop2.5.0-cdh5.3.2 叢集已經部署完成,叢集訪問許可權為 hadoop5 使用者。這種在 eclipse 上操作 Hdfs 和提交 MapReduce 任務的方式為 Hadoop 客戶端操作,故無須在該機器上配置 Hadoop 叢集檔案,也無須在該機器上啟動 hadoop 相關程序。
二. 前期準備
1. 下載部署 eclipse
下載 eclipse ,筆者所用版本為 eclipse-jee-juno-SR2-linux-gtk-x86_64.tar
解壓後,將 eclipse 壓縮包放置在當前使用者的 /home/hadoop5/softwares/tar_packages 路徑下,然後解壓到 ~/softwares/ 的路徑下
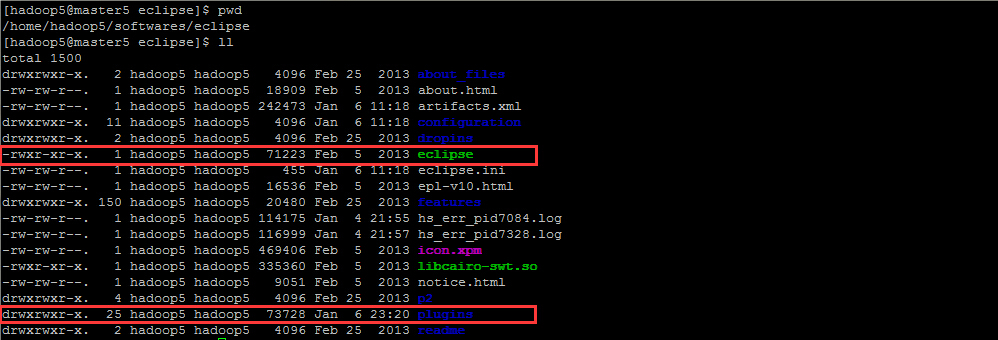
tar -zxvf eclipse-jee-juno-SR2-linux-gtk-x86_64.tar.gz -C ~/softwares/解壓後的 eclipse 的路徑目錄如下圖所示:
2. 下載外掛
外掛用的是 hadoop-eclipse-plugin-2.5.1.jar
將自己打包或者下載的 hadoop-eclipse 直接的外掛匯入 eclipse 的 plugins 目錄(複製進去即可),該篇使用直接下載的外掛 hadoop-eclipse-plugin-2.5.1.jar,然後啟動 eclipse。
./eclipse 開啟 eclipse 後,出現程序 org.eclipse.equinox.launcher_1.3.0.v20120522-1813.jar
Note: 建議安裝第三方外掛 FatJar,點選這裡檢視
三. 配置 Hadoop 開發環境
1. 切換到 Hadoop 的程式設計主介面
Window -> Show View -> Other -> Map/Reduce Locations
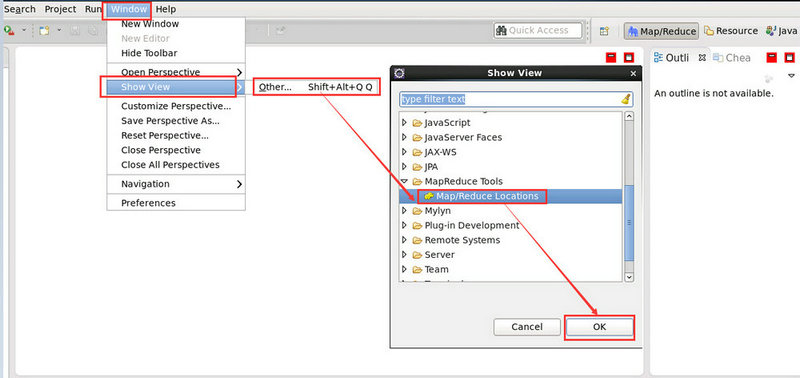
然後恢復到初始的 MapReduce 的程式設計介面
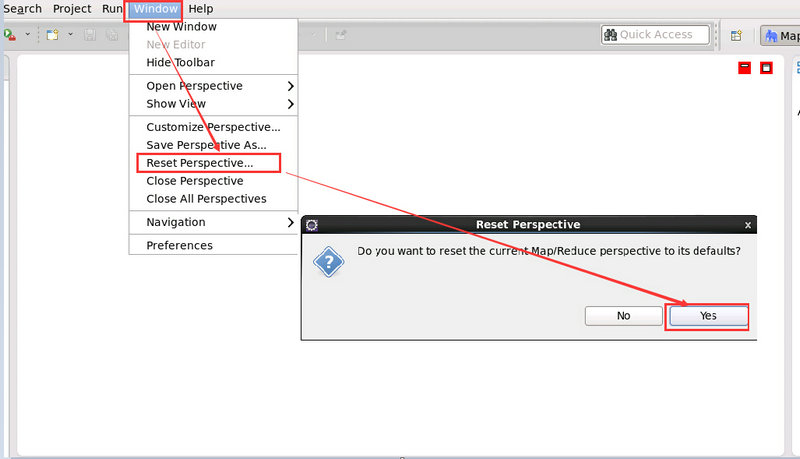
Window -> Reset Perspective -> Yes
2. 可見 Hadoop-eclipse 外掛已生效
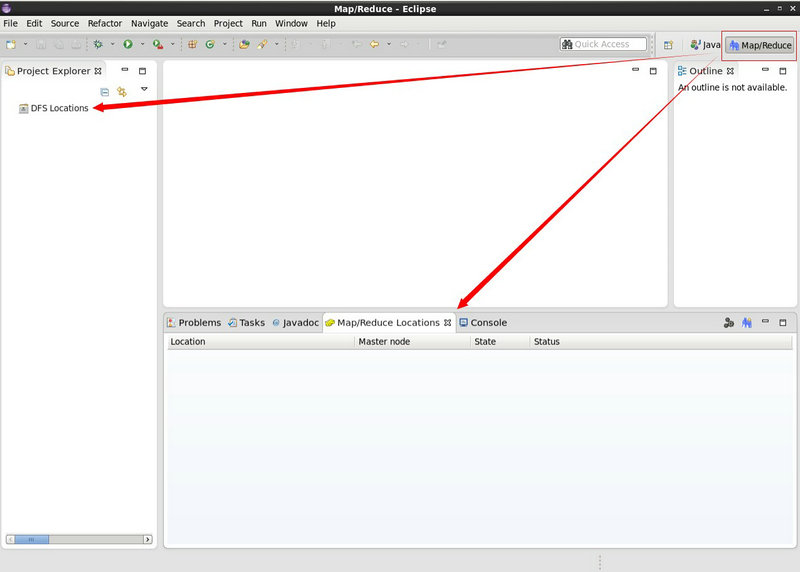
將下載的 hadoop-eclipse-plugin-2.5.1.jar 檔案放到 Eclipse 的 plugins 目錄下,重啟 Eclipse 即可看到該外掛已生效,一個是 DFS 顯示的位置,一個是 mapreduce 顯示的位置,具體如下圖所示:
3. 選擇 Hadoop 安裝目錄
在 eclipse 中配置 hadoop 安裝目錄:
Window—>Preference,選擇 Hadoop Map/Reduce
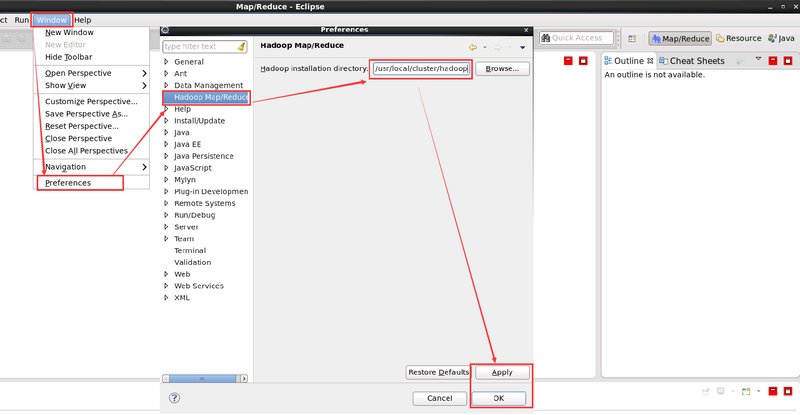
紅線圈出的部分為 Hadoop 的安裝目錄
4. 建立 New hadoop location
在 MapReduce Locations 出處點選右鍵新建 mapreduce 配置環境,具體圖示如下:

5. 配置新建的 New hadoop location
進入 mapreduce 配置環境,具體如下圖所示。
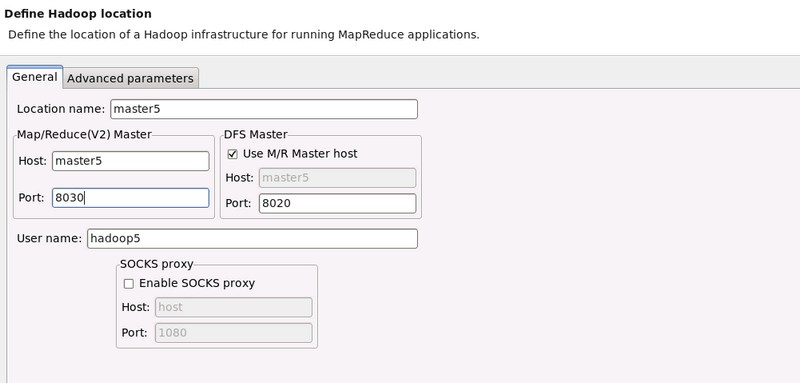
- Location name 可任意填寫
- Map/Reduce(V2) Master 中 Host 為 ResourceManager 機器 ip
- Map/Reduce(V2) Master 中 Port 為 ResourceManager 接受任務的埠號,即 yarn-site.xml 檔案中yarn.resourcemanager.scheduler.address配置項中埠號

- DFS Master 中的 Host 為 NameNode 機器 ip,Port 為 core-site.xml 檔案中 fs.defaultFS 配置項中埠號

6. 檢視最終連線效果
上一步驟配置完成後,我們看到的介面如下圖所示。左側欄中即為 hdfs 目錄,在每個目錄上可點選右鍵操作
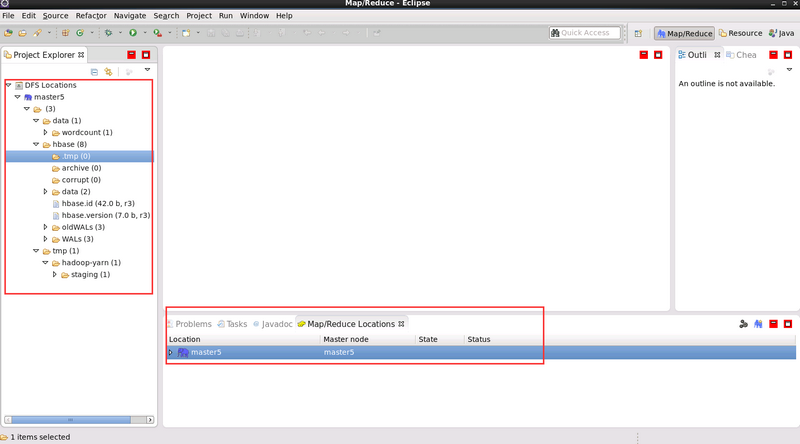
當然,上面的 data 的目錄是預先建立好的,而 tmp 和 hbase 是開始歷史伺服器和 HBase 後自動生成的
四. Eclipse 中直接提交 MapReduce任務
eclipse 中直接提交 mapreduce 任務(此處以 wordcount 為例,同時注意 hadoop 叢集防火牆需對該機器開放相應埠,關閉防火牆最省事了)
如果我們將 hadoop 自帶的 wordcount 在 eclipse 中執行是不可以的,調整後具體操作如下。
4.1 新建 Map/Reduce工程
新建Map/Reduce工程的特點就是 無須手動匯入 hadoop jar 包
1. 建立 Map/Reduce 工程
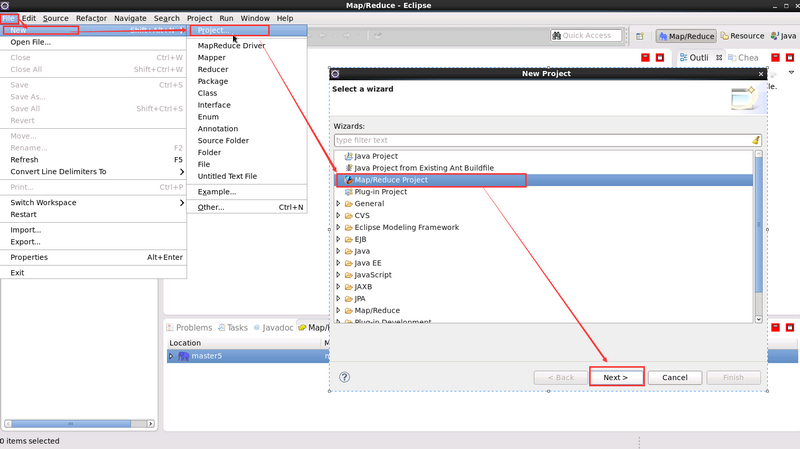
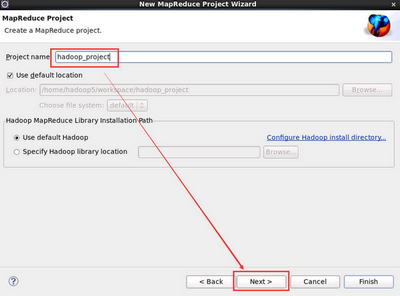
2. 點選 next 輸入 hadoop 工程名即可

3. 新建 Wordcount 類
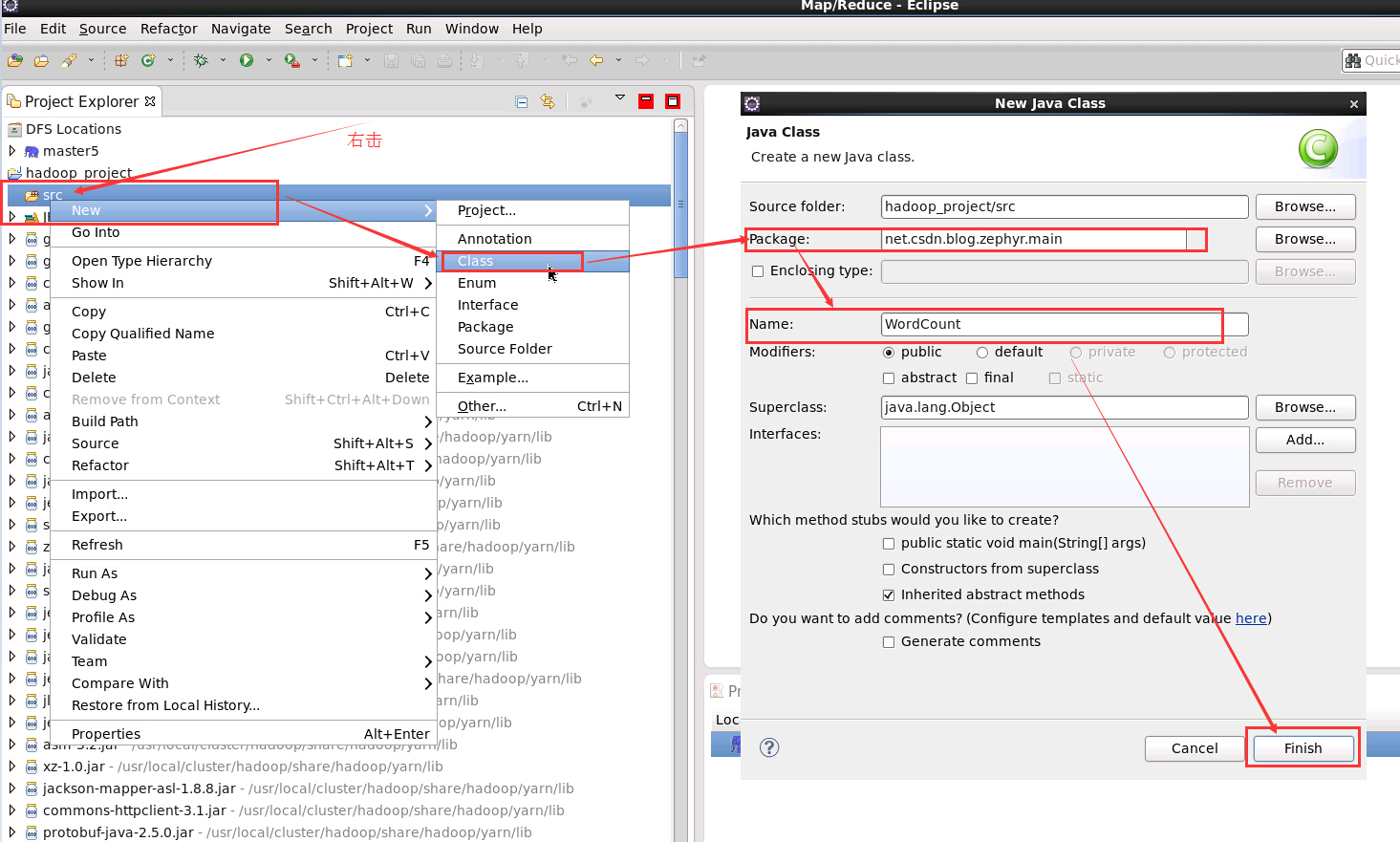
在新建的 WordCount 類中新增如下程式碼:
package net.csdn.blog.zephyr.main;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs =
new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = Job.getInstance(conf);
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
public static class TokenizerMapper extends
Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
}4. 執行程式
首先上傳檔案到 HDFS 上,這步驟筆者我就不贅述了,筆者我上傳的是 slaves 檔案
- 先設定執行引數
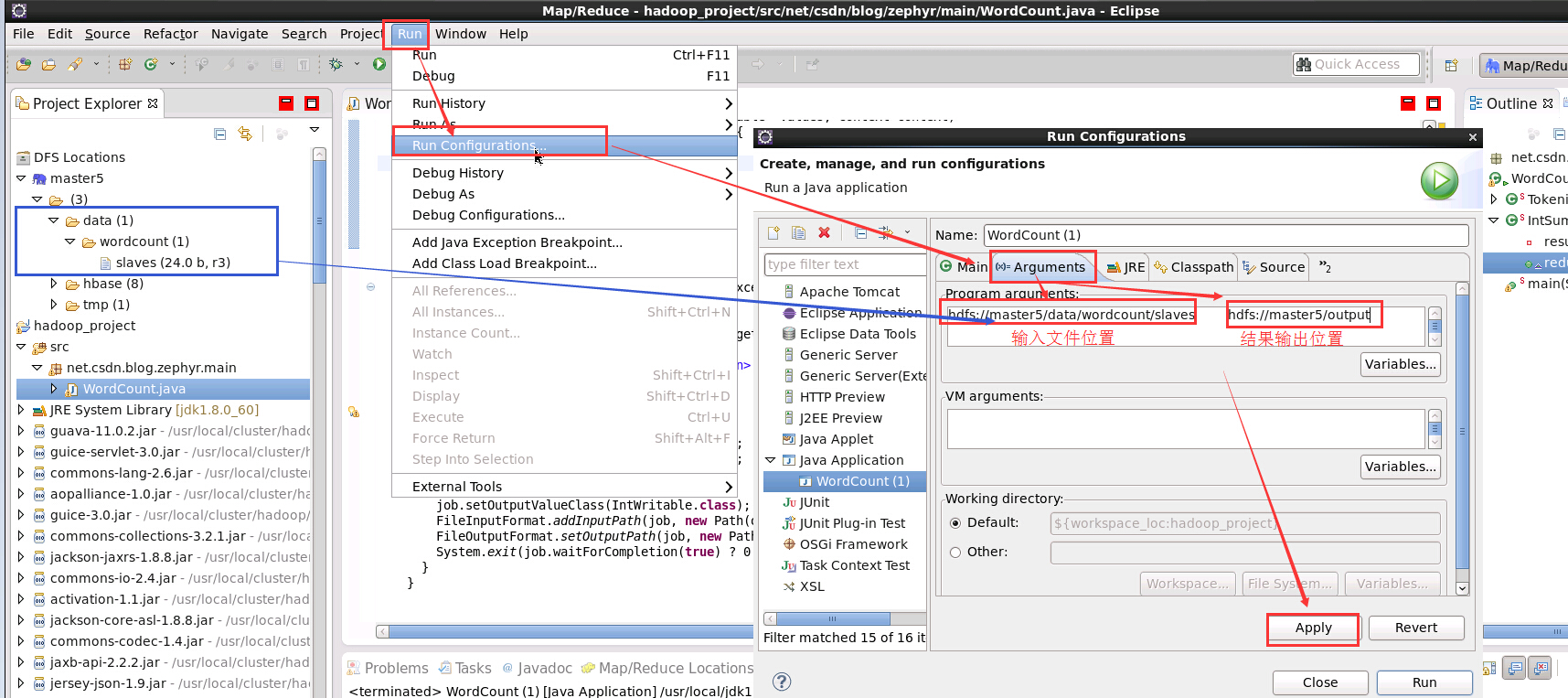
- 執行 Hadoop 程式
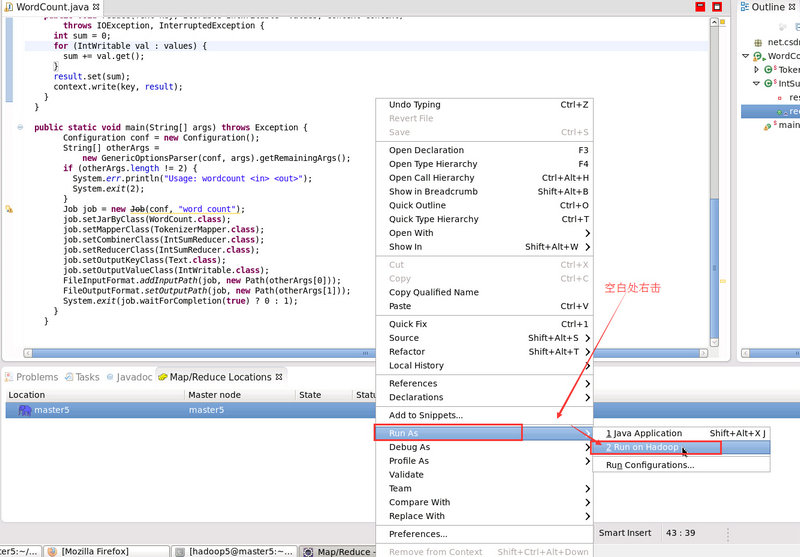
- 重新整理 HDFS 的最新情況
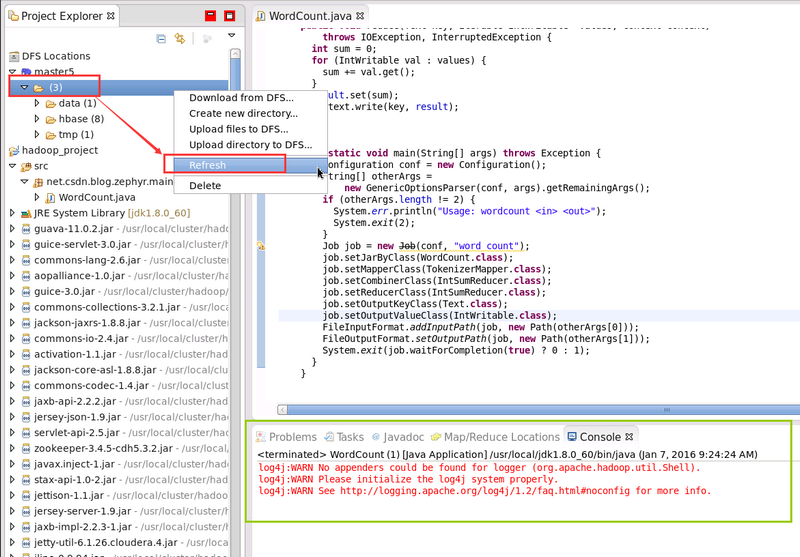
要麼 右擊資料夾 -> Refresh ,要麼 右擊藍色小象 -> Reconnect ,或者 右擊 “DFS Locations” -> Disconnect ,這樣才能看到最新的輸出結果目錄。右擊 “藍色小象”和 “DFS Locations” 的 Refresh 是沒有作用的。
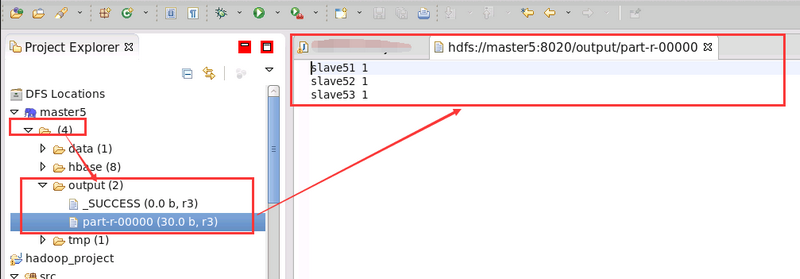
- 最終輸出結果顯示
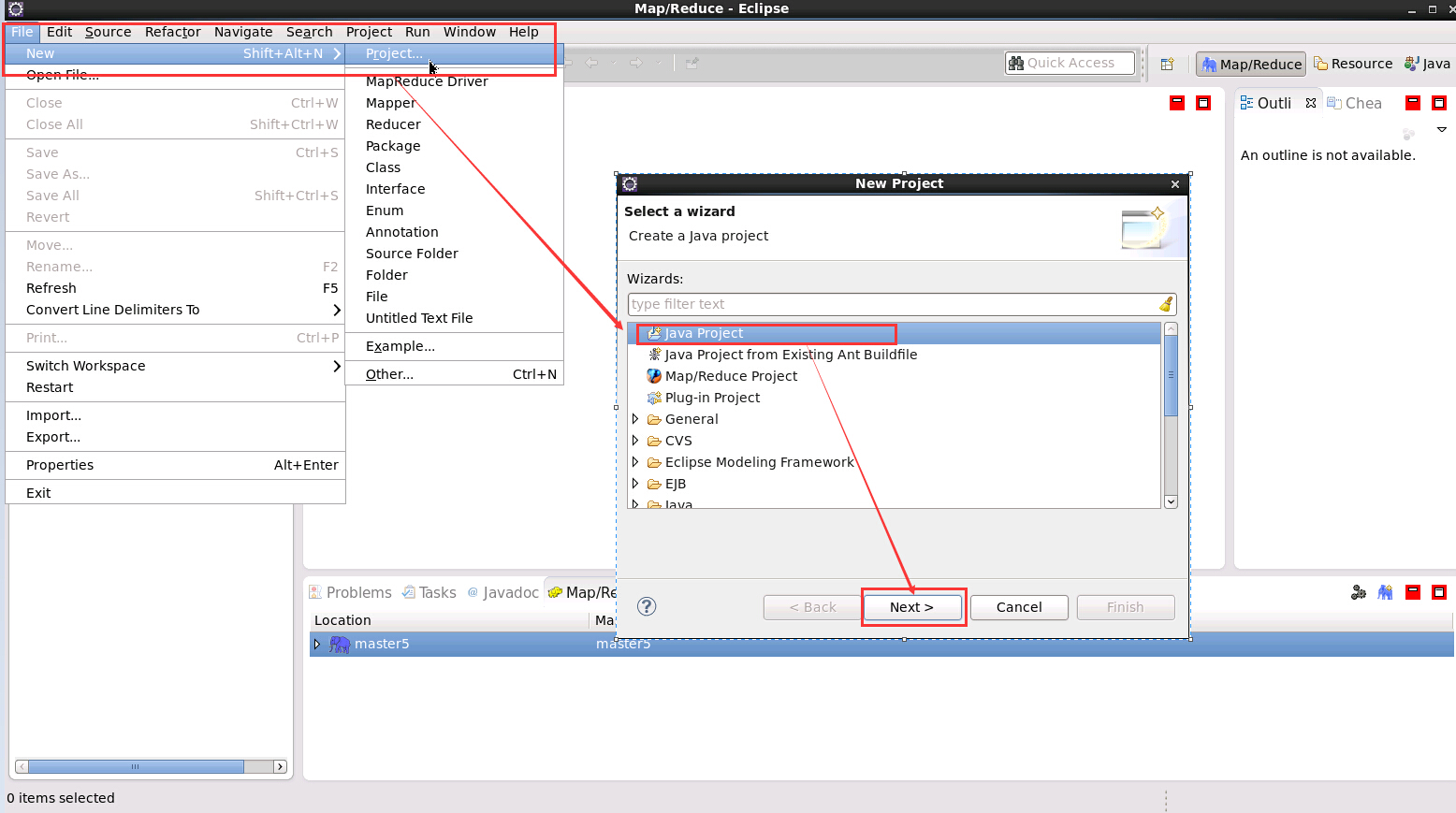
4.2 新建 java 工程
1. 新建 java 工程
新建 java 工程的特點就是 需要手動匯入 hadoop 相應 jar 包,具體如下圖所示:
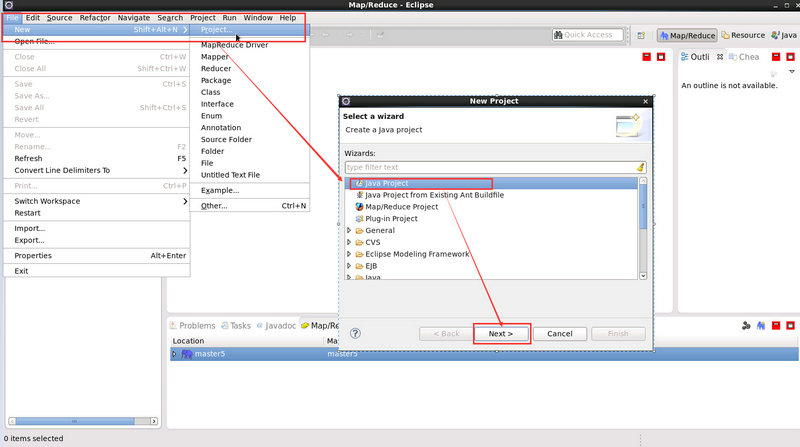
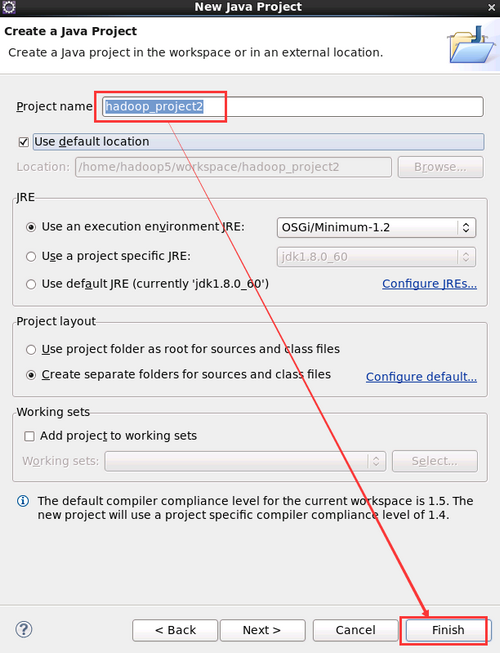
- hadoop_project2 是自定義的專案名稱
- 選擇 no 是保持 MapReduce 的程式設計介面
2. 新增預設的 JRE
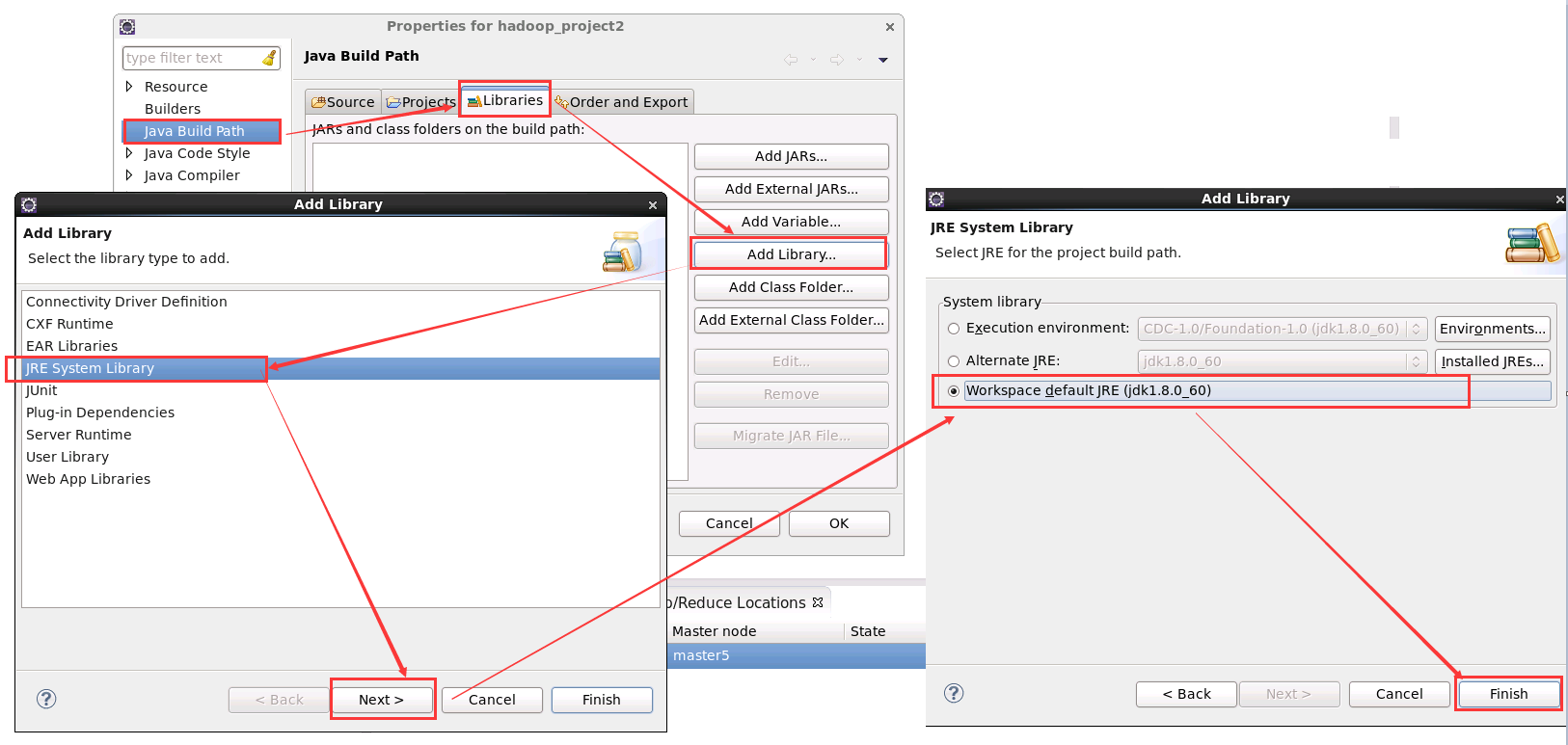
新建 java 工程完成後,下面新增 hadoop 相應 jar 包,hadoop2.5.0-cdh5.3.2 相應 jar 包在 ${HADOOP_HOME}/share/hadoop 目錄中。
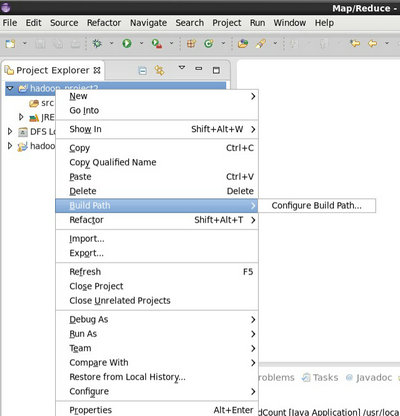
進入 Libraries,點選 Add Library ,點選 JRE System Library 新增 Eclipse 預設的 JRE 環境
3. 新增 hadoop jar 包
新建 hadoop 相應 library 成功後新增 hadoop 相應 jar 包到該 library下面即可。
進入 Libraries,點選 Add Library,點選 User Library 新增 hadoop 相應 jar 包
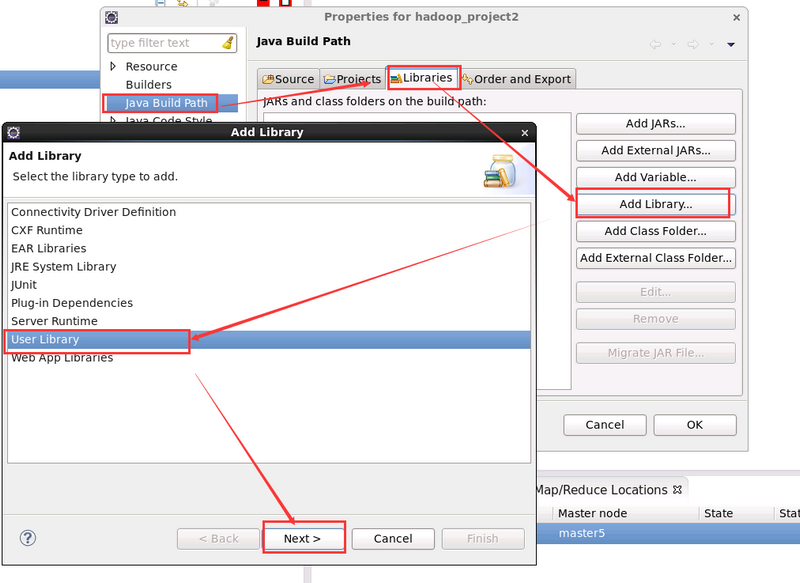
自定義 library 的名字
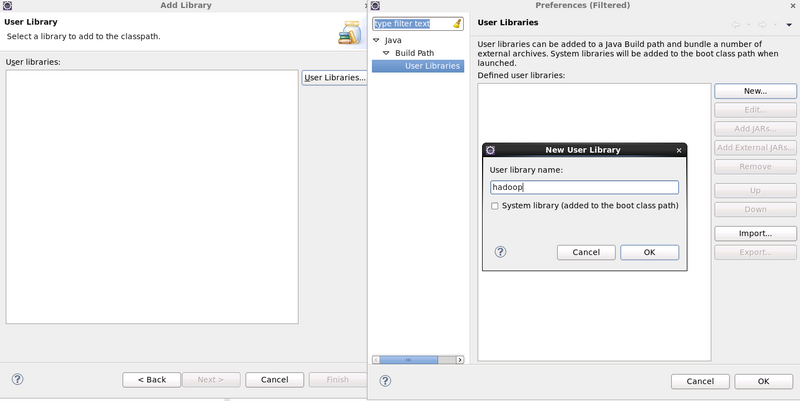
筆者我建立了 4 個 Library ,分別取名為 hadoop-common、hadoop-yarn、hadoop-hdfs、hadoop-mapreduce
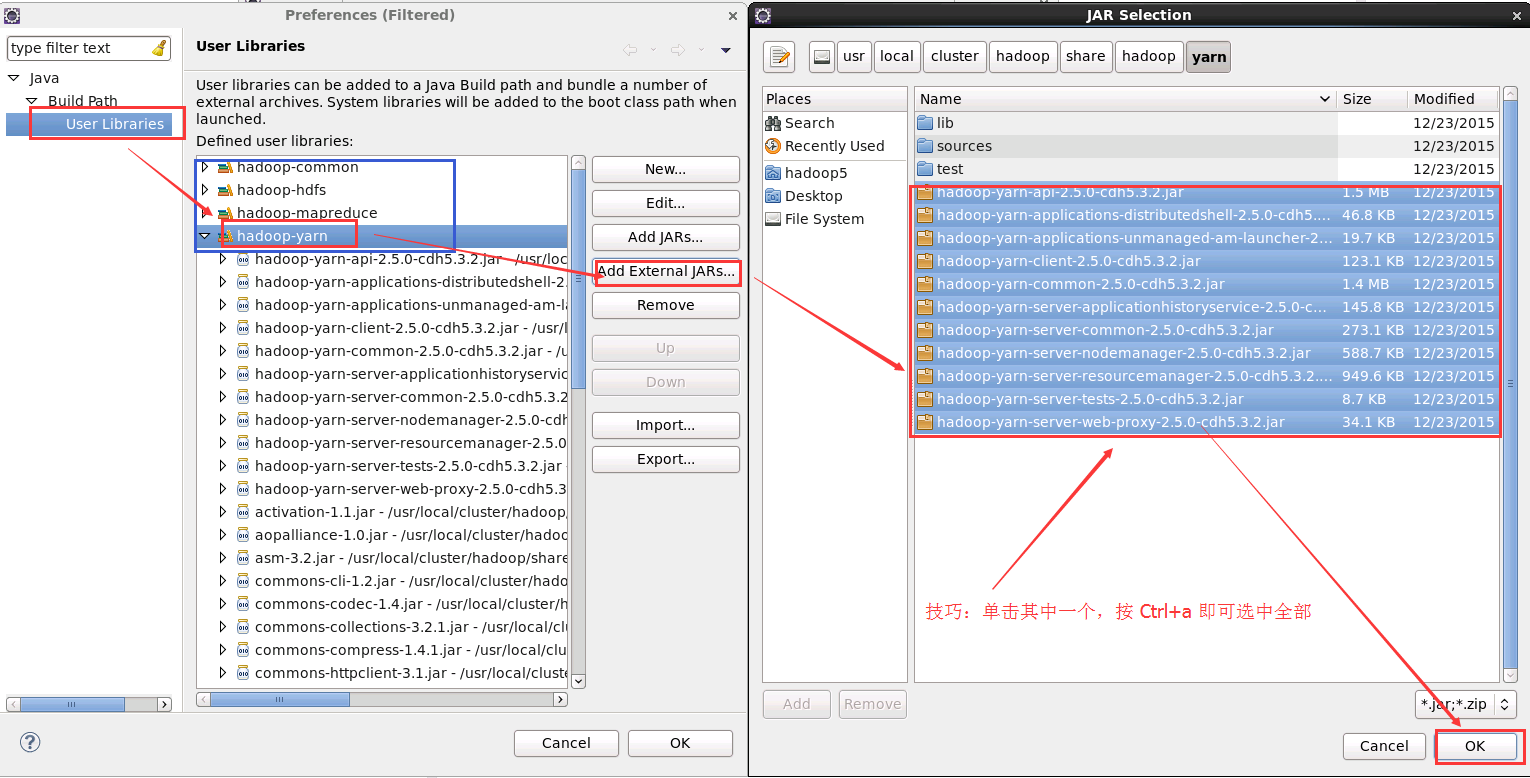
4. 需要新增的 hadoop 相應 jar 包有
${HADOOP_HOME}/share/hadoop/common下所有jar包,及裡面的lib目錄下所有jar包
${HADOOP_HOME}/share/hadoop/hdfs下所有jar包,及裡面lib下的jar包
${HADOOP_HOME}/share/hadoop/mapreduce下所有jar包,及裡面lib下的jar包
${HADOOP_HOME}/share/hadoop/yarn下所有jar包,及裡面lib下的jar包在上述的 4 個自定義的 Library 中新增相應的 jar 包。選中某一個 User Library,然後點選旁邊的 “Add External JARs”,然後根據 ${HADOOP_HOME}/share/hadoop 路徑下選擇與之對應的 jar 包。
5. 執行 Java 工程
步驟和程式碼和之前是一樣的。唯一區別的啟動選項,選擇的是 Java Application

與 Hadoop 執行方式不同的是,在 Console 控制檯上,能看到更加詳細的輸出資訊,這裡就不上圖了,且執行的方式卻是本地執行模式。用執行緒模擬 map,reduce 的過程。
五. 以 Jar 包方式執行
5.1 系統 Export 輸出 jar 包
1. 匯出 Jar 包
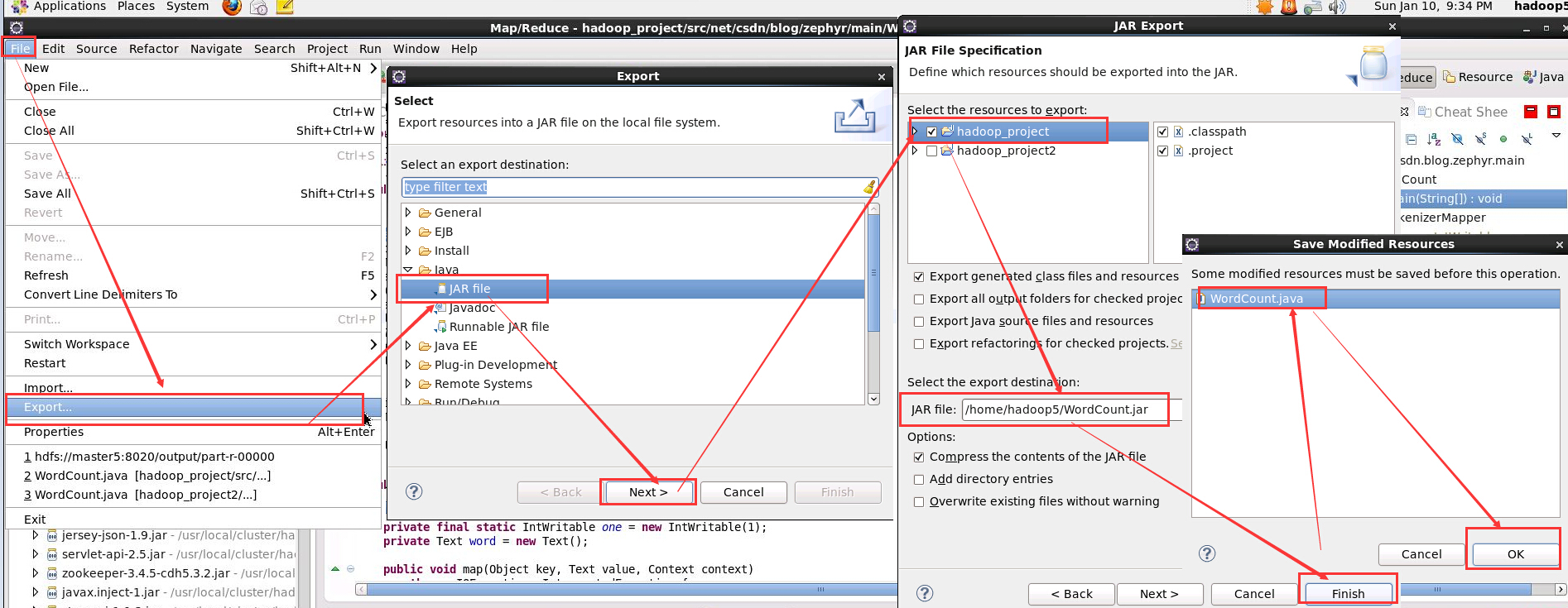
所要填的就是 Jar 的輸出路徑以及檔名
2. 執行 Jar 包
可以在相應輸出目錄下生成 WordCount.jar 的 Jar 包,執行之
hadoop jar WordCount.jar net.csdn.blog.zephyr.main.WordCount /data/wordcount/slaves /output這裡需要填類名,如果是在包下,請確保填寫詳細的包名,如這裡的 net.csdn.blog.zephyr.main,否則會報找不到類的錯誤。
/data/wordcount 為 HDFS 存放文字的目錄,如果指定一個目錄為 MapReduce 輸入的路徑,則 MapReduce 會將該路徑下的所有檔案作為輸入。如果指定一個檔案,則 MapReduce 只會將該檔案作為輸入。/output 為作業輸出路徑,該路徑在作業執行之前必須不存在,否則會報錯。
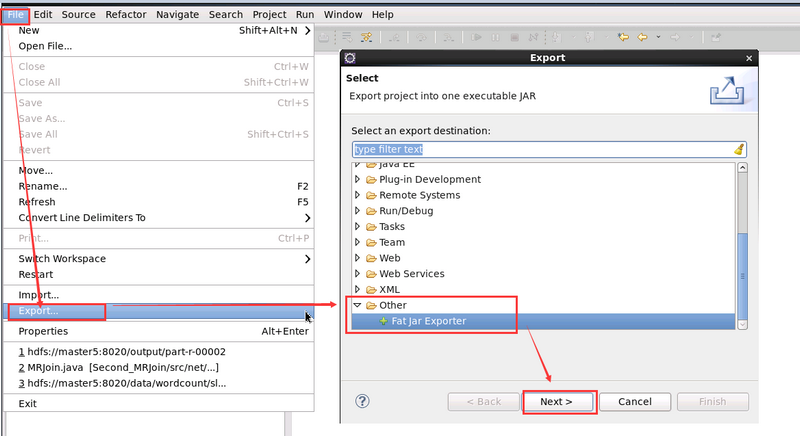
5.2 使用第三方外掛 FatJar
1. File -> Export ->Other -> Fat Jar Exporter
2. 配置各種引數
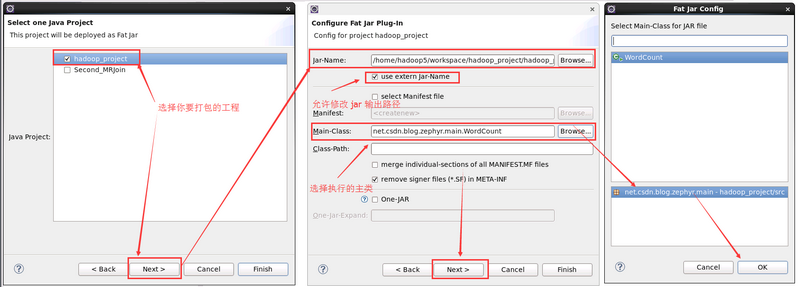
Note: 注意別選中 Merge individual-sections of all MANIFEST.MF Files,如果選中的話,很有可能在執行有 fat jar 打包的 JAR 檔案時控制檯出現各種警告,原因:在 MANIFEST.MF 檔案中,有多個 SHA1-Digest,導致控制檯報錯。
在執行有fat jar打包的JAR檔案時控制檯出現各種警告:
008-12-2 8:55:20 java.util.jar.Attributes read
警告: Duplicate name in Manifest: SHA1-Digest.
Ensure that the manifest does not have duplicate entries, and
that blank lines separate individual sections in both your
manifest and in the META-INF/MANIFEST.MF entry in the jar file.
2008-12-2 8:55:20 java.util.jar.Attributes read
警告: Duplicate name in Manifest: SHA1-Digest.
Ensure that the manifest does not have duplicate entries, and
that blank lines separate individual sections in both your
manifest and in the META-INF/MANIFEST.MF entry in the jar file.3. 選擇要打包的第三方 JAR 檔案,這些檔案會打包進最終的 readXml_fat.jar
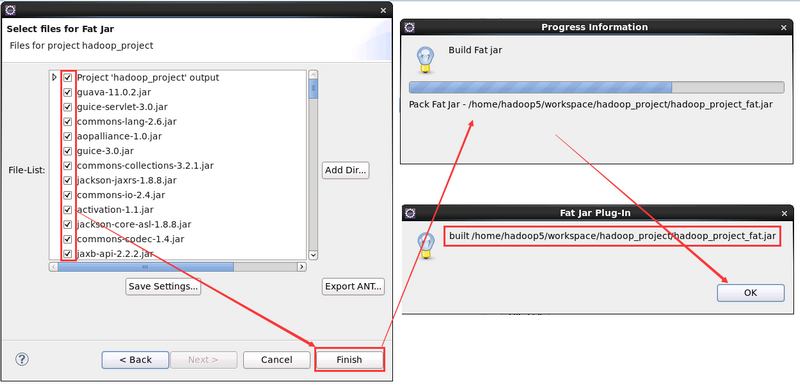
4. 執行新生成的 jar 檔案
cd /home/hadoop5/workspace/hadoop_project
hadoop jar hadoop_project_fat.jar /data/wordcount/slaves /output/注意:此時就不用再寫執行的主類了,因為在打包的時候已經設定啦~
六. 參考資料
6.1 FatJar 安裝
FatJar 是一個非常簡單的軟體打包解決方案,它利用 Java 的定製類裝入器,動態地從單一檔案檔案中裝入應用程式所有的類,同時保留支援 JAR 檔案的結構。隨著 FatJar Eclipse 外掛 FJEP 的推出, Eclipse 的使用者現在只要在嚮導中選中一個複選框,就可以建立 One-JAR 應用程式。依賴的庫被放進 lib/ 目錄,主程式和類被放進 main/main.jar,並自動寫好 META-INF/MANIFEST.MF 檔案。
2. 安裝 FatJar
將該外掛直接放置在 eclipse目錄下的 plugin 目錄下即可!然後重啟 eclipse 就 OK 了。