
[Elasticsearch in Action讀書筆記]第一章 Elasticsearch介紹
為什麼需要搜尋引擎
- 搜尋的目的是快速尋找需要的內容而不用瀏覽整個站點
- 搜尋結果應該是有順序的,相關度越高的結果越應該排在前面
- 需要提供篩選,以優化搜尋結果整體的相關性
-
搜尋的速度不能太慢
由於傳統的關係型資料庫無法很好地解決這類問題,所以需要引入專門的搜尋引擎。
Elasticsearch 的用途
- 部署在關係型資料庫之上,加快搜索相關的 SQL 查詢。或是為 NoSQL 及其他資料來源新增搜尋功能
- 像 MongoDB 一樣作為文件型 NoSQL 資料庫使用
Elasticsearch 的特點
更快速的搜尋
Elasticsearch 是開源軟體,構建於 Lucene,Elasticsearch 使用 Lucene 的方式查詢和索引文件,通過擴充套件使其更快且更方便。並且可以使用 HTTP JSON API 的方式互動,使得應用程式不需要限制於 Java 語言。
Lucene 使用倒排索引的方式管理文件,它使每個詞元都維護一個與其有關的文件列表。就像是通過目錄指向頁碼,然後通過頁碼翻到具體的內容頁一樣。
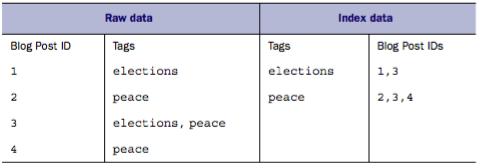
上圖的部落格和標籤是一個很好的例子:左邊為原始資料,一個部落格可以擁有多個標籤。右邊通過倒排索引使得每個標籤都指向那些擁有它的部落格。這樣當搜尋標籤時,左邊只能依次遍歷查詢,而右邊則可以直接找到對應的所有部落格。
保證結果的相關度
相關度是一個很重要的概念,它用於證明搜尋到的文件到底是真的關於這個關鍵詞,還是僅僅包含了這個關鍵詞。一個最簡單的例子:也許一個文件裡出現該關鍵詞的次數越多,它就與這個關鍵詞越有關。
Elasticsearch 預設使用 TF-IDF(term frequency–inverse document frequency)進行相關度計算
,它的意思是:
- term frequency:詞頻,指單詞在文件中出現的頻率,詞頻越高相關度也就越高
-
inverse document frequency:逆向文件頻率,指其他出現該單詞的文件的個數,逆向文件頻率越低相關度越高
也就是說,如果一個單詞在某個文件中出現的次數很多,並且很少出現在其他文件中,那麼這個單詞就可以為該文件帶來非常高的相關度。
Elasticsearch 還提供了一些其他的方式計算相關度,例如增加某個欄位的影響力,甚至可以通過指令碼自己實現計算相關度分數的方法。這幾乎可以滿足各種需求,無論是你希望關鍵詞出現在標題上的部落格更靠前,還是希望點贊數越多的部落格更靠前,或是較新的部落格更靠前。
不僅僅是精確匹配
Elasticsearch 還提供一些配置用於支援錯詞、衍生詞(例如單複數、各種時態等),以提高匹配的精度。同時還可以支援關鍵詞聯想等功能。
Elasticsearch 的使用場景
作為主資料來源
通常來說,搜尋引擎一般是構建在其他資料來源之上,用於提供更加良好的搜尋體驗。這是因為之前的大多搜尋引擎都無法提供可靠地儲存和一些常用的功能,像是統計。
但是如今 Elasticsearch 提供了這些功能,所以可以直接當做資料庫使用,當然只適用於某些場景。
例如一個部落格應用,這類應用並沒有太複雜的關聯關係,且對事務不敏感,所以很適合 Elasticsearch(除了太太太太耗記憶體)。
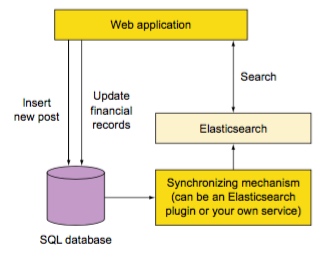
就像上圖一樣,在建立新文章時將它索引到 Elasticsearch 中,之後通過查詢獲取文章內容。無論是簡單的主鍵查詢,還是複雜些的基於標籤、類別的查詢,包括搜尋功能,都可以非常輕鬆的實現。甚至還可以通過聚合和修改相關度做一些標籤統計、熱門文章等複雜功能。
作為輔助資料來源
Elasticsearch 並不適合所有場景,例如它沒有事務這個概念,也無法很好地完成關聯查詢。所以更多的場景是輔助一個已有的主資料來源,並提供它在搜尋及實時分析領域上的支援。
在使用多個數據源時,必須要保證資料來源之間的資料是同步的,通常可以使用一些已有的外掛或是自己寫一個系統實現。
現成的解決方案
Elasticsearch 的出名有很大一部分原因是由於它擁有 ELK(Logstash Elasticsearch Kibana)這一套通用的日誌分析解決方案。其中 Logstash 用於收集日誌,Elasticsearch 用於儲存和索引日誌,Kibana 提供了一個人性化的 Web 介面用於展示搜尋結果。這樣不需要寫任何程式碼就可以擁有一個功能強大的日誌分析系統。
Elasticsearch 的優勢
Elasticsearch 提供了 REST API,使得無論是開發者可以輕易的通過 JSON 構造查詢語句搜尋文件,或是修改配置資訊。
在 Lucene 之上,Elasticsearch 還提供了一些更加高階的功能,例如快取、實時分析、聚合和統計等。並且文件的管理更加靈活,單次查詢可以同時查詢多個索引。
最後,Elasticsearch 擁有良好的伸縮性,預設支援叢集(即使只運行了一個節點),並且可以輕鬆地通過增加節點達到擴容和容災的目的,可以在必要時刻移除節點以節約花費。
安裝 Elasticsearch
安裝 Java
Elasticsearch 使用 Java 開發,所以首先需要安裝 JRE,在這裡就不詳述了。
它會通過兩種方式尋找系統中的 Java:JAVA_HOME和系統路徑。通過env(類 Unix 系統)和set可以檢視環境變數,直接在命令列輸入java -version可以檢視是否存在與系統路徑中。
安裝 Elasticsearch
Elasticsearch 的安裝十分簡單,只需要在官網下載對應的tar.gz包,解壓後執行啟動指令碼即可:
| 1 2 3 | tar zxf elasticsearch-*.tar.gz cd elasticsearch-* bin/elasticsearch |
檢視啟動日誌
啟動時會在命令列輸出一些日誌:
啟動節點的版本,pid,名稱等資訊,Elasticsearch 預設會給節點隨機起一個名字(這裡是 Answer):
| 1 | [2016-05-03 17:24:15,032][INFO][node] [Answer] version [1.7.1], pid [21122], build [b88f43f/2015-07-29T09:54:16Z] |
載入外掛資訊:
| 1 | [2016-05-03 17:24:15,233][INFO][plugins] [Answer] loaded [analysis-ik, marvel], sites [marvel] |
內部節點通訊的埠為 9300:
| 1 | [2016-05-03 17:24:26,456][INFO][transport] [Answer] bound_address {inet [/0:0:0:0:0:0:0:0:9300]}, publish_address {inet [/192.168.1.222:9300]} |
該節點被選為主節點:
| 1 | [2016-05-03 17:24:30,247][INFO][cluster.service] [Answer] new_master [Answer][BztA5MLnQW6-obfcjN4T7w][localhost.localdomain][inet [/192.168.1.222:9300]], reason: zen-disco-join (elected_as_master) |
http 通訊埠為 9200:
| 1 | [2016-05-03 17:24:30,371][INFO][http] [Answer] bound_address {inet [/0:0:0:0:0:0:0:0:9200]}, publish_address {inet [/192.168.1.222:9200]} |
節點已啟動完畢:
| 1 | [2016-05-03 17:24:30,372][INFO][node] [Answer] started |
從閘道器恢復資料,第一次啟動必然是 0:
| 1 | [2016-05-03 17:24:30,702][INFO][gateway] [Answer] recovered [0] indices into cluster_state |
嘗試互動
節點啟動成功後就可以通過 REST API 進行互動了,請求 9200 埠,會以 JSON 格式返回節點資訊:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | curl http://localhost:9200 { "status" : 200, "name" : "St. John Allerdyce", "cluster_name" : "elasticsearch", "version" : { "number" : "1.7.1", "build_hash" : "b88f43fc40b0bcd7f173a1f9ee2e97816de80b19", "build_timestamp" : "2015-07-29T09:54:16Z", "build_snapshot" : false, "lucene_version" : "4.10.4" }, "tagline" : "You Know, for Search" } |
總結
-
Elasticsearch 是一個開源的搜尋引擎,基於 Apache Lucene
-
典型應用場景是索引大量資料,並高效的進行全文搜尋或是實時統計
-
搜尋功能不僅限於全文搜尋,可以修改相關度的計算方式或是給出搜尋建議
-
執行十分簡單,只需要下載檔案,解壓縮,執行指令碼即可
-
可以使用 HTTP REST API 通過 JSON 進行索引、查詢資料和修改叢集設定
-
也可以將其作為一個用於實時搜尋和分析的文件型 NoSQL 資料庫
-
會自動將資料平均分佈到各個分片中,可以很輕鬆的通過新增節點橫向擴充套件叢集,分片會被複制從而提高容錯性
參考:http://www.scienjus.com/elasticsearch-in-action-1/