
淺談人工智慧:現狀、任務、構架與統一 | 正本清源
作者:朱鬆純,加州大學洛杉磯分校(UCLA)
統計學和電腦科學教授
視覺、認知、學習與自主機器人中心主任
2017年11月02日刊登於《視覺求索》微信公眾號
原文連結

目錄
引言
第一節 現狀:正視現實
第二節 未來:一隻烏鴉給我們的啟示
第三節 歷史:從“春秋五霸”到“戰國六雄”
第四節 統一:“小資料、大任務”正規化與認知構架
第五節 學科一:計算視覺 — 從“深”到“暗”
第六節 學科二:認知推理 — 走進內心世界
第七節 學科三:語言通訊 — 溝通的認知基礎
第八節 學科四:博弈倫理 — 獲取、共享人類的價值觀
第九節 學科五:機器人學 — 構建大任務平臺
第十節 學科六:機器學習 — 學習的終極極限與“停機問題”
第十一節 總結: 智慧科學 — 牛頓與達爾文的統一
附錄 中科院自動化所報告會上的問答與互動摘錄
鳴謝
引言
“人工智慧”這個名詞在沉寂了近30年之後,最近兩年“鹹魚翻身”,成為了科技公司公關的戰場、網路媒體吸睛的風口,隨後受到政府的重視和投資界的追捧。於是,新聞釋出會、高峰論壇接踵而來,政府戰略規劃出臺,各種新聞應接不暇,宣告一個“智慧為王”時代的到來。
到底什麼是人工智慧?現在的研究處於什麼階段?今後如何發展?這是大家普遍關注的問題。由於人工智慧涵蓋的學科和技術面非常廣,要在短時間內全面認識、理解人工智慧,別說非專業人士,就算對本行業研究人員,也是十分困難的任務。
所以,現在很多宣傳與決策衝到認識之前了,由此不可避免地造成一些思想和輿論的混亂。
自從去年用了微信以來,我就常常收到親朋好友轉來的驚世駭俗的新聞標題。我發現很多議論缺乏科學依據,變成了“娛樂AI”。一個在1970年代研究黑洞的物理學博士,從來沒有研究過人工智慧,卻時不時被擡出來預測人類末日的到來。某些公司的公關部門和媒體發揮想象力,動輒把一些無辜的研究人員封為“大師”、“泰斗”。最近,名詞不夠用了。九月初,就有報道把請來的一位美國教授稱作“人工智慧祖師爺”。這位教授的確是機器學習領域的一個領軍人物,但人工智慧是1956年開始的,這位教授也才剛剛出生。況且機器學習只是人工智慧的一個領域而已,大部分其它重要領域,如視覺、語言、機器人,他都沒有涉足,所以這樣的封號很荒唐(申明一點:我對這位學者本人沒有意見,估計他自己不一定知道這個封號)。當時我想,後面是不是有人會搬出“達摩老祖、佛祖如來、孔雀王、太上老君、玉皇大帝”這樣的封號。十月初,赫然就聽說達摩院成立了,宣稱要碾壓美國,輿情轟動!別說一般老百姓擔心丟飯碗,就連一些業內的研究人員都被說得心慌了,來問我有什麼看法。
我的看法很簡單:大多數寫報道和搞炒作宣傳的人,基本不懂人工智慧。這就像年輕人玩的傳話遊戲,扭曲的資訊在多次傳導過程中,逐級放大,最後傳回來,自己嚇到自己了。下面這個例子就說明公眾的誤解到了什麼程度。今年9月我在車上聽到一家電臺討論人工智慧。兩位主持人談到矽谷臉書公司,有個程式設計師突然發現,兩臺電腦在通訊過程中發明了一種全新的語言,快速交流,人看不懂。眼看一種“超級智慧”在幾秒之內迅速迭代升級(我加一句:這似乎就像宇宙大爆炸的前幾秒鐘),程式設計師驚恐萬狀。人類現在只剩最後一招才能拯救自己了:“別愣著,趕緊拔電源啊!…”終於把人類從鬼門關又拉回來了。
回到本文的正題。全面認識人工智慧之所以困難,是有客觀原因的。
其一、人工智慧是一個非常廣泛的領域。當前人工智慧涵蓋很多大的學科,我把它們歸納為六個:
(1)計算機視覺(暫且把模式識別,影象處理等問題歸入其中)、
(2)自然語言理解與交流(暫且把語音識別、合成歸入其中,包括對話)、
(3)認知與推理(包含各種物理和社會常識)、
(4)機器人學(機械、控制、設計、運動規劃、任務規劃等)、
(5)博弈與倫理(多代理人agents的互動、對抗與合作,機器人與社會融合等議題)。
(6)機器學習(各種統計的建模、分析工具和計算的方法),
這些領域目前還比較散,目前它們正在交叉發展,走向統一的過程中。我把它們通俗稱作“戰國六雄”,中國歷史本來是“戰國七雄”,我這裡為了省事,把兩個小一點的領域:博弈與倫理合並了,倫理本身就是博弈的種種平衡態。最終目標是希望形成一個完整的科學體系,從目前鬧哄哄的工程實踐變成一門真正的科學Science of Intelligence。
由於學科比較分散,從事相關研究的大多數博士、教授等專業人員,往往也只是涉及以上某個學科,甚至長期專注於某個學科中的具體問題。比如,人臉識別是計算機視覺這個學科裡面的一個很小的問題;深度學習屬於機器學習這個學科的一個當紅的流派。很多人現在把深度學習就等同於人工智慧,就相當於把一個地級市說成全國,肯定不合適。讀到這裡,搞深度學習的同學一定不服氣,或者很生氣。你先別急,等讀完後面的內容,你就會發現,不管CNN網路有多少層,還是很淺,涉及的任務還是很小。
各個領域的研究人員看人工智慧,如果按照印度人的諺語可以叫做“盲人摸象”,但這顯然是言語冒犯了,還是中國的文豪蘇軾遊廬山時說得有水準:
其二,人工智慧發展的斷代現象。由於歷史發展的原因,人工智慧自1980年代以來,被分化出以上幾大學科,相互獨立發展,而且這些學科基本拋棄了之前30年以邏輯推理與啟發式搜尋為主的研究方法,取而代之的是概率統計(建模、學習)的方法。留在傳統人工智慧領域(邏輯推理、搜尋博弈、專家系統等)而沒有分流到以上分支學科的老一輩中,的確是有很多全域性視野的,但多數已經過世或退休了。他們之中只有極少數人在80-90年代,以敏銳的眼光,過渡或者引領了概率統計與學習的方法,成為了學術領軍人物。而新生代(80年代以後)留在傳統人工智慧學科的研究人員很少,他們又不是很瞭解那些被分化出去的學科中的具體問題。
這種領域的分化與歷史的斷代, 客觀上造成了目前的學界和產業界思路和觀點相當“混亂”的局面,媒體上的混亂就更放大了。但是,以積極的態度來看,這個局面確實為現在的年輕一代研究人員、研究生提供了一個很好的建功立業的機會和廣闊的舞臺。
鑑於這些現象,《視覺求索》編輯部同仁和同行多次催促我寫一篇人工智慧的評論和介紹材料。我就免為其難,僅以自己30年來讀書和跨學科研究的經歷、觀察和思辨,淺談什麼是人工智慧;它的研究現狀、任務與構架;以及如何走向統一。
我寫這篇文章的動機在於三點:
(1)為在讀的研究生們、為有志進入人工智慧研究領域的年輕學者開闊視野。
(2)為那些對人工智慧感興趣、喜歡思考的人們,做一個前沿的、綜述性的介紹。
(3)為公眾與媒體從業人員,做一個人工智慧科普,澄清一些事實。
本文來歷: 本文技術內容選自我2014年來在多所大學和研究所做的講座報告。2017年7月,微軟的沈向洋博士要求我在一個朋友聚會上做一個人工智慧的簡介,我增加了一些通俗的內容。2017年9月,在譚鐵牛和王蘊紅老師的要求下,我參加了中科院自動化所舉辦的人工智慧人機互動講習班,他們派速記員和一名博士生整理出本文初稿。如果沒有他們的熱情幫助,這篇文章是不可能寫成的。原講座兩個半小時,本文做了刪減和文字修飾。仍然有四萬字,加上大量插圖和示例。很抱歉,無法再壓縮了。
本文摘要:文章前四節淺顯探討什麼是人工智慧和當前所處的歷史時期,後面六節分別探討六個學科的重點研究問題和難點,有什麼樣的前沿的課題等待年輕人去探索,最後一節討論人工智慧是否以及如何成為一門成熟的科學體系。
誠如屈子所言:“路漫漫其修遠兮,吾將上下而求索”。
第一節 現狀評估:正視現實
人工智慧的研究,簡單來說,就是要通過智慧的機器,延伸和增強(augment)人類在改造自然、治理社會的各項任務中的能力和效率,最終實現一個人與機器和諧共生共存的社會。這裡說的智慧機器,可以是一個虛擬的或者物理的機器人。與人類幾千年來創造出來的各種工具和機器不同的是,智慧機器有自主的感知、認知、決策、學習、執行和社會協作能力,符合人類情感、倫理與道德觀念。
拋開科幻的空想,談幾個近期具體的應用。無人駕駛大家聽了很多,先說說軍用。軍隊裡的一個班或者行動組,現在比如要七個人,將來可以減到五個人,另外兩個用機器來替換。其次,機器人可以用在救災和一些危險的場景,如核洩露現場,人不能進去,必須靠機器人。醫用的例子很多:智慧的假肢或外骨架(exoskeleton)與人腦和身體訊號對接,增強人的行動控制能力,幫助殘疾人更好生活。此外,還有就是家庭養老等服務機器人等。

但是,這方面的進展很不盡人意。以前日本常常炫耀他們機器人能跳舞,中國有一次春節晚會也拿來表演了。那都是事先編寫的程式,結果一個福島核輻射事故一下子把所有問題都暴露了,發現他們的機器人一點招都沒有。美國也派了機器人過去,同樣出了很多問題。比如一個簡單的技術問題,機器人進到災難現場,背後拖一根長長的電纜,要供電和傳資料,結果電纜就被纏住了,動彈不得。有一次,一位同事在餐桌上半開玩笑說,以現在的技術,要讓一個機器人長時間像人一樣處理問題,可能要自帶兩個微型的核電站,一個發電驅動機械和計算裝置,另一個發電驅動冷卻系統。順便說一個,人腦的功耗大約是10-25瓦。
看到這裡,有人要問了,教授說得不對,我們明明在網上看到美國機器人讓人歎為觀止的表現。比如,這一家波士頓動力學公司(Boston Dynamics)的演示,它們的機器人,怎麼踢都踢不倒呢,或者踢倒了可以自己爬起來,而且在野外叢林箭步如飛呢,還有幾個負重的電驢、大狗也很酷。這家公司本來是由美國國防部支援開發出機器人來的,被谷歌收購之後、就不再承接國防專案。可是,谷歌發現除了燒錢,目前還找不到商業出路,最近一直待售之中。您會問,那谷歌不是很牛嗎?DeepMind下圍棋不是也一次次刺激中國人的神經嗎?有一個逆天的機器人身體、一個逆天的機器人大腦,它們都在同一個公司內部,那為什麼沒有做出一個人工智慧的產品呢?他們何嘗不在夜以繼日的奮戰之中啊。

人工智慧炒作了這麼長時間,您看看周圍環境,您看到機器人走到大街上了?沒有。您看到人工智慧進入家庭了嗎?其實還沒有。您可能唯一直接領教過的是基於大資料和深度學習訓練出來的聊天機器人,你可能跟Ta聊過。用我老家湖北人的話,這就叫做“扯白”— 東扯西拉、說白話。如果你沒有被Ta氣得背過氣的話,要麼您真的是閒得慌,要麼是您真的有耐性。

為了測試技術現狀,美國國防部高階研究署2015年在洛杉磯郊區Pomona做了一個DARPA Robot Challenge(DRC),懸賞了兩百萬美金獎給競賽的第一名。有很多隊伍參加了這個競賽,上圖是韓國科技大學隊贏了第一名,右邊是他們的機器人在現場開門進去“救災”。整個比賽場景設定的跟好萊塢片場一樣,複製了三個賽場,全是冒煙的救災場面。機器人自己開著一個車子過來,自己下車,開門,去拿工具,關閥門,在牆上開洞,最後過一個磚頭做的障礙區,上樓梯等一系列動作。我當時帶著學生在現場看,因為我們剛好有一個大的DARPA專案,專案主管是裡面的裁判員。當時,我第一感覺還是很震撼的,感覺不錯。後來發現內情,原來機器人所有的動作基本上是人在遙控的。每一步、每一個場景分別有一個介面,每個學生控制一個模組。感知、認知、動作都是人在指揮。就是說這個機器人其實並沒有自己的感知、認知、思維推理、規劃的能力。造成的結果是,你就可以看到一些不可思議的事情。比如說這個機器人去抓門把手的時候,因為它靠後臺人的感知,誤差一釐米,就沒抓著;或者腳踩樓梯的時候差了一點點,它重心就失去了平衡,可是在後面控制的學生沒有重力感知訊號,一看失去平衡,他來不及反應了。你想想看,我們人踩滑了一下子能保持平衡,因為你整個人都在一起反應,可是那個學生只是遠遠地看著,他反應不過來,所以機器人就東倒西歪。
這還是一個簡單的場景。其一、整個場景都是事先設定的,各個團隊也都反覆操練過的。如果是沒有遇見的場景,需要靈機決斷呢?其二、整個場景還沒有人出現,如果有其他人出現,需要社會活動(如語言交流、分工協作)的話,那複雜度就又要上兩個數量級了。

其實,要是完全由人手動控制,現在的機器人都可以做手術了,而且手術機器人已經在普及之中。上圖是我實驗室與一家公司合作的專案,機器人可以開拉鍊、檢查包裹、用鉗子撤除炸彈等,都是可以實現的。現在的機器人,機械控制這一塊已經很不錯了,但這也不是完全管用。比如上面提到的波士頓動力學公司的機器人電驢走山路很穩定,但是它馬達噪音大,轟隆隆的噪音,到戰場上去把目標都給暴露了。特別是晚上執勤、偵察,你搞那麼大動靜,怎麼行呢?
2015年的這次DRC競賽,暫時就斷送了美國機器人研究的重大專案的立項。外行(包含國會議員)從表面看,以為這個問題已經解決了,應該留給公司去開發;內行看到裡面的困難,覺得一時半會沒有大量經費解決不了。這個認識上的落差在某種程度上就是“科研的冬天”到來的前題條件。
小結一下,現在的人工智慧和機器人,關鍵問題是缺乏物理的常識和社會的常識“Common sense”。 這是人工智慧研究最大的障礙。那麼什麼是常識?常識就是我們在這個世界和社會生存的最基本的知識:(1)它使用頻率最高;(2)它可以舉一反三,推匯出並且幫助獲取其它知識。這是解決人工智慧研究的一個核心課題。我自2010年來,一直在帶領一個跨學科團隊,攻關視覺常識的獲取與推理問題。我在自動化所做了另外一個關於視覺常識報告,也被轉錄成中文了,不久會發表出來。
那麼是不是說,我們離真正的人工智慧還很遙遠呢?其實也不然。關鍵是研究的思路要找對問題和方向。自然界已經為我們提供了很好的案例。
下面,我就來看一下,自然界給我們展示的解答。
第二節 未來目標: 一隻烏鴉給我們的啟示
同屬自然界的鳥類,我們對比一下體型大小都差不多的烏鴉和鸚鵡。鸚鵡有很強的語言模仿能力,你說一個短句,多說幾遍,它能重複,這就類似於當前的由資料驅動的聊天機器人。二者都可以說話,但鸚鵡和聊天機器人都不明白說話的語境和語義,也就是它們不能把說的話對應到物理世界和社會的物體、場景、人物,不符合因果與邏輯。
可是,烏鴉就遠比鸚鵡聰明,它們能夠製造工具,懂得各種物理的常識和人的活動的社會常識。
下面,我就介紹一隻烏鴉,它生活在複雜的城市環境中,與人類互動和共存。YouTube網上有不少這方面的視訊,大家可以找來看看。我個人認為,人工智慧研究該搞一個“烏鴉圖騰”, 因為我們必須認真向它們學習。

上圖a是一隻烏鴉,被研究人員在日本發現和跟蹤拍攝的。烏鴉是野生的,也就是說,沒人管,沒人教。它必須靠自己的觀察、感知、認知、學習、推理、執行,完全自主生活。假如把它看成機器人的話,它就在我們現實生活中活下來。如果這是一個自主的流浪漢進城了,他要在城裡活下去,包括與城管周旋。
首先,烏鴉面臨一個任務,就是尋找食物。它找到了堅果(至於如何發現堅果裡面有果肉,那是另外一個例子了),需要砸碎,可是這個任務超出它的物理動作的能力。其它動物,如大猩猩會使用工具,找幾塊石頭,一塊大的墊在底下,一塊中等的拿在手上來砸。烏鴉怎麼試都不行,它把堅果從天上往下拋,發現解決不了這個任務。在這個過程中,它就發現一個訣竅,把果子放到路上讓車軋過去(圖b),這就是“鳥機互動”了。後來進一步發現,雖然堅果被軋碎了,但它到路中間去吃是一件很危險的事。因為在一個車水馬龍的路面上,隨時它就犧牲了。我這裡要強調一點,這個過程是沒有大資料訓練的,也沒有所謂監督學習,烏鴉的生命沒有第二次機會。這是與當前很多機器學習,特別是深度學習完全不同的機制。
然後,它又開始觀察了,見圖c。它發現在靠近紅綠路燈的路口,車子和人有時候停下了。這時,它必須進一步領悟出紅綠燈、斑馬線、行人指示燈、車子停、人流停這之間複雜的因果鏈。甚至,哪個燈在哪個方向管用、對什麼物件管用。搞清楚之後,烏鴉就選擇了一根正好在斑馬線上方的一根電線,蹲下來了(圖d)。這裡我要強調另一點,也許它觀察和學習的是別的地點,那個點沒有這些蹲點的條件。它必須相信,同樣的因果關係,可以搬到當前的地點來用。這一點,當前很多機器學習方法是做不到的。比如,一些增強學習方法,讓機器人抓取一些固定物體,如積木玩具,換一換位置都不行;打遊戲的人工智慧演算法,換一換畫面,又得重新開始學習。
它把堅果拋到斑馬線上,等車子軋過去,然後等到行人燈亮了(圖e)。這個時候,車子都停在斑馬線外面,它終於可以從容不迫地走過去,吃到了地上的果肉。你說這個烏鴉有多聰明,這是我期望的真正的智慧。
這個烏鴉給我們的啟示,至少有三點:
其一、它是一個完全自主的智慧。感知、認知、推理、學習、和執行, 它都有。我們前面說的, 世界上一批頂級的科學家都解決不了的問題,烏鴉向我們證明了,這個解存在。
其二、你說它有大資料學習嗎?這個烏鴉有幾百萬人工標註好的訓練資料給它學習嗎?沒有,它自己把這個事通過少量資料想清楚了,沒人教它。
其三、烏鴉頭有多大?不到人腦的1%大小。 人腦功耗大約是10-25瓦,它就只有0.1-0.2瓦,就實現功能了,根本不需要前面談到的核動力發電。 這給硬體晶片設計者也提出了挑戰和思路。十幾年前我到中科院計算所講座, 就說要做視覺晶片VPU,應該比後來的GPU更超前。我最近參與了一個計算機體系結構的大專案,也有這個目標。
在座的年輕人想想看,你們有很大的機會在這裡面,這個解存在,但是我們不知道怎麼用一個科學的手段去實現這個解。
講通俗一點,我們要尋找“烏鴉”模式的智慧,而不要“鸚鵡”模式的智慧。當然,我們必須也要看到,“鸚鵡”模式的智慧在商業上,針對某些垂直應用或許有效。
我這裡不是說要把所有智慧問題都解決了,才能做商業應用。單項技術如果成熟落地,也可以有巨大商業價值。我這裡談的是科學研究的目標。
第三節 歷史時期:從“春秋五霸”到“戰國六雄”
要搞清楚人工智慧的發展趨勢,首先得回顧歷史。讀不懂歷史,無法預測未來。這一節,我就結合自己的經歷談一下我的觀點,不見得準確和全面。為了讓非專業人士便於理解,我把人工智慧的60年曆史與中國歷史的一個時期做一個類比,但絕對不要做更多的推廣和延伸。如下圖所示,這個的時期是以美國時間為準的,中國一般會滯後一兩年。
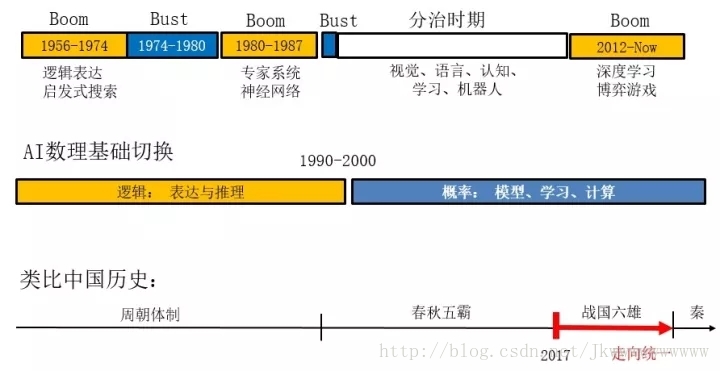
首先,從表面一層來看。反映在一些產業新聞和社會新聞層面上,人工智慧經過了幾起幾落,英文叫做Boom and Bust,意思是一哄而上、一鬨而散,很形象。每次興盛期都有不同的技術在裡面起作用。
最早一次的興起是1956-1974,以命題邏輯、謂詞邏輯等知識表達、啟發式搜尋演算法為代表。當時就已經開始研究下棋了。然後進入第一次冬天。這個時候,中國結束文革,開始學習西方科技。我上小學的時候,就聽到報紙報道計算機與人下國際象棋,十分好奇。
1980年代初又興起了第二次熱潮,一批吹牛的教授、研究人員登場了。做專家系統、知識工程、醫療診斷等,中國當時也有人想做中醫等系統。雖然這次其中也有學者拿了圖靈獎,但這些研究沒有很好的理論根基。1986年我上了中國科大計算機系,我對計算機專業本身不是最感興趣,覺得那就是一個工具和技能,而人工智慧方向水很深,值得長期探索,所以我很早就去選修了人工智慧的研究生課程,是由自動化系一個到美國進修的老師回來開的課。上完課,我很失望,感覺撲空了。它基本還是以符號為主的推理,離現實世界很遠。當時人工智慧裡面的人員也很悲觀,沒士氣。所以,我就去閱讀關於人的智慧的相關領域:神經生理學、心理學、認知科學等,這就讓我摸到了計算機視覺這個新興的學科。在80年代末有個短暫的神經網路的研究熱潮,我們當時本科五年制,我的大學畢業論文就是做神經網路的。隨後,人工智慧就跌入了近30年的寒冬。
第三次熱潮就是最近兩年興起的深度學習推動的。有了以前的教訓,一開始學者們都很謹慎,出來警告說我們做的是特定任務,不是通用人工智慧,大家不要炒作。但是,攔不住了。公司要做宣傳,然後,大家開始加碼宣傳。這就像踩踏事件,處在前面的人是清醒的,他們叫停,可是後面大量聞信趕來的人不知情,拼命往裡面擠。人工智慧的確是太重要了,誰都不想誤了這趟車。也有人認為這次是真的,不會再有冬天了。冬天不冬天,那就要看我們現在怎麼做了。
所以說,從我讀大學開始,人工智慧這個名詞從公眾視線就消失了近30年。我現在回頭看,其實它當時並沒有消失,而是分化了。研究人員分別聚集到五個大的領域或者叫做學科:計算機視覺、自然語言理解、認知科學、機器學習、機器人學。這些領域形成了自己的學術圈子、國際會議、國際期刊,各搞各的,獨立發展。人工智慧裡面還有一些做博弈下棋、常識推理,還留在裡面繼續搞,但人數不多。我把這30年叫做一個“分治時期”,相當於中國歷史的“春秋時期”。春秋五霸就相當於這分出去的五個學科,大家各自發展壯大。
其次、從深一層的理論基礎看。我把人工智慧發展的60年分為兩個階段。
第一階段:前30年以數理邏輯的表達與推理為主。這裡面有一些傑出的代表人物,如John McCarthy、Marvin Minsky、Herbert Simmon。他們懂很多認知科學的東西,有很強的全域性觀念。這些都是我讀大學的時候仰慕的人物,他們拿過圖靈獎和其它一堆大獎。但是,他們的工具基本都是基於數理邏輯和推理。這一套邏輯的東西發展得很乾淨、漂亮,很值得我們學習。大家有興趣,可以參考一本最新工具書:The Handbook of Knowledge Representation,2007年編寫的,1000多頁。但是,這些符號的知識表達不落地,全書談的沒有實際的圖片和系統;所以,一本1000多頁的書,PDF檔案只有10M,下載非常快。而我現在給的這個講座,PPT差不多1G, 因為有大量的圖片、視訊,是真實的例子。
這個邏輯表達的“體制”,就相當於中國的周朝,周文王建立了一個相對鬆散的諸侯部落體制,後來指揮不靈,就瓦解了,進入一個春秋五霸時期。而人工智慧正好也分出了五大領域。
第二階段:後30年以概率統計的建模、學習和計算為主。在10餘年的發展之後,“春秋五霸”在1990年中期都開始找到了概率統計這個新“體制”:統計建模、機器學習、隨機計算演算法等。
在這個體制的轉型過程中,起到核心作用的有這麼幾個人。講得通俗一點,他們屬於先知先覺者,提前看到了人工智慧的發展趨勢,押對了方向(就相當於80年代買了微軟、英特爾股票;90年代末,押對了中國房地產的那一批人)。他們沒有進入中國媒體的宣傳視野。我簡要介紹一下,從中我們也可以學習到一些治學之道。

第一個人叫Ulf Grenander。他從60年代就開始做隨機過程和概率模型,是最早的先驅。60年代屬於百家爭鳴的時期,當別的領軍人物都在談邏輯、神經網路的時候,他開始做概率模型和計算,建立了廣義模式理論,試圖給自然界各種模式建立一套統一的數理模型。我在以前談計算機視覺歷史的博文裡寫過他,他剛剛去世。美國數學學會AMS剛剛以他名字設立了一個獎項(Grenander Prize)獎給對統計模型和計算領域有貢獻的學者。他絕對是學術思想的先驅人物。
第二個人是Judea Pearl。他是我在UCLA的同事,原來是做啟發式搜尋演算法的。80年代提出貝葉斯網路把概率知識表達於認知推理,並估計推理的不確定性。到90年代末,他進一步研究因果推理,這又一次領先於時代。2011年因為這些貢獻他拿了圖靈獎。他是一個知識淵博、思維活躍的人,不斷有原創思想。80多歲了,還在高產發表論文。順便吹牛一句,他是第一個在UCLA計算機系和統計系兼職的教授,我是多年之後第二個這樣兼職的。其實搞這種跨學科研究當時思想超前,找工作或者評議的時候,兩邊的同行都不待見,不認可。
第三個人是Leslei Valiant。他因離散數學、計算機演算法、分散式體系結構方面的大量貢獻,2010年拿了圖靈獎。1984年,他發表了一篇文章,開創了computational learning theory。他問了兩個很簡單、但是深刻的問題。第一個問題:你到底要多少例子、資料才能近似地、以某種置信度學到某個概念,就是PAClearning;第二個問題:如果兩個弱分類器綜合在一起,能否提高效能?如果能,那麼不斷加弱分類器,就可以收斂到強分類器。這個就是Boosting和Adaboost的來源,後來被他的一個博士後設計了演算法。順便講一句,這個機器學習的原理,其實中國人早就在生活中觀察到了,就是俗話說的“三個臭裨將、頂個諸葛亮”。這裡的裨將就是副官,打仗的時候湊在一起商量對策,被民間以訛傳訛,說成“皮匠”。Valiant為人非常低調。我1992年去哈佛讀書的時候,第一學期就上他的課,當時聽不懂他說話,他上課基本是自言自語。他把自己科研的問題直接佈置作業讓我們去做,到哪裡都找不到參考答案,也沒有任何人可以問。苦啊,100分的課我考了40多分。上課的人從四十多人,到了期中只有十來個人,我開始擔心是不是要掛科了。最後,還是堅持到期末。他把成績貼在他辦公室門上,當我懷著忐忑不安心情去看分的時候,發現他給每個人都是A。
第四個人是David Mumford。我把他放在這裡,有點私心,因為他是我博士導師。他說他60年代初本來對人工智慧感興趣。因為他數學能力特別強,上代數幾何課程的時候就發現能夠證明大定理了,結果一路不可收拾,拿了菲爾茨獎。但是,到了80年代中期,他不忘初心,還是決定轉回到人工智慧方向來,從計算機視覺和計算神經科學入手。我聽說他把原來代數幾何的書全部拿下書架放在走廊,讓人拿走,再也不看了。數學家來訪問,他也不接待了。計算機視覺80年代至90年代初,一個最大的流派就是做幾何和不變數,他是這方面的行家,但他根本不過問這個方向。他就從頭開始學概率,那個時候他搞不懂的問題就帶我去敲樓上統計系教授的門,比如去問哈佛一個有名的概率學家Persy Diaconis。他完全是一個學者,放下架子去學習新東西,直奔關鍵的體系,而不是拿著手上用慣了的錘子到處找釘子 — 這是我最佩服的地方。然後,他皈依了廣義模式理論。他的貢獻,我就避嫌不說了。
這個時期,還有一個重要的人物是做神經網路和深度學習的多倫多大學教授Hinton。我上大學的時候,80年代後期那一次神經網路熱潮,他就出名了。他很有思想,也很堅持,是個學者型的人物。所不同的是,他下面的團隊有點像搖滾歌手,能憑著一首通俗歌曲(程式碼),迅速紅遍大江南北。這裡順便說一下,我跟Hinton只見過一面。他腰椎疾病使得他不能到處作報告,前幾年來UCLA做講座(那時候深度學習剛剛開始起來),我們安排了一個面談。一見面,他就說“我們總算見面了”,因為他讀過我早期做的統計紋理模型和隨機演算法的一些論文,他們學派的一些模型和演算法與我們做的工作在數理層面有很多本質的聯絡。我列印了一篇綜述文章給他帶在坐火車回去的路上看。這是一篇關於隱式(馬爾科夫場)與顯式(稀疏)模型的統一與過渡的資訊尺度的論文,他回Toronto後就發來郵件,說很高興讀到這篇論文。很有意思的是,這篇論文的初稿,我和學生匿名投到CVPR會議,三個評分是“(5)強烈拒絕;(5)強烈拒絕;(4)拒絕”。評論都很短:“這篇文章不知所云,很怪異weird”。我們覺得文章死定了,就懶得反駁 (rebuttal),結果出乎意外地被錄取了。當然,發表了也沒人讀懂。所以,我就寫成一篇長的綜述,算是暫時擱置了。我把這篇論文給他看,Hinton畢竟是行家,他一定也想過類似的問題。最近,我們又回去做這個問題,我在今年的ICIP大會特邀報告上還提到這個問題,後面也會作為一個《視覺求索》文章釋出出來。這是一個十分關鍵的問題,就是兩大類概率統計模型如何統一起來(就像物理學,希望統一某兩個力和場),這是繞不過去的。
扯遠了,回到人工智慧的歷史時期,我作了一個比較通俗的說法,讓大家好記住,相當於咱們中國早期的歷史。早期數理邏輯的體制相當於周朝,到80年代這個體制瓦解了,人工智慧大概有二三十年不存在了,說起人工智慧大家都覺得不著調,汙名化了。其實,它進入一個春秋五霸時期,計算機視覺、自然語言理解、認知科學、機器學習、機器人學五大學科獨立發展。在發展壯大的過程中,這些學科都發現了一個新的平臺或者模式,就是概率建模和隨機計算。春秋時期雖然有一些征戰,但還是相對平靜的時期。
那麼現在開始進入一個什麼狀態呢?這“春秋五霸”不斷擴充地盤和人馬,在一個共同平臺上開始互動了。比如說視覺跟機器學習很早就開始融合了。現在視覺與自然語言、視覺跟認知、視覺跟機器人開始融合了。近年來,我和合作者就多次組織這樣的聯席研討會。現在,學科之間則開始兼併了,就像是中國歷史上的“戰國七雄”時期。除了五霸,還有原來留在人工智慧裡面的兩個大方向:博弈決策和倫理道德。這兩者其實很接近,我後面把它們歸併到一起來講,一共六大領域,我把它歸納為“戰國六雄”。
所以,我跟那些計算機視覺的研究生和年輕人說,你們不要單純在視覺這裡做,你趕緊出去“搶地盤”,單獨做視覺,已經沒有多少新東西可做的了,效能調不過公司的人是一方面;更麻煩的是,別的領域的人打進來,把你的地盤給佔了。這是必然發生的事情,現在正在發生的事情。
我的判斷是,我們剛剛進入一個“戰國時期”,以後就要把這些領域統一起來。首先我們必須深入理解計算機視覺、自然語言、機器人等領域,這裡面有很豐富的內容和語意。如果您不懂這些問題domain的內涵,僅僅是做機器學習就稱作人工智慧專家,恐怕說不過去。
我們正在進入這麼一個大整合的、大變革的時代,有很多機會讓我們去探索前沿,不要辜負了這個時代。這是我演講的第一個部分:人工智慧的歷史、現狀,發展的大趨勢。
下面,進入我今天演講的第二個主題:用一個什麼樣的構架把這些領域和問題統一起來。我不敢說我有答案,只是給大家提出一些問題、例子和思路,供大家思考。不要指望我給你提供程式碼,下載回去,調調引數就能發文章。
第四節 人工智慧研究的認知構架:小資料、大任務正規化
智慧是一種現象,表現在個體和社會群體的行為過程中。回到前面烏鴉的例子,我認為智慧系統的根源可以追溯到兩個基本前提條件:
一、物理環境客觀的現實與因果鏈條。這是外部物理環境給烏鴉提供的、生活的邊界條件。在不同的環境條件下,智慧的形式會是不一樣的。任何智慧的機器必須理解物理世界及其因果鏈條,適應這個世界。
二、智慧物種與生俱來的任務與價值鏈條。這個任務是一個生物進化的“剛需”。如個體的生存,要解決吃飯和安全問題,而物種的傳承需要交配和社會活動。這些基本任務會衍生出大量的其它的“任務”。動物的行為都是被各種任務驅動的。任務代表了價值觀和決策函式,這些價值函式很多在進化過程中就已經形成了,包括人腦中發現的各種化學成分的獎懲調製,如多巴胺(快樂)、血清素(痛苦)、乙醯膽鹼(焦慮、不確定性)、去甲腎上腺素(新奇、興奮)等。
有了物理環境的因果鏈和智慧物種的任務與價值鏈,那麼一切都是可以推匯出來的。要構造一個智慧系統,如機器人或者遊戲環境中的虛擬的人物,我們先給他們定義好身體的基本行動的功能,再定一個模型的空間(包括價值函式)。其實,生物的基因也就給了每個智慧的個體這兩點。然後,它就降臨在某個環境和社會群體之中,就應該自主地生存,就像烏鴉那樣找到一條活路:認識世界、利用世界、改造世界。
這裡說的模型的空間是一個數學的概念,我們人腦時刻都在改變之中,也就是一個抽象的點,在這個空間中移動。模型的空間通過價值函式、決策函式、感知、認知、任務計劃等來表達。通俗來說,一個腦模型就是世界觀、人生觀、價值觀的一個數學的表達。這個空間的複雜度決定了個體的智商和成就。我後面會講到,這個模型的表達方式和包含哪些基本要素。
有了這個先天的基本條件(設計)後,下一個重要問題:是什麼驅動了模型在空間中的運動,也就是學習的過程?還是兩點:
一、 外來的資料。外部世界通過各種感知訊號,傳遞到人腦,塑造我們的模型。資料來源於觀察(observation)和實踐(experimentation)。觀察的資料一般用於學習各種統計模型,這種模型就是某種時間和空間的聯合分佈,也就是統計的關聯與相關性。實踐的資料用於學習各種因果模型,將行為與結果聯絡在一起。因果與統計相關是不同的概念。
二、內在的任務。這就是由內在的價值函式驅動的行為、以期達到某種目的。我們的價值函式是在生物進化過程中形成的。因為任務的不同,我們往往對環境中有些變數非常敏感,而對其它一些變數不關心。由此,形成不同的模型。
機器人的腦、人腦都可以看成一個模型。任何一個模型由資料與任務來共同塑造。
現在,我們就來到一個很關鍵的地方。同樣是在概率統計的框架下,當前的很多深度學習方法,屬於一個被我稱作“大資料、小任務正規化(big data for small task)”。針對某個特定的任務,如人臉識別和物體識別,設計一個簡單的價值函式Loss function,用大量資料訓練特定的模型。這種方法在某些問題上也很有效。但是,造成的結果是,這個模型不能泛化和解釋。所謂泛化就是把模型用到其它任務,解釋其實也是一種複雜的任務。這是必然的結果:你種的是瓜, 怎麼希望得豆呢?
我多年來一直在提倡的一個相反的思路:人工智慧的發展,需要進入一個“小資料、大任務正規化(small data for big tasks)”,要用大量任務、而不是大量資料來塑造智慧系統和模型。在哲學思想上,必須有一個思路上的大的轉變和顛覆。自然辨證法裡面,恩格斯講過,“勞動創造了人”,這個有點爭議。我認為一個更合適的說法是“任務塑造了智慧”。人的各種感知和行為,時時刻刻都是被任務驅動的。這是我過去很多年來一直堅持的觀點,也是為什麼我總體上不認可深度學習這個學派的做法,雖然我自己是最早提倡統計建模與學習的一批人,但是後來我看到了更大的問題和局勢。當然,我們的假設前提是智慧系統已經有了前面講的基本的設定,這個系統設定是億萬年的進化得來的,是不是通過大量資料了打磨(淘汰)出來的呢。有道理!如果我們把整個發展的過程都考慮進來,智慧系統的影響可以分成三個時間段:(1)億萬年的進化,被達爾文理論的一個客觀的適者生存的pheontype landscape驅動;(2)千年的文化形成與傳承;(3)幾十年個體的學習與適應。 我們人工智慧研究通常考慮的是第三個階段。
那麼,如何定義大量的任務?人所感興趣的任務有多少,是個什麼空間結構?這個問題,心理和認知科學一直說不清楚,寫不下來。這是人工智慧發展的一個巨大挑戰。
理清了這些前提條件,帶著這樣的問題,下面我用六節分別介紹六大領域的問題和例子,看能不能找到共性的、統一的框架和表達模型。過去幾年來,我的研究中心一直把這六個領域的問題綜合在一起研究,目的就是尋找一個統一的構架,找到“烏鴉”這個解。
第五節 計算機視覺:從“深”到“暗” Dark, Beyond Deep
視覺是人腦最主要的資訊來源,也是進入人工智慧這個殿堂的大門。我自己的研究也正是從這裡入手的。這一節以一個具體例子來介紹視覺裡面的問題。當然,很多問題遠遠沒有被解決。

這是我家廚房的一個視角。多年前的一個下午,我女兒放學回家,我正在寫一個大的專案申請書,就拍了這一張作為例子。影象就是一個畫素的二維矩陣,可是我們感知到非常豐富的三維場景、行為的資訊;你看的時間越長,理解的也越多。下面我列舉幾個被主流(指大多數研究人員)忽視的、但是很關鍵的研究問題。
一、幾何常識推理與三維場景構建。以前計算機視覺的研究,需要通過多張影象(多視角)之間特徵點的對應關係,去計算這些點在三維世界座標系的位置(SfM、SLAM)。其實人只需要一張影象就可以把三維幾何估算出來。最早我在2002與一個學生韓峰發表了一篇文章,受到當時幾何學派的嘲笑:一張影象怎麼能計算三維呢,數學上說不通呀。其實,在我們的人造環境中,有很多幾何常識和規律:比如,你坐的椅子高度就是你小腿的長度約16英寸,桌子約30英寸,案臺約35英寸,門高約80英寸 — 都是按照人的身體尺寸和動作來設計的。另外,人造環境中有很多重複的東西,比如幾個窗戶一樣大小一致,建築設計和城市規劃都有規則。這些就是geometric common sense,你根據這些幾何的約束就可以定位很多點的三維位置,同時估計相機位置和光軸。
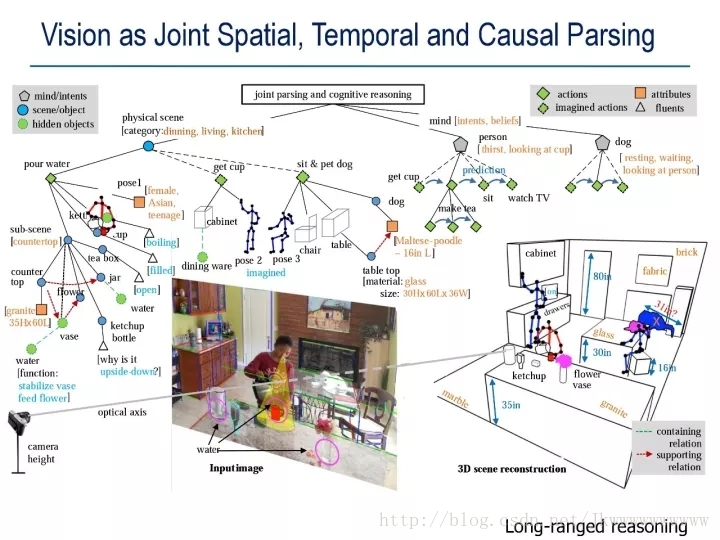
見下圖所示,在這個三維場景中,我們的理解就可以表達成為一個層次分解(compositional)的時空因果的解譯圖(Spatial,Temporal and Causal Parse Graph),簡稱 STC-PG。STC-PG是一個極其重要的概念,我下面會逐步介紹。
幾何重建的一個很重要的背景是,我們往往不需要追求十分精確的深度位置。比如,人對三維的感知其實都是非常不準的,它的精確度取決於你當前要執行的任務。在執行的過程中,你不斷地根據需要來提高精度。比如,你要去拿幾米以外的一個杯子,一開始你對杯子的方位只是一個大致的估計,在你走近、伸手的過程中逐步調整精度。
這就回到上一節談的問題,不同任務對幾何與識別的精度要求不一樣。這是人腦計算非常高效的一個重要原因。最近,我以前一個博士後劉曉白(現在是助理教授)和我其他學生在這方面取得了很好進展,具體可以檢視他們相關文章。
二、場景識別的本質是功能推理。現在很多學者做場景的分類和分割都是用一些影象特徵,用大量的圖片例子和手工標註的結果去訓練神經網路模型 — 這是典型的“鸚鵡”模式。而一個場景的定義本質上就是功能。當你看到一個三維空間之後,人腦很快就可以想象我可以幹什麼:這個地方倒水,這裡可以拿杯子,這裡可以坐著看電視等。現代的設計往往是複合的空間,就是一個房間可以多種功能,所以簡單去分類已經不合適了。比如,美式廚房可以做飯、洗菜、用餐、聊天、吃飯。臥室可以睡覺、梳妝、放衣服、看書。場景的定義是按照你在裡面能夠幹什麼,這個場景就是個什麼,按照功能劃分,這些動作都是你想象出來的,實際影象中並沒有。人腦感知的識別區與運動規劃區是直接互通的,相互影響。我的博士學生趙一彪就是做這個的,他畢業去了MIT做認知科學博後,現在創立了一家自動駕駛的AI公司。
為了想象這些功能,人腦有十分豐富的動作模型,這些動作根據尺度分為兩類(見下圖)。第一類(左圖)是與整個身體相關的動作,如坐、站、睡覺、工作等等;第二類(右圖)是與手的動作相關的,如砸、剁、鋸、撬等等。這些四維基本模型(三維空間加一維時間)可以通過日常活動記錄下來,表達了人的動作和傢俱之間,以及手和工具之間的關係。正因為這一點,心理學研究發現我們將物體分成兩大類,分別存放在腦皮層不同區域:一類是跟手的大小有關,跟手的動作相關的,如你桌上的東西;另一類是跟身體有關,例如傢俱之類。
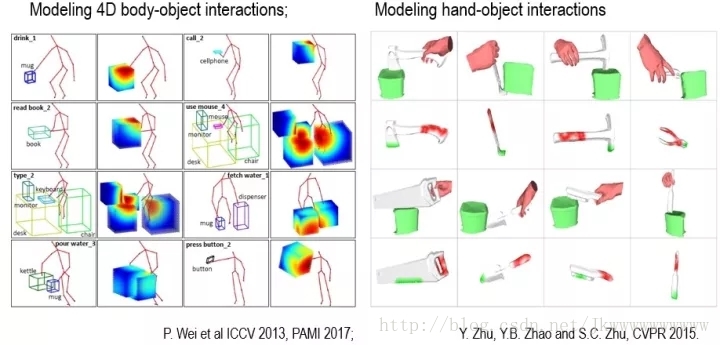
有了這個理解,我們就知道:下面兩張圖,雖然影象特徵完全不同,但是他們是同一類場景,功能上是等價的。人的活動和行為,不管你是哪個國家、哪個歷史時期,基本是不變的。這是智慧泛化的基礎,也就是把你放到一個新的地區,你不需要大資料訓練,馬上就能理解、適應。這是我們能夠舉一反三的一個基礎。

回到前面的那個STC-PG解譯圖,每個場景底下其實就分解成為一些動作和功能 (見STC-PG圖中的綠色方片節點)。由計算機想象、推理的各種功能決定對場景的分類。 想象功能就是把人的各種姿態放到三維場景中去擬合(見廚房解譯圖中人體線畫)。這是完全不同於當前的深度學習方法用的分類方法。
三、物理穩定性與關係的推理。我們的生活空間除了滿足人類的各種需求(功能、任務)之外, 另一個基本約束就是物理。我們對影象的解釋和理解被表達成為一個解譯圖,這個解譯圖必須滿足物理規律,否則就是錯誤的。比如穩定性是人可以快速感知的,如果你發現周圍東西不穩,要倒了,你反應非常快,趕緊閃開。最近我們專案組的耶魯大學教授Brian Scholl的認知實驗發現,人對物理穩定性的反應是毫秒級,第一反應時間大約 100ms。
我們對影象的理解包含了物體之間的物理關係,每個物體的支撐點在那裡。比如,下面這個圖,吊燈和牆上掛的東西,如果沒有支撐點,就會掉下來(右圖)。這個研究方向,MIT認知科學系的Josh Tenenbuam教授與我都做了多年。

我提出了一個新的場景理解的minimax標準:minimize instability and maximize functionality最小化不穩定性且最大化功能性。這比以前我們做影象理解的用的MDL(最小描述長度)標準要更靠譜。這是解決計算機視覺的基本原理,功能和物理是設計場景的基本原則。幾何尺寸是附屬於功能推出來的,比如椅子的高度就是因為你要坐得舒服,所以就是你小腿的長度。
回到我家廚房的例子,你就會問,那裡面的水是如何被檢測到的呢?水是看不見的,花瓶和水壺裡的水由各種方式推出來的。另外,你可能注意到,桌上的番茄醬瓶子是倒立著,為什麼呢? 你可能很清楚,你家的洗頭膏快用完的時候,瓶子是不是也是的倒著放的呢?這就是對粘稠液體的物理和功能理解之後的結果。由此,你可以看到我們對一個場景的理解是何等“深刻”,遠遠超過了用深度學習來做的物體分類和檢測。
四、意向、注意和預測。廚房那張圖有一個人和一隻狗,我們可以進一步識別其動作、眼睛注視的地方,由此推導其動機和意向。這樣我們可以計算她在幹什麼、想幹什麼,比如說她現在是渴了,還是累了。通過時間累積之後,進而知道她知道哪些,也就是她看到了或者沒有看到什麼。在時間上做預測,她下面想幹什麼。只有把這些都計算出來了,機器才能更好地與人進行互動。
所以,雖然我們只看到一張圖片,那張STC-PG中,我們增加了時間維度,對人和動物的之前和之後的動作,做一個層次的分析和預測。當機器人能夠預判別人的意圖和下面的動作,那麼它才能和人進行互動和合作。後面,我們講的語言對話可以幫助人機互動和合作;但是,我們日常很多互動協助,靠的是默契,不需要言語也能做不少事。
下面的這一張圖,是多攝像機的一個綜合場景的解譯例項。這是我的實驗室做出來的一個視覺系統。這個視訊的理解就輸出為一個大的綜合的STC-PG。在此基礎上,就可以輸出文字的描述(I2T)和回答提問 QA。我們把它叫做視覺圖靈測試,網址:visualturingtest.com。
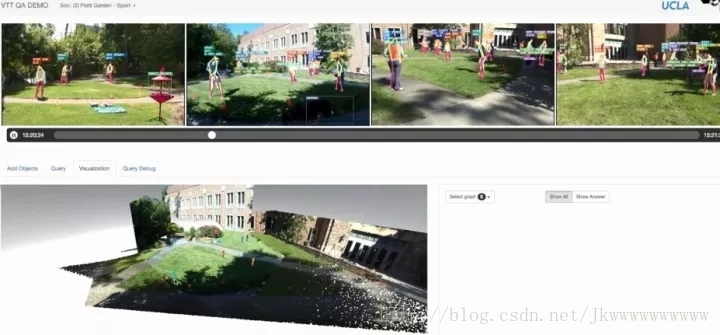
與第一節講的機器人競賽類似,這也是一個DARPA專案。測試就是用大量視訊,我們算出場景和人的三維的模型、動作、屬性、關係等等,然後就來回答各種各樣的1000多個問題。現在一幫計算機視覺的人研究VQA(視覺問答),就是拿大量的影象和文字一起訓練,這是典型的“鸚鵡”系統,基本都是“扯白”。回答的文字沒有真正理解影象的內容,常常邏輯不通。我們這個工作是在VQA之前,認真做了多年。我們系統在專案DARPA測試中領先,當時其它團隊根本無法完成這項任務。可是,現在科研的一個現實是走向“娛樂化”:膚淺的歌曲流行,大家都能唱,複雜高深的東西大家躲著走。
既然說到這裡,我就順便說說一些競賽的事情。大約從2008年開始,CVPR會議的風氣就被人“帶到溝裡”了,組織各種資料集競賽,不談理解了,就是數字掛帥。中國很多學生和團隊就開始參與,俗稱“刷榜”。我那個時候跟那些組織資料集的人說(其實我自己2005年是最早在湖北蓮花山做大型資料標註的,但我一早就看到這個問題,不鼓勵刷榜),你們這些比賽前幾名肯定是中國學生或者公司。現在果然應驗了,大部分榜上前幾名都是中國人名字或單位了。咱們刷榜比打乒乓球還厲害,刷榜變成咱們AI研究的“國球”。所謂刷榜,一般是下載了人家的程式碼,改進、調整、搭建更大模組,這樣速度快。我曾經訪問一家技術很牛的中國公司(不是搞視覺的),那個公司的研發主管非常驕傲,說他們刷榜總是贏,美國一流大學都不在話下。我聽得不耐煩了,我說人家就是兩個學生在那裡弄,你們這麼大個團隊在這裡刷,你程式碼裡面基本沒有演算法是你自己的。如果人家之前不公佈程式碼,你們根本沒法玩。很多公司就拿這種刷榜的結果宣傳自己超過了世界一流水平。
五、任務驅動的因果推理與學習。前面我談了場景的理解的例子,下面我談一下物體的識別和理解,以及為什麼我們不需要大資料的學習模式,而是靠舉一反三的能力。
我們人是非常功利的社會動物,就是說做什麼事情都是被任務所驅動的。這一點,2000年前的司馬遷就已經遠在西方功利哲學之前看到了( 《史記》 “貨殖列傳” ):
“天下熙熙,皆為利來;天下攘攘,皆為利往。”
那麼,人也就帶著功利的目的來看待這個世界,這叫做“teleological stance”。這個物體是用來幹什麼的?它對我有什麼用?怎麼用?
當然,有沒有用是相對於我們手頭的任務來決定的。很多東西,當你用不上的時候,往往視而不見;一旦要急用,你就會當個寶。俗話叫做“勢利眼”,沒辦法,這是人性!你今天干什麼、明天干什麼,每時每刻都有任務。俗話又叫做“屁股決定腦袋”,一個官員坐在不同位置,他就有不同的任務與思路,位置一調,馬上就“物是人非”了。
我們的知識是根據我們的任務來組織的。那麼什麼叫做任務呢?如何表達成數學描述呢?
每個任務其實是在改變場景中的某些物體的狀態。牛頓發明了一個詞,在這裡被借用了:叫做fluent。這個詞還沒被翻譯到中文,就是一種可以改變的狀態,我暫且翻譯為“流態”吧。比如,把水燒開,水溫就是一個流態;番茄醬與瓶子的空間位置關係是一個流態,可以被擠出來;還有一些流態是人的生物狀態,比如餓、累、喜悅、悲痛;或者社會關係: