
centos7下搭建hadoop、hbase、hive、spark分散式系統架構
全棧工程師開發手冊 (作者:欒鵬)
在使用前建議先將當前使用者設定為root使用者。參考https://blog.csdn.net/luanpeng825485697/article/details/80278383中修改使用者許可權的第三種方法。有了許可權就會方便操作。
在根目錄下建立資料夾/lp/hadoop,用來在這裡面存放hadoop生態環境
分散式hadoop部署
首先,在http://hadoop.apache.org/releases.html找到最新穩定版tar包,我選擇的是hadoop-2.7.3.tar.gz
下載解壓到/lp/hadoop/hadoop-2.7.3
hdfs的架構:hdfs部分由NameNode、SecondaryNameNode和DataNode組成。DataNode是真正的在每個儲存節點上管理資料的模組,NameNode是對全域性資料的名字資訊做管理的模組,SecondaryNameNode是它的從節點,以防掛掉。
最後再說map-reduce:Map-reduce依賴於yarn和hdfs,另外還有一個JobHistoryServer用來看任務執行歷史
hadoop雖然有多個模組分別部署,但是所需要的程式都在同一個tar包中,所以不同模組用到的配置檔案都在一起,讓我們來看幾個最重要的配置檔案:
各種預設配置:core-default.xml, hdfs-default.xml, yarn-default.xml, mapred-default.xml
各種web頁面配置:core-site.xml, hdfs-site.xml, yarn-site.xml, mapred-site.xml
從這些配置檔案也可以看出hadoop的幾大部分是分開配置的。
除上面這些之外還有一些重要的配置:hadoop-env.sh、mapred-env.sh、yarn-env.sh,他們用來配置程式執行時的java虛擬機器引數以及一些二進位制、配置、日誌等的目錄配置
下面我們真正的來修改必須修改的配置檔案。
修改etc/hadoop/core-site.xml,把配置改成:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://127.0.0.1:9001</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> </configuration>
這裡面配置的是hdfs的檔案系統地址:本機的9001埠
修改etc/hadoop/hdfs-site.xml,把配置改成:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/lp/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/lp/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.datanode.fsdataset.volume.choosing.policy</name>
<value>org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>127.0.0.1:8305</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>127.0.0.1:8310</value>
</property>
</configuration>
這裡面配置的是hdfs檔案儲存在本地的哪裡以及secondary namenode的地址
修改etc/hadoop/yarn-site.xml,把配置改成:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>127.0.0.1</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>127.0.0.1:8320</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>864000</value>
</property>
<property>
<name>yarn.log-aggregation.retain-check-interval-seconds</name>
<value>86400</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/lp/hadoop/YarnApp/Logs</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://127.0.0.1:8325/jobhistory/logs/</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/lp/hadoop/YarnApp/nodemanager</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>5000</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4.1</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
這裡面配置的是yarn的日誌地址以及一些引數配置
通過cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml建立etc/hadoop/mapred-site.xml,內容改為如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>Execution framework set to Hadoop YARN.</description>
</property>
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/lp/hadoop/YarnApp/tmp/hadoop-yarn/staging</value>
</property>
<!--MapReduce JobHistory Server地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>127.0.0.1:8330</value>
</property>
<!--MapReduce JobHistory Server Web UI地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>127.0.0.1:8331</value>
</property>
<!--MR JobHistory Server管理的日誌的存放位置-->
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>${yarn.app.mapreduce.am.staging-dir}/history/done</value>
</property>
<!--MapReduce作業產生的日誌存放位置-->
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>${yarn.app.mapreduce.am.staging-dir}/history/done_intermediate</value>
</property>
<property>
<name>mapreduce.jobhistory.joblist.cache.size</name>
<value>1000</value>
</property>
<property>
<name>mapreduce.tasktracker.map.tasks.maximum</name>
<value>8</value>
</property>
<property>
<name>mapreduce.tasktracker.reduce.tasks.maximum</name>
<value>8</value>
</property>
<property>
<name>mapreduce.jobtracker.maxtasks.perjob</name>
<value>5</value>
<description>The maximum number of tasks for a single job.
A value of -1 indicates that there is no maximum.
</description>
</property>
</configuration>
這裡面配置的是mapred的任務歷史相關配置
如果你的hadoop部署在多臺機器,那麼需要修改etc/hadoop/slaves,把其他slave機器ip加到裡面,如果只部署在這一臺,那麼就留一個localhost即可。
如果hadoop分散式部署在多臺機器上,每臺機器上的部署都是一樣的,都要知道master(主)的位置,每一個slaves(從)的位置。
下面我們啟動hadoop,啟動之前我們配置好必要的環境變數:
在hadoop-env.sh裡寫JAVA_HOME
export JAVA_HOME="你的java安裝地址"
為這邊寫的是
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk
這一部分下面的命令,需要在/lp/hadoop/hadoop-2.7.3目錄下執行,可以在/lp/hadoop/hadoop-2.7.3目錄下右健(在終端中開啟),然後再執行下面的hadoop部署的命令
先啟動hdfs,在此之前要格式化分散式檔案系統,執行:
./bin/hdfs namenode -format myclustername
如果格式化正常可以看到/lp/hadoop/dfs下生成了name目錄
然後啟動namenode,執行:
./sbin/hadoop-daemon.sh --script hdfs start namenode
如果正常啟動,可以看到啟動了相應的程序,並且/lp/hadoop/hadoop-2.7.3/logs目錄下生成了相應的日誌
然後啟動datanode,執行:
./sbin/hadoop-daemon.sh --script hdfs start datanode
如果考慮啟動secondary namenode,可以用同樣的方法啟動
下面我們啟動yarn,先啟動resourcemanager,執行:
./sbin/yarn-daemon.sh start resourcemanager
如果正常啟動,可以看到啟動了相應的程序,並且logs目錄下生成了相應的日誌
然後啟動nodemanager,執行:
./sbin/yarn-daemon.sh start nodemanager
如果正常啟動,可以看到啟動了相應的程序,並且logs目錄下生成了相應的日誌
然後啟動MapReduce JobHistory Server,執行:
./sbin/mr-jobhistory-daemon.sh start historyserver
下面我們看下web介面
開啟http://127.0.0.1:8320/cluster看下yarn管理的叢集資源情況(因為在yarn-site.xml中我們配置了yarn.resourcemanager.webapp.address是127.0.0.1:8320)
開啟http://127.0.0.1:8331/jobhistory看下map-reduce任務的執行歷史情況(因為在mapred-site.xml中我們配置了mapreduce.jobhistory.webapp.address是127.0.0.1:8331)
開啟http://127.0.0.1:8305/dfshealth.html看下namenode的儲存系統情況(因為在hdfs-site.xml中我們配置了dfs.namenode.http-address是127.0.0.1:8305)
到此為止我們對hadoop的部署完成。
以後再啟動就不需要再輸入這麼多啟動命令,只需要啟動start-dfs.sh和start-yarn.sh就可以了,他們會自動啟動namenode、datanode、secondarynamenode,和 resourcemanager、nodemanager。
[[email protected] hadoop-2.7.3]# ./sbin/start-dfs.sh
自動啟動namenode、datanode、secondarynamenode。
Starting namenodes on [localhost]
The authenticity of host 'localhost (::1)' can't be established.
ECDSA key fingerprint is 1e:64:5d:6d:26:40:c9:3e:14:0a:5f:50:6f:2f:3f:52.
Are you sure you want to continue connecting (yes/no)? yes
localhost: Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
[email protected]'s password:
localhost: starting namenode, logging to /lp/hadoop/hadoop-2.7.3/logs/hadoop-root-namenode-localhost.out
[email protected]'s password:
localhost: starting datanode, logging to /lp/hadoop/hadoop-2.7.3/logs/hadoop-root-datanode-localhost.out
Starting secondary namenodes [localhost]
[email protected]'s password:
localhost: starting secondarynamenode, logging to /lp/hadoop/hadoop-2.7.3/logs/hadoop-root-secondarynamenode-localhost.out
[[email protected] hadoop-2.7.3]# ./sbin/start-yarn.sh
自動啟動 resourcemanager、nodemanager。
starting yarn daemons
starting resourcemanager, logging to /lp/hadoop/hadoop-2.7.3/logs/yarn-root-resourcemanager-localhost.out
[email protected]'s password:
localhost: starting nodemanager, logging to /lp/hadoop/hadoop-2.7.3/logs/yarn-root-nodemanager-localhost.out
下面試驗一下hadoop的功能。
在/lp/hadoop/hadoop-2.7.3資料夾下新建一個檔案data,內容為
1
2
3
4
先驗證一下hdfs分散式檔案系統,執行以下命令看是否有輸出:
建立HDFS目錄(注意不是本地目錄)
[[email protected] hadoop-2.7.3]# ./bin/hadoop fs -mkdir /input
[[email protected]alhost hadoop-2.7.3]# cat data
1
2
3
4
[[email protected] hadoop-2.7.3]# ./bin/hadoop fs -put data /input
[[email protected] hadoop-2.7.3]# ./bin/hadoop fs -ls /input
Found 1 items
-rw-r--r-- 3 work supergroup 8 2016-11-03 16:56 /input/data
但是在存放資料的目錄/lp/hadoop/dfs/data,是看不出來有變化的:
這時候,在http://127.0.0.1:8305/dfshealth.html上能夠看出一些變化:
Configured Capacity: 2.62 TB
DFS Used: 48 KB (0%)
Non DFS Used: 3.99 GB
DFS Remaining: 2.62 TB (99.85%)
建立HDFS資料夾
./bin/hadoop fs -mkdir /input
刪除HDFS資料夾
./bin/hadoop fs -rmr /input
上面的命令就把output資料夾刪除了,-rmr是一個遞迴刪除操作,會刪除該資料夾下面的所有檔案以及資料夾。也可以選用-rm ,單個刪除。
新增本地檔案到hdfs目錄
先在本地建立兩個資料夾/lp/hadoop/dfs/input、/lp/hadoop/dfs/output
[[email protected] hadoop-2.7.3]# ./bin/hadoop fs -put /lp/hadoop/dfs/input /input
[[email protected] hadoop-2.7.3]# ./bin/hadoop fs -put /lp/hadoop/dfs/output /output
上面命令的hadoop fs -put 後面的第一個引數是本地路徑,第二個引數是hadoop HDFS上的路徑,意思就是將本地路徑載入到HDFS上。
注意:在將本地目錄新增為hdfs目錄以後,再更改本地目錄,並不會修改hdfs目錄。
現在跑一個hadoop命令wc看看:
# ./bin/hadoop jar ./share/hadoop/tools/lib/hadoop-streaming-2.7.3.jar -input /input -output /output -mapper cat -reducer wc
可以看到結果:
# ./bin/hadoop fs -ls /output
Found 2 items
-rw-r--r-- 3 work supergroup 0 2016-11-03 17:17 /output/_SUCCESS
-rw-r--r-- 3 work supergroup 25 2016-11-03 17:17 /output/part-00000
# ./bin/hadoop fs -cat /output/part-00000
4 4 12
原來是wc的輸出格式:
行數 單詞數 位元組數
hbase的部署
首先從http://www.apache.org/dyn/closer.cgi/hbase/下載穩定版安裝包,我下的是hbase-1.2.6-bin.tar.gz
下載解壓到/lp/hadoop/hbase-1.2.6
解壓後修改conf/hbase-site.xml,改成:
<configuration>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9001/hbase</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>127.0.0.1</value>
</property>
<property>
<name>hbase.coprocessor.master.classes</name>
<value>org.apache.hadoop.hbase.security.access.AccessController</value>
</property>
<property>
<name>hbase.coprocessor.region.classes</name>
<value>org.apache.hadoop.hbase.security.token.TokenProvider,org.apache.hadoop.hbase.security.access.AccessController,org.apache.hadoop.hbase.security.access.SecureBulkLoadEndpoint</value>
</property>
</configuration>
其中hbase.rootdir配置的是hdfs地址,ip:port要和hadoop/core-site.xml中的fs.defaultFS保持一致
其中hbase.zookeeper.quorum是zookeeper的地址,可以配多個,我們試驗用就先配一個
修改 /lp/hadoop/hbase-1.2.6/conf/hbase-env.sh
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk
hbase的部署,需要在/lp/hadoop/hbase-1.2.6目錄下右健(在終端中開啟),然後執行hbase部署的命令
啟動hbase,執行
./bin/start-hbase.sh
這時有可能會讓你輸入本地機器的密碼
啟動成功後可以看到幾個程序起來,包括zookeeper的HQuorumPeer和hbase的HMaster、HRegionServer
然後啟動hbase的shell
./bin/hbase shell
下面我們試驗一下hbase的使用,執行:
hbase(main):001:0> status
1 active master, 0 backup masters, 1 servers, 0 dead, 3.0000 average load
建立一張表
hbase(main):004:0> create 'table1','field1'
0 row(s) in 1.3430 seconds
=> Hbase::Table - table1
獲取一張表
hbase(main):005:0> t1 = get_table('table1')
0 row(s) in 0.0010 seconds
=> Hbase::Table - table1
新增一行
hbase(main):008:0> t1.put 'row1', 'field1:qualifier1', 'value1'
0 row(s) in 0.4160 seconds
讀取全部
hbase(main):009:0> t1.scan
ROW COLUMN+CELL
row1 column=field1:qualifier1, timestamp=1470621285068, value=value1
1 row(s) in 0.1000 seconds
我們同時也看到hdfs中多出了hbase儲存的目錄(注意下面的命令是在/lp/hadoop/hadoop-2.7.3目錄下執行):
[[email protected] hadoop-2.7.3]# ./bin/hadoop fs -ls /hbase
Found 7 items
drwxr-xr-x - root supergroup 0 2016-08-08 09:05 /hbase/.tmp
drwxr-xr-x - root supergroup 0 2016-08-08 09:58 /hbase/MasterProcWALs
drwxr-xr-x - root supergroup 0 2016-08-08 09:05 /hbase/WALs
drwxr-xr-x - root supergroup 0 2016-08-08 09:05 /hbase/data
-rw-r--r-- 3 root supergroup 42 2016-08-08 09:05 /hbase/hbase.id
-rw-r--r-- 3 root supergroup 7 2016-08-08 09:05 /hbase/hbase.version
drwxr-xr-x - root supergroup 0 2016-08-08 09:24 /hbase/oldWALs
這說明hbase是以hdfs為儲存介質的,因此它具有分散式儲存擁有的所有優點
hbase的架構如下:
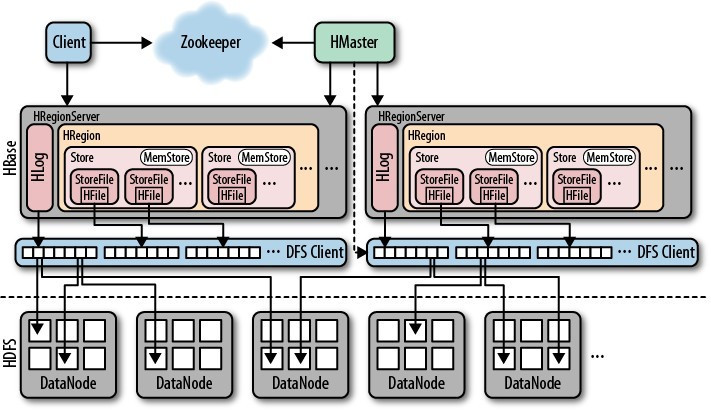
其中HMaster負責管理HRegionServer以實現負載均衡,負責管理和分配HRegion(資料分片),還負責管理名稱空間和table元資料,以及許可權控制
HRegionServer負責管理本地的HRegion、管理資料以及和hdfs互動。
Zookeeper負責叢集的協調(如HMaster主從的failover)以及叢集狀態資訊的儲存
客戶端傳輸資料直接和HRegionServer通訊
Hive
從http://mirrors.hust.edu.cn/apache/hive下載安裝包,我下的是apache-hive-2.1.1-bin.tar.gz
解壓後,我們先準備hdfs,執行:
解壓後在 /lp/hadoop/apache-hive-2.1.1-bin
開啟conf,準備配置檔案 cp hive-env.sh.template hive-env.sh
修改HADOOP_HOME:HADOOP_HOME=/lp/hadoop/hadoop-2.7.3
複製hive-default.xml.template貼上為hive-site.xml
複製hive-log4j2.properties.template貼上為hive-log4j2.properties
複製hive-exec-log4j2.properties.template貼上為hive-exec-log4j2.properties
解壓後,我們先準備hdfs,執行(下面的命令是在/lp/hadoop/hadoop-2.7.3目錄下執行的):
[[email protected] hadoop-2.7.3]# ./bin/hadoop fs -mkdir /tmp
[[email protected] hadoop-2.7.3]# ./bin/hadoop fs -mkdir /user
[[email protected] hadoop-2.7.3]# ./bin/hadoop fs -mkdir /user/hive
[[email protected] hadoop-2.7.3]# ./bin/hadoop fs -mkdir /user/hive/warehourse
[[email protected] hadoop-2.7.3]# ./bin/hadoop fs -chmod g+w /tmp
[[email protected] hadoop-2.7.3]# ./bin/hadoop fs -chmod g+w /user/hive/warehourse
使用hive必須提前設定好HADOOP_HOME環境變數,這樣它可以自動找到我們的hdfs作為儲存,不妨我們把各種HOME和各種PATH都配置好:
vim ~/.bashrc
點選a修改,新增以下內容
HADOOP_HOME=/lp/hadoop/hadoop-2.7.3
export HADOOP_HOME
HBASE_HOME=/lp/hadoop/hbase-1.2.6
export HBASE_HOME
HIVE_HOME=/lp/hadoop/apache-hive-2.1.1-bin
export HIVE_HOME
PATH=$PATH:$HOME/bin
PATH=$PATH:$HBASE_HOME/bin
PATH=$PATH:$HIVE_HOME/bin
PATH=$PATH:$HADOOP_HOME/bin
export PATH
按esc退出編輯,按ZZ儲存退出。
執行一下“source ~/.bashrc ”,重新載入修改後的配置。
修改/lp/hadoop/apache-hive-2.1.1-bin/conf/hive-site.xml,把其中的${system:java.io.tmpdir}都修改成/lp/hadoop/apache-hive-2.1.1-bin/tmp,你也可以自己設定成自己的tmp目錄,把${system:user.name}都換成使用者名稱,為這裡替換成了luanpeng
初始化元資料資料庫(預設儲存在本地的derby資料庫,也可以配置成mysql),注意,不要先執行hive命令,否則這一步會出錯,(注意下面的命令是在/lp/hadoop/apache-hive-2.1.1-bin目錄下執行)
[[email protected] apache-hive-2.1.1-bin]# ./bin/schematool -dbType derby -initSchema
成功之後我們可以以客戶端形式直接啟動hive,如:
[[email protected] apache-hive-2.1.1-bin]# ./bin/hive
hive> show databases;
OK
default
Time taken: 1.886 seconds, Fetched: 1 row(s)
hive>
試著建立個數據庫是否可以:
hive> create database mydatabase;
OK
Time taken: 0.721 seconds
hive> show databases;
OK
default
mydatabase
Time taken: 0.051 seconds, Fetched: 2 row(s)
hive>
這時候,還是單機版。需要啟動server。啟動之前,先把埠改一下。
修改/lp/hadoop/apache-hive-2.1.1-bin/conf/hive-site.xml檔案
<name>hive.server2.thrift.port</name>
<value>10000</value>
改成
<name>hive.server2.thrift.port</name>
<value>8338</value>
然後啟動命令:
[[email protected] apache-hive-2.1.1-bin]# mkdir log ;
[[email protected] apache-hive-2.1.1-bin]# nohup ./bin/hiveserver2 &>log/hive.log &
這時可以通過jdbc客戶端連線這個服務訪問hive,埠是8338.
Spark
下載Spark版本和地址:
解壓後的目錄為/lp/hadoop/spark-2.3.0-bin-hadoop2.7
spark有多種部署方式,Standalone模式、Spark On Mesos模式、Spark On YARN模式。
下面我們嘗試spark單機直接跑、spark叢集執行,spark在yarn上執行。
首先支援單機直接跑
如執行樣例程式:(下面的命令是在/lp/hadoop/spark-2.3.0-bin-hadoop2.7中執行的)
[[email protected] spark-2.3.0-bin-hadoop2.7]# ./bin/spark-submit examples/src/main/python/pi.py 10
打印出很多日誌,其中有如下幾條重要日誌:
2018-05-14 20:12:43 INFO DAGScheduler:54 - Job 0 finished: reduce at /lp/hadoop/spark-2.3.0-bin-hadoop2.7/examples/src/main/python/pi.py:44, took 0.981974 s
Pi is roughly 3.142740
2018-05-14 20:12:43 INFO AbstractConnector:318 - Stopped [email protected]{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
2018-05-14 20:12:43 INFO SparkUI:54 - Stopped Spark web UI at http://192.168.122.1:4040
表示,計算任務成功了。
下面是spark叢集執行任務
修改下預設埠,修改sbin/start-master.sh 檔案
if [ "$SPARK_MASTER_WEBUI_PORT" = "" ]; then
SPARK_MASTER_WEBUI_PORT=8080
fi
改成
if [ "$SPARK_MASTER_WEBUI_PORT" = "" ]; then
SPARK_MASTER_WEBUI_PORT=8340
fi
改一下UI埠從8081到8341, 修改sbin/start-slaves.sh檔案
if [ "$SPARK_WORKER_WEBUI_PORT" = "" ]; then
SPARK_WORKER_WEBUI_PORT=8341
fi
執行命令:
[[email protected] spark-2.3.0-bin-hadoop2.7]# sbin/start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /lp/hadoop/spark-2.3.0-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-localhost.out
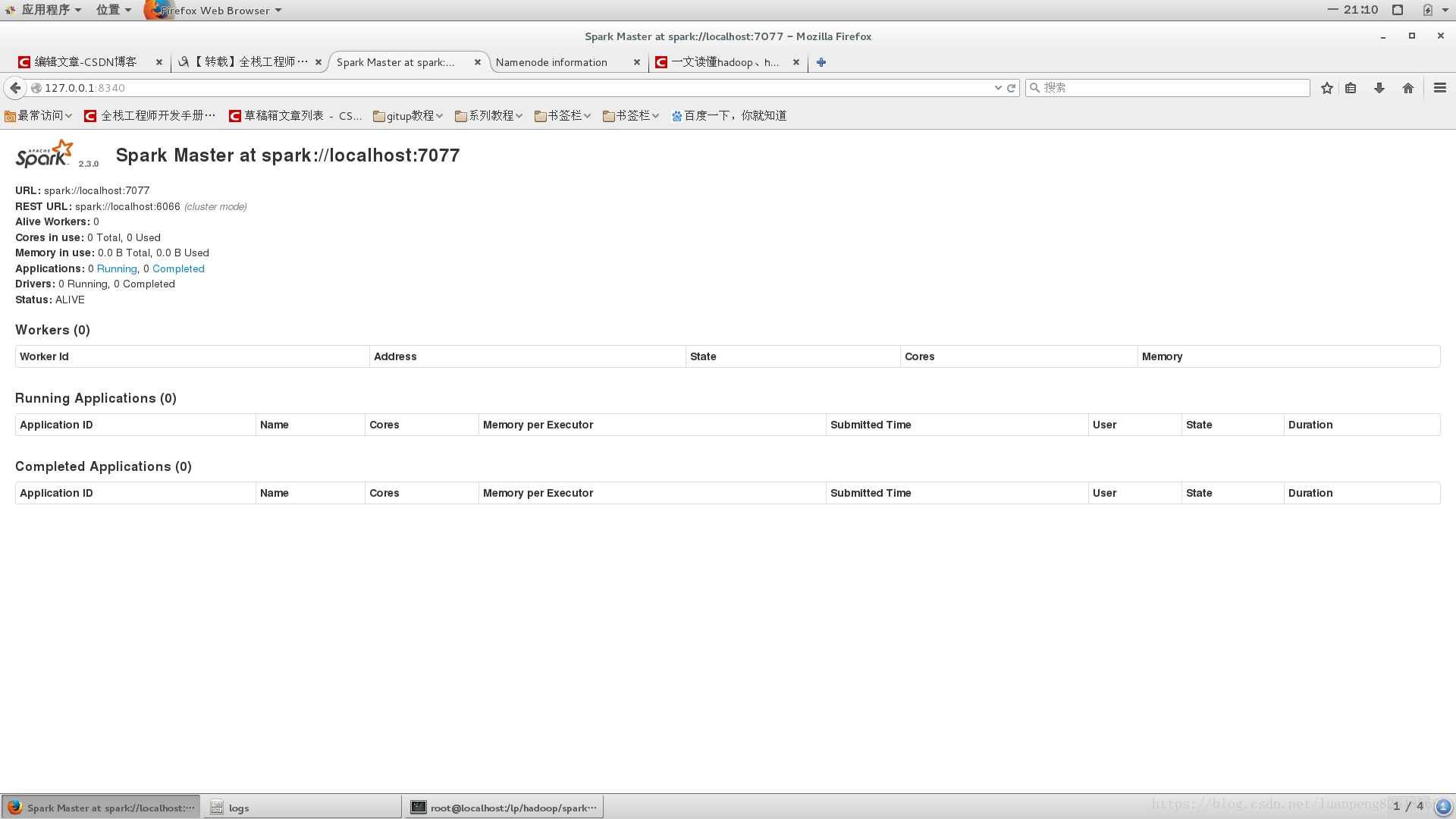
根據圖片中的url:spark://localhost:7077
再啟動slave
[[email protected] spark-2.3.0-bin-hadoop2.7]# ./sbin/start-slave.sh spark://localhost:7077
看日誌/lp/hadoop/spark-2.3.0-bin-hadoop2.7/logs資料夾中的日誌若沒有報錯,則ok
看slave 的UI 介面 http://127.0.0.1:8341/ 也能正常看到。 (11.27注:看起來主從都是這臺機器)
現在,就可以把剛剛單機的任務提交到spark叢集上來運行了:
[[email protected] spark-2.3.0-bin-hadoop2.7]# ./bin/spark-submit --master spark://localhost:7077 examples/src/main/python/pi.py 10
結果日誌包括了:
2018-05-14 21:25:44 INFO DAGScheduler:54 - Job 0 finished: reduce at /lp/hadoop/spark-2.3.0-bin-hadoop2.7/examples/src/main/python/pi.py:44, took 1.894816 s
Pi is roughly 3.152956
2018-05-14 21:25:44 INFO AbstractConnector:318 - Stopped [email protected]{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
2018-05-14 21:25:44 INFO SparkUI:54 - Stopped Spark web UI at http://192.168.122.1:4040
spark部署在yarn叢集上
spark程式也可以部署到yarn叢集上執行,也就是我們部署hadoop時啟動的yarn。當然部署在yarn上首先要要求啟動了hadoop的hdfs和yarn。
我們需要提前配置好HADOOP_CONF_DIR,修改/etc/profile檔案,新增:
HADOOP_HOME=/lp/hadoop/hadoop-2.7.3
export HADOOP_HOME
HBASE_HOME=/lp/hadoop/hbase-1.2.6
export HBASE_HOME
HIVE_HOME=/lp/hadoop/apache-hive-2.1.1-bin
export HIVE_HOME
PATH=$PATH:$HOME/bin
PATH=$PATH:$HBASE_HOME/bin
PATH=$PATH:$HIVE_HOME/bin
PATH=$PATH:$HADOOP_HOME/bin
export PATH
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
執行以下命令,重新載入配置檔案
source /etc/profile
下面我們把任務部署到yarn叢集上去:
[[email protected] spark-2.3.0-bin-hadoop2.7]# ./bin/spark-submit --master yarn --deploy-mode cluster examples/src/main/python/pi.py 10
總結一下
hdfs是所有hadoop生態的底層儲存架構,它主要完成了分散式儲存系統的邏輯,凡是需要儲存的都基於其上構建
yarn是負責叢集資源管理的部分,這個資源主要指計算資源,因此它支撐了各種計算模組
map-reduce元件主要完成了map-reduce任務的排程邏輯,它依賴於hdfs作為輸入輸出及中間過程的儲存,因此在hdfs之上,它也依賴yarn為它分配資源,因此也在yarn之上
hbase基於hdfs儲存,通過獨立的服務管理起來,因此僅在hdfs之上
hive基於hdfs儲存,通過獨立的服務管理起來,因此僅在hdfs之上
spark基於hdfs儲存,即可以依賴yarn做資源分配計算資源也可以通過獨立的服務管理,因此在hdfs之上也在yarn之上,從結構上看它和mapreduce一層比較像
總之,每一個系統負責了自己擅長的一部分,同時相互依託,形成了整個hadoop生態。
相關推薦
centos7下搭建hadoop、hbase、hive、spark分散式系統架構
全棧工程師開發手冊 (作者:欒鵬) 在使用前建議先將當前使用者設定為root使用者。參考https://blog.csdn.net/luanpeng825485697/article/details/80278383中修改使用者許可權的第三種方法。有了
hadoop、hbase、hive、spark分散式系統架構原理
全棧工程師開發手冊 (作者:欒鵬) 機器學習、資料探勘等各種大資料處理都離不開各種開源分散式系統,hadoop使用者分散式儲存和map-reduce計算,spark用於分散式機器學習,hive是分散式資料庫,hbase是分散式kv系統,看似互不相關的他們卻
一、CentOS7下搭建FastDFS+Nginx實現靜態圖片服務器
文件 源碼 wsgi ide 管理 配置 ror centos7 tor 在集群環境下,圖片存放在本地存在諸多限制,一般采用單獨的圖片服務器進行管理。FastDFS就是這樣一個圖片管理服務器。 環境需求,CentOS7下 一.先下載三件套,並上傳到服務器中(Nginx自行下
Hadoop生態中:Hive、Pig、HBase 關係與區別
Pig 一種操作hadoop的輕量級指令碼語言,最初又雅虎公司推出,不過現在正在走下坡路了。當初雅虎自己慢慢退出pig的維護之後將它開源貢獻到開源社群由所有愛好者來維護。不過現在還是有些公司在用,不過我認為與其使用pig不如使用hive。:) Pig是一種資料流語言,
Centos7下配置Java web環境(JDK、Tomcat、Mysql)
sql ner route aio word client rpm node share 在Centos7中配置java web環境主要涉及三方面配置:JDK、Tomcat以及Mysql 這裏使用版本如下: JDK:jdk-8u181-linux-x64,下載地址:http
Hive簡介、什麼是Hive、為什麼使用Hive、Hive的特點、Hive架構圖、Hive基本組成、Hive與Hadoop的關係、Hive與傳統資料庫對比、Hive資料儲存
1.1 Hive簡介 1.1.1 什麼是Hive Hive是基於Hadoop的一個數據倉庫工具,可以將結構化的資料檔案對映為一張資料庫表,並提供類SQL查詢功能。 1.1.2 為什麼使用Hive Ø 直接使用hadoop所面
Windows環境下搭建Hadoop(2.6.0)+Hive(2.2.0)環境並連線Kettle(6.0)
前提:配置JDK1.8環境,並配置相應的環境變數,JAVA_HOME 一.Hadoop的安裝 1.1 下載Hadoop (2.6.0) http://hadoop.apache.org/releases.html 1.1.1 下載對應版本的winutils(https://gith
centos7 下solr7.4.0 配置mysql 資料來源、中文分詞
準備 solr7.4.0未安裝請移步 solr安裝 solr 未配置中文分詞請移步 中文分詞 配置mysql資料來源步驟如下 下載mysql驅動包 地址:http://central.ma
CentOS7下使用docker,完成Jenkins映象、tomcat映象製作和啟動
最終的目的,是為了完成docker環境的Jenkins搭建使用,並從gitlab上獲取程式碼,打出war包,war包通過目錄掛載的方式,在tomcat容器中使用,總體思路如下 一、CentOS7下使用Docker 首先確保已經執行了yum源切換到阿里雲,參考上一節
centos7下gitlab的配置(nginx衝突、埠更改)
網上有很多關於gitlab配置的文章。但是普遍存在的問題是,對於gitlab自帶的配置模板和gitlab-ctl reconfigure之後生成的配置檔案沒有做區分,也沒有對gitlab-ctl reconfigure對於配置檔案的影響做說明,導致讀者不知
在centos6.5環境下搭建多版本python(python2.6、python2.7、python3.5)共存環境
可能存在的問題 yum安裝、原始碼安裝、二進位制安裝用哪個,官網文件是原始碼安裝,所以咱們就用原始碼安裝 在原始碼安裝的時候會有什麼問題 一個是預設路徑的問題,在編譯的時候時候如果不指定路徑的話,很多二進位制檔案會安裝到預設的目錄下/usr/bin下面,系
Linux下搭建實現HttpRunnerManager的非同步執行、定時任務及任務監控
前言 在之前搭建的HttpRunnerManager介面測試平臺,我們還有一些功能沒有實現,比如非同步執行、定時任務、任務監控等,要完成非同步執行,需要搭建 RabbitMQ 等環境,今天我們就來實現這些功能。 需要在Linux上提前準備的環境(下面是本人搭建時的環境): 1,HttpRunnerManag
第四百零五節,centos7下搭建sentry錯誤日誌服務器,接收python以及Django錯誤,
rate install 中文 engine some remove master -- 復制 第四百零五節,centos7下搭建sentry錯誤日誌服務器,接收python以及Django錯誤, 通過docker安裝sentry 安裝docker 1.卸載舊版本
在Centos7下搭建Socks5代理服務器
socks5 采用socks協議的代理服務器就是SOCKS服務器,是一種通用的代理服務器。Socks是個電路級的底層網關,是DavidKoblas在1990年開發的,此後就一直作為Internet RFC標準的開放標準。Socks 不要求應用程序遵循特定的操作系統平臺,Socks 代理與應用層代
Centos7下搭建Zabbix
ges restart start bin chown time rpm -ivh 正式 登錄 安裝Mysql5.61.下載MySQL的repo源 #wget http://repo.mysql.com/mysql-community-release-el7-5.noarc
Centos7下搭建Django+uWSGI+nginx基於python3
def .tar.gz nts sse soc pycha make 啟動 share 1.電腦環境 Centos7 + python3.6 + virtualenv 由於centos自帶的是python2.7版本,所以要自己安裝新的版本,這裏就不對此描述了,直接開工
如何在CentOS7下部署Hadoop
1.前言 “大雲物移”是當年很火熱的一個話題,分別指大資料、雲端計算、物聯網和移動網際網路,其中大資料領域談論得多就是Hadoop。當然Hadoop不代表大資料,而是大資料處理領域的一個比較有名的開源框架而已,通常說的大資料包含了大資料的存放、大資料的分析處理及大資料的查詢展示,本篇提到的Ha
Centos7下配置Hadoop偽分散式環境
Centos 版本:7 Hadoop版本:2.7.4 Java版本:1.8 一、安裝JDK 官網下載jdk 1.8 http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.
centos7下搭建django
安裝環境:centos7.4 1 安裝nginx yum install nginx 注:嘗試過在本地和騰訊雲上安裝,使用同一條命令:在本地安裝提示沒有可用安裝包,雲上安裝正常 啟動nginx,並啟用開機啟動
基於Centos7+Docker 搭建hadoop叢集
總體流程: 獲取centos7映象 為centos7映象安裝ssh 使用pipework為容器配置IP 為centos7映象配置java、hadoop 配置hadoop 1.獲取centos7映象 $ docker pull centos:7 //檢視當前已下載docke