
Java獲取網頁下超連結並儲存
阿新 • • 發佈:2018-11-02
把本程式改造為一個輸入一個起始URL及其引數之後就可以下載此URL及其引數所指定的WEB頁面以及此WEB頁面中HTML語言超級連結所指向的所有WEB頁面(只下載一級即可)。
主要需要利用Pattern類方法和正則表示式來獲取超連結
import java.io.*;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
class HtmlParser1 結果:
擷取的超連結
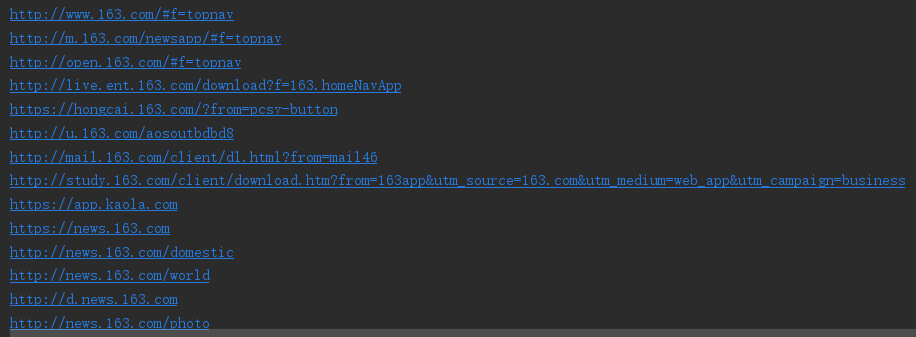
獲取的超連結的HTML網頁:
