
Hadoop之——MapReduce實戰(一)
MapReduce概述
MapReduce是一種分散式計算模型,由Google提出,主要用於搜尋領域,解決海量資料的計算問題.
MR由兩個階段組成:Map和Reduce,使用者只需要實現map()和reduce()兩個函式,即可實現分散式計算,非常簡單。
這兩個函式的形參是key、value對,表示函式的輸入資訊。
MR執行流程
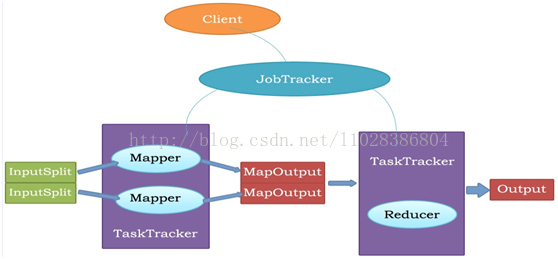
MapReduce原理
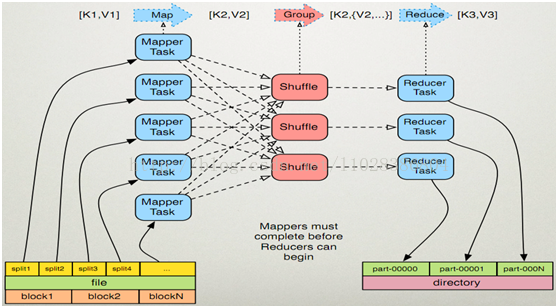
執行步驟
1. map任務處理
1.1 讀取輸入檔案內容,解析成key、value對。對輸入檔案的每一行,解析成key、value對。每一個鍵值對呼叫一次map函式。
1.2 寫自己的邏輯,對輸入的key、value處理,轉換成新的key、value輸出。
1.3 對輸出的key、value進行分割槽。
1.4 對不同分割槽的資料,按照key進行排序、分組。相同key的value放到一個集合中。
1.5 (可選)分組後的資料進行歸約。
2.reduce任務處理
2.1 對多個map任務的輸出,按照不同的分割槽,通過網路copy到不同的reduce節點。
2.2 對多個map任務的輸出進行合併、排序。寫reduce函式自己的邏輯,對輸入的key、value處理,轉換成新的key、value輸出。
2.3 把reduce的輸出儲存到檔案中。
例子:實現WordCountApp
map、reduce鍵值對格式

WordCountApp的驅動程式碼
public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); //載入配置檔案 Job job = new Job(conf); //建立一個job,供JobTracker使用 job.setJarByClass(WordCountApp.class); job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); FileInputFormat.setInputPaths(job, new Path("hdfs://192.168.1.10:9000/input")); FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.1.10:9000/output")); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.waitForCompletion(true); }
JobTracker
負責接收使用者提交的作業,負責啟動、跟蹤任務執行。
JobSubmissionProtocol是JobClient與JobTracker通訊的介面。
InterTrackerProtocol是TaskTracker與JobTracker通訊的介面。
TaskTracker
負責執行任務
JobClient
是使用者作業與JobTracker互動的主要介面。
負責提交作業的,負責啟動、跟蹤任務執行、訪問任務狀態和日誌等
最小的MapReduce驅動
Configuration configuration = new Configuration();
Job job = new Job(configuration, "HelloWorld");
job.setInputFormat(TextInputFormat.class);
job.setMapperClass(IdentityMapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setPartitionerClass(HashPartitioner.class);
job.setNumReduceTasks(1);
job.setReducerClass(IdentityReducer.class);
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(Text.class);
job.setOutputFormat(TextOutputFormat.class);
job.waitForCompletion(true);
MapReduce驅動預設的設定

序列化概念
序列化(Serialization)是指把結構化物件轉化為位元組流。
反序列化(Deserialization)是序列化的逆過程。即把位元組流轉回結構化物件。
Java序列化(java.io.Serializable
Hadoop序列化的特點
序列化格式特點:
- 緊湊:高效使用儲存空間。
- 快速:讀寫資料的額外開銷小
- 可擴充套件:可透明地讀取老格式的資料
互操作:支援多語言的互動
Hadoop的序列化格式:Writable
注意:Java序列化的不足:
1.不精簡。附加資訊多。不大適合隨機訪問。
2.儲存空間大。遞迴地輸出類的超類描述直到不再有超類。序列化圖物件,反序列化時為每個物件新建一個例項。相反。Writable物件可以重用。
3.擴充套件性差。而Writable方便使用者自定義
Hadoop序列化的作用
序列化在分散式環境的兩大作用:程序間通訊,永久儲存。
Hadoop節點間通訊。
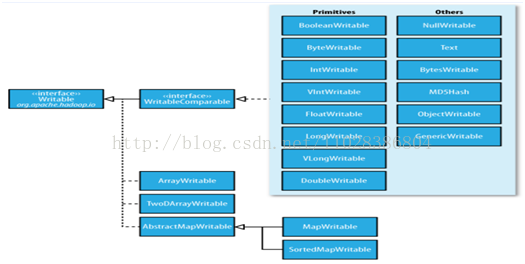
Writable介面
Writable介面, 是根據 DataInput和 DataOutput 實現的簡單、有效的序列化物件.
MR的任意Key和Value必須實現Writable介面.
MR的任意key必須實現WritableComparable介面
常用的Writable實現類
Text一般認為它等價於java.lang.String的Writable。針對UTF-8序列。
例:
Text test = new Text("test");
IntWritable one = new IntWritable(1);


Writable
① write 是把每個物件序列化到輸出流
② readFields是把輸入流位元組反序列化
③ 實現WritableComparable.
④ Java值物件的比較:一般需要重寫toString(),hashCode(),equals()方法
基於檔案的儲存結構
SequenceFile 無序儲存
MapFile 會對key建立索引檔案,value按key順序儲存
基於MapFile的結構有:
ArrayFile 像我們使用的陣列一樣,key值為序列化的數字
SetFile 他只有key,value為不可變的資料
BloomMapFile 在 MapFile 的基礎上增加了一個 /bloom檔案,包含的是二進位制的過濾表,在每一次寫操作完成時,會更新這個過濾表。
MapReduce的輸入處理類
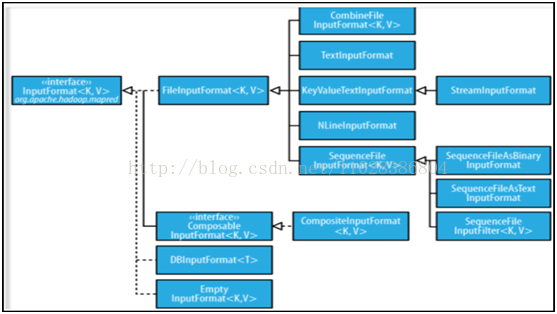
FileInputFormat:FileInputFormat是所有以檔案作為資料來源的InputFormat實現的基類,FileInputFormat儲存作為job輸入的所有檔案,並實現了對輸入檔案計算splits的方法。至於獲得記錄的方法是有不同的子類——TextInputFormat進行實現的。
InputFormat

InputFormat 負責處理MR的輸入部分.
有三個作用:
驗證作業的輸入是否規範.
把輸入檔案切分成InputSplit.
提供RecordReader 的實現類,把InputSplit讀到Mapper中進行處理
InputSplit
在執行mapreduce之前,原始資料被分割成若干split,每個split作為一個map任務的輸入,在map執行過程中split會被分解成一個個記錄(key-value對),map會依次處理每一個記錄。
FileInputFormat只劃分比HDFS block大的檔案,所以FileInputFormat劃分的結果是這個檔案或者是這個檔案中的一部分.
如果一個檔案的大小比block小,將不會被劃分,這也是Hadoop處理大檔案的效率要比處理很多小檔案的效率高的原因。
當Hadoop處理很多小檔案(檔案大小小於hdfs block大小)的時候,由於FileInputFormat不會對小檔案進行劃分,所以每一個小檔案都會被當做一個split並分配一個map任務,導致效率底下。
例如:一個1G的檔案,會被劃分成16個64MB的split,並分配16個map任務處理,而10000個100kb的檔案會被10000個map任務處理。
TextInputFormat
TextInputformat是預設的處理類,處理普通文字檔案。
檔案中每一行作為一個記錄,他將每一行在檔案中的起始偏移量作為key,每一行的內容作為value。
預設以\n或回車鍵作為一行記錄。
TextInputFormat繼承了FileInputFormat。InputFormat類的層次結構
其他輸入類
CombineFileInputFormat
相對於大量的小檔案來說,hadoop更合適處理少量的大檔案。
CombineFileInputFormat可以緩解這個問題,它是針對小檔案而設計的。
KeyValueTextInputFormat
當輸入資料的每一行是兩列,並用tab分離的形式的時候,KeyValueTextInputformat處理這種格式的檔案非常適合。
NLineInputformat
NLineInputformat可以控制在每個split中資料的行數。
SequenceFileInputformat
當輸入檔案格式是sequencefile的時候,要使用SequenceFileInputformat作為輸入
自定義輸入格式
1)繼承FileInputFormat基類。
2)重寫裡面的getSplits(JobContextcontext)方法。
3)重寫createRecordReader(InputSplitsplit, TaskAttemptContext context)方法。
Hadoop的輸出
TextOutputformat
預設的輸出格式,key和value中間值用tab隔開的。
SequenceFileOutputformat
將key和value以sequencefile格式輸出。
SequenceFileAsOutputFormat
將key和value以原始二進位制的格式輸出。
MapFileOutputFormat
將key和value寫入MapFile中。由於MapFile中的key是有序的,所以寫入的時候必須保證記錄是按key值順序寫入的。
MultipleOutputFormat
預設情況下一個reducer會產生一個輸出,但是有些時候我們想一個reducer產生多個輸出,MultipleOutputFormat和MultipleOutputs可以實現這個功能。相關推薦
Hadoop之——MapReduce實戰(一)
MapReduce概述 MapReduce是一種分散式計算模型,由Google提出,主要用於搜尋領域,解決海量資料的計算問題. MR由兩個階段組成:Map和Reduce,使用者只需要實現map()和reduce()兩個函式,即可實現分散式計算,非常簡單。
Hadoop之——MapReduce實戰(二)
MapReduce的老api寫法 import org.apache.hadoop.fs.Path; import org.apache.hadoop.mapred.FileInputFormat; import org.apache.hadoop.mapred.File
【原創】MapReduce實戰(一)
tid refs 讀取 sel instance 網站 let 創建 -c 應用場景: 用戶每天會在網站上產生各種各樣的行為,比如瀏覽網頁,下單等,這種行為會被網站記錄下來,形成用戶行為日誌,並存儲在hdfs上。格式如下: 17:03:35.012?pageview?{"d
React-Native 之 專案實戰(一)
前言 本文有配套視訊,可以酌情觀看。 文中內容因各人理解不同,可能會有所偏差,歡迎朋友們聯絡我。 文中所有內容僅供學習交流之用,不可用於商業用途,如因此引起的相關法律法規責任,與我無關。 如文中內容對您造成不便,煩請聯絡 [email prot
一步一步寫web之react實戰(一)
react系列文章建立在你已經熟悉javascript、html、css、less、webpack、react語法等的基礎上,這個熟悉是單個的教程都看過,但是沒有系統的把它們串聯起來。 下面開始我的嘗試之旅(注:此篇與下一篇為盲目探索篇,從(三)開始正式實踐)。 首先,假設
【Linux Nginx實戰】之初識Nginx(一)
Nginx LNMP 實戰 1.Nginx是什麽? nginx是一款高性能的HTTP和反向代理服務器軟件,第一個開源版本誕生於2004年,雖然誕生較晚但經過十多年的發展,已經成為非常流行的web服務器軟件,下圖是w3techs公布的全球網站服務器軟件統計報告 2.Nginx為什麽流行? 首先,ng
【SpringMVC】7.REST風格的CRUD實戰(一)之前期工作
一、什麼是REST和CRUD? 1.有關REST 有關REST的解釋我已近在之前的SpringMVC系列文章提到過,如果有興趣的同學可以翻看《【SpringMVC】3.REST表現層狀態轉換》進行檢視。 2.有關CRUD In comp
Spark修煉之道(進階篇)——Spark入門到精通:第十節 Spark SQL案例實戰(一)
作者:周志湖 放假了,終於能抽出時間更新部落格了……. 1. 獲取資料 本文通過將github上的Spark專案git日誌作為資料,對SparkSQL的內容進行詳細介紹 資料獲取命令如下: [[email protected] spa
Hadoop實戰(一) 在VMWare上搭建centos虛擬機器叢集
一、VMware的下載和安裝 下載VMware 安裝VMware:一路Next即可 二、centos的下載和安裝 下載centos 安裝三個centos 64位虛擬機器(master slave1 slave2) 在搭建Hadoop時,master將會作為namenod
kubernetes之監控Prometheus實戰(一)
Prometheus介紹 Prometheus是一個最初在SoundCloud上構建的開源監控系統 。它現在是一個獨立的開源專案,為了強調這一點,並說明專案的治理結構,Prometheus 於2016年加入CNCF,作為繼Kubernetes之後的第二個託管專案。 特點 具有由 metr
Python之Django商城專案實戰(一):搭建開發環境
一、搭建環境:1、安裝pythonsudo apt-get install python3-pip2、安裝mysql3、建立虛擬環境安裝虛擬環境:pip install virtualenv方法一:建立虛擬環境(python3.6):python -m venv myenv
SSM專案實戰(一)--- 高併發秒殺系統之DAO層
專案為慕課網上 搞定Java SSM框架開發的綜合案例–實現一個秒殺系統案例。 1.首先搭建專案 使用Maven構建來管理依賴項,pom.xml檔案: 此pom.xml可作為大多數ssm專案依賴的參考 <project xmlns="http:
Spark之路:(一)Scala + Spark + Hadoop環境搭建
一、Spark 介紹 Spark是基於記憶體計算的大資料分散式計算框架。Spark基於記憶體計算,提高了在大資料環境下資料處理的實時性,同時保證了高容錯性和高可伸縮性,允許使用者將Spark部署在大量廉價硬體之上,形成叢集。 1.提供分散式計算功能,將分散式
vue專案實戰(一)之vue-cli腳手架搭建專案
首先假如你已經安裝了node和npm,如果沒有的話自己百度安裝一下。 如果感覺npm下載速度慢,可以使用淘寶映象cnpm,連結地址: http://npm.taobao.org/ 安裝cnpm 方式一: npm install -g cnpm --registry
資料視覺化之matplotlib庫實戰(一)
本篇主要內容來自於唐宇迪-機器學習課程的資料視覺化章節,此文只做個人實操和理解用。 #折線圖的繪製 # -*- coding: utf-8 -*- import pandas as pd #首先還是照例匯入檔案 unrate = pd.read_csv(r'/
大資料開發之Hadoop工程師學習筆記(一)
第一課:實施Hadoop叢集;CDH家族1.Hadoop大資料:目前軟體和硬體無法處理的資料稱為大資料。Hadoop擅長離線資料分析,有時間差,難以做實時資料處理。檔案系統是半隻讀資料,不能修該,只能追加,隨機讀寫很麻煩。Hadoop不是資料庫,Hbase才是資料庫。兩大板塊
專案管理之敏捷開發-Scrum應用實戰(一)
最近開始研究敏捷開發,公司的專案管理有些混亂,效率不高,一直想著有沒有什麼改進的辦法,最後想到可以試試敏捷.昨天公司開會我提出了做一些改革的想法,希望公司開始慢慢推行敏捷來提高溝通效率,提升交付質量.領導層明確表示支援,但是可能沒有那麼快開始全面實行,而且公司現在基本上
Hadoop實戰(一),單詞計數(wordcount)
目的 通過特定Hadoop Demo實戰,瞭解、學習、掌握大資料框架日常使用及嘗試挑戰大資料研發過程中遇到的挑戰等。 場景描述 運用MapReduce 進行簡單的單詞計數統計。 實驗
Spring 事務配置實戰(一):過濾無需事務處理的查詢之類操作
log pla ssi pan spl tail gif aop img <tx:advice id="txAdvice" transaction-manager="transactionManager"> <tx:attributes
設計模式之問題集錦(一)
是把 後繼 ogr data- 跟著 沒有 解釋器 space 基本實現 設計模式的主要資料是《大話設計模式》。第一階段先看看各種模式的基本概念。實現每一個模式下的樣例。然後在進行理解性的學習和掌握,靈活掌握各種模式的長處,知道某種模式適合那種狀態。如今,樣