
【1】pytorch torchvision原始碼解讀之Alexnet
最近開始學習一個新的深度學習框架PyTorch。
框架中有一個非常重要且好用的包:torchvision,顧名思義這個包主要是關於計算機視覺cv的。這個包主要由3個子包組成,分別是:torchvision.datasets、torchvision.models、torchvision.transforms。
具體介紹可以參考官網:https://pytorch.org/docs/master/torchvision
具體程式碼可以參考github:https://github.com/pytorch/vision
torchvision.models這個包中包含alexnet、densenet、inception、resnet、squeezenet、vgg等常用經典的網路結構,並且提供了預訓練模型,可以通過簡單呼叫來讀取網路結構和預訓練模型。
今天我們來解讀一下Alexnet的原始碼實現。如果對AlexNet不是很瞭解 可以檢視這裡的論文筆記https://blog.csdn.net/sinat_33487968/article/details/83543406
如何使用呢?
import torchvision
model = torchvision.models.Alexnet(pretrained=True)這樣就可以獲得網路的結構了,pretrained引數的意思是是否預訓練,如果為True就會從網上下載好已經訓練引數的模型。改引數預設是False。
import torch.utils.model_zoo as model_zoo __all__ = ['AlexNet', 'alexnet'] model_urls = { 'alexnet': 'https://download.pytorch.org/models/alexnet-owt-4df8aa71.pth', }
首先是匯入必要的庫,其中model_zoo是和匯入預訓練模型相關的包,另外all變數定義了可以從外部import的函式名或類名。這也是前面為什麼可以用torchvision.models.alexnet()來呼叫的原因。model_urls這個字典是預訓練模型的下載地址。
接下來就是Alexnet這個類
class AlexNet(nn.Module): def __init__(self, num_classes=1000): super(AlexNet, self).__init__() self.feature = nn.Sequential( nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2), nn.ReLU(inplace=True), # inplace為True,將會改變輸入的資料 ,否則不會改變原輸入,只會產生新的輸出 nn.MaxPool2d(kernel_size=3, stride=2), nn.Conv2d(64, 192, kernel_size=5, padding=2), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2), nn.Conv2d(192, 384, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2), ) self.classifer = nn.Sequential( nn.Dropout(), nn.Linear(256 * 6 * 6, 4096), nn.ReLU(inplace=True), nn.Dropout(), nn.Linear(4096, 4096), nn.ReLU(inplace=True), nn.Linear(4096, num_classes), ) def forward(self, x): x = self.feature(x) x = x.view(x.size(0), 256 * 6 * 6) # reshape x = self.classifer(x) return x
AlexNet網路是通過AlexNet這個類例項化的。首先還是繼承PyTorch中網路的基類:torch.nn.Module,其次主要的是重寫初始化__init__和forward方法。在初始化__init__中主要是定義一些層的引數。forward方法中主要是定義資料在層之間的流動順序,也就是層的連線順序。基本上就是五層卷積加上三層全連線(不算relu和max max pooling)。注意到ReLU的inplace為True,將會改變輸入的資料 ,否則不會改變原輸入,只會產生新的輸出。而 x = x.view(x.size(0), 256 * 6 * 6) 的意思是reshape卷積層得到的結果,為了匹配後面的全連線層。
具體結構可以參照下圖:
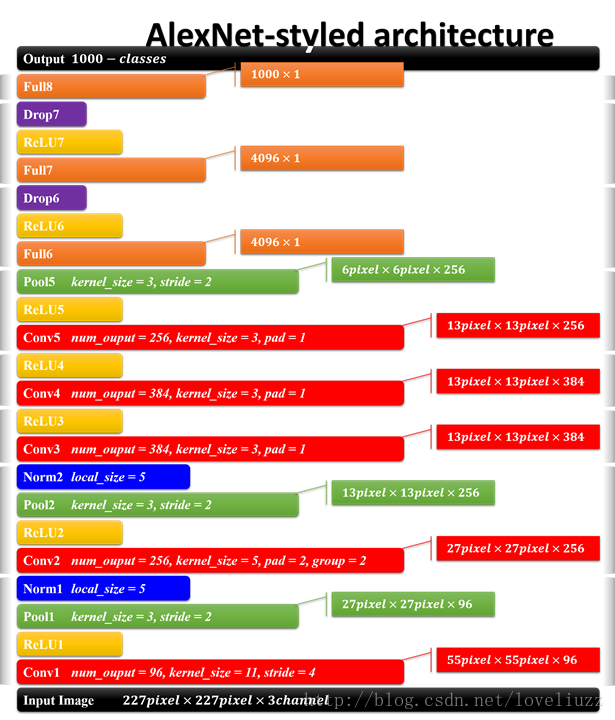
最後呈現上原始碼
import torch.nn as nn
import torch.utils.model_zoo as model_zoo
__all__ = ['Alexnet', 'alexnet']
model_urls = {
'alexnet': 'https://download.pytorch.org/models/alexnet-owt-4df8aa71.pth',
}
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.feature = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True), # inplace為True,將會改變輸入的資料 ,否則不會改變原輸入,只會產生新的輸出
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.classifer = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.feature(x)
x = x.view(x.size(0), 256 * 6 * 6) # reshape
x = self.classifer(x)
return x
def alexnet(pretrained = False,**kwargs):
r"""AlexNet model architecture from the
"One werid trick..."<https://arxiv.org/abs/1404.5997>_papper.
Args:
pretrained(bool):if True,returns a model pre-trained on ImagetNet
"""
model = AlexNet(**kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['alexnet']))
return model
if __name__ == '__main__':
alexnet()