
hadoop編寫MapReduce例子(附有程式碼)
阿新 • • 發佈:2018-11-01
開發環境:hadoop2.6.5, jdk1.8. ubuntu14系統
1.在本地寫好程式碼(eclipse寫的,當時沒用maven,直接把jar引到程式裡了)
2.打成jar包(eclipse右鍵專案,點選export,選擇jar包型別),打jar包的時候記得引入程式入口類,以及不加入程式碼依賴的jar包
3.在叢集的master節點上,使用hadoop fs -ls -R /檢視hdfs中的檔案列表
4.在hdfs上新建資料夾data,hadoop fs -mkdir -p /user/data
5.將資料傳到data資料夾中,hadoop fs -put ddd /user/data
6.將程式打好的jar包(hadoopDemo.jar)上傳到master節點上
7.執行hadoop jar hadoopDemo.jar /user/data /user/out1(out1是輸出檔案的目錄)
程式執行成功之後的結果:
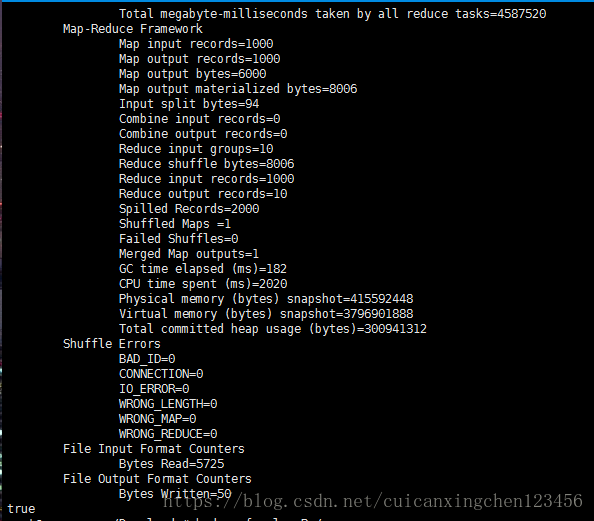
8.命令hadoop fs -cat /user/out1/part-r*檢視程式碼執行結果
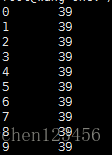
這個例子是key是0-9的隨機數,value是0-40的隨機數(用random隨機生成的)。然後找出來每個key對應的value的最大值
程式碼和資料:https://download.csdn.net/download/cuicanxingchen123456/10741216