
spark RDD運算元 parallelize,makeRDD,textFile
- parallelize
將一個存在的集合,變成一個RDD。這種方式試用於學習spark和做一些spark的測試
- 第一個引數一是一個 Seq集合
- 第二個引數分割槽數
var array = List(1, 2, 3, 4, 5, 6, 7, 8) var rdd = sc.parallelize(array,3)
- makeRDD
只有scala版本的才有makeRDD ,跟parallelize類似。
var array = List(1, 2, 3, 4, 5, 6, 7, 8) var rdd = sc.makeRDD(array)
- textFile
從外部儲存中讀取資料來建立 RDD ,如讀取本地D:\log\system.log。
var lines = sc.textFile("file:\\D:\log\system.log")
相關推薦
spark RDD運算元 parallelize,makeRDD,textFile
- parallelize 將一個存在的集合,變成一個RDD。這種方式試用於學習spark和做一些spark的測試 第一個引數一是一個 Seq集合 第二個引數分割槽數 var array = List(1, 2, 3, 4, 5, 6, 7
spark RDD運算元(一) parallelize,makeRDD,textFile
作者: 翟開順 首發:CSDN parallelize 呼叫SparkContext 的 parallelize(),將一個存在的集合,變成一個RDD,這種方式試用於學習spark和做一些spark的測試 scala版本 def paral
spark RDD建立方式:parallelize,makeRDD,textFile
parallelize 呼叫SparkContext 的 parallelize(),將一個存在的集合,變成一個RDD,這種方式試用於學習spark和做一些spark的測試 scala版本 ? 1 def parallelize[T](s
第14課:spark RDD彈性表現和來源,容錯
hadoop 的MapReduce是基於資料集的,位置感知,容錯 負載均衡 基於資料集的處理:從物理儲存上載入資料,然後操作資料,然後寫入物理儲存裝置; 基於資料集的操作不適應的場景: 1,不適合於大量的迭代 2,互動式查詢
Spark-core運算元大全(java,scala,python)
/** * Java版本導包相關 */ import org.apache.spark.Partitioner; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD
spark RDD運算元大全
RDD作為spark核心的資料抽象,有關RDD的原始碼可看spark原始碼《一》RDD,有大量的api,也就是運算元 之前寫過兩篇運算元原始碼,一篇觸發runJob()的運算元,一篇是基於combineByKey()運算元的原始碼,有興趣的可以去看下。 目錄 map()&&
spark RDD運算元(二) filter,map ,flatMap
作者: 翟開順 首發:CSDN 先來一張spark快速大資料中的圖片進行快速入門,後面有更詳細的例子 filter 舉例,在F:\sparktest\sample.txt 檔案的內容如下 aa bb cc aa aa aa dd
spark RDD運算元(十一)之RDD Action 儲存操作saveAsTextFile,saveAsSequenceFile,saveAsObjectFile,saveAsHadoopFile 等
關鍵字:Spark運算元、Spark函式、Spark RDD行動Action、Spark RDD儲存操作、saveAsTextFile、saveAsSequenceFile、saveAsObjectFile,saveAsHadoopFile、saveAsHa
Spark RDD運算元介紹
Spark學習筆記總結 01. Spark基礎 1. 介紹 Spark可以用於批處理、互動式查詢(Spark SQL)、實時流處理(Spark Streaming)、機器學習(Spark MLlib)和圖計算(GraphX)。 Spark是MapReduce的替代方案,而且
Spark-RDD運算元
一、Spark-RDD運算元簡介 RDD(Resilient Distributed DataSet)是分散式資料集。RDD是Spark最基本的資料的抽象。 scala中的集合。RDD相當於一個不可變、可分割槽、裡面的元素可以平行計算的集合。 RDD特點: 具
spark RDD運算元(四)之建立鍵值對RDD mapToPair flatMapToPair
mapToPair 舉例,在F:\sparktest\sample.txt 檔案的內容如下 aa bb cc aa aa aa dd dd ee ee ee ee ff aa bb zks ee kks ee zz zks 將每一行的第一個單詞
Spark RDD運算元【四】
自己總結了常用的部分運算元,方便自己理解和查閱 Spark RDD運算元列表 1. collectAsMap 2.count,countByKey,countByValue 3. filter,fi
spark RDD運算元(十)之PairRDD的Action操作countByKey, collectAsMap
countByKey def countByKey(): Map[K, Long] 以RDD{(1, 2),(2,4),(2,5), (3, 4),(3,5), (3, 6)}為例 rdd.cou
Spark效能調優-RDD運算元調優篇(深度好文,面試常問,建議收藏)
## RDD運算元調優 不廢話,直接進入正題! #### 1. RDD複用 在對RDD進行運算元時,要避免相同的運算元和計算邏輯之下對RDD進行重複的計算,如下圖所示: 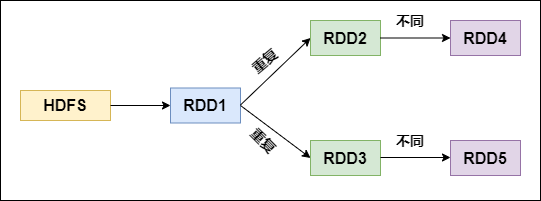
RDD的緩存,依賴,spark提交任務流程
持久化 存儲 技術分享 alt 重要 depend 任務 cache 但是 1.RDD的緩存 Spark速度非常快的原因之一,就是在不同操作中可以在內存中持久化或緩存個數據集。當持久化某個RDD後,每一個節點都將把計算的分片結果保存在內存中,並在對此RDD或衍生出的RDD進
spark RDD,DataFrame,DataSet 介紹
列式存儲 ren gre rds 包含 執行 這一 ces 中一 彈性分布式數據集(Resilient Distributed Dataset,RDD) RDD是Spark一開始就提供的主要API,從根本上來說,一個RDD就是你的數據的一個不可變的分布式元素集
大資料之Spark(四)--- Dependency依賴,啟動模式,shuffle,RDD持久化,變數傳遞,共享變數,分散式計算PI的值
一、Dependency:依賴:RDD分割槽之間的依存關係 --------------------------------------------------------- 1.NarrowDependency: 子RDD的每個分割槽依賴於父RDD的少量分割槽。 |
spark中RDD,DataSet,DataFrame的區別
接觸到spark不可避免的會接觸spark的Api; rdd,DataFrame,DataSet, 接下來就大致說一下他們的有點以及各自的區別; 首先DataFrame,Data
spark RDD,reduceByKey vs groupByKey
Spark 中有兩個類似的api,分別是 reduceByKey 和 groupByKey 。這兩個的功能類似,但底層實現卻有些不同,那麼為什麼要這樣設計呢?我們來從原始碼的角度分析一下。 先看兩者的呼叫順序(都是使用預設的Partitioner,即defaultPartitioner) 所用 spark 版
Spark rdd 介紹,和案例介紹
1.2、建立RDD 1)由一個已經存在的Scala集合建立。 val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8)) 2)由外部儲存系統的資料集建立,包括本地的檔案系統,還有所有Hadoop支援的資料集,比如HD