
如何在CentOS7下部署Hadoop
阿新 • • 發佈:2018-11-02
1.前言
“大雲物移”是當年很火熱的一個話題,分別指大資料、雲端計算、物聯網和移動網際網路,其中大資料領域談論得多就是Hadoop。當然Hadoop不代表大資料,而是大資料處理領域的一個比較有名的開源框架而已,通常說的大資料包含了大資料的存放、大資料的分析處理及大資料的查詢展示,本篇提到的Hadoop只不過是在其中的大資料的分析處理環節起作用,Apache提供了一個開源全家桶,包括了Hadoop、HBase、Zookeeper、Spark、Hive及Pig等一些框架。不過限於篇幅,本篇只介紹Hadoop的偽分散式部署,包括MapReduce和HDFS。
2.準備
JDK檔案:jdk-8u131-linux-x64.tar.gz
官方下載地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Hadoop檔案:hadoop-2.9.0.tar.gz
官方下載地址:http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.9.0/hadoop-2.9.0.tar.gz
3.安裝
3.1安裝Oracle JDK
3.1.1解除安裝Open JDK
雖然Open JDK是JDK的開源實現,不過個人還是比較喜歡Oracle JDK,可能覺得它出身更正統一些吧。因此首先檢查伺服器上是否安裝了Open JDK,執行命令:
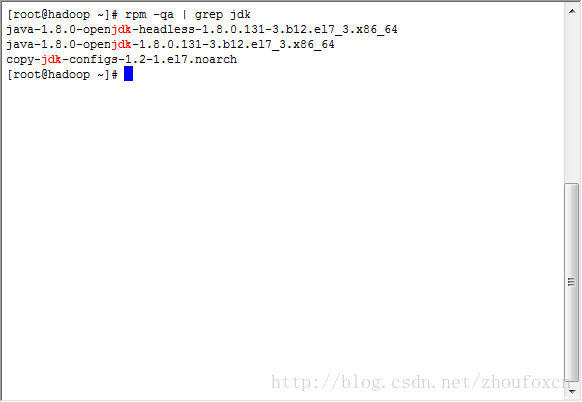
rpm -qa | grep jdk
如果伺服器已經安裝了Open JDK,採用下面的方式解除安裝掉Open JDK,如下圖所示:
3.1.2安裝Oracle JDK
可能有些人對Oracle JDK感覺到有點彆扭,至少本人就是如此,當年Sun公司推出了Java但由於經營不善被Oracle收購,所以以前經常說的Sun JDK現在改口稱Oracle JDK了。將前文提及的JDK安裝包下載至/root目錄下。
按照下面的方式來安裝:
cd /root
tar -zxf /root/jdk-8u131-linux-x64.tar.gz -C /usr/local
這樣一來JDK就安裝在/usr/local/jdk1.8.0_131目錄下了。
下面就對環境變數進行設定,因為在Linux中存在著互動式shell和非互動式shell,互動式shell顧名思義就是在與使用者的互動過程中執行的shell,通常是通過SSH登入到Linux系統之後輸入shell指令碼或命令等待使用者輸入或者確認然後執行的shell,而非互動式shell則是無需使用者干預的shell,如一些service的啟動等。互動式shell從/etc/profile中讀取所有使用者的環境變數設定,非互動式shell則從/etc/bashrc中讀取所有使用者的環境變數設定。因此可能會出現在互動式環境下執行shell指令碼沒有問題,在非互動式環境下執行shell指令碼則會出現找不到環境變數配置資訊的問題。
為保險起見,我們在/etc/profile和/etc/bashrc都配置Java相關的環境變數,將新增的內容放在原檔案的末尾,新增的內容如下:
export JAVA_HOME=/usr/local/jdk1.8.0_131
export JRE_HOME=/usr/local/jdk1.8.0_131
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
可以通過tail檢視修改後的檔案:
[[email protected] ~]# tail /etc/profile -n 5
export JAVA_HOME=/usr/local/jdk1.8.0_131
export JRE_HOME=/usr/local/jdk1.8.0_131
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
[[email protected] ~]# tail /etc/bashrc -n 5
export JAVA_HOME=/usr/local/jdk1.8.0_131
export JRE_HOME=/usr/local/jdk1.8.0_131
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
[[email protected] ~]# source /etc/profile
[[email protected] ~]# source /etc/bashrc
[[email protected] ~]# java -version
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
[[email protected] ~]#
注意,要想讓我們的配置馬上生效,應該執行source /etc/profile和source /etc/bashrc來立即讀取更新後的配置資訊。
3.2安裝Hadoop
將前文提及的Hadoop安裝包下載至/root目錄下。
通過如下命名安裝Hadoop:
[[email protected] ~]# cd /root
[[email protected] ~]# tar -zxf /root/hadoop-2.9.0.tar.gz -C /usr/local
這樣一來,Hadoop2.9.0就安裝在/usr/local/hadoop-2.9.0目錄下,我們可以通過如下命令檢視一下:
[[email protected] ~]# /usr/local/hadoop-2.9.0/bin/hadoop version
Hadoop 2.9.0
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 756ebc8394e473ac25feac05fa493f6d612e6c50
Compiled by arsuresh on 2017-11-13T23:15Z
Compiled with protoc 2.5.0
From source with checksum 0a76a9a32a5257331741f8d5932f183
This command was run using /usr/local/hadoop-2.9.0/share/hadoop/common/hadoop-common-2.9.0.jar
[[email protected] ~]#
畢竟每次執行hadoop的時候帶著這麼一長串命令不是很方便,尤其是需要手動輸入的時候,我們依然可以借鑑配置JAVA環境引數的方式將Hadoop相關的環境引數配置到環境變數配置檔案source /etc/profile和source /etc/bashrc中,在兩個檔案的末尾分別增加如下配置:
export HADOOP_HOME=/usr/local/hadoop-2.9.0
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
新增完內容儲存,最後別忘了執行如下命令重新整理環境變數資訊:
[[email protected] ~]# source /etc/profile
[[email protected] ~]# source /etc/bashrc
這時候再執行hadoop的相關命令就無需帶路徑資訊了,如下:
[[email protected] ~]# hadoop version
Hadoop 2.9.0
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 756ebc8394e473ac25feac05fa493f6d612e6c50
Compiled by arsuresh on 2017-11-13T23:15Z
Compiled with protoc 2.5.0
From source with checksum 0a76a9a32a5257331741f8d5932f183
This command was run using /usr/local/hadoop-2.9.0/share/hadoop/common/hadoop-common-2.9.0.jar
4.配置
4.1使用者配置
為便於管理和維護,我們單獨建立一個系統賬戶用來執行hadoop有關的指令碼和任務,這個系統賬戶名為hadoop,通過以下指令碼建立:
useradd hadoop -s /bin/bash –m
上面的命令建立了名為hadoop的使用者和使用者組,並且nginx使用者無法登入系統(-s /sbin/nologin限制),可以通過id命令檢視:
[[email protected] ~]# id hadoop
uid=1001(hadoop) gid=1001(hadoop) groups=1001(hadoop)
通過上面的命令建立的使用者是沒有密碼的,需要用passwd來設定密碼:
[[email protected] ~]# passwd hadoop
Changing password for user hadoop.
New password:
BAD PASSWORD: The password is shorter than 8 characters
Retype new password:
passwd: all authentication tokens updated successfully.
因為有時候需要hadoop這個使用者執行一些高許可權的命令,因此給予它sudo的許可權,開啟/etc/sudoers檔案,找到“root ALL=(ALL) ALL”那一行,在下面新增一行:
hadoop ALL=(ALL) ALL
然後儲存檔案(記住如果是用vim等編輯器編輯,最終儲存的時候要使用”:wq!”命令來強制儲存到這個只讀檔案)。修改的結果如下圖所示:

4.2免登入配置
雖然在本篇講述的是Hadoop的偽分散式部署,但是中間還有一些分散式的操作,這就要求能夠用ssh來登入,注意這裡的ssh不是Java裡面的SSH(Servlet+Spring+Hibernate),這裡講的SSH是Secure Shell 的縮寫,是用於Linux伺服器之間遠端登入的服務協議。
如果當前是用root使用者登入,那麼就要切換為hadoop使用者:
[[email protected] hadoop]# su hadoop
[[email protected] ~]$ cd ~
[[email protected] ~]$ pwd
/home/hadoop
可以看出hadoop使用者的工作路徑為/home/hadoop,然後我們用ssh登入本機,第一次登入的時候會提示是否繼續登入,然後輸入”yes”,接著會提示我們輸入當前用於ssh登入的使用者(這裡是hadoop)的在對應伺服器上的密碼(這裡是localhost),輸入正確密碼後就可以登入,然後在輸入”exit”退出登入,如下所示:
[[email protected] ~]$ ssh localhost
[email protected]'s password:
Last login: Sat Dec 2 11:48:52 2017 from localhost
[[email protected] ~]$ rm -rf /home/hadoop/.ssh
[[email protected] ~]$ ssh localhost
The authenticity of host 'localhost (::1)' can't be established.
ECDSA key fingerprint is aa:21:ce:7a:b2:06:3e:ff:3f:3e:cc:dd:40:38:64:9d.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
[email protected]'s password:
Last login: Sat Dec 2 11:49:58 2017 from localhost
[[email protected] ~]$ exit
logout
Connection to localhost closed.
經過上述操作後,建立了這個目錄/home/hadoop/.ssh和該目錄下的known_hosts檔案。
這樣每次登入都會提示輸入密碼,但在Hadoop執行過程中會通過shell無互動的形式在遠端伺服器上執行命令,因此需要設定成免密碼登入才行。我們需要通過通過如下命令建立金鑰檔案(一路回車即可):
[[email protected] ~]$ cd /home/hadoop/.ssh/
[[email protected] .ssh]$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa.
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.
The key fingerprint is:
19:b3:11:a5:6b:a3:26:03:c9:b9:b3:b8:02:ea:c9:25 [email protected]
The key's randomart image is:
+--[ RSA 2048]----+
| ... |
| o |
| = |
| . o B |
| = S |
|. o o . |
|oEo.o o |
|+.+o + |
|==. |
+-----------------+
然後將金鑰檔案的內容新增到authorized_keys檔案,同時授予600的許可權。
[[email protected] .ssh]$ cat id_rsa.pub >> authorized_keys
[[email protected] .ssh]$ chmod 600 authorized_keys
這時,再使用ssh localhost命令就不需要輸入密碼了,如下:
[[email protected] .ssh]$ ssh localhost
Last login: Sat Dec 2 11:50:44 2017 from localhost
[[email protected] ~]$ exit
logout
Connection to localhost closed.
注意:在本系列的第9篇關於git使用者免密碼登入時也講到了類似的操作,而且當時也講了git檔案傳輸也是使用ssh協議的。
4.3hadoop的配置
4.3.1更改hadoop安裝目錄的所有者
首先檢查一下/usr/local/hadoop-2.9.0這個hadoop的安裝目錄的所有者和使用者組是否是hadoop,如果不是就需要通過chown來設定:
[[email protected] .ssh]$ ls -lh /usr/local/hadoop-2.9.0
total 128K
drwxr-xr-x. 2 root root 194 Nov 14 07:28 bin
drwxr-xr-x. 3 root root 20 Nov 14 07:28 etc
drwxr-xr-x. 2 root root 106 Nov 14 07:28 include
drwxr-xr-x. 3 root root 20 Nov 14 07:28 lib
drwxr-xr-x. 2 root root 239 Nov 14 07:28 libexec
-rw-r--r--. 1 root root 104K Nov 14 07:28 LICENSE.txt
-rw-r--r--. 1 root root 16K Nov 14 07:28 NOTICE.txt
-rw-r--r--. 1 root root 1.4K Nov 14 07:28 README.txt
drwxr-xr-x. 3 root root 4.0K Nov 14 07:28 sbin
drwxr-xr-x. 4 root root 31 Nov 14 07:28 share
下面是更改owner和group的命令:
[[email protected] .ssh]$ sudo chown -R hadoop:hadoop /usr/local/hadoop-2.9.0
We trust you have received the usual lecture from the local System
Administrator. It usually boils down to these three things:
#1) Respect the privacy of others.
#2) Think before you type.
#3) With great power comes great responsibility.
[sudo] password for hadoop:
再次檢視,就可以看到命令執行成功了。
[[email protected] .ssh]$ ls -lh /usr/local/hadoop-2.9.0
total 128K
drwxr-xr-x. 2 hadoop hadoop 194 Nov 14 07:28 bin
drwxr-xr-x. 3 hadoop hadoop 20 Nov 14 07:28 etc
drwxr-xr-x. 2 hadoop hadoop 106 Nov 14 07:28 include
drwxr-xr-x. 3 hadoop hadoop 20 Nov 14 07:28 lib
drwxr-xr-x. 2 hadoop hadoop 239 Nov 14 07:28 libexec
-rw-r--r--. 1 hadoop hadoop 104K Nov 14 07:28 LICENSE.txt
-rw-r--r--. 1 hadoop hadoop 16K Nov 14 07:28 NOTICE.txt
-rw-r--r--. 1 hadoop hadoop 1.4K Nov 14 07:28 README.txt
drwxr-xr-x. 3 hadoop hadoop 4.0K Nov 14 07:28 sbin
drwxr-xr-x. 4 hadoop hadoop 31 Nov 14 07:28 share
4.3.2更改hadoop的配置
hadoop的配置檔案存放於/usr/local/hadoop-2.9.0/etc/hadoop目錄下,主要有幾個配置檔案:
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
其中,後兩個主要是跟YARN有關的配置。
將core-site.xml更改為如下內容:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
然後再將hdfs-site.xml更改為如下內容:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
5.檢驗配置
5.1NameNode格式化
經過上面的配置,Hadoop是配置成功了,但是並不能工作,還需要進行初始化操作,因為我們已經配置了Hadoop的相關環境變數,因此我們可以直接執行如下命令:
hdfs namenode –format
如果沒有問題的話,可以看到如下輸出:
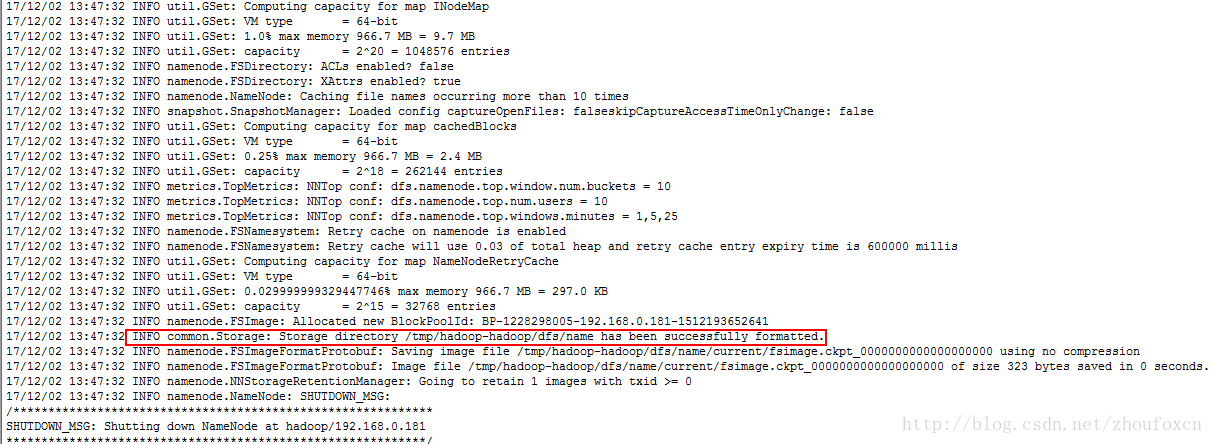
其中有一句:” INFO common.Storage: Storage directory /tmp/hadoop-hadoop/dfs/name has been successfully formatted.”
5.2開啟 NameNode 和 DataNode 守護程序
通過start-dfs.sh命令開啟NameNode 和 DataNode 守護進,第一次執行時會詢問是否連線,輸入”yes”即可(因為已經配置了ssh免密碼登入),如下所示(請注意一定要用建立的hadoop使用者來執行,如果不是hadoop請記得用su hadoop命令來切換到hadoop使用者):
[[email protected] hadoop]$ start-dfs.sh
17/12/02 13:54:19 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [localhost]
localhost: starting namenode, logging to /usr/local/hadoop-2.9.0/logs/hadoop-hadoop-namenode-hadoop.out
localhost: starting datanode, logging to /usr/local/hadoop-2.9.0/logs/hadoop-hadoop-datanode-hadoop.out
Starting secondary namenodes [0.0.0.0]
The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established.
ECDSA key fingerprint is aa:21:ce:7a:b2:06:3e:ff:3f:3e:cc:dd:40:38:64:9d.
Are you sure you want to continue connecting (yes/no)? yes
0.0.0.0: Warning: Permanently added '0.0.0.0' (ECDSA) to the list of known hosts.
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop-2.9.0/logs/hadoop-hadoop-secondarynamenode-hadoop.out
17/12/02 13:54:42 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
然後我們可以通過jps這個java提供的工具來檢視啟動情況:
[[email protected] hadoop]$ jps
11441 Jps
11203 SecondaryNameNode
10903 NameNode
11004 DataNode
若啟動成功會出現上述的程序,如果沒有NameNode和DataNode程序請檢查配置情況,或者通過/usr/local/hadoop-2.9.0/logs下的日誌來檢視配置錯誤。
這時可以在瀏覽器中輸入http://localhost:50070/檢視NameNode和DataNode的資訊以及HDFS的資訊,介面如下:

如果虛擬機器採用了橋接模式,也可以在虛擬機器外檢視,像本人所使用的CentOS7,需要注意兩點:
1.在/etc/sysconfig/selinux檔案中將“SELINUX=enforcing”改為” SELINUX=disabled”;
2.通過執行systemctl disable firewalld來禁用防火牆。
5.3執行WordCount程式
Hadoop中的WordCount如同其它程式語言中的Hello World程式一樣,就是通過一個簡單的程式來程式是如何編寫的。
5.3.1 HDFS簡介
要想執行WordCount就需要使用HDFS,HDFS是Hadoop的基石。可以這麼理解,Hadoop要處理大量的資料檔案,這些資料檔案需要一個可靠的方式來儲存,在即使出現一些機器的硬碟損壞的情況下,資料檔案中儲存的資料仍然不會丟失。在資料量比較小的時候,磁碟陣列(Redundant Arrays of Independent Disks,RAID)可以做到這一點,現在是HDFS用軟體的方式實現了這個功能。
HDFS也提供了一些命令用於對檔案系統的操作,我們知道Linux本身提供了一些對檔案系統的操作,比如mkdir、rm、mv等,HDFS中也提供同樣的操作,不過執行方式上有一些變化,比如mkdir命令在HDFS中執行應該寫成 hdfs dfs –mkdir,同樣的,ls命令在HDFS下執行要寫成hdfs dfs –ls。
下面是一些HDFS命令:
級聯建立HDFS目錄:hdfs dfs -mkdir -p /user/haddop
檢視HDFS目錄:hdfs dfs -ls /user
建立HDFS目錄:hdfs dfs -mkdir /input
檢視HDFS目錄:hdfs dfs -ls /
刪除HDFS目錄:hdfs dfs -rm -r -f /input
刪除HDFS目錄:hdfs dfs -rm -r -f /user/haddop
級聯建立HDFS目錄:hdfs dfs -mkdir -p /user/hadoop/input
注意:在HDFS中建立的目錄也僅支援在HDFS中檢視,在HDFS之外(比如在Linux系統中的命令列下)是看不到這些目錄存在的。重要的事情多重複幾遍:請按照本文中的3.2節提示將Hadoop安裝路徑資訊配置到環境變數中。
5.3.2執行WordCount程式
首先將工作路徑切換到Hadoop的安裝目錄:/usr/local/hadoop-2.9.0
接著在HDFS中建立目錄:hdfs dfs -mkdir -p /user/hadoop/input
然後指定要分析的資料來源,可以將一些文字資料放到剛剛建立的HDFS系統下的input目錄下,為了簡單起見,這裡就直接將hadoop安裝路徑下的一些用於配置的xml放在input目錄下:
hdfs dfs -put /usr/local/hadoop-2.9.0/etc/hadoop/*.xml /user/hadoop/input
這時可以通過HDFS檢視:
[[email protected] ~]$ hdfs dfs -ls /user/hadoop/input
17/12/17 10:27:27 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 8 items
-rw-r--r-- 1 hadoop supergroup 7861 2017-12-17 10:26 /user/hadoop/input/capacity-scheduler.xml
-rw-r--r-- 1 hadoop supergroup 884 2017-12-17 10:26 /user/hadoop/input/core-site.xml
-rw-r--r-- 1 hadoop supergroup 10206 2017-12-17 10:26 /user/hadoop/input/hadoop-policy.xml
-rw-r--r-- 1 hadoop supergroup 867 2017-12-17 10:26 /user/hadoop/input/hdfs-site.xml
-rw-r--r-- 1 hadoop supergroup 620 2017-12-17 10:26 /user/hadoop/input/httpfs-site.xml
-rw-r--r-- 1 hadoop supergroup 3518 2017-12-17 10:26 /user/hadoop/input/kms-acls.xml
-rw-r--r-- 1 hadoop supergroup 5939 2017-12-17 10:26 /user/hadoop/input/kms-site.xml
-rw-r--r-- 1 hadoop supergroup 690 2017-12-17 10:26 /user/hadoop/input/yarn-site.xml
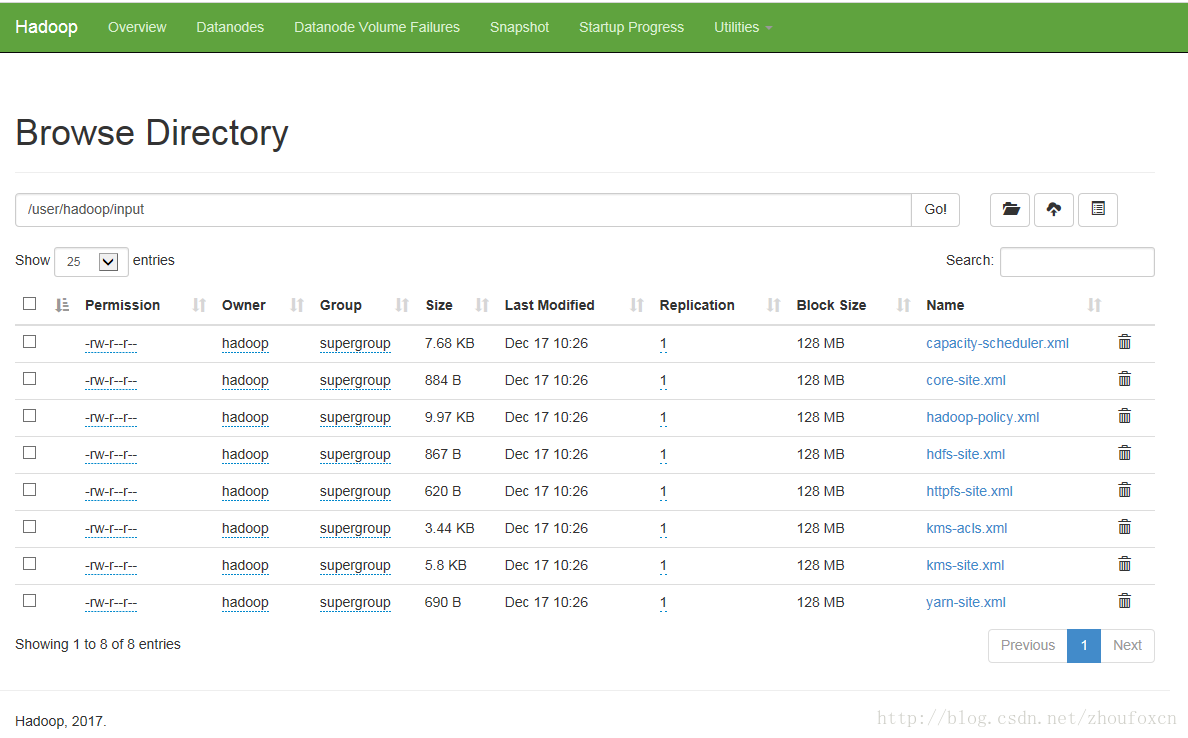
當然,也可以在Hadoop提供的Web介面下檢視,在瀏覽器輸入網址http://localhost:50070/explorer.html然後輸入HDFS下的檔案路徑,如下圖所示:
然後執行MapReduce作業,命令如下:
hadoop jar /usr/local/hadoop-2.9.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'
這個作業的作用的將/user/hadoop/input/這個HDFS目錄下的檔案中包含有dfs開頭的單詞找出來並統計出現的次數,如果程式執行沒有錯誤,我們將會在/user/hadoop/output/這個HDFS目錄下看到兩個檔案:
hdfs dfs -ls /user/hadoop/output
17/12/17 10:41:28 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 2 items
-rw-r--r-- 1 hadoop supergroup 0 2017-12-17 10:36 /user/hadoop/output/_SUCCESS
-rw-r--r-- 1 hadoop supergroup 29 2017-12-17 10:36 /user/hadoop/output/part-r-00000
我們用如下命令在HDFS中檢視:
hdfs dfs -cat /user/hadoop/output/*
17/12/17 10:42:57 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
1 dfsadmin
1 dfs.replication
也可以將其從HDFS檔案系統中取出來放在本地:
[[email protected] ~]$ hdfs dfs -get /user/hadoop/output /home/hadoop/output
上面的命令就是將HDFS檔案路徑/user/hadoop/output中的所有內容都拷貝到/home/hadoop/output下,這是就可以用熟悉的Linux命名檢視檔案內容了。
注意:
1、在程式執行時,/user/hadoop/output這個HDFS目錄不能存在,否則再次執行時會報錯,這是可以重新指定輸出目錄或者刪除這個目錄即可,如執行hdfs dfs -rm -f -r /user/hadoop/output命令。
2、如果需要關閉Hadoop,請執行stop-dfs.sh命名即可。
3、Hadoop的NameNode和DataNode節點的格式化成功執行一次之後,下次執行時不必執行。
5.4啟用YARN模式
YARN,全稱是Yet Another Resource Negotiator,YARN是從 MapReduce 中分離出來的,負責資源管理與任務排程。YARN 運行於 MapReduce 之上,提供了高可用性、高擴充套件性。上述通過 tart-dfs.sh 啟動 Hadoop,僅僅是啟動了 MapReduce 環境,我們可以啟動 YARN ,讓 YARN 來負責資源管理與任務排程。
要想使用YARN,首先要通過mapred-site.xml來配置,預設情況在/usr/local/hadoop-2.9.0/etc/hadoop是不存在這個檔案的,但是有一個名為mapred-site.xml.template的模板檔案。
首先將其改名為mapred-site.xml:
cp /usr/local/hadoop-2.9.0/etc/hadoop/mapred-site.xml.template /usr/local/hadoop-2.9.0/etc/hadoop/mapred-site.xml
然後修改檔案內容如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
同樣將同一目錄下的yarn-site.xml檔案內容修改如下:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
至此,可以通過start-yarn.sh來啟動YARN和通過stop-yarn.sh來停止YARN了。
啟動YARN:
請在確定已經正確執行過start-dfs.sh後再執行執行如下命令:
start-yarn.sh
為了能在Web中檢視任務執行情況,需要開啟歷史伺服器,執行如下命令:
mr-jobhistory-daemon.sh start historyserver
這時可通過jps檢視啟動情況:
[[email protected] ~]$ jps
7559 JobHistoryServer
8039 DataNode
8215 SecondaryNameNode
8519 NodeManager
8872 Jps
8394 ResourceManager
7902 NameNode
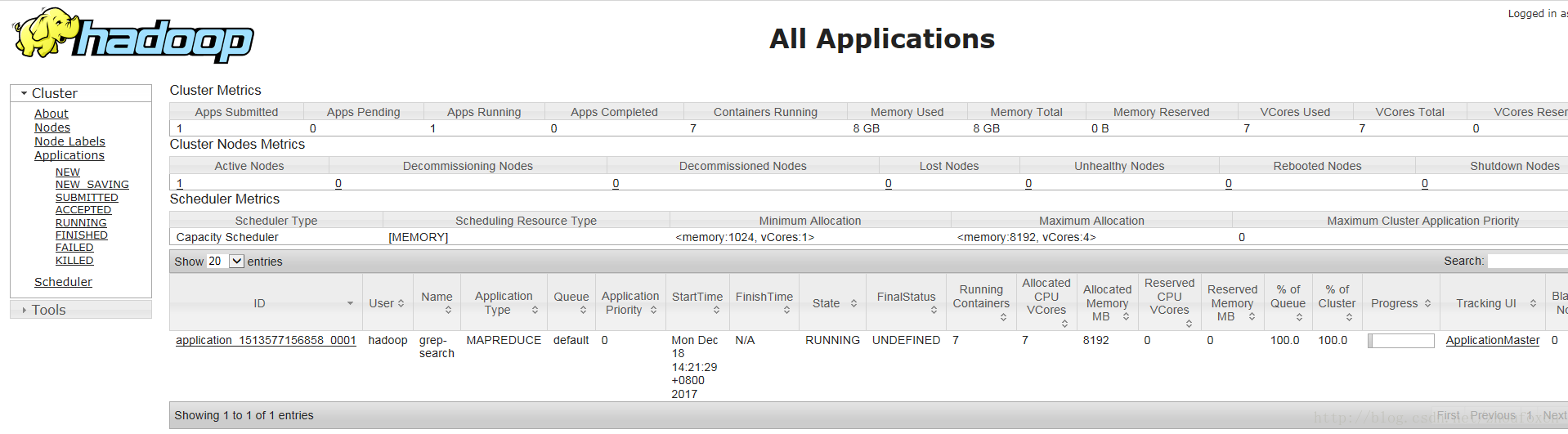
啟動YARN之後是可以在Web介面中檢視任務的執行情況的,網址是http://localhost:8088/,介面如下:
6.總結
“大雲物移”是當年很火熱的一個話題,分別指大資料、雲端計算、物聯網和移動網際網路,其中大資料領域談論得多就是Hadoop。當然Hadoop不代表大資料,而是大資料處理領域的一個比較有名的開源框架而已,通常說的大資料包含了大資料的存放、大資料的分析處理及大資料的查詢展示,本篇提到的Hadoop只不過是在其中的大資料的分析處理環節起作用,Apache提供了一個開源全家桶,包括了Hadoop、HBase、Zookeeper、Spark、Hive及Pig等一些框架。不過限於篇幅,本篇只介紹Hadoop的偽分散式部署,包括MapReduce和HDFS。
2.準備
JDK檔案:jdk-8u131-linux-x64.tar.gz
官方下載地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Hadoop檔案:hadoop-2.9.0.tar.gz
官方下載地址:http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.9.0/hadoop-2.9.0.tar.gz
3.安裝
3.1安裝Oracle JDK
3.1.1解除安裝Open JDK
雖然Open JDK是JDK的開源實現,不過個人還是比較喜歡Oracle JDK,可能覺得它出身更正統一些吧。因此首先檢查伺服器上是否安裝了Open JDK,執行命令:
rpm -qa | grep jdk
如果伺服器已經安裝了Open JDK,採用下面的方式解除安裝掉Open JDK,如下圖所示:
3.1.2安裝Oracle JDK
可能有些人對Oracle JDK感覺到有點彆扭,至少本人就是如此,當年Sun公司推出了Java但由於經營不善被Oracle收購,所以以前經常說的Sun JDK現在改口稱Oracle JDK了。將前文提及的JDK安裝包下載至/root目錄下。
按照下面的方式來安裝:
cd /root
tar -zxf /root/jdk-8u131-linux-x64.tar.gz -C /usr/local
這樣一來JDK就安裝在/usr/local/jdk1.8.0_131目錄下了。
下面就對環境變數進行設定,因為在Linux中存在著互動式shell和非互動式shell,互動式shell顧名思義就是在與使用者的互動過程中執行的shell,通常是通過SSH登入到Linux系統之後輸入shell指令碼或命令等待使用者輸入或者確認然後執行的shell,而非互動式shell則是無需使用者干預的shell,如一些service的啟動等。互動式shell從/etc/profile中讀取所有使用者的環境變數設定,非互動式shell則從/etc/bashrc中讀取所有使用者的環境變數設定。因此可能會出現在互動式環境下執行shell指令碼沒有問題,在非互動式環境下執行shell指令碼則會出現找不到環境變數配置資訊的問題。
為保險起見,我們在/etc/profile和/etc/bashrc都配置Java相關的環境變數,將新增的內容放在原檔案的末尾,新增的內容如下:
export JAVA_HOME=/usr/local/jdk1.8.0_131
export JRE_HOME=/usr/local/jdk1.8.0_131
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
可以通過tail檢視修改後的檔案:
[[email protected] ~]# tail /etc/profile -n 5
export JAVA_HOME=/usr/local/jdk1.8.0_131
export JRE_HOME=/usr/local/jdk1.8.0_131
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
[[email protected] ~]# tail /etc/bashrc -n 5
export JAVA_HOME=/usr/local/jdk1.8.0_131
export JRE_HOME=/usr/local/jdk1.8.0_131
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
[[email protected] ~]# source /etc/profile
[[email protected] ~]# source /etc/bashrc
[[email protected] ~]# java -version
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
[[email protected] ~]#
注意,要想讓我們的配置馬上生效,應該執行source /etc/profile和source /etc/bashrc來立即讀取更新後的配置資訊。
3.2安裝Hadoop
將前文提及的Hadoop安裝包下載至/root目錄下。
通過如下命名安裝Hadoop:
[[email protected] ~]# cd /root
[[email protected] ~]# tar -zxf /root/hadoop-2.9.0.tar.gz -C /usr/local
這樣一來,Hadoop2.9.0就安裝在/usr/local/hadoop-2.9.0目錄下,我們可以通過如下命令檢視一下:
[[email protected] ~]# /usr/local/hadoop-2.9.0/bin/hadoop version
Hadoop 2.9.0
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 756ebc8394e473ac25feac05fa493f6d612e6c50
Compiled by arsuresh on 2017-11-13T23:15Z
Compiled with protoc 2.5.0
From source with checksum 0a76a9a32a5257331741f8d5932f183
This command was run using /usr/local/hadoop-2.9.0/share/hadoop/common/hadoop-common-2.9.0.jar
[[email protected] ~]#
畢竟每次執行hadoop的時候帶著這麼一長串命令不是很方便,尤其是需要手動輸入的時候,我們依然可以借鑑配置JAVA環境引數的方式將Hadoop相關的環境引數配置到環境變數配置檔案source /etc/profile和source /etc/bashrc中,在兩個檔案的末尾分別增加如下配置:
export HADOOP_HOME=/usr/local/hadoop-2.9.0
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
新增完內容儲存,最後別忘了執行如下命令重新整理環境變數資訊:
[[email protected] ~]# source /etc/profile
[[email protected] ~]# source /etc/bashrc
這時候再執行hadoop的相關命令就無需帶路徑資訊了,如下:
[[email protected] ~]# hadoop version
Hadoop 2.9.0
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 756ebc8394e473ac25feac05fa493f6d612e6c50
Compiled by arsuresh on 2017-11-13T23:15Z
Compiled with protoc 2.5.0
From source with checksum 0a76a9a32a5257331741f8d5932f183
This command was run using /usr/local/hadoop-2.9.0/share/hadoop/common/hadoop-common-2.9.0.jar
4.配置
4.1使用者配置
為便於管理和維護,我們單獨建立一個系統賬戶用來執行hadoop有關的指令碼和任務,這個系統賬戶名為hadoop,通過以下指令碼建立:
useradd hadoop -s /bin/bash –m
上面的命令建立了名為hadoop的使用者和使用者組,並且nginx使用者無法登入系統(-s /sbin/nologin限制),可以通過id命令檢視:
[[email protected] ~]# id hadoop
uid=1001(hadoop) gid=1001(hadoop) groups=1001(hadoop)
通過上面的命令建立的使用者是沒有密碼的,需要用passwd來設定密碼:
[[email protected] ~]# passwd hadoop
Changing password for user hadoop.
New password:
BAD PASSWORD: The password is shorter than 8 characters
Retype new password:
passwd: all authentication tokens updated successfully.
因為有時候需要hadoop這個使用者執行一些高許可權的命令,因此給予它sudo的許可權,開啟/etc/sudoers檔案,找到“root ALL=(ALL) ALL”那一行,在下面新增一行:
hadoop ALL=(ALL) ALL
然後儲存檔案(記住如果是用vim等編輯器編輯,最終儲存的時候要使用”:wq!”命令來強制儲存到這個只讀檔案)。修改的結果如下圖所示:
4.2免登入配置
雖然在本篇講述的是Hadoop的偽分散式部署,但是中間還有一些分散式的操作,這就要求能夠用ssh來登入,注意這裡的ssh不是Java裡面的SSH(Servlet+Spring+Hibernate),這裡講的SSH是Secure Shell 的縮寫,是用於Linux伺服器之間遠端登入的服務協議。
如果當前是用root使用者登入,那麼就要切換為hadoop使用者:
[[email protected] hadoop]# su hadoop
[[email protected] ~]$ cd ~
[[email protected] ~]$ pwd
/home/hadoop
可以看出hadoop使用者的工作路徑為/home/hadoop,然後我們用ssh登入本機,第一次登入的時候會提示是否繼續登入,然後輸入”yes”,接著會提示我們輸入當前用於ssh登入的使用者(這裡是hadoop)的在對應伺服器上的密碼(這裡是localhost),輸入正確密碼後就可以登入,然後在輸入”exit”退出登入,如下所示:
[[email protected] ~]$ ssh localhost
[email protected]'s password:
Last login: Sat Dec 2 11:48:52 2017 from localhost
[[email protected] ~]$ rm -rf /home/hadoop/.ssh
[[email protected] ~]$ ssh localhost
The authenticity of host 'localhost (::1)' can't be established.
ECDSA key fingerprint is aa:21:ce:7a:b2:06:3e:ff:3f:3e:cc:dd:40:38:64:9d.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
[email protected]'s password:
Last login: Sat Dec 2 11:49:58 2017 from localhost
[[email protected] ~]$ exit
logout
Connection to localhost closed.
經過上述操作後,建立了這個目錄/home/hadoop/.ssh和該目錄下的known_hosts檔案。
這樣每次登入都會提示輸入密碼,但在Hadoop執行過程中會通過shell無互動的形式在遠端伺服器上執行命令,因此需要設定成免密碼登入才行。我們需要通過通過如下命令建立金鑰檔案(一路回車即可):
[[email protected] ~]$ cd /home/hadoop/.ssh/
[[email protected] .ssh]$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa.
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.
The key fingerprint is:
19:b3:11:a5:6b:a3:26:03:c9:b9:b3:b8:02:ea:c9:25 [email protected]
The key's randomart image is:
+--[ RSA 2048]----+
| ... |
| o |
| = |
| . o B |
| = S |
|. o o . |
|oEo.o o |
|+.+o + |
|==. |
+-----------------+
然後將金鑰檔案的內容新增到authorized_keys檔案,同時授予600的許可權。
[[email protected] .ssh]$ cat id_rsa.pub >> authorized_keys
[[email protected] .ssh]$ chmod 600 authorized_keys
這時,再使用ssh localhost命令就不需要輸入密碼了,如下:
[[email protected] .ssh]$ ssh localhost
Last login: Sat Dec 2 11:50:44 2017 from localhost
[[email protected] ~]$ exit
logout
Connection to localhost closed.
注意:在本系列的第9篇關於git使用者免密碼登入時也講到了類似的操作,而且當時也講了git檔案傳輸也是使用ssh協議的。
4.3hadoop的配置
4.3.1更改hadoop安裝目錄的所有者
首先檢查一下/usr/local/hadoop-2.9.0這個hadoop的安裝目錄的所有者和使用者組是否是hadoop,如果不是就需要通過chown來設定:
[[email protected] .ssh]$ ls -lh /usr/local/hadoop-2.9.0
total 128K
drwxr-xr-x. 2 root root 194 Nov 14 07:28 bin
drwxr-xr-x. 3 root root 20 Nov 14 07:28 etc
drwxr-xr-x. 2 root root 106 Nov 14 07:28 include
drwxr-xr-x. 3 root root 20 Nov 14 07:28 lib
drwxr-xr-x. 2 root root 239 Nov 14 07:28 libexec
-rw-r--r--. 1 root root 104K Nov 14 07:28 LICENSE.txt
-rw-r--r--. 1 root root 16K Nov 14 07:28 NOTICE.txt
-rw-r--r--. 1 root root 1.4K Nov 14 07:28 README.txt
drwxr-xr-x. 3 root root 4.0K Nov 14 07:28 sbin
drwxr-xr-x. 4 root root 31 Nov 14 07:28 share
下面是更改owner和group的命令:
[[email protected] .ssh]$ sudo chown -R hadoop:hadoop /usr/local/hadoop-2.9.0
We trust you have received the usual lecture from the local System
Administrator. It usually boils down to these three things:
#1) Respect the privacy of others.
#2) Think before you type.
#3) With great power comes great responsibility.
[sudo] password for hadoop:
再次檢視,就可以看到命令執行成功了。
[[email protected] .ssh]$ ls -lh /usr/local/hadoop-2.9.0
total 128K
drwxr-xr-x. 2 hadoop hadoop 194 Nov 14 07:28 bin
drwxr-xr-x. 3 hadoop hadoop 20 Nov 14 07:28 etc
drwxr-xr-x. 2 hadoop hadoop 106 Nov 14 07:28 include
drwxr-xr-x. 3 hadoop hadoop 20 Nov 14 07:28 lib
drwxr-xr-x. 2 hadoop hadoop 239 Nov 14 07:28 libexec
-rw-r--r--. 1 hadoop hadoop 104K Nov 14 07:28 LICENSE.txt
-rw-r--r--. 1 hadoop hadoop 16K Nov 14 07:28 NOTICE.txt
-rw-r--r--. 1 hadoop hadoop 1.4K Nov 14 07:28 README.txt
drwxr-xr-x. 3 hadoop hadoop 4.0K Nov 14 07:28 sbin
drwxr-xr-x. 4 hadoop hadoop 31 Nov 14 07:28 share
4.3.2更改hadoop的配置
hadoop的配置檔案存放於/usr/local/hadoop-2.9.0/etc/hadoop目錄下,主要有幾個配置檔案:
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
其中,後兩個主要是跟YARN有關的配置。
將core-site.xml更改為如下內容:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
然後再將hdfs-site.xml更改為如下內容:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
5.檢驗配置
5.1NameNode格式化
經過上面的配置,Hadoop是配置成功了,但是並不能工作,還需要進行初始化操作,因為我們已經配置了Hadoop的相關環境變數,因此我們可以直接執行如下命令:
hdfs namenode –format
如果沒有問題的話,可以看到如下輸出:
其中有一句:” INFO common.Storage: Storage directory /tmp/hadoop-hadoop/dfs/name has been successfully formatted.”
5.2開啟 NameNode 和 DataNode 守護程序
通過start-dfs.sh命令開啟NameNode 和 DataNode 守護進,第一次執行時會詢問是否連線,輸入”yes”即可(因為已經配置了ssh免密碼登入),如下所示(請注意一定要用建立的hadoop使用者來執行,如果不是hadoop請記得用su hadoop命令來切換到hadoop使用者):
[[email protected] hadoop]$ start-dfs.sh
17/12/02 13:54:19 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [localhost]
localhost: starting namenode, logging to /usr/local/hadoop-2.9.0/logs/hadoop-hadoop-namenode-hadoop.out
localhost: starting datanode, logging to /usr/local/hadoop-2.9.0/logs/hadoop-hadoop-datanode-hadoop.out
Starting secondary namenodes [0.0.0.0]
The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established.
ECDSA key fingerprint is aa:21:ce:7a:b2:06:3e:ff:3f:3e:cc:dd:40:38:64:9d.
Are you sure you want to continue connecting (yes/no)? yes
0.0.0.0: Warning: Permanently added '0.0.0.0' (ECDSA) to the list of known hosts.
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop-2.9.0/logs/hadoop-hadoop-secondarynamenode-hadoop.out
17/12/02 13:54:42 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
然後我們可以通過jps這個java提供的工具來檢視啟動情況:
[[email protected] hadoop]$ jps
11441 Jps
11203 SecondaryNameNode
10903 NameNode
11004 DataNode
若啟動成功會出現上述的程序,如果沒有NameNode和DataNode程序請檢查配置情況,或者通過/usr/local/hadoop-2.9.0/logs下的日誌來檢視配置錯誤。
這時可以在瀏覽器中輸入http://localhost:50070/檢視NameNode和DataNode的資訊以及HDFS的資訊,介面如下:
如果虛擬機器採用了橋接模式,也可以在虛擬機器外檢視,像本人所使用的CentOS7,需要注意兩點:
1.在/etc/sysconfig/selinux檔案中將“SELINUX=enforcing”改為” SELINUX=disabled”;
2.通過執行systemctl disable firewalld來禁用防火牆。
5.3執行WordCount程式
Hadoop中的WordCount如同其它程式語言中的Hello World程式一樣,就是通過一個簡單的程式來程式是如何編寫的。
5.3.1 HDFS簡介
要想執行WordCount就需要使用HDFS,HDFS是Hadoop的基石。可以這麼理解,Hadoop要處理大量的資料檔案,這些資料檔案需要一個可靠的方式來儲存,在即使出現一些機器的硬碟損壞的情況下,資料檔案中儲存的資料仍然不會丟失。在資料量比較小的時候,磁碟陣列(Redundant Arrays of Independent Disks,RAID)可以做到這一點,現在是HDFS用軟體的方式實現了這個功能。
HDFS也提供了一些命令用於對檔案系統的操作,我們知道Linux本身提供了一些對檔案系統的操作,比如mkdir、rm、mv等,HDFS中也提供同樣的操作,不過執行方式上有一些變化,比如mkdir命令在HDFS中執行應該寫成 hdfs dfs –mkdir,同樣的,ls命令在HDFS下執行要寫成hdfs dfs –ls。
下面是一些HDFS命令:
級聯建立HDFS目錄:hdfs dfs -mkdir -p /user/haddop
檢視HDFS目錄:hdfs dfs -ls /user
建立HDFS目錄:hdfs dfs -mkdir /input
檢視HDFS目錄:hdfs dfs -ls /
刪除HDFS目錄:hdfs dfs -rm -r -f /input
刪除HDFS目錄:hdfs dfs -rm -r -f /user/haddop
級聯建立HDFS目錄:hdfs dfs -mkdir -p /user/hadoop/input
注意:在HDFS中建立的目錄也僅支援在HDFS中檢視,在HDFS之外(比如在Linux系統中的命令列下)是看不到這些目錄存在的。重要的事情多重複幾遍:請按照本文中的3.2節提示將Hadoop安裝路徑資訊配置到環境變數中。
5.3.2執行WordCount程式
首先將工作路徑切換到Hadoop的安裝目錄:/usr/local/hadoop-2.9.0
接著在HDFS中建立目錄:hdfs dfs -mkdir -p /user/hadoop/input
然後指定要分析的資料來源,可以將一些文字資料放到剛剛建立的HDFS系統下的input目錄下,為了簡單起見,這裡就直接將hadoop安裝路徑下的一些用於配置的xml放在input目錄下:
hdfs dfs -put /usr/local/hadoop-2.9.0/etc/hadoop/*.xml /user/hadoop/input
這時可以通過HDFS檢視:
[[email protected] ~]$ hdfs dfs -ls /user/hadoop/input
17/12/17 10:27:27 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 8 items
-rw-r--r-- 1 hadoop supergroup 7861 2017-12-17 10:26 /user/hadoop/input/capacity-scheduler.xml
-rw-r--r-- 1 hadoop supergroup 884 2017-12-17 10:26 /user/hadoop/input/core-site.xml
-rw-r--r-- 1 hadoop supergroup 10206 2017-12-17 10:26 /user/hadoop/input/hadoop-policy.xml
-rw-r--r-- 1 hadoop supergroup 867 2017-12-17 10:26 /user/hadoop/input/hdfs-site.xml
-rw-r--r-- 1 hadoop supergroup 620 2017-12-17 10:26 /user/hadoop/input/httpfs-site.xml
-rw-r--r-- 1 hadoop supergroup 3518 2017-12-17 10:26 /user/hadoop/input/kms-acls.xml
-rw-r--r-- 1 hadoop supergroup 5939 2017-12-17 10:26 /user/hadoop/input/kms-site.xml
-rw-r--r-- 1 hadoop supergroup 690 2017-12-17 10:26 /user/hadoop/input/yarn-site.xml
當然,也可以在Hadoop提供的Web介面下檢視,在瀏覽器輸入網址http://localhost:50070/explorer.html然後輸入HDFS下的檔案路徑,如下圖所示:
然後執行MapReduce作業,命令如下:
hadoop jar /usr/local/hadoop-2.9.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'
這個作業的作用的將/user/hadoop/input/這個HDFS目錄下的檔案中包含有dfs開頭的單詞找出來並統計出現的次數,如果程式執行沒有錯誤,我們將會在/user/hadoop/output/這個HDFS目錄下看到兩個檔案:
hdfs dfs -ls /user/hadoop/output
17/12/17 10:41:28 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 2 items
-rw-r--r-- 1 hadoop supergroup 0 2017-12-17 10:36 /user/hadoop/output/_SUCCESS
-rw-r--r-- 1 hadoop supergroup 29 2017-12-17 10:36 /user/hadoop/output/part-r-00000
我們用如下命令在HDFS中檢視:
hdfs dfs -cat /user/hadoop/output/*
17/12/17 10:42:57 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
1 dfsadmin
1 dfs.replication
也可以將其從HDFS檔案系統中取出來放在本地:
[[email protected] ~]$ hdfs dfs -get /user/hadoop/output /home/hadoop/output
上面的命令就是將HDFS檔案路徑/user/hadoop/output中的所有內容都拷貝到/home/hadoop/output下,這是就可以用熟悉的Linux命名檢視檔案內容了。
注意:
1、在程式執行時,/user/hadoop/output這個HDFS目錄不能存在,否則再次執行時會報錯,這是可以重新指定輸出目錄或者刪除這個目錄即可,如執行hdfs dfs -rm -f -r /user/hadoop/output命令。
2、如果需要關閉Hadoop,請執行stop-dfs.sh命名即可。
3、Hadoop的NameNode和DataNode節點的格式化成功執行一次之後,下次執行時不必執行。
5.4啟用YARN模式
YARN,全稱是Yet Another Resource Negotiator,YARN是從 MapReduce 中分離出來的,負責資源管理與任務排程。YARN 運行於 MapReduce 之上,提供了高可用性、高擴充套件性。上述通過 tart-dfs.sh 啟動 Hadoop,僅僅是啟動了 MapReduce 環境,我們可以啟動 YARN ,讓 YARN 來負責資源管理與任務排程。
要想使用YARN,首先要通過mapred-site.xml來配置,預設情況在/usr/local/hadoop-2.9.0/etc/hadoop是不存在這個檔案的,但是有一個名為mapred-site.xml.template的模板檔案。
首先將其改名為mapred-site.xml:
cp /usr/local/hadoop-2.9.0/etc/hadoop/mapred-site.xml.template /usr/local/hadoop-2.9.0/etc/hadoop/mapred-site.xml
然後修改檔案內容如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
同樣將同一目錄下的yarn-site.xml檔案內容修改如下:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
至此,可以通過start-yarn.sh來啟動YARN和通過stop-yarn.sh來停止YARN了。
啟動YARN:
請在確定已經正確執行過start-dfs.sh後再執行執行如下命令:
start-yarn.sh
為了能在Web中檢視任務執行情況,需要開啟歷史伺服器,執行如下命令:
mr-jobhistory-daemon.sh start historyserver
這時可通過jps檢視啟動情況:
[[email protected] ~]$ jps
7559 JobHistoryServer
8039 DataNode
8215 SecondaryNameNode
8519 NodeManager
8872 Jps
8394 ResourceManager
7902 NameNode
啟動YARN之後是可以在Web介面中檢視任務的執行情況的,網址是http://localhost:8088/,介面如下:
6.總結
本篇主要講述瞭如何在CentOS7下部署Hadoop,包括了Hadoop執行的支援元件以及Hadoop的配置,並簡單介紹了一下HDFS這個分散式檔案系統的命令及用法,最後通過執行簡單的MapReduce示例來演示如何執行MapReduce程式。
7.宣告:本文通過轉載,檢視原文請點選https://blog.csdn.net/zhoufoxcn/article/details/78903629