
hbase架構原理之region、memstore、hfile、hlog、columm-family、colum、cell
Hbase的頂級儲存結構是表,Hbase的表可以理解成是行的集合,行(記錄)是列族的集合,列族是列的集合。這裡有重點介紹幾個容易混爻的幾個感念!
HBase採用Master/Slave架構搭建叢集,它隸屬於Hadoop生態系統,由一下型別節點組成:HMaster節點、HRegionServer節點、ZooKeeper叢集,而在底層,它將資料儲存於HDFS中,因而涉及到HDFS的NameNode、DataNode等,總體結構如下:

HMaster節點用於:
管理HRegionServer,實現其負載均衡;
管理和分配HRegion,比如在HRegion split時分配新的HRegion;
在HRegionServer退出時遷移其內的HRegion到其他HRegionServer上。實現DDL操作(Data Definition Language,namespace和table的增刪改,column familiy的增刪改等)。
管理namespace和table的元資料(實際儲存在HDFS上)。
許可權控制(ACL)。
HRegion
假設我們有100億條資料,這麼大的資料無法儲存到一臺機器上,這時hbase水平切分成不同的分片,分片就是region,一個regionServer包含若干region,由於是水平切分,一條完整的資料一定是隻屬於一個region,其實hbase底層存儲存結構是key-value形式的,key就是row-key!
HBase使用RowKey將表水平切割成多個HRegion,從HMaster的角度,每個HRegion都紀錄了它的StartKey和EndKey(第一個HRegion的StartKey為空,最後一個HRegion的EndKey為空),由於RowKey是排序的,因而Client可以通過HMaster快速的定位每個RowKey在哪個HRegion中。HRegion由HMaster分配到相應的HRegionServer中,然後由HRegionServer負責HRegion的啟動和管理,和Client的通訊,負責資料的讀(使用HDFS)。
列族column family
它是column的集合,在建立表的時候就指定,不能頻繁修改。值得注意的是,列族的數量越少越好,因為過多的列族相互之間會影響,生產環境中的列族一般是一個到兩個
hdfs://h201:8020/hbase/data/${名字空間}/${表名}/${區域名稱}/${列族名稱}/${檔名}
舉例:/hbase/data/ns1/t1/a4d63a61a8da24a863bff3c8d7cd20de/f1/c2a7fa8c41304b9e9b8b24b4a89171ce
其中{區域名稱}是t1的region, 由每張表切割形成,一張表由若干個region組成,不同的region分到不同的region server以便均衡負載
列column
和列族的限制數量不同,列族可以包含很多個列,前面說的“幾十億行*百萬列”就是這個意思。
列的值cell
存在單元格(cell)中。每一列的值允許有多個版本,由timestamp來區分不同版本。多個版本產生原因:向同一行下面的同一個列多次插入資料,
每插入一次就有一個對應版本的value。
MemStore Flush
MemStore是一個In Memory Sorted Buffer,在每個HStore中都有一個MemStore,即它是一個HRegion的一個Column Family對應一個例項。它的排列順序以
RowKey、Column Family、Column的順序以及Timestamp的倒序,如下所示:

每一次Put/Delete請求都是先寫入到MemStore中,當MemStore滿後會Flush成一個新的StoreFile(底層實現是HFile),即一個HStore(Column Family)可以有0個或多個StoreFile(HFile)。
有以下三種情況可以觸發MemStore的Flush動作,需要注意的是MemStore的最小Flush單元是HRegion而不是單個MemStore。據說這是Column Family有個數限制的其中一個原因,估計是因為太多的Column Family一起Flush會引起效能問題?具體原因有待考證。
1、當一個HRegion中的所有MemStore的大小總和超過了hbase.hregion.memstore.flush.size的大小,預設128MB。此時當前的HRegion中所有的MemStore會Flush到HDFS中。
2、當全域性MemStore的大小超過了hbase.regionserver.global.memstore.upperLimit的大小,預設40%的記憶體使用量。此時當前HRegionServer中所有HRegion中的MemStore都會Flush到HDFS中,Flush順序是MemStore大小的倒序(一個HRegion中所有MemStore總和作為該HRegion的MemStore的大小還是選取最大的MemStore作為參考?有待考證),直到總體的MemStore使用量低於hbase.regionserver.global.memstore.lowerLimit,預設38%的記憶體使用量。
3、當前HRegionServer中WAL的大小超過了hbase.regionserver.hlog.blocksize * hbase.regionserver.max.logs的數量,當前HRegionServer中所有HRegion中的MemStore都會Flush到HDFS中,Flush使用時間順序,最早的MemStore先Flush直到WAL的數量少於hbase.regionserver.hlog.blocksize * hbase.regionserver.max.logs。這裡說這兩個相乘的預設大小是2GB,查程式碼,hbase.regionserver.max.logs預設值是32,而hbase.regionserver.hlog.blocksize是HDFS的預設blocksize,32MB。但不管怎麼樣,因為這個大小超過限制引起的Flush不是一件好事,可能引起長時間的延遲,因而這篇文章給的建議:“Hint: keep hbase.regionserver.hlog.blocksize * hbase.regionserver.maxlogs just a bit above hbase.regionserver.global.memstore.lowerLimit * HBASE_HEAPSIZE.”。並且需要注意,這裡給的描述是有錯的(雖然它是官方的文件)。http://hbase.apache.org/book.html#_memstore_flush
在MemStore Flush過程中,還會在尾部追加一些meta資料,其中就包括Flush時最大的WAL sequence值,以告訴HBase這個StoreFile寫入的最新資料的序列,那麼在Recover時就直到從哪裡開始。在HRegion啟動時,這個sequence會被讀取,並取最大的作為下一次更新時的起始sequence。

HFile格式
HBase的資料以KeyValue(Cell)的形式順序的儲存在HFile中,在MemStore的Flush過程中生成HFile,由於MemStore中儲存的Cell遵循相同的排列順序,因而Flush過程是順序寫,我們直到磁碟的順序寫效能很高,因為不需要不停的移動磁碟指標。

HFile參考BigTable的SSTable和Hadoop的TFile實現,從HBase開始到現在,HFile經歷了三個版本,其中V2在0.92引入,V3在0.98引入。首先我們來看一下
V1的格式:
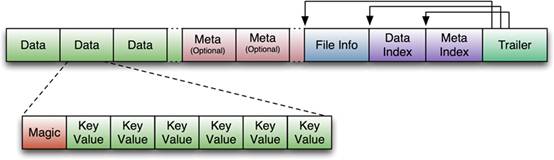
V1的HFile由多個Data Block、Meta Block、FileInfo、Data Index、Meta Index、Trailer組成,其中Data Block是HBase的最小儲存單元,在前文中提到的BlockCache就是基於Data Block的快取的。
一個Data Block由一個魔數和一系列的KeyValue(Cell)組成,魔數是一個隨機的數字,用於表示這是一個Data Block型別,以快速監測這個Data Block的格式,防止資料的破壞。
Data Block的大小可以在建立Column Family時設定(HColumnDescriptor.setBlockSize()),預設值是64KB,大號的Block有利於順序Scan,小號Block利於隨機查詢,因而需要權衡。Meta塊是可選的,FileInfo是固定長度的塊,它紀錄了檔案的一些Meta資訊,例如:AVG_KEY_LEN, AVG_VALUE_LEN, LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEY等。Data Index和Meta Index紀錄了每個Data塊和Meta塊的起始點、未壓縮時大小、Key(起始RowKey?)等。
Trailer紀錄了FileInfo、Data Index、Meta Index塊的起始位置,Data Index和Meta Index索引的數量等。其中FileInfo和Trailer是固定長度的。
HFile裡面的每個KeyValue對就是一個簡單的byte陣列。但是這個byte數組裡麵包含了很多項,並且有固定的結構。我們來看看裡面的具體結構:

開始是兩個固定長度的數值,分別表示Key的長度和Value的長度。緊接著是Key,開始是固定長度的數值,表示RowKey的長度,緊接著是 RowKey,然後是固定長度的數值,表示Family的長度,然後是Family,接著是Qualifier,然後是兩個固定長度的數值,表示Time Stamp和Key Type(Put/Delete)。
Value部分沒有這麼複雜的結構,就是純粹的二進位制資料了。隨著HFile版本遷移,KeyValue(Cell)的格式並未發生太多變化,只是在V3版本,尾部添加了一個可選的Tag陣列。
HFile V1版本的在實際使用過程中發現它佔用記憶體多,並且Bloom File和Block Index會變的很大,而引起啟動時間變長。其中每個HFile的Bloom Filter可以增長到100MB,這在查詢時會引起效能問題,因為每次查詢時需要載入並查詢Bloom Filter,100MB的Bloom Filer會引起很大的延遲;
另一個,Block Index在一個HRegionServer可能會增長到總共6GB,HRegionServer在啟動時需要先載入所有這些Block Index,因而增加了啟動時間。為了解決這些問題,在0.92版本中引入HFileV2版本:

在這個版本中,Block Index和Bloom Filter新增到了Data Block中間,而這種設計同時也減少了寫的記憶體使用量;另外,為了提升啟動速度,在這個版本中還引入了延遲讀的功能,即在HFile真正被使用時才對其進行解析。
FileV3版本基本和V2版本相比,並沒有太大的改變,它在KeyValue(Cell)層面上添加了Tag陣列的支援;並在FileInfo結構中添加了和Tag相關的兩個欄位。關於具
體HFile格式演化介紹,可以參考其它資料
對HFileV2格式具體分析,它是一個多層的類B+樹索引,採用這種設計,可以實現查詢不需要讀取整個檔案:

Data Block中的Cell都是升序排列,每個block都有它自己的Leaf-Index,每個Block的最後一個Key被放入Intermediate-Index中,Root-Index指向
Intermediate-Index。在HFile的末尾還有Bloom Filter用於快速定位那麼沒有在某個Data Block中的Row;TimeRange資訊用於給那些使用時間查詢的參考。
在HFile開啟時,這些索引資訊都被載入並儲存在記憶體中,以增加以後的讀取效能。
Hlog
hlog是為容錯存在的,大型分散式系統中硬體故障很常見,HBase也不例外,如果MemStore還沒有刷寫到hfile,伺服器就崩潰了,記憶體中沒有寫到硬碟的資料就丟失了。hbase的應對辦法是在寫動作完成之前,先寫入hlog,Hbase叢集中每臺伺服器維護一個hlog,直到hlog新記錄成功寫入後,寫動作才被認為是成功完成。
也就是說每個寫入到作需要同時得到memstore和hlog的確認,如果在memstore沒有寫到hfile之前宕機,資料就可以從hlog恢復!
總結一:
hbase首先按照row-key按行切分資料,每一份就是一個region(會在適當的時機合併),然後再按照列族切分,每個列族對應硬碟上的一個資料夾。所以說hbase是面向列儲存的,key-value形式的資料庫
總結二:
在查詢資料時,hbase首先根據row-key找到對應的region,然後再根據需要的列族到硬碟上找到對應的資料夾讀取資料
---------------------
作者:亞當-adam
來源:CSDN
原文:https://blog.csdn.net/zhaojianting/article/details/78480329
版權宣告:本文為博主原創文章,轉載請附上博文連結!