
mysql 索引的使用之中文全文索引
這裡討論的是 mysql 5.7 InnoDB 全文索引,在mysql 5.6 之前的版本中,myisam 支援全文索引而InnoDB 是不支援的,而且 mysql 全文索引對中文的支援也不太友好,所以一般採用其它方案去替代。一般的替代方案是 sphinx 或者 elasticSearch 。
在mysql 索引使用篇(https://blog.csdn.net/zhang_referee/article/details/83215770) 中說過,類似於 columnName like '%keywords%' 的模糊匹配是很慢的,而且又無法使用到索引。在專案中一般採用其它方案去替代(我之前使用的是elasticSeaarch) 。
先看一下,這裡的案例表,索引情況:
mysql> show index from dye_production_schedules; +--------------------------+------------+--------------------------+--------------+---------------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | +--------------------------+------------+--------------------------+--------------+---------------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | dye_production_schedules | 0 | PRIMARY | 1 | id | A | 1708677 | NULL | NULL | | BTREE | | | | dye_production_schedules | 1 | order_id_order_detail_id | 1 | order_id | A | 9115 | NULL | NULL | | BTREE | | | | dye_production_schedules | 1 | order_id_order_detail_id | 2 | order_detail_id | A | 1831978 | NULL | NULL | | BTREE | | | | dye_production_schedules | 1 | dye_factory_id | 1 | dye_factory_id | A | 14141 | NULL | NULL | | BTREE | | | | dye_production_schedules | 1 | dye_code | 1 | dye_code | A | 1831978 | NULL | NULL | | BTREE | | | | dye_production_schedules | 1 | order_detail_id | 1 | order_detail_id | A | 95830 | NULL | NULL | | BTREE | | | | dye_production_schedules | 1 | order_id_batch_num | 1 | order_id | A | 10781 | NULL | NULL | | BTREE | | | | dye_production_schedules | 1 | order_id_batch_num | 2 | batch_num | A | 1831978 | NULL | NULL | | BTREE | | | | dye_production_schedules | 1 | customer_color_name | 1 | customer_color_name | NULL | 1831978 | NULL | NULL | | FULLTEXT | | | +--------------------------+------------+--------------------------+--------------+---------------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ 9 rows in set (0.02 sec)
可以看到在 custormer_color_name 列上建立了全文索引。不過這裡有個坑,後面會說到。
如果看過我之前的 mysql 索引基礎篇的文章(https://blog.csdn.net/zhang_referee/article/details/83045903) 就會發現,我在建全文索引的時候埋了個大坑——天真的以為建立了全文索引就能支援中文。結果在寫這篇文章的時候,發現explain 分析說使用到了全文索引,但在具體查詢某個中文關鍵詞的時候,查詢結果出人意外——檢索不到想要的資料。後來查資料才知,原來要使用中文全文索引,需要手動指定ngram全文分析器。可以在建立或修改時使用指定 WITH PARSER ngram。
我這裡修改執行一下,以下語句即可:
mysql> alter table dye_production_schedules add fulltext(`customer_color_name`) with parser ngram;
Query OK, 0 rows affected (12 min 39.63 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show create table dye_production_schedules;

ok ,下面就來體驗一把強大的 ngram 。在示例表資料中`customer_color_name`列上搜索 '纏綿悱惻' :
mysql> select id,dye_code,customer_color_name from dye_production_schedules where match(`customer_color_name`) against('纏綿悱惻') limit 10;
+------+----------------+-----------------------------------------------------------------------------------------------------------+
| id | dye_code | customer_color_name |
+------+----------------+-----------------------------------------------------------------------------------------------------------+
| 873 | 069d837c01a1ad | pjvwylu5K4到福州一次,有一篇《將離》抒寫那回的別恨,是纏綿悱惻的文字。m2BbW |
| 962 | 6fbc2b2e505359 | Mv4mJp27tP朋友拉到福州一次,有一篇《將離》抒寫那回的別恨,是纏綿悱惻的0UnbO |
| 1856 | 0b28e88b7d8aed | c7Enqd3xNZ》抒寫那回的別恨,是纏綿悱惻的文字。這些日子,我在浙江亂跑,pI8fH |
| 3851 | 72b085dd124bf6 | WEXKPAUkb6恨,是纏綿悱惻的文字。這些日子,我在浙江亂跑,有時到上海小住2DwSv |
| 4004 | 71cd2b3a7aa06c | Wt79irOzTC友拉到福州一次,有一篇《將離》抒寫那回的別恨,是纏綿悱惻的文HGAjU |
| 5556 | 8fdef9d7df4774 | MXI3te2VPp《將離》抒寫那回的別恨,是纏綿悱惻的文字。這些日子,我在浙江DvlKS |
| 5945 | 09c7ec5af6b589 | rSgWeb5qa8次,有一篇《將離》抒寫那回的別恨,是纏綿悱惻的文字。這些日子NO9yX |
| 6258 | ee292e96585a49 | tE8GlNjvDe寫那回的別恨,是纏綿悱惻的文字。這些日子,我在浙江亂跑,有時Xsk96 |
| 6548 | 18c869d0bcd38c | XbetqKvrQL回的別恨,是纏綿悱惻的文字。這些日子,我在浙江亂跑,有時到上a9HoY |
| 6741 | 7dade53c7f5001 | 49uHlA3mdh《將離》抒寫那回的別恨,是纏綿悱惻的文字。這些日子,我在浙江UVkwS |
+------+----------------+-----------------------------------------------------------------------------------------------------------+
10 rows in set (0.02 sec)
mysql> explain select id,dye_code,customer_color_name from dye_production_schedules where match(`customer_color_name`) against('纏綿悱惻') limit 10 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: dye_production_schedules
partitions: NULL
type: fulltext
possible_keys: customer_color_name
key: customer_color_name
key_len: 0
ref: const
rows: 1
filtered: 100.00
Extra: Using where; Ft_hints: sorted, limit = 10
1 row in set, 1 warning (0.02 sec)
MySQL內建的全文解析器使用單詞之間的空格作為分隔符來確定單詞的開始和結束位置,但不適用於中文等語言。為了解決這個問題,MySQL提供了一個支援中文,日文和韓文(CJK)的 ngram 全文解析器。ngram全文解析器支援InnoDB和 MyISAM。
MySQL 5.7.6中引入的ngram全文解析器是一個內建的伺服器外掛。與其他內建伺服器外掛一樣,它在伺服器啟動時自動載入。
全文索引相關的配置選項中,除了最小和最大字長選項(innodb_ft_min_token_size, innodb_ft_max_token_size, ft_min_word_len, ft_max_word_len),其它同樣適用於ngram。
mysql> select @@innodb_ft_min_token_size;
+----------------------------+
| @@innodb_ft_min_token_size |
+----------------------------+
| 3 |
+----------------------------+
1 row in set (0.00 sec)
mysql> select @@innodb_ft_max_token_size;
+----------------------------+
| @@innodb_ft_max_token_size |
+----------------------------+
| 84 |
+----------------------------+
1 row in set (0.00 sec)
mysql> select @@ft_min_word_len;
+-------------------+
| @@ft_min_word_len |
+-------------------+
| 4 |
+-------------------+
1 row in set (0.00 sec)
mysql> select @@ft_max_word_len;
+-------------------+
| @@ft_max_word_len |
+-------------------+
| 84 |
+-------------------+
1 row in set (0.00 sec)
mysql> select @@ngram_token_size;
+--------------------+
| @@ngram_token_size |
+--------------------+
| 2 |
+--------------------+
1 row in set (0.00 sec)
可見系統預設分詞大小為3,而ngram 預設分詞大小為2。
還可以使用show_variables like '%ngram%' 來檢視其它ngram 相關的系統變數。

ngram解析器的預設ngram標記大小為2。例如,分詞大小為2時,ngram解析器將字串"纏綿悱惻"解析為: 纏綿,綿悱,悱惻。可以使用ngram_token_size 來配置分詞大小,最小值為1,最大值為10。通常,ngram_token_size設定為要搜尋的最大分詞的大小,如果你想查詢到單個字,那麼我們需要設定為1。 ngram_token_size的值設定的越小,全文索引佔用的空間也越小。一般來說,查詢正好等於ngram_token_size的詞,速度會更快,但是查詢比它更長的詞或短語,則會變慢。
ngram分析器停用詞處理
內建的MySQL全文解析器將單詞與禁用詞列表中的條目進行比較。如果單詞等於禁用詞列表中的條目,則該單詞將從索引中排除。對於ngram解析器,以不同方式執行停用詞處理。ngram解析器排除包含停用詞的符號,而不是排除與禁用詞列表中的條目相等的符號。例如,假設 ngram_token_size=2包含“ a,b ”的文件被解析為“ a ” 和“ ,b ”。如果逗號(“ , ”)被定義為停用詞,則兩者都是“ a ”和“ ,b ”從索引中排除,因為它們包含逗號。預設情況下,ngram解析器使用預設的停用詞列表,其中包含英語停用詞列表。對於適用於中文,日文或韓文的禁用詞列表,必須由我們自己建立(這裡大部分來自於mysql英文官方手冊翻譯)。
看到這裡後,我就在想,中文也有很多無意義的詞,比如說"的",然後就實驗了一把。
mysql> select sql_no_cache id,dye_code,customer_color_name from dye_production_schedules where `customer_color_name` like '%北平%' limit 10;
+-----+----------------+-----------------------------------------------------------------------------------------------------------+
| id | dye_code | customer_color_name |
+-----+----------------+-----------------------------------------------------------------------------------------------------------+
| 11 | d30049b79b5edd | icOjVlwSoB他那時途中思家的小詩,重唸了兩遍,覺得怪有意思。北平回去不久92UdZ |
| 157 | 8668a352ea2f99 | fJrhb2RCz8生半日閒”那一句詩了。我說北平看花,比別處有意思,也正在此。cKdWk |
| 341 | 93d4f53f9599a1 | VJqw1XZmRN呢。北平看花的事很盛,看花的地方也很多;但那時熱鬧的似乎也只HK6hE |
| 403 | 38ce4915d6fd95 | A3vGXUznk1,無論如何不回來了。但他卻到北平住了半年,也是朋友拉去的。我tqSx9 |
| 453 | f3b52affbb1a5e | V3xEk4Py9o逃不了的。我說北平看花,比別處有意思,也正在此。這時候,我似SsYgq |
| 457 | fe70909ea64144 | PlwxnqtGZf住了不過一年,我卻傳染了他那愛花的嗜好。但重到北平時,住在花FmKsU |
| 507 | 1f1d257e0459e9 | HBnSkUtFx4。但到北平讀了幾年書,卻只到過崇效寺一次;而去得又嫌早些,那Cr3yK |
| 513 | cd23e33736db2c | BpFSEtnW5N了他那愛花的嗜好。但重到北平時,住在花事很盛的清華園裡,接連LhCoq |
| 558 | 7c800747d7fd7c | ivrH6WkfbI算是有水;北平的三海和頤和園雖然有點兒水,但太平衍了,一覽而2YNy0 |
| 570 | 9acf048b31f126 | OqjIiCJyUE了不過一年,我卻傳染了他那愛花的嗜好。但重到北平時,住在花事4BY5R |
+-----+----------------+-----------------------------------------------------------------------------------------------------------+
10 rows in set, 1 warning (0.02 sec)
mysql> explain select sql_no_cache id,dye_code,customer_color_name from dye_production_schedules where `customer_color_name` like '%北平%' limit 10;
+----+-------------+--------------------------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------------------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | dye_production_schedules | NULL | ALL | NULL | NULL | NULL | NULL | 1831978 | 11.11 | Using where |
+----+-------------+--------------------------+------------+------+---------------+------+---------+------+---------+----------+-------------+
1 row in set, 2 warnings (0.00 sec)
mysql> explain select id,dye_code,customer_color_name from dye_production_schedules where match(`customer_color_name`) against('的');
+----+-------------+--------------------------+------------+----------+---------------------+---------------------+---------+-------+------+----------+-------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------------------+------------+----------+---------------------+---------------------+---------+-------+------+----------+-------------------------------+
| 1 | SIMPLE | dye_production_schedules | NULL | fulltext | customer_color_name | customer_color_name | 0 | const | 1 | 100.00 | Using where; Ft_hints: sorted |
+----+-------------+--------------------------+------------+----------+---------------------+---------------------+---------+-------+------+----------+-------------------------------+
1 row in set, 1 warning (0.00 sec)
mysql> select id,dye_code,customer_color_name from dye_production_schedules where match(`customer_color_name`) against('的');
Empty set (0.05 sec)
在上面的栗子中,可以看到,會自動的把"的"這種無用詞給過濾掉,所以我們單搜"的"是沒有匹配結果的。
這裡提下,ngram_token_size 是隻讀變數,

以上截圖自mysql 官方手冊。
這裡說下第二種修改方法,mysql配置檔案預設(my.cnf)是沒有ngram_token_size這個配置項的,需要自己新增,記得重啟mysql.

通過將ngram_token_size 這個選項設定為1後發現,上面的查詢結果為空。
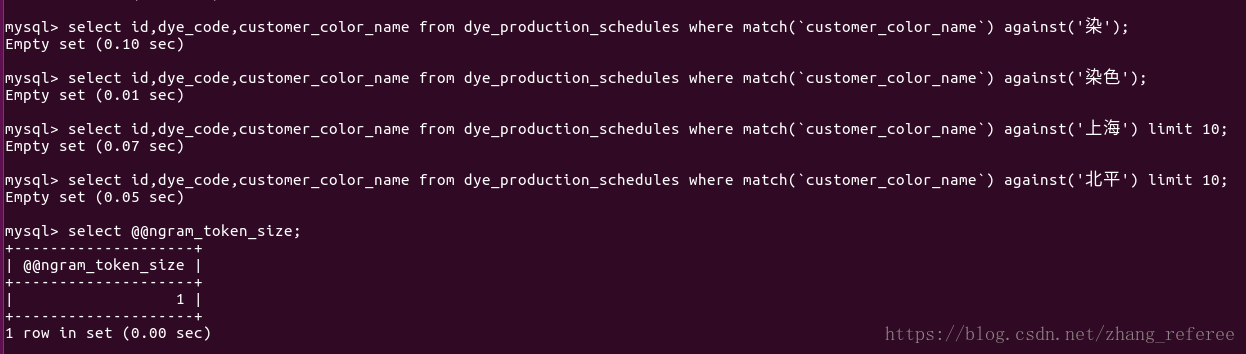
目測是改ngram_token_size 值是在索引建立後所致。可以建一個表測驗一番:
mysql> create table ngram_token_test(
->
-> id int auto_increment,
-> `content` varchar(128) not null default '',
-> primary key(id),
-> fulltext index `content` (`content`) with parser ngram
->
-> )engine = innodb default charset = utf8;
Query OK, 0 rows affected (2.62 sec)
mysql> insert into ngram_token_test(`content`) values
-> ('染色'),
-> ('上海'),
-> ('海山生明月'),
-> ('今夕何夕兮搴洲中流'),
-> ('今日何日兮得與王子同舟'),
-> ('蒙羞被好兮不訾詬恥'),
-> ('心幾煩而不絕兮得知王子'),
-> ('山有木兮木有枝'),
-> ('心悅君兮君不知'),
-> ('小木兮子');
Query OK, 10 rows affected (0.16 sec)
Records: 10 Duplicates: 0 Warnings: 0
mysql> select @@ngram_token_size;
+--------------------+
| @@ngram_token_size |
+--------------------+
| 1 |
+--------------------+
1 row in set (0.00 sec)
mysql> select * from ngram_token_test where match(`content`) against('海');
+----+-----------------+
| id | content |
+----+-----------------+
| 2 | 上海 |
| 3 | 海山生明月 |
+----+-----------------+
2 rows in set (0.00 sec)
mysql> select * from ngram_token_test where match(`content`) against('小');
+----+--------------+
| id | content |
+----+--------------+
| 10 | 小木兮子 |
+----+--------------+
1 row in set (0.01 sec)
ok ,果然如猜想那樣,如果使用ngram 分詞器,修改了 ngram_token_size 這個值後,修改前建立的相關索引需要重建(忽然明白了,為什麼是隻讀變量了)。
OK,然後改回原來的值。

ngram 解析器查詢處理
先建立一個示例表:
mysql> create table articles(
->
-> id int auto_increment,
-> `content` varchar(256) not null default '',
-> primary key(id),
-> fulltext index `content` (`content`) WITH PARSER NGRAM
->
-> )engine = innoDB default charset = utf8;
Query OK, 0 rows affected (3.12 sec)
mysql> insert into articles(`content`) values
-> ('計算機資訊系統'),
-> ('資料庫管理系統'),
-> ('資訊的系統'),
-> ('息系'),
-> ('管理系統開發與維護'),
-> ('資訊系統'),
-> ('作業系統'),
-> ('作系'),
-> ('系統'),
-> ('mysql 管理從入門到放棄'),
-> ('mysql 管理和維護'),
-> ('筆記本維修'),
-> ('linux 系統維護'),
-> ('管理員的日常'),
-> ('資訊挖掘與分析');
Query OK, 15 rows affected (0.12 sec)
Records: 15 Duplicates: 0 Warnings: 0
ngram Parser Term Search
對於自然語言模式搜尋,搜尋項將轉換為ngram項的並集。例如,字串“ abc ”(假設 ngram_token_size=2)被轉換為“ ab bc ”。給定兩個文件,一個包含“ ab ”而另一個包含 “ abc ”,搜尋詞“ ab bc ”匹配兩個文件。
對於布林模式搜尋,搜尋項將轉換為ngram短語搜尋。例如,字串'abc'(假設 ngram_token_size=2)將轉換為' “ ab bc ” '。給定兩個文件,一個包含'ab'而另一個包含'abc',搜尋短語' “ ab bc ” '僅匹配包含'abc'的文件。
自然語言模式:
mysql> select * from articles where match(`content`) against('資訊系統' IN NATURAL LANGUAGE MODE);
+----+-----------------------------+
| id | content |
+----+-----------------------------+
| 1 | 計算機資訊系統 |
| 6 | 資訊系統 |
| 4 | 息系 |
| 3 | 資訊的系統 |
| 15 | 資訊挖掘與分析 |
| 2 | 資料庫管理系統 |
| 5 | 管理系統開發與維護 |
| 7 | 作業系統 |
| 9 | 系統 |
| 13 | linux 系統維護 |
+----+-----------------------------+
10 rows in set (0.00 sec)

布林模式:
mysql> select * from articles where match(`content`) against('資訊系統' IN BOOLEAN MODE);
+----+-----------------------+
| id | content |
+----+-----------------------+
| 1 | 計算機資訊系統 |
| 6 | 資訊系統 |
+----+-----------------------+
2 rows in set (0.00 sec)
ngram Parser萬用字元搜尋
如果萬用字元搜尋的字首符號小於ngram分詞大小,則查詢將返回包含以該符號開頭的ngram的所有索引行。例如,假設 ngram_token_size=2搜尋“ a * ”將返回以“ a ”開頭的所有行 。
如果萬用字元搜尋的字首符號大於等於ngram分詞大小,則該查詢將轉換為ngram短語,並忽略萬用字元運算子。例如,假定 ngram_token_size=2,一個 “ ABC * ”萬用字元搜尋被轉換為 “ AB BC ”。
mysql> select * from articles where match(`content`) against('信*' IN BOOLEAN MODE);
+----+-----------------------+
| id | content |
+----+-----------------------+
| 1 | 計算機資訊系統 |
| 3 | 資訊的系統 |
| 6 | 資訊系統 |
| 15 | 資訊挖掘與分析 |
+----+-----------------------+
4 rows in set (0.00 sec)
mysql> select * from articles where match(`content`) against('資訊系*' IN BOOLEAN MODE);
+----+-----------------------+
| id | content |
+----+-----------------------+
| 1 | 計算機資訊系統 |
| 6 | 資訊系統 |
+----+-----------------------+
2 rows in set (0.01 sec)
ngram Parser短語搜尋
短語搜尋轉換為ngram短語搜尋。例如,搜尋短語“ abc ”被轉換為 “ ab bc ”,其返回包含“ abc ”和“ ab bc ”的文件 。
搜尋短語“ abc def ”被轉換為 “ ab bc de ef ”,其返回包含“ abc def ”和“ ab bc de ef ”的文件 。不返回包含“ abcdef ”的文件。
mysql> insert into articles(`content`) values
-> ('管理--新增'),
-> ('理維'),
-> ('維護'),
-> ('管理維護');
Query OK, 4 rows affected (0.10 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> select * from articles where match(`content`) against('管理維護' IN BOOLEAN MODE);
+----+--------------+
| id | content |
+----+--------------+
| 19 | 管理維護 |
+----+--------------+
1 row in set (0.00 sec)
mysql> select * from articles where match(`content`) against('管理的維護' IN BOOLEAN MODE);
Empty set (0.00 sec)
mysql> select * from articles where match(`content`) against('管理 維護 ' IN BOOLEAN MODE);
+----+--------------------------------+
| id | content |
+----+--------------------------------+
| 5 | 管理系統開發與維護 |
| 11 | mysql 管理和維護 |
| 19 | 管理維護 |
| 13 | linux 系統維護 |
| 18 | 維護 |
| 2 | 資料庫管理系統 |
| 10 | mysql 管理從入門到放棄 |
| 14 | 管理員的日常 |
| 16 | 管理--新增 |
+----+--------------------------------+
9 rows in set (0.00 sec)
由於官方文件全為英文,加之本人英文水平有限,有些感覺不好翻譯的地方直接上了英文,與其瞎翻譯誤導人,不如保持原汁原味。
本文參考自:
mysql 官方手冊 : https://dev.mysql.com/doc/refman/5.7/en/fulltext-search-ngram.html
這裡推薦這篇文章:http://www.cnblogs.com/zhoujinyi/p/5643408.html ,在寫到後半部分的時候,有參考到,感覺寫的很不錯。