
多執行緒下HashMap的死迴圈
阿新 • • 發佈:2018-11-01
多執行緒下HashMap的死迴圈
Java的HashMap是非執行緒安全的。多執行緒下應該用ConcurrentHashMap。
多執行緒下[HashMap]的問題(這裡主要說死迴圈問題):
1、多執行緒put操作後,get操作導致死迴圈。
2、多執行緒put非NULL元素後,get操作得到NULL值。
3、多執行緒put操作,導致元素丟失。
1、為何出現死迴圈?
HashMap是採用連結串列解決Hash衝突,因為是連結串列結構,那麼就很容易形成閉合的鏈路,這樣在迴圈的時候只要有執行緒對這個HashMap進行get操作就會產生死迴圈。
那就只有在多執行緒併發的情況下才會出現這種情況,那就是在put操作的時候,如果size>initialCapacity*loadFactor,那麼這時候HashMap就會進行rehash操作,隨之HashMap的結構就會發生翻天覆地的變化。很有可能就是在兩個執行緒在這個時候同時觸發了rehash操作,產生了閉合的迴路。
2、如何產生的:
儲存資料put():
如果這個元素所在的位置上已經存放有其他元素了,那麼在同一個位子上的元素將以連結串列的形式存放,新加入的元素放在鏈頭,而先前加入的放在鏈尾。
檢查容量是否超標addEntry:
調整Hash表大小resize:
一般來說,Hash表這個容器當有資料要插入時,都會檢查容量有沒有超過設定的thredhold,如果超過,需要增大Hash表的尺寸,這個過程稱為resize。
多個執行緒同時往HashMap新增新元素時,多次resize會有一定概率出現死迴圈,因為每次resize需要把舊的資料對映到新的雜湊表,這一部分程式碼在HashMap#transfer() 方法,如下:
3、圖解HashMap死迴圈:
正常的ReHash的過程(單執行緒):
假設了我們的hash演算法就是簡單的用key mod 一下表的大小(也就是陣列的長度)。
最上面的是old hash 表,其中的Hash表的size=2, 所以key = 3, 7, 5,在mod 2以後都衝突在table[1]這裡了。
接下來的三個步驟是Hash表 resize成4,然後所有的<key,value> 重新rehash的過程。
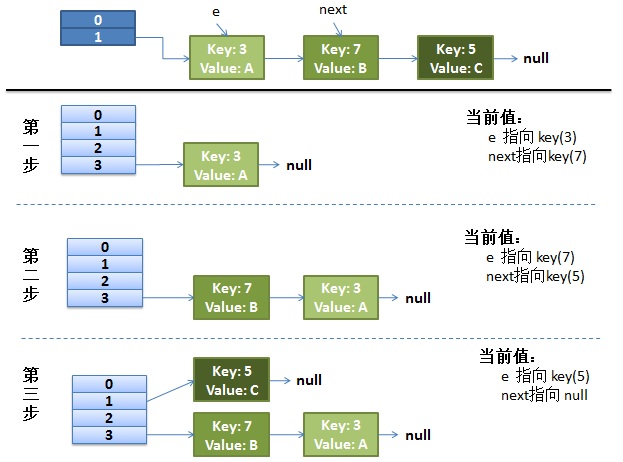
併發下的Rehash(多執行緒)
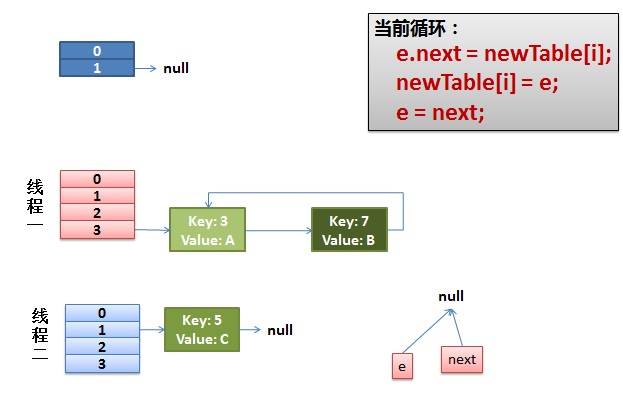
1)假設我們有兩個執行緒。
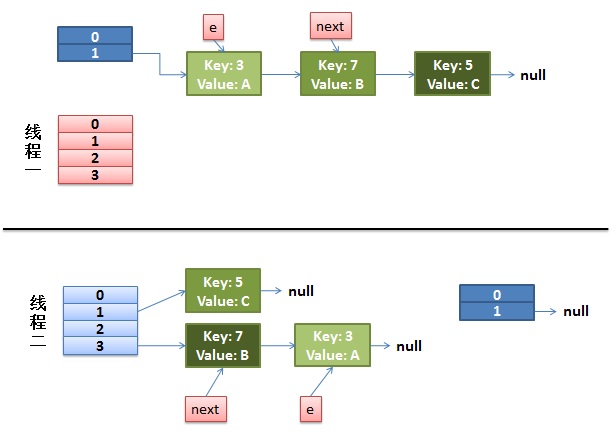
注意,因為Thread1的 e 指向了key(3),而next指向了key(7),其線上程二rehash後,指向了執行緒二重組後的連結串列。我們可以看到連結串列的順序被反轉後。在這裡執行緒一變成了操作經過執行緒二操作後的HashMap。
2)執行緒一被排程回來執行。
先是執行 newTalbe[i] = e;
然後是e = next,導致了e指向了key(7),
而下一次迴圈的next = e.next導致了next指向了key(3)。
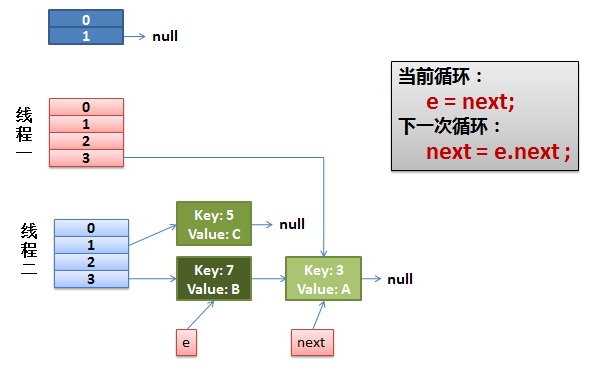
3)一切安好。
執行緒一接著工作。把key(7)摘下來,放到newTable[i]的第一個,然後把e和next往下移。這個元素所在的位置上已經存放有其他元素了,那麼在同一個位子上的元素將以連結串列的形式存放,新加入的放在鏈頭,而先前加入的放在鏈尾。
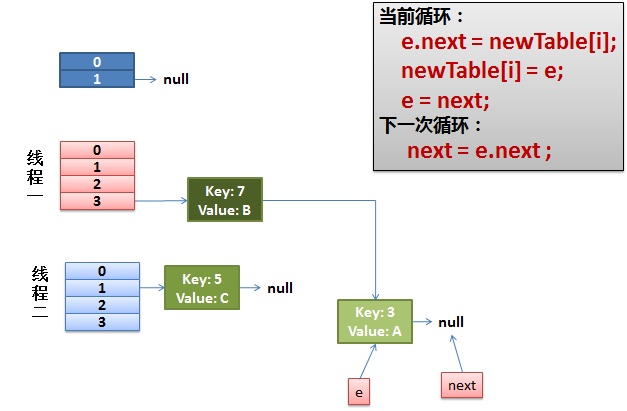
4)環形連結出現。
e.next = newTable[i] 導致 key(3).next 指向了 key(7)。
注意:此時的key(7).next 已經指向了key(3), 環形連結串列就這樣出現了。
於是,當我們的執行緒一呼叫到,HashTable.get(11)時,悲劇就出現了——Infinite Loop。
疫苗:Java HashMap的死迴圈
每天努力一點,每天都在進步。
Java的HashMap是非執行緒安全的。多執行緒下應該用ConcurrentHashMap。
多執行緒下[HashMap]的問題(這裡主要說死迴圈問題):
1、多執行緒put操作後,get操作導致死迴圈。
2、多執行緒put非NULL元素後,get操作得到NULL值。
3、多執行緒put操作,導致元素丟失。
1、為何出現死迴圈?
HashMap是採用連結串列解決Hash衝突,因為是連結串列結構,那麼就很容易形成閉合的鏈路,這樣在迴圈的時候只要有執行緒對這個HashMap進行get操作就會產生死迴圈。
那就只有在多執行緒併發的情況下才會出現這種情況,那就是在put操作的時候,如果size>initialCapacity*loadFactor,那麼這時候HashMap就會進行rehash操作,隨之HashMap的結構就會發生翻天覆地的變化。很有可能就是在兩個執行緒在這個時候同時觸發了rehash操作,產生了閉合的迴路。
2、如何產生的:
儲存資料put():
public V put(K key, V value)
{
......
//算Hash值
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//如果該key已被插入,則替換掉舊的value (連結操作)
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//該key不存在,需要增加一個結點
addEntry(hash, key, value, i); 如果這個元素所在的位置上已經存放有其他元素了,那麼在同一個位子上的元素將以連結串列的形式存放,新加入的元素放在鏈頭,而先前加入的放在鏈尾。
檢查容量是否超標addEntry:
void addEntry(int hash, K key, V value, int bucketIndex)
{
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
//檢視當前的size是否超過了我們設定的閾值threshold,如果超過,需要resize
if (size++ >= threshold)
resize(2 * table.length); 調整Hash表大小resize:
void resize(int newCapacity)
{
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
......
//建立一個新的Hash Table
Entry[] newTable = new Entry[newCapacity];
//將Old Hash Table上的資料遷移到New Hash Table上
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}一般來說,Hash表這個容器當有資料要插入時,都會檢查容量有沒有超過設定的thredhold,如果超過,需要增大Hash表的尺寸,這個過程稱為resize。
多個執行緒同時往HashMap新增新元素時,多次resize會有一定概率出現死迴圈,因為每次resize需要把舊的資料對映到新的雜湊表,這一部分程式碼在HashMap#transfer() 方法,如下:
void transfer(Entry[] newTable)
{
Entry[] src = table;
int newCapacity = newTable.length;
//下面這段程式碼的意思是:
// 從OldTable裡摘一個元素出來,然後放到NewTable中
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;//取出第一個元素
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}3、圖解HashMap死迴圈:
正常的ReHash的過程(單執行緒):
假設了我們的hash演算法就是簡單的用key mod 一下表的大小(也就是陣列的長度)。
最上面的是old hash 表,其中的Hash表的size=2, 所以key = 3, 7, 5,在mod 2以後都衝突在table[1]這裡了。
接下來的三個步驟是Hash表 resize成4,然後所有的<key,value> 重新rehash的過程。
併發下的Rehash(多執行緒)
1)假設我們有兩個執行緒。
do {
Entry<K,V> next = e.next; // <--假設執行緒一執行到這裡就被排程掛起了,執行其他操作
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);注意,因為Thread1的 e 指向了key(3),而next指向了key(7),其線上程二rehash後,指向了執行緒二重組後的連結串列。我們可以看到連結串列的順序被反轉後。在這裡執行緒一變成了操作經過執行緒二操作後的HashMap。
2)執行緒一被排程回來執行。
先是執行 newTalbe[i] = e;
然後是e = next,導致了e指向了key(7),
而下一次迴圈的next = e.next導致了next指向了key(3)。
3)一切安好。
執行緒一接著工作。把key(7)摘下來,放到newTable[i]的第一個,然後把e和next往下移。這個元素所在的位置上已經存放有其他元素了,那麼在同一個位子上的元素將以連結串列的形式存放,新加入的放在鏈頭,而先前加入的放在鏈尾。
4)環形連結出現。
e.next = newTable[i] 導致 key(3).next 指向了 key(7)。
注意:此時的key(7).next 已經指向了key(3), 環形連結串列就這樣出現了。
於是,當我們的執行緒一呼叫到,HashTable.get(11)時,悲劇就出現了——Infinite Loop。
疫苗:Java HashMap的死迴圈
每天努力一點,每天都在進步。